测评qwen 、glm ,deepseek的模型 对垂直领域的能力的支持情况对比
对于Deepseek模型的输出结果来看,实际上当时选择的模型coder类型,侧重编码,在相同的提示词的情况下,输出直接输出的就是命令的的排查方法,但是确实思路的分析,首先进行了排除对于GLM和qwen的回答,对保存告警的排查思路和命令行的输出都有着不错的效果,在参考模型参数的大小,对于glm4:9b 占用 5.5 GB硬盘资源,是90亿参数的模型,qwen2.5:latest 占硬盘 4.7 GB
前言:
在写这篇文章的时候,我也看了许多测评的文章,总觉得差点意思,都是对通用能力的测评,或者是垂直领域的coder 或者是math能力,就不太适用于我目前的项目,对于任何一个公司开发项目肯定是数据是非常核心的,不能说去直接调用市面给用户使用的大模型的api,需要部署本地大模型进行使用。我的思路,通过本地部署大模型,通过开发平台进行对垂直领域的回答,把chatGPT作为专家模型,进行对比,最后选出参数合适,领域知识全面的模型进行使用,引入项目当中去。
一、模型的测评平台搭建
通过开源项目Open_webUI和Ollama集成进行测试的项目地址我放到了下面
https://github.com/open-webui/open-webui
1.Docker desktop的安装
1.1 Docker desktop下载
网址:https://www.docker.com/products/docker-desktop/
进入网址后:点击Download Docker Desktop,我这里是windows系统,可以选择“Download for Windows - AMD64” 和 “Download for Windows - ARM64”
主要有以下区别:
“Download for Windows - AMD64” 是针对 64 位的 AMD 处理器架构设计的软件版本。
- AMD64 架构在个人电脑领域广泛应用,具有强大的性能和广泛的软件兼容性。它能够处理大量的数据和复杂的计算任务,适用于各种高性能需求的场景,如游戏、图形设计、视频编辑等。
- 很多主流的软件和游戏都针对 AMD64 架构进行了优化,以充分发挥其性能优势。
“Download for Windows - ARM64” 则是针对 ARM64 架构的版本。
