小白如何入门AI大模型,超详材料(建议收藏)
小白如何入门AI大模型,超详材料(建议收藏)
AI大模型
大模型(大规模语言模型)是指具有庞大参数规模(数百万至数千亿级)的机器学习模型,通过海量数据和算力训练形成,可处理文本生成、图像识别、语音交互等复杂任务。其类型涵盖自然语言处理、计算机视觉、语音识别、强化学习等方向。
一、大模型上游:基础技术与资源支撑
大模型产业链上游是支撑技术研发的基础层,涵盖硬件设施、数据资源和基础软件三大核心领域,为模型训练和推理提供算力、数据及底层开发环境支持。
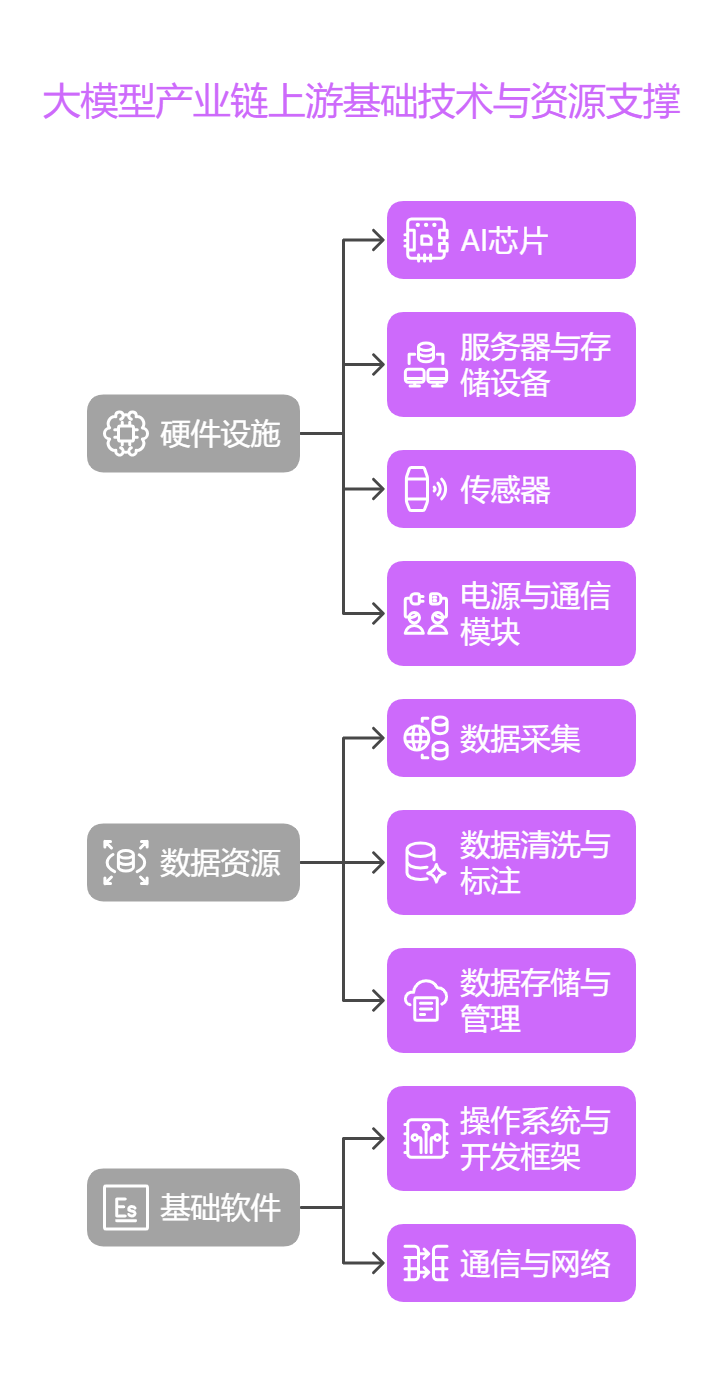
1. 硬件设施
-
AI芯片:作为算力核心,承担模型训练和推理任务。
-
类型:GPU(英伟达A100/H100)、TPU(谷歌)、NPU(寒武纪)等高性能芯片。
-
国产化趋势:国内厂商如华为昇腾、寒武纪加速替代进口芯片,降低算力依赖。
-
-
服务器与存储设备:
-
高性能服务器:浪潮信息、中科曙光等厂商提供支持分布式训练的GPU服务器,单台成本高达百万级,中小企业可通过一体机(集成大模型的低成本设备)降低部署门槛。
-
存储设备:SSD固态硬盘、分布式存储系统(如Hadoop)满足海量数据的高速读写需求。
-
-
传感器:摄像头、激光雷达等设备采集多模态数据(图像、语音、环境信息),为模型训练提供原始输入。
-
电源与通信模块:高能效电源保障硬件稳定运行,光模块(中际旭创)和5G/6G网络确保数据传输效率。
2. 数据资源
-
数据采集:
-
来源:互联网爬虫、传感器、企业数据库、公开数据集(如ImageNet)等。
-
多模态覆盖:文本、图像、音频、视频等多元化数据增强模型泛化能力。
-
-
数据清洗与标注:
-
清洗:去重、去噪、格式标准化,提升数据质量。
-
标注:人工标注(如医学影像标注)结合自动化工具(半监督学习)降低成本,形成结构化训练集。
-
-
数据存储与管理:
-
云存储:阿里云、腾讯云等提供弹性存储空间,支持PB级数据扩容。
-
数据库技术:向量数据库(如Milvus)优化大模型的数据检索效率。
-
3. 基础软件
-
操作系统与开发框架:
-
操作系统:Linux(开源生态适配AI开发)、Windows Server(企业级服务器管理)。
-
深度学习框架:TensorFlow、PyTorch简化模型构建,支持从训练到部署的全流程开发。
-
-
通信与网络:
-
网络协议:RDMA(远程直接内存访问)技术提升分布式训练节点间通信效率。
-
边缘计算支持:低延迟网络(如5G)推动端侧设备与云端协同计算。
-
上游核心挑战与趋势
-
算力成本:GPU服务器价格高昂,推动国产芯片研发和轻量化模型(如TinyBERT)以降低硬件需求。
-
