Ubuntn系统hive的安装与搭建
如果出现错误:'hiveuser'@'localhost' (using password: YES) SQL Error code: 1045 Use --verbose for detailed stacktrace. *** schemaTool failed ***: 选择 MySQL 或 Derby 作为 Hive 元数据存储(推荐 MySQL): 已安装并配置 Hadoop 集群(HD
1. 前置条件
-
操作系统: Ubuntu 20.04/22.04(或其他版本)
-
Java: JDK 1.8+(建议使用 OpenJDK 11)
-
Hadoop: 已安装并配置 Hadoop 集群(HDFS 和 YARN 需正常运行)
-
数据库: 选择 MySQL 或 Derby 作为 Hive 元数据存储(推荐 MySQL)
2.下载并安装 Hive
hive3.1.3下载连接:https://archive.apache.org/dist/hive/hive-3.1.3/apache-hive-3.1.3-bin.tar.gz
下载完之后将压缩包复制到master服务器的下载目录中
2.1 进入压缩包所在目录
cd /home/hadoop/下载2.2 解压压缩包
tar -xzvf apache-hive-3.1.3-bin.tar.gz
2.3 移动解压后的安装包至/opt/hive
sudo mv apache-hive-3.1.3-bin /opt/hive2.4 配置环境变量
# 编辑 ~/.bashrc
vim ~/.bashrcexport HIVE_HOME=/opt/hive
export PATH=$PATH:$HIVE_HOME/bin
export HADOOP_HOME=/usr/local/hadoop # 替换为你的 Hadoop 安装路径

# 使配置生效
source ~/.bashrc3. 配置 Hive
3.1 进入 Hive 配置目录:
cd /opt/hive/conf3.2 配置 hive-env.sh
vim hive-env.shexport HADOOP_HEAPSIZE=1024