ARM64 架构主要用于移动设备和一些低功耗的计算设备,如智能手机、平板电脑和部分轻薄笔记本电脑。近年来,随着技术的发展,ARM64 架构也开始在桌面级电脑市场崭露头角。
ARM64 架构的特点是功耗低、续航能力强,适合对移动性要求较高的用户。
我这里选择的是Download for Windows - AMD64,你根据你的需要进行选择即可
下载完成后你的目录就会有.exe的应用程序
具体的Docker desktop的安装不做过多的赘述,点击下一步下一步安装即可,安装好之后,打开软件主界面是:(这里我调整了主题是暗色系,正常是白色)
我们在 CMD 终端上看。

至此,Docker Desktop 安装告一段落,接下来就是在 安装Ollama平台和Open_webUI
2.Ollama的本地部署
进入网址:Download Ollama on macOS 根据你的需求进行下载即可,我这里直接下载的是windows版本,下载完成后也是在目录里出现了一个exe的文件,点击下一步进行安装即可
ollama部署完成后我们继续进入官网https://ollama.com/,搜索栏进行搜索选择你想用的模型
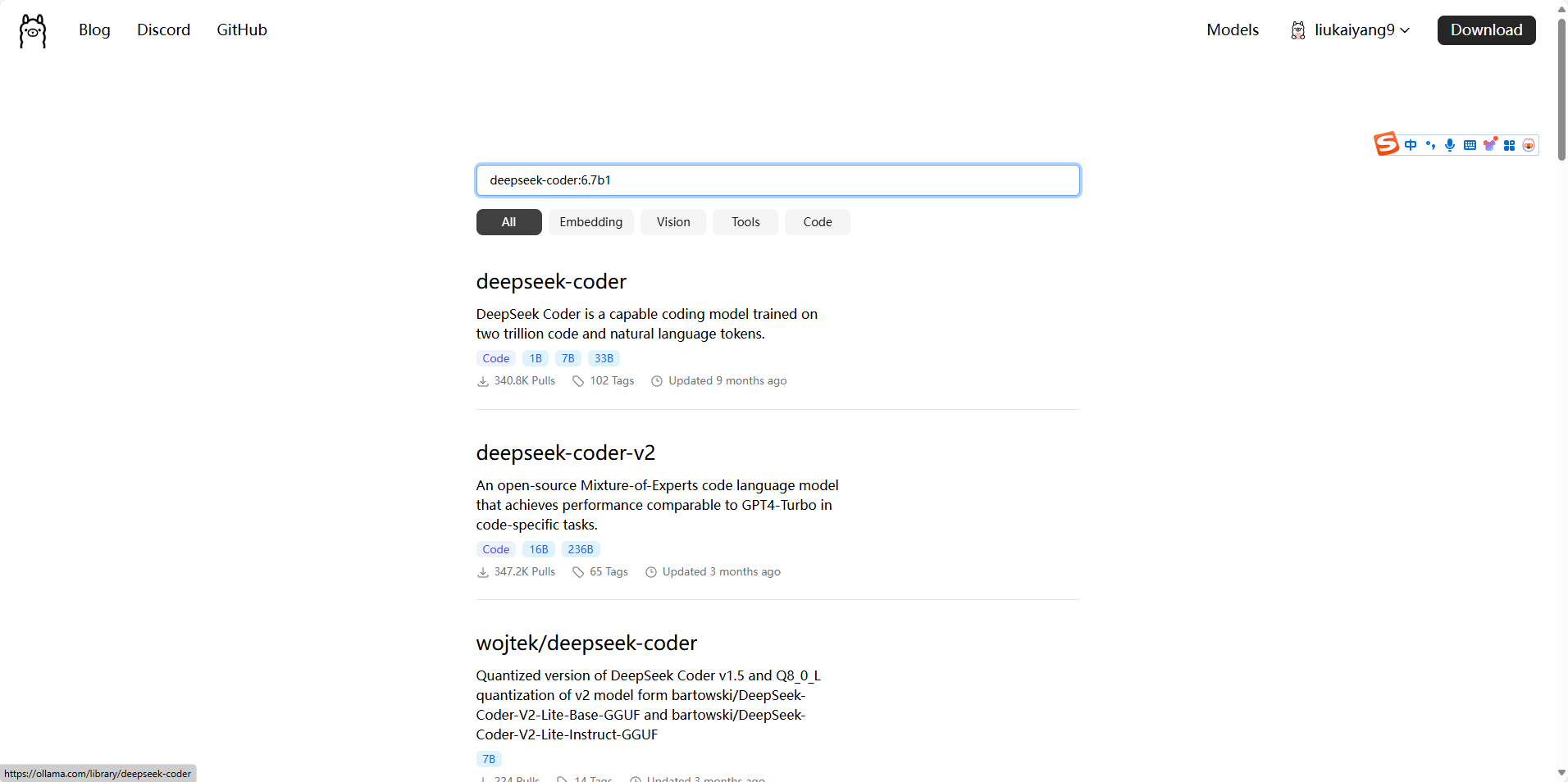
点击进去,复制红框里的命令行
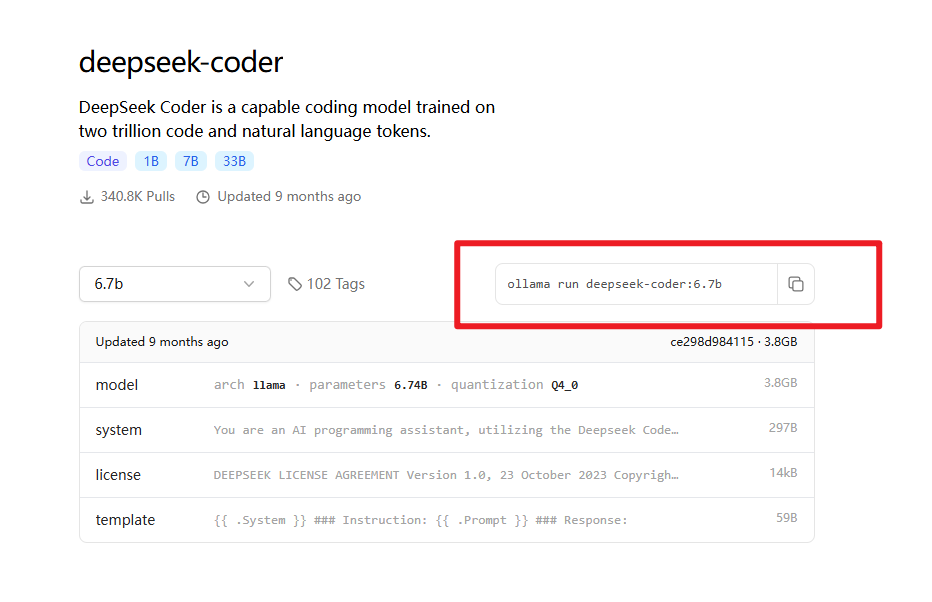
将复制的命令在windows的cmd窗口下进行运行 , 模型就开始下载耐心等待即可
等待一段时间你就会发现通过ollma list,就会增加一个deepseek-coder:6.7b的模型
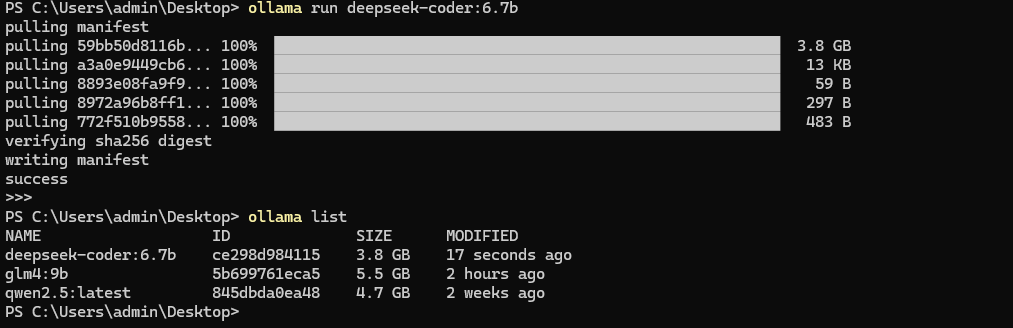
需要注意的是如果你是win系统部署的Ollama平台,windows 的安装默认不支持修改程序安装目录,那么默认位置如下:
默认安装后的目录:C:\Users\username\AppData\Local\Programs\Ollama
默认安装的模型目录:C:\Users\username\ .ollama
默认的配置文件目录:C:\Users\username\AppData\Local\Ollama
这里提一下是因为后续在模型推理的时候使用cpu 还是GPU,需要找到配置文件的路径进行确认
3.Open_webUI本地项目的部署
3.1 容器部署
在 Windows 系统上完成 Docker Desktop 的安装后,我们直接进入github此项目的仓库