数据合规性:隐私计算技术(联邦学习)保障数据安全,符合《数据安全法》等法规要求。
-
技术融合:量子计算与AI芯片结合,探索突破传统算力瓶颈的可能性。
通过以上基础层支撑,大模型产业链得以实现从数据到算力的完整闭环,为后续模型开发和应用落地奠定基础。
二、 中游:技术开发与模型优化
中游是大模型产业链的核心技术层,聚焦模型研发、训练优化及配套工具开发,承担从算法设计到模型落地的关键环节。以下是具体细分内容及技术要点:
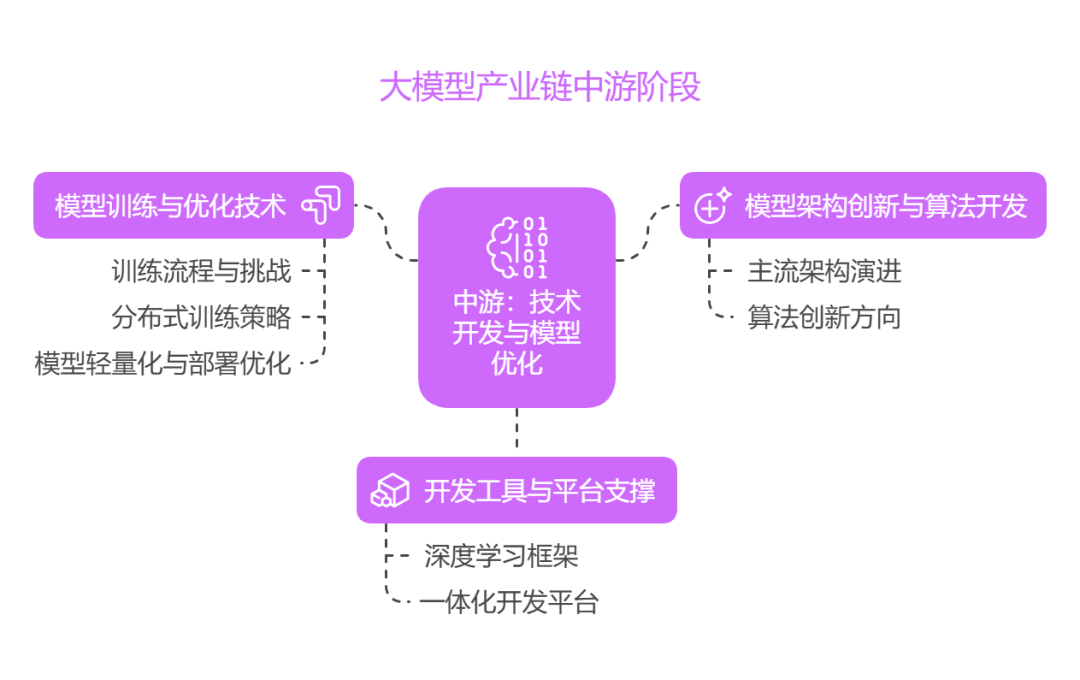
一、模型架构创新与算法开发
1. 主流架构演进
-
Transformer 架构:通过自注意力机制和多头注意力层实现并行化长序列处理,成为大模型(如 GPT-4、BERT)的底层支撑。
-
多模态扩展:基于 Transformer 架构整合文本、图像、语音数据,开发跨模态交互模型(如 GPT-4V)。
-
国产架构探索:针对中文场景优化分词和语义理解能力,如百度文心大模型、阿里通义千问。
2. 算法创新方向
-
预训练与微调结合:通过无监督预训练(学习通用知识)与有监督微调(适配垂直任务)提升模型泛化能力。
-
强化学习应用:引入人类反馈强化学习(RLHF),优化模型输出与人类价值观的匹配度(如 ChatGPT 的对话对齐)。
二、模型训练与优化技术
1. 训练流程与挑战
-
训练阶段:
-
预训练:基于海量无标注数据(如互联网文本、多模态数据)完成基础能力构建,参数规模达千亿级。
-
后训练:通过指令微调(Instruction Tuning)和领域适配(Domain Adaptation)提升任务执行精度。
-
-
核心挑战:
-
算力需求:单次训练需数千张 GPU 卡并行运行数周,硬件成本高昂。
-
数据瓶颈:高质量标注数据稀缺,需结合半监督学习(Self-training)和合成数据生成(Data Augmentation)突破限制。
-
2. 分布式训练策略
-
并行技术:
-
数据并行:拆分数据批次至多节点同步训练,提升吞吐量。
-
流水线并行:按模型层拆分至不同设备,减少显存占用。
-
张量并行:拆分权重矩阵至多卡,降低单卡计算压力(如 Megatron-LM)。
-
-
优化技术:
-
混合精度训练:FP16/FP32 混合计算加速训练,兼顾精度与效率。
-
梯度检查点:牺牲部分计算时间换取显存节省,支持更大批次训练。
-
3. 模型轻量化与部署优化
-
参数压缩:
-
知识蒸馏:将大模型知识迁移至小模型(如 TinyBERT),降低推理成本。
-
量化技术:将 FP32 参数压缩至 INT8,提升端侧设备运行效率。
-
-
推理加速:
-
算子融合:合并计算步骤减少内存访问延迟。
-
动态批处理:根据请求量动态调整批次大小,提高 GPU 利用率。