export HADOOP_HOME=/usr/local/hadoop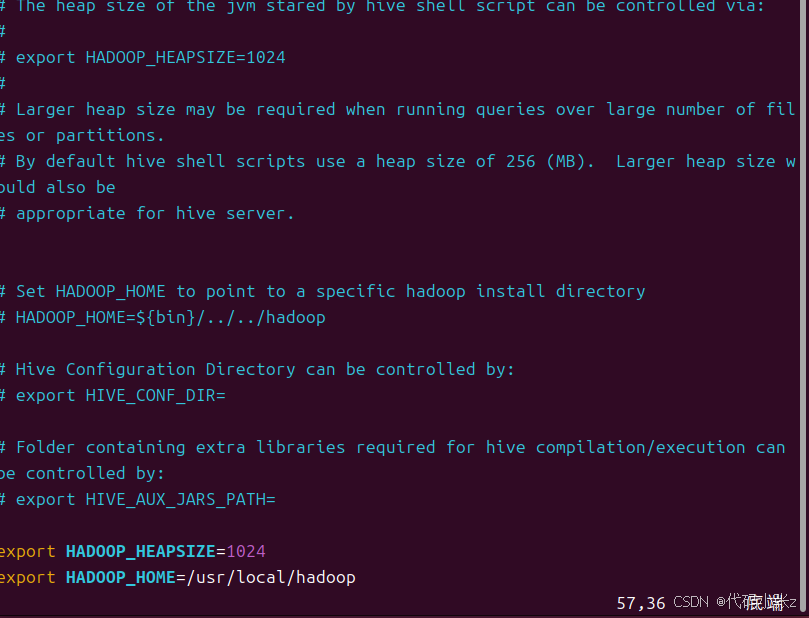
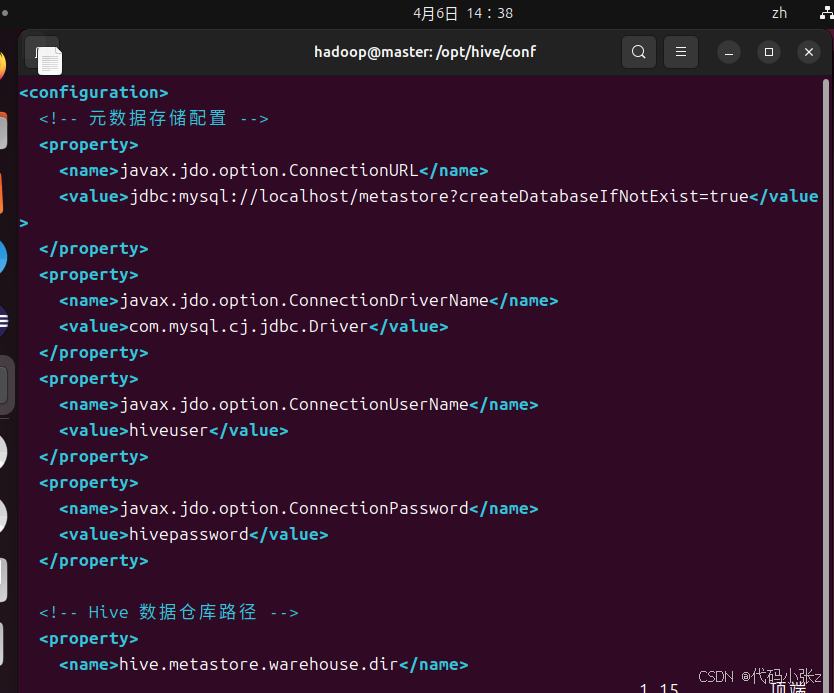
3.3 配置hive-site.xml
vim hive-site.xml<configuration>
<!-- MySQL元数据库配置 -->
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://localhost/metastore?createDatabaseIfNotExist=true&useSSL=false</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.cj.jdbc.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>hiveuser</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>111111</value> <!-- 替换为你的MySQL密码 -->
</property>
<!-- HDFS存储路径 -->
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive/warehouse</value>
</property>
<property>
<name>hive.exec.scratchdir</name>
<value>/user/hive/tmp</value>
</property>
</configuration>
4.下载 MySQL JDBC 驱动
4.1 下载驱动压缩包
wget https://dev.mysql.com/get/Downloads/Connector-J/mysql-connector-j-8.0.33.tar.gz4.2 解压压缩包
tar -xzvf mysql-connector-j-8.0.33.tar.gz
4.3 将 MySQL JDBC 驱动(如 mysql-connector-java-8.0.28.jar)复制到 $HIVE_HOME/lib:
sudo cp mysql-connector-java-8.0.28.jar /opt/hive/lib/
4.4 验证文件是否复制成功
ls /opt/hive/lib/mysql-connector-j-8.0.33.jar
5.初始化元数据库
5.1. 成功后会显示 schemaTool completed
schematool -dbType mysql -initSchema可选:
如果出现错误:'hiveuser'@'localhost' (using password: YES) SQL Error code: 1045 Use --verbose for detailed stacktrace. *** schemaTool failed ***
这个错误表明 Hive 无法连接到 MySQL 元数据库,原因是 MySQL 拒绝了用户 hiveuser 的访问权限。
5.2 确认 MySQL 用户权限
# 登录 MySQL 并检查用户:
sudo mysql -u root -p# 执行以下 SQL 查询:
-- 检查用户是否存在
SELECT User, Host FROM mysql.user;
-- 查看用户权限
SHOW GRANTS FOR 'hiveuser'@'localhost';如果用户不存在或权限不足,继续下一步。
5.3 使用 root 用户创建
-- 删除旧用户(如果存在)
DROP USER IF EXISTS 'hiveuser'@'localhost';
-- 创建新用户并设置密码
CREATE USER 'hiveuser'@'localhost' IDENTIFIED BY '111111';
-- 授予所有权限(仅限于 metastore 数据库)
GRANT ALL PRIVILEGES ON metastore.* TO 'hiveuser'@'localhost';
-- 刷新权限
FLUSH PRIVILEGES;
-- 验证权限
SHOW GRANTS FOR 'hiveuser'@'localhost';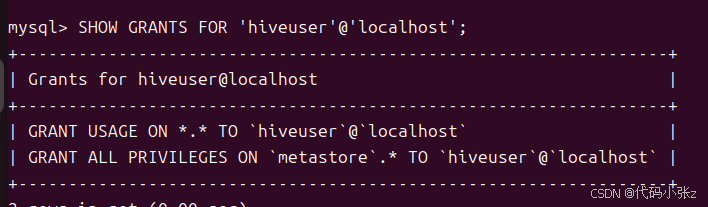