https://github.com/open-webui/open-webui 可以点击浏览器自带的翻译找到下面的信息
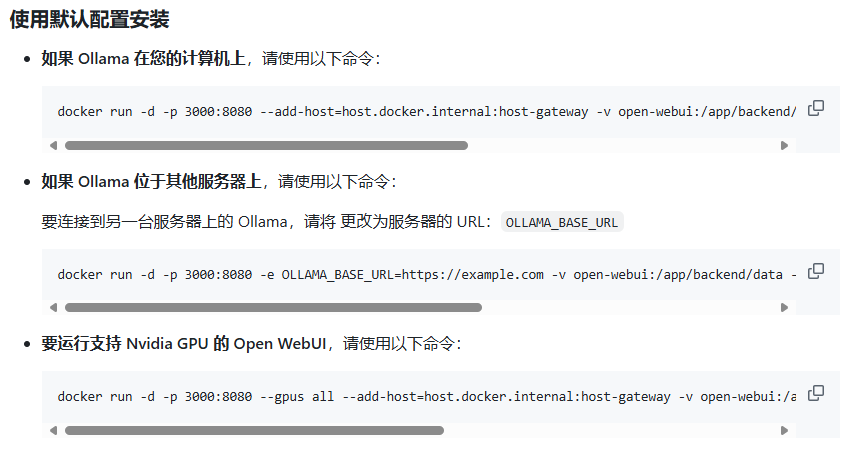
这里提供了多种安装环境的选择,我们只需挑选适合自己情况的那一部分即可我们在这里直接复制命令在windows 的cmd窗口进行运行即可 ,因为我是在windows本地进行部署,我选择是第一条命令
1 |
docker run -d -p 3000:8080 --add-host=host.docker.internal:host-gateway -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:main |
这条命令它的主要作用是去拉取一个 Open WebUI 的 Docker 镜像,并进行部署。我们只需在 CMD 终端上执行这条命令,暂时不考虑调整各个参数。
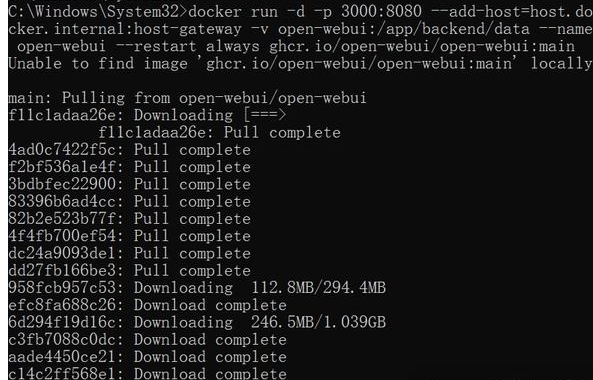
这个过程可能需要一些时间,请耐心等待,当每个项目都显示Pull complete时,恭喜你,这个 Docker 镜像的部署就完成了。
3.2 进入UI界面
如果你是本地部署的通过在浏览上输入http://localhost:3000即可进入下面的ui界面,然后进行注册
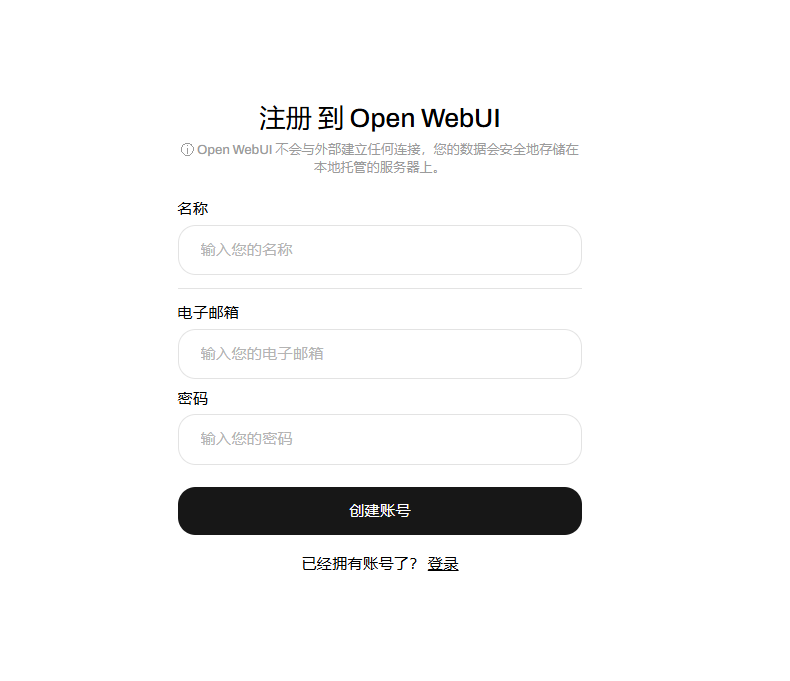
注册完成后你就得到了一个类似于chatGPT的UI界面
到这里你可以选择一个模型进行使用,这与之前的ollama list查看的模型是一致,如下图
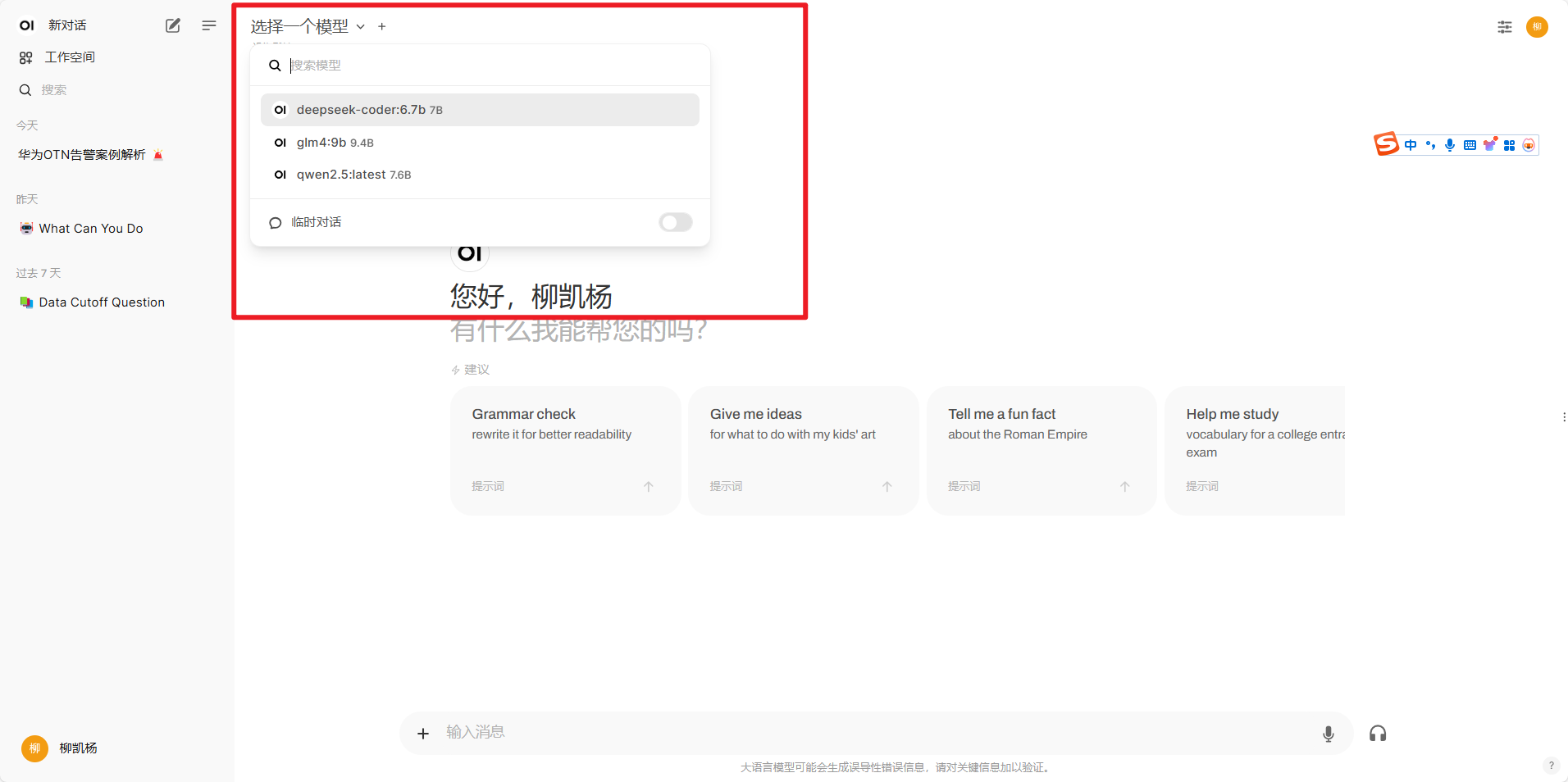

二、模型的选取
在选择模型时,我们需要综合考虑任务需求、模型性能、硬件兼容性、数据匹配、部署复杂度、社区支持、成本预算以及可解释性等多个因素。通过仔细评估这些因素,选择最适合你应用场景的模型,并确保其高效、可靠地运行。
· 首先根据任务的需求,我这里要做的任务是对话形式的智能助手,所以在模型的选择是我选择的chat多轮对话的基座大模型,其次模型的性能其实就是我们测评得出的效果,在这里就是支持我垂直领域知识的情况;然后模型的大小,硬件的兼容性,和成本预算,我这里的服务器的配置如下:

所以选择百亿参数以下的模型应该绰绰有余,下一步明确部署的模型是通过CPU还是GPU进行的推理,因为这里使用的是ollama平台进行的模型的部署,通常情况下是通过CPU进行部署推理的,通过ollama run 模型名,命令部署的模型,默认情况下是可以在CPU上运行的,但这取决于你的具体配置。Ollama框架支持仅使用CPU或者CPU+GPU的混合模式进行推理。如果你的系统配置了GPU,并且正确设置了环境(包括安装了必要的GPU驱动和NVIDIA Container Toolkit),Ollama可以通过设置参数来利用GPU资源。然而,根据你提供的信息,并没有明确指出在运行deepseek-coder:6.7b时是否特别指定了使用GPU。如果没有额外的参数来指定使用GPU,它很可能会默认使用CPU进行推理。因为我这边进行了正确设置了环境(包括安装了必要的GPU驱动和NVIDIA Container Toolkit),所以我得模型推理的时候使用了GPU
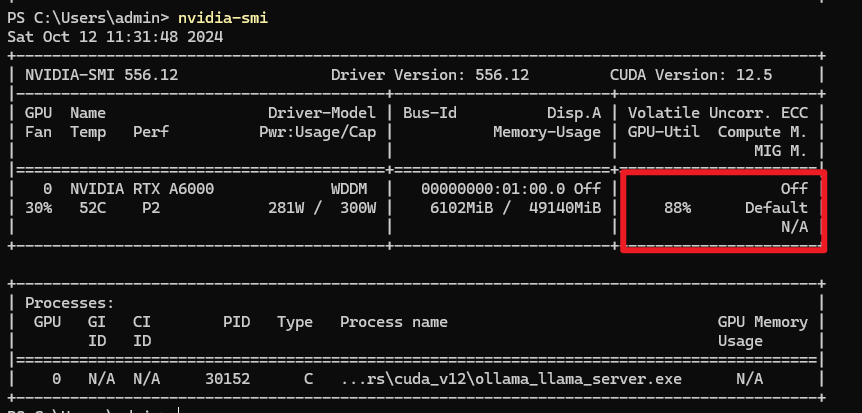
好吧,说了这么多,最后我综合考量我们的项目大小和本身的硬件资源,以及客户的要求,在这里选取的大模型如下:
清华2024年6月开源的GLM-4-9B系列
阿里2024年6月开源qwen2系列
阿里2024年9月19日开源qwen2.5系列

三、实际测评过程
1.测评思路
因为我做的这个项目是关于通讯设备OTN网元设备的项目,所以根据使用场景我的想法:希望的是通过以下四个阶段对模型进行测评和对比,最终通过回答的效果分析。
准备阶段:制定详细的测评问卷或对话脚本,确保覆盖所有测评点。
执行阶段:通过API或交互界面,向模型提出上述设计的问题,并记录其回答。
评估阶段:由OTN领域的专家团队(这里将chatGPT当做专家)对模型的回答进行评分,依据准确性、深度、相关性和实用性。
分析与反馈:汇总测评结果,分析模型在技术理解与解释能力上的强项与不足,提出改进建议。
2.测评的维度
评估大模型在OTN网元设备相关场景的支持能力,主要围绕技术理解、操作指导、故障诊断和未来趋势预测等关键方面进行。以下是比较细化的测评维度
(1)技术理解与解释能力:
- 专业知识掌握:测试大模型能否准确解释OTN的基本概念,如光传输终端设备(Transponder)、光交叉连接设备(OXC)、光保护(OP)和光监控设备的功能与工作原理。
- 技术细节理解:评估模型是否能理解并解释OTN标准(如G.709、G.959.1等)的关键要素,以及这些标准如何影响设备的性能和互操作性。
- 测试问题:
- 请解释光传输终端设备(Transponder)的功能和工作原理。
- 在OTN网络中,Transponder的主要作用是什么?
- Transponder如何处理光信号的调制和解调?
- 请解释光交叉连接设备(OXC)的功能和工作原理。
- 在OTN网络中,OXC的主要作用是什么?
- OXC如何实现光信号的交叉连接和路由?
- 请解释光保护(OP)的功能和工作原理。
- 在OTN网络中,光保护的主要作用是什么?
- 光保护如何确保网络的可靠性和稳定性?
- 请解释光监控设备的功能和工作原理。
- 在OTN网络中,光监控设备的主要作用是什么?
- 光监控设备如何实时监控网络状态?
- 请解释G.709标准中的OTUk帧结构。
- G.709标准如何影响OTN设备的性能?
- G.709标准如何确保设备的互操作性?
- 请解释G.959.1标准中的光传输层(OTL)概念。
- G.959.1标准如何影响OTN设备的性能?
- G.959.1标准如何确保设备的互操作性?
(2)操作指导与配置建议:
- 命令与配置:测试模型是否能提供正确的OTN设备配置指令,包括初始化设置、波长分配、保护配置等。
- 故障模拟与解决:提出常见或特定的OTN设备故障场景,评估模型能否提供有效的诊断步骤和解决方案。
- 测试问题:
- 如何在华为OTN设备上配置波长分配?
- 如何在中兴通讯OTN设备上配置波长分配?
- 如何在爱立信OTN设备上配置波长分配?
- 如何在华为OTN设备上配置1+1保护?
- 如何在中兴通讯OTN设备上配置1:1保护?
- 如何在爱立信OTN设备上配置共享保护环?
- 如果华为OTN设备上报了许多告警信息,应该如何诊断和解决?
- 如果中兴通讯OTN设备的光功率异常,应该如何诊断和解决?
- 如果爱立信OTN设备的波长冲突,应该如何诊断和解决?
- 如果华为OTN设备的OTUk帧结构异常,应该如何诊断和解决?
- 如果中兴通讯OTN设备的ODUk路径状态异常,应该如何诊断和解决?
- 如果爱立信OTN设备的OPUk净荷类型错误,应该如何诊断和解决?
(3)性能分析与优化:
- 性能指标理解:考察模型是否能理解并分析OTN网络的关键性能指标(如误码率、光信噪比等)。
- 优化建议:询问模型关于提升OTN网络效率和性能的建议,包括但不限于带宽管理、资源分配等。
- 测试问题:
- 请解释误码率(BER)在OTN网络中的重要性。
- 如何测量和分析OTN网络中的误码率?