-
三、开发工具与平台支撑
1. 深度学习框架
-
主流框架:PyTorch、TensorFlow 提供灵活的动态图/静态图编程接口,支持快速迭代。
-
国产框架适配:华为 MindSpore、百度飞桨针对国产芯片(昇腾、寒武纪)优化分布式训练性能。
2. 一体化开发平台
-
功能集成:阿里云 PAI、华为 ModelArts 整合数据管理、模型训练、监控调试功能,降低开发门槛。
-
自动化工具:
-
超参搜索:通过贝叶斯优化自动选择最佳超参数组合。
-
模型压缩工具链:提供蒸馏、剪枝、量化的一键式压缩方案。
-
四、安全与合规管理
-
隐私保护:联邦学习实现数据不出域的多方联合建模,避免敏感信息泄露。
-
模型可解释性:引入注意力可视化工具(如 LIME)追踪模型决策依据,提升可信度。
-
伦理对齐:通过价值观对齐算法(如 Constitutional AI)约束模型输出内容。
中游核心趋势
-
低代码化:开发平台提供可视化界面,降低非技术人员的模型调优难度。
-
绿色计算:优化能耗比(如稀疏化训练),减少训练过程的碳排放。
-
开源协作:Meta、智谱 AI 等企业开源模型架构,推动技术共享与生态共建。
中游通过技术突破与工具创新,推动大模型从实验室走向规模化应用,并为下游行业提供可落地的解决方案。
三、 下游:行业应用与终端产品
大模型产业链下游聚焦行业应用与终端服务,通过技术落地实现商业化价值,覆盖医疗、金融、制造等垂直领域及智能终端设备。以下是下游核心环节与典型案例:
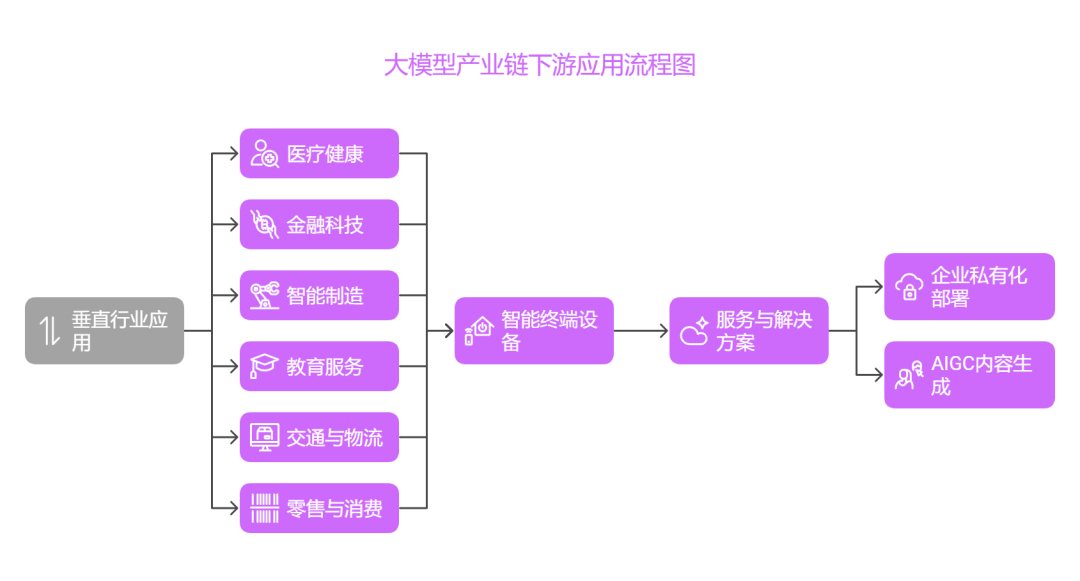
一、垂直行业应用
1. 医疗健康
-
精准诊疗:大模型支持医学影像分析(如CT/MRI病灶识别)、基因序列解读及个性化治疗方案推荐,提升诊断效率与准确性。
-
药物研发:通过分子结构模拟与化合物筛选,缩短新药研发周期(如AI预测药物毒性)。
2. 金融科技
-
智能风控:基于用户行为数据构建反欺诈模型,实时监控交易风险。
-
量化交易:利用大模型分析市场趋势,优化投资组合策略。
3. 智能制造
-
工业质检:通过视觉大模型识别产品缺陷,替代人工质检(如汽车零部件表面划痕检测)。
-
预测性维护:分析设备传感器数据,预测故障并提前维护,减少停机损失。
4. 教育服务
-
个性化学习:根据学生知识水平生成定制化习题与课程计划。
-
智能批改:自动评估作文、编程作业,提供纠错建议。
5. 交通与物流
-
自动驾驶:融合多模态数据实现环境感知与路径规划(如激光雷达与摄像头协同)。
-
智能调度:优化物流路径与仓储管理,降低运输成本。
6. 零售与消费
-
智能客服:通过自然语言处理(NLP)提供24小时商品咨询与售后支持。
-
营销推荐:分析用户偏好生成个性化广告文案与商品推荐。