5.4 验证 MySQL 连接
手动测试用户能否连接:
mysql -u hiveuser -p -e "SHOW DATABASES;"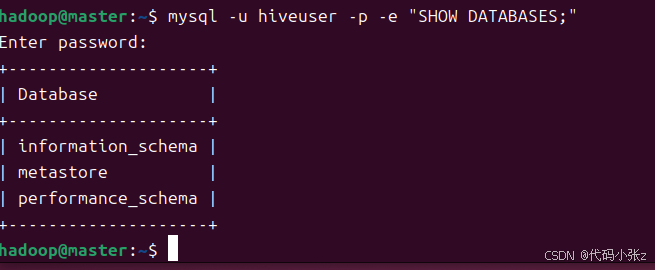
5.5 重新初始化元数据库
schematool -dbType mysql -initSchema --verbose 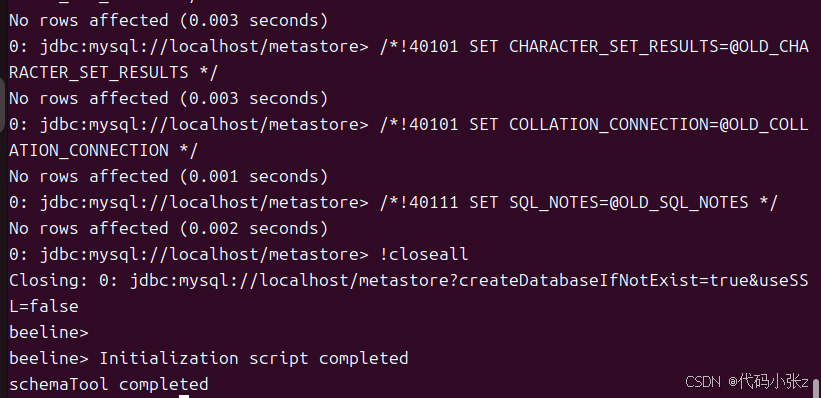
6. 启动 Hive
#启动 Hadoop 集群
start-dfs.sh
start-yarn.sh#创建 Hive 所需目录
hadoop fs -mkdir -p /user/hive/warehouse
hadoop fs -mkdir -p /user/hive/tmp
hadoop fs -chmod -R 777 /user/hive#启动 Hive CLI
hive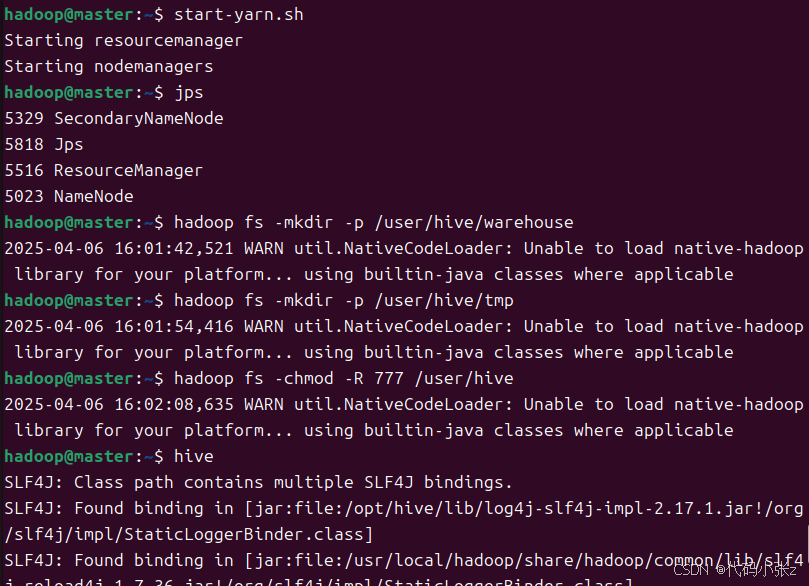
7.完整测试流程
-- 1. 创建新表(明确指定格式)
CREATE TABLE test_new (
id INT,
name STRING
) STORED AS TEXTFILE;
-- 2. 设置本地模式(测试用)
SET hive.exec.mode.local.auto=true;
-- 3. 插入数据
INSERT INTO test_new VALUES (1, 'hive-test');
-- 4. 查询验证
SELECT * FROM test_new;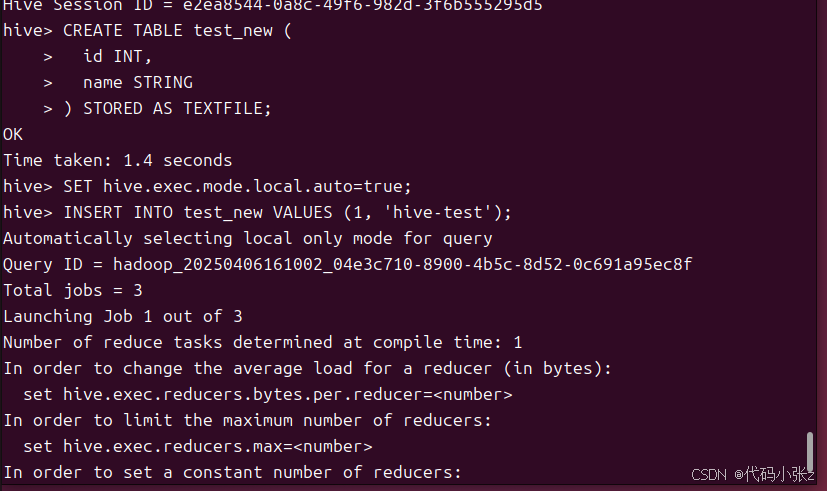
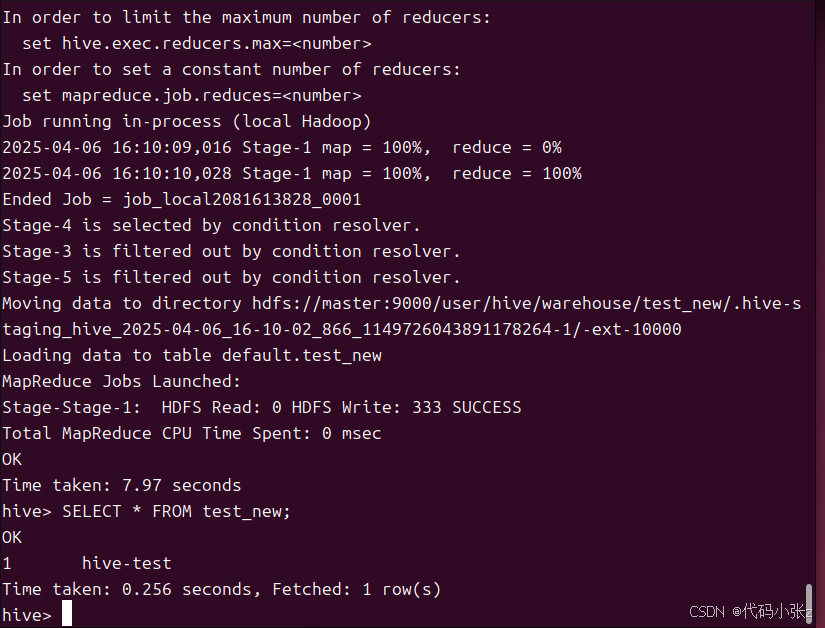
8.退出流程
8.1 退出hive
exit;8.2 退出hadoop
stop-yarn.sh
stop-dfs.sh

欢迎加入 MCP 技术社区!与志同道合者携手前行,一同解锁 MCP 技术的无限可能!
更多推荐


 23
23 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)