- 误码率过高时,可能的原因有哪些?
- 请解释光信噪比(OSNR)在OTN网络中的重要性。
- 如何测量和分析OTN网络中的光信噪比?
- 光信噪比过低时,可能的原因有哪些?
- 请列举并解释OTN网络中的其他关键性能指标。
- 如何测量和分析这些性能指标?
- 这些性能指标异常时,可能的原因有哪些?
- 如何优化OTN网络的带宽管理?
- 带宽管理不当可能导致哪些问题?
- 请提供具体的带宽管理优化建议。
- 如何优化OTN网络的资源分配?
- 资源分配不当可能导致哪些问题?
- 请提供具体的资源分配优化建议。
- 请提供其他提升OTN网络效率和性能的建议。
- 这些优化建议如何实施?
- 这些优化建议可能带来的好处是什么?
(4)兼容性与互操作性(目前已华为为例,之后会适配更多的厂商):
- 设备兼容:测试模型对不同厂商OTN设备特性的了解,以及如何在多厂商环境中确保设备间的兼容性。
- 标准遵循:评估模型对国际电信联盟(ITU-T)标准的熟悉程度,以及如何确保设备配置符合这些标准。
- 测试问题:
- 请描述华为和中兴通讯的OTN设备在光功率管理方面的主要区别。
- 爱立信的OTN设备在光复用段(OMS)层有哪些独特的功能?
- 华为的OTN设备在光传输段(OTS)层有哪些独特的功能?
- 在多厂商环境中,如何确保华为和中兴通讯的OTN设备能够无缝对接?
- 在多厂商环境中,如何处理爱立信和华为的OTN设备在光通道(OCH)层的兼容性问题?
- 请解释ITU-T G.709标准中的OTUk帧结构。
- 在ITU-T G.872标准中,OTN网络的主要功能模块有哪些?
- 请描述ITU-T G.808.1标准中的1+1保护机制。
- 如何确保华为的OTN设备配置符合ITU-T G.709标准?