二、智能终端设备
1. 消费电子产品
-
智能手机:集成大模型实现AI摄影(场景识别与图像优化)、实时语音翻。
-
AR/VR设备:结合生成式AI渲染虚拟场景,提升沉浸式体验。
2. 物联网设备
-
智能家居:语音助手(如智能音箱)控制家电、调节室内环境。
-
工业机器人:基于视觉与运动规划模型执行精密装配任务。
三、服务与解决方案
1. 企业私有化部署
-
行业定制模型:为银行、能源等行业提供私有化大模型,满足数据安全与合规需求(如金融知识库问答系统)。
-
云服务集成:通过API接口快速接入大模型能力(如阿里云智能客服解决方案)。
2. AIGC内容生成
-
创意工具:支持文案创作(如广告语生成)、视频剪辑(自动生成字幕与特效)。
-
数字人应用:驱动虚拟主播、数字员工实现交互式服务。
下游核心趋势
-
政策驱动:国家政策(如《数据安全法》)推动行业合规应用,加速医疗、政务等领域AI渗透。
-
多模态融合:跨模态大模型(如GPT-4V)支持复杂场景交互(如医疗影像+文本报告联合分析)。
-
边缘计算普及:轻量化模型适配端侧设备,实现低延迟实时推理(如智能摄像头本地化处理)。
-
开源生态协作:企业联合开发者共建行业应用生态(如开源医疗大模型社区)。
下游通过技术与场景深度融合,持续释放大模型的经济价值与社会效益,推动产业智能化升级。
如何系统的去学习大模型LLM ?
大模型时代,火爆出圈的LLM大模型让程序员们开始重新评估自己的本领。 “AI会取代那些行业?”“谁的饭碗又将不保了?”等问题热议不断。
事实上,抢你饭碗的不是AI,而是会利用AI的人。
继科大讯飞、阿里、华为等巨头公司发布AI产品后,很多中小企业也陆续进场!超高年薪,挖掘AI大模型人才! 如今大厂老板们,也更倾向于会AI的人,普通程序员,还有应对的机会吗?
与其焦虑……
不如成为「掌握AI工具的技术人」,毕竟AI时代,谁先尝试,谁就能占得先机!
但是LLM相关的内容很多,现在网上的老课程老教材关于LLM又太少。所以现在小白入门就只能靠自学,学习成本和门槛很高。
基于此,我用做产品的心态来打磨这份大模型教程,深挖痛点并持续修改了近70次后,终于把整个AI大模型的学习门槛,降到了最低!
在这个版本当中:
第一您不需要具备任何算法和数学的基础
第二不要求准备高配置的电脑
第三不必懂Python等任何编程语言
您只需要听我讲,跟着我做即可,为了让学习的道路变得更简单,这份大模型教程已经给大家整理并打包,现在将这份 LLM大模型资料 分享出来:包括LLM大模型书籍、640套大模型行业报告、LLM大模型学习视频、LLM大模型学习路线、开源大模型学习教程等, 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓

一、LLM大模型经典书籍
AI大模型已经成为了当今科技领域的一大热点,那以下这些大模型书籍就是非常不错的学习资源。

二、640套LLM大模型报告合集
这套包含640份报告的合集,涵盖了大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。(几乎涵盖所有行业)
三、LLM大模型系列视频教程

四、LLM大模型开源教程(LLaLA/Meta/chatglm/chatgpt)

五、AI产品经理大模型教程

LLM大模型学习路线 ↓
阶段1:AI大模型时代的基础理解
-
目标:了解AI大模型的基本概念、发展历程和核心原理。
-
内容:
- L1.1 人工智能简述与大模型起源
- L1.2 大模型与通用人工智能
- L1.3 GPT模型的发展历程
- L1.4 模型工程
- L1.4.1 知识大模型
- L1.4.2 生产大模型
- L1.4.3 模型工程方法论
- L1.4.4 模型工程实践
- L1.5 GPT应用案例
阶段2:AI大模型API应用开发工程
-
目标:掌握AI大模型API的使用和开发,以及相关的编程技能。
-
内容:
- L2.1 API接口
- L2.1.1 OpenAI API接口
- L2.1.2 Python接口接入
- L2.1.3 BOT工具类框架
- L2.1.4 代码示例
- L2.2 Prompt框架
- L2.3 流水线工程
- L2.4 总结与展望
阶段3:AI大模型应用架构实践
-
目标:深入理解AI大模型的应用架构,并能够进行私有化部署。
-
内容:
- L3.1 Agent模型框架
- L3.2 MetaGPT
- L3.3 ChatGLM
- L3.4 LLAMA
- L3.5 其他大模型介绍
阶段4:AI大模型私有化部署
-
目标:掌握多种AI大模型的私有化部署,包括多模态和特定领域模型。
-
内容:
- L4.1 模型私有化部署概述
- L4.2 模型私有化部署的关键技术
- L4.3 模型私有化部署的实施步骤
- L4.4 模型私有化部署的应用场景
这份 LLM大模型资料 包括LLM大模型书籍、640套大模型行业报告、LLM大模型学习视频、LLM大模型学习路线、开源大模型学习教程等, 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓

欢迎加入 MCP 技术社区!与志同道合者携手前行,一同解锁 MCP 技术的无限可能!
更多推荐


 24
24 0
0- 0



 已为社区贡献84条内容
已为社区贡献84条内容

所有评论(0)