- 在配置中兴通讯的OTN设备时,如何确保其符合ITU-T G.872标准?
- 在配置爱立信的OTN设备时,如何确保其符合ITU-T G.808.1标准?
(5)安全与风险管理:
- 安全配置:询问模型关于OTN网络的安全配置建议,如防止未授权访问和数据泄露。
- 风险评估:测试模型是否能识别潜在的网络操作风险,并提供预防措施。
- 测试问题:
- 如何配置OTN网络以防止未授权访问?
- 请列举常见的未授权访问风险,并提供相应的防护措施。
- 如何在华为OTN设备上配置访问控制列表(ACL)?
- 如何配置OTN网络以防止数据泄露?
- 请列举常见的数据泄露风险,并提供相应的防护措施。
- 如何在爱立信OTN设备上配置数据加密?
- 请列举OTN网络中常见的潜在操作风险。
- 如何识别和评估这些潜在风险?
- 请提供具体的识别和评估步骤。
- 针对识别出的潜在风险,请提供相应的预防措施。
- 如何实施这些预防措施?
- 这些预防措施可能带来的好处是什么?
3.实施过程
进入web_UI界面,分别创建三个模型的对话框
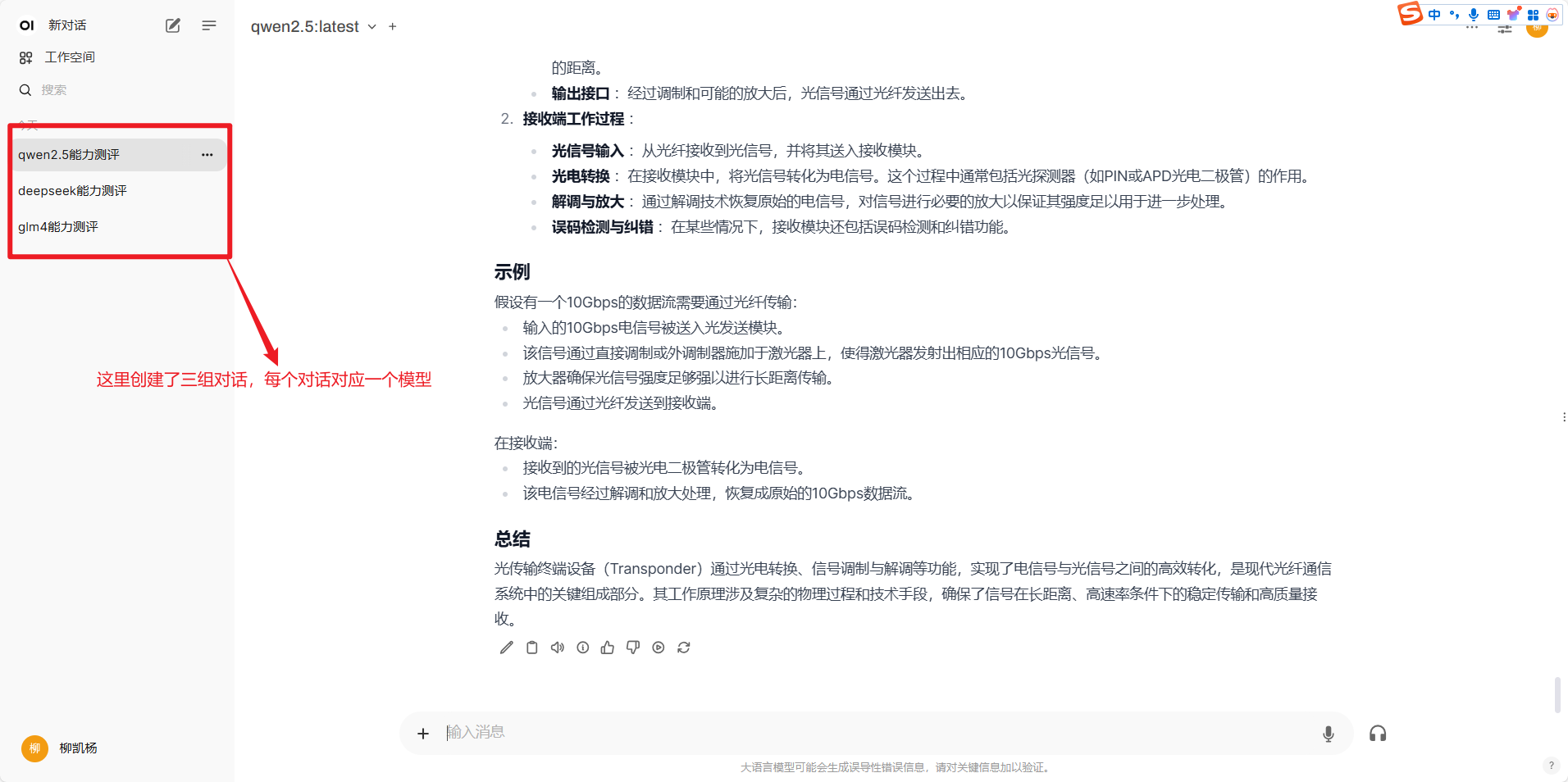
以此问题举例进行对比:
1 2 3 4 |
2023-10-05 14:32:15 Major ALM_GFP_dLFD Port 1/2/3 GFP dLFD Alarm on Port 1/2/3 Active NE1 Additional Info: Link failure detected 2023-10-05 14:32:15 Major APS_INDI Line 1/2/3 APS Indication on Line 1/2/3 Active NE1 Additional Info: Protection switch initiated 2023-10-05 14:32:15 Major APS_FAIL Line 1/2/3 APS Failure on Line 1/2/3 Active NE1 Additional Info: Protection switch failed 如果华为的OTN设备出现了上述的告警,应该如何诊断和解决? |
(1)qwen的回答:


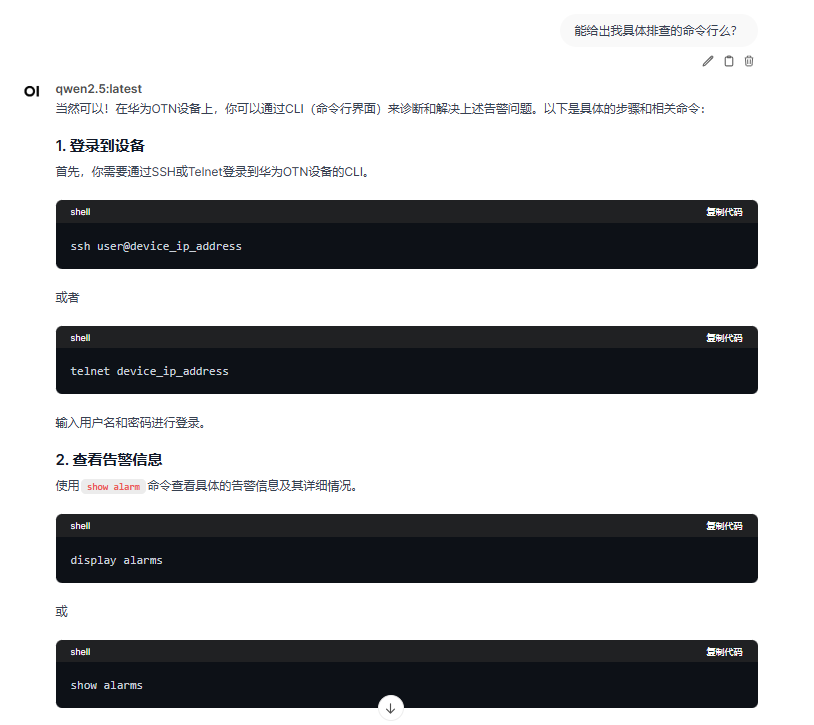
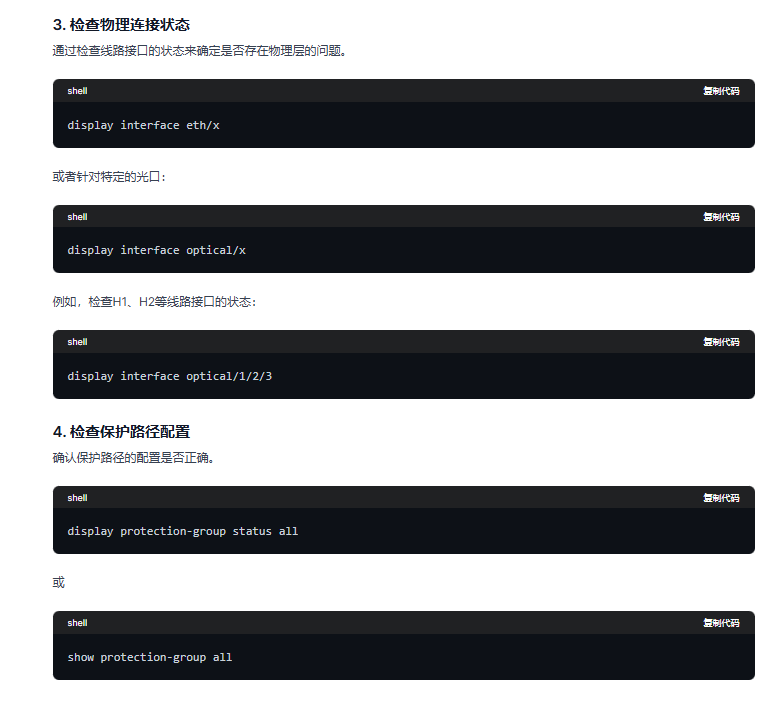
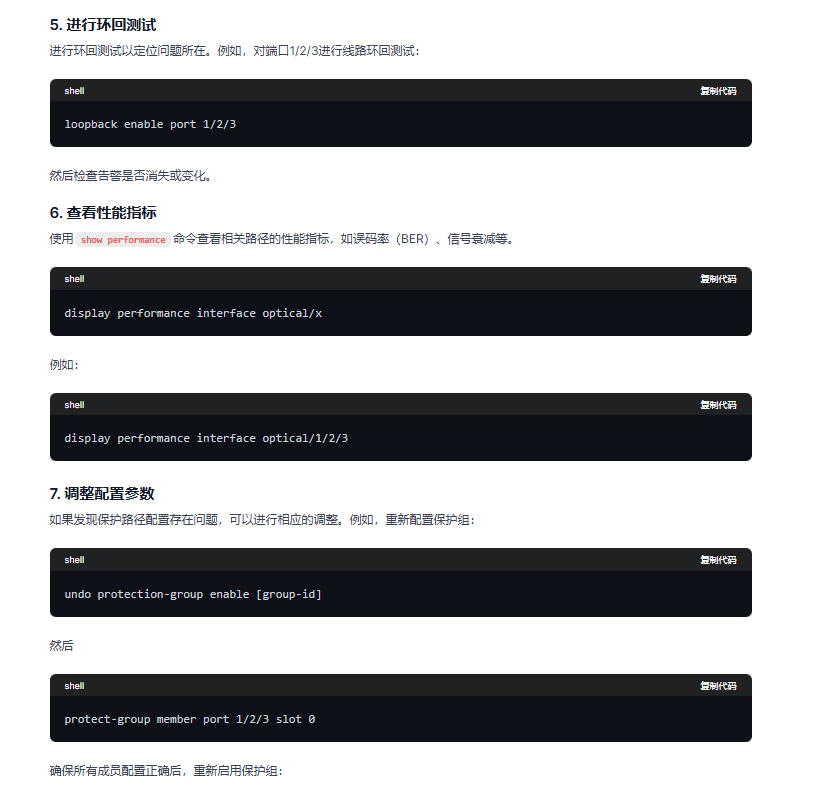
(2)glm4的回答:



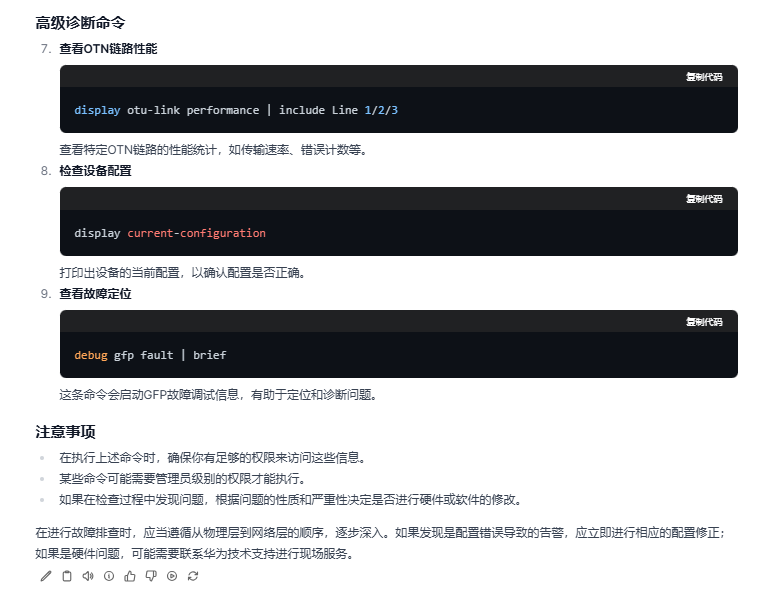
(3)deepseek的回答:

(4)chatGPT的回答





(5)总结:
对于Deepseek模型的输出结果来看,实际上当时选择的模型coder类型,侧重编码,在相同的提示词的情况下,输出直接输出的就是命令的的排查方法,但是确实思路的分析,首先进行了排除
对于GLM和qwen的回答,对保存告警的排查思路和命令行的输出都有着不错的效果,在参考模型参数的大小,对于glm4:9b 占用 5.5 GB硬盘资源,是90亿参数的模型,qwen2.5:latest 占硬盘 4.7 GB ,是70亿参数的模型,最终选择qwen2.5:latest 作为我们项目的最终基座模型。

欢迎加入 MCP 技术社区!与志同道合者携手前行,一同解锁 MCP 技术的无限可能!
更多推荐


 32
32 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)