python so 封装_5分钟GET AI - 用 Python 玩转 YOLO
本文攻略:如何使用最先进的AI技术,识别图片和视频中的物体建议玩家等级:技术圈外人,AI零基础,学生党,初级码农阅读此文先解锁技能:命令行基础Git 基础Python 基础Python ctypes:英文党戳此链接,中国人最爱此链接几乎不需要 AI 基础实践此文推荐装备:操作系统:macOS SierraIDE:Jupyter Notebook, VSCode, Sublime, AtomPyth

本文攻略:如何使用最先进的AI技术,识别图片和视频中的物体
建议玩家等级:技术圈外人,AI零基础,学生党,初级码农
阅读此文先解锁技能:
- 命令行基础
- Git 基础
- Python 基础
- Python ctypes:英文党戳此链接,中国人最爱此链接
- 几乎不需要 AI 基础
实践此文推荐装备:
- 操作系统:macOS Sierra
- IDE:Jupyter Notebook, VSCode, Sublime, Atom
- Python v3.6
- NVIDIA 1080 Titan 显卡一块(非必需,人民币玩家可以有)
PART 1:What is YOLO
YOLO 是时下最流行(state of the art)的物体检测(Object Detection) AI 模型之一,流行的原因是因为好用,好用的标准归纳为3条:
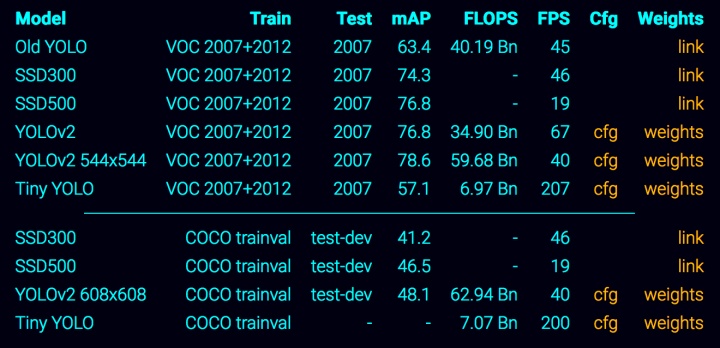
- 检测范围广:YOLO9000 覆盖了9000种常用分类,YOLOv2 覆盖了PASCAL VOC和COCO数据集分类。(说人话:就是可以检测出9000种常见物体)
- 检测准确率高
- 检测速度快:平民玩家用普通CPU就能运行低配乞丐版(Tiny YOLO),人民币玩家用GPU运行高配豪华版 (YOLOv2)。作者大神给出的参考值是 Tiny YOLO 可以达到200FPS,YOLOv2 达到40FPS,当然这是用 NVIDIA Titan X 传奇装备跑出来的分数。
PASCAL VOC 和 COCO 数据集是什么?数据集由成千上万张图片组成,AI通过学习数据集图片中包含的物体以及该物体的分类,最终能达到正确识别所有图片中的物体所属的分类。PASCAL VOC 和 COCO 是两个有名的图片物体分类数据集,同样有名的还有 ImageNet 数据集。200FPS 是什么?可以理解为一秒钟处理200张图片,普通视频24FPS肉眼就不会感到卡顿
PART 2: How to get YOLO
Step 1. Git 获取 YOLO 代码,命令行输入:
git clone https://github.com/pjreddie/darknetStep 2. 因为是用C++写的,所以需要编译下载后的 YOLO 代码,命令行输入:
cd darknet
make编译成功后,发现 darknet 根目录下多了两个文件 libdarknet.so 和 libdarknet.a,这两家伙是干什么用的?Don't worry,这是C++源码编译后的产物,在这里我们不必关心这些细节
Step 3. 下载 weights 文件
YOLO作者大神已经为我们准备好了YOLO不同的版本,先下载其中两个最具代表版本 Tiny YOLO(低配乞丐版) 和 YOLOv2(高配豪华版),每一个版本都由两个文件配对组成
cfg 文件:模型参数配置文件。该文件已经随源代码一起下载下来,保存在cfg目录。
weights 文件:模型学习好的权重文件。该文件较大,因为文件里面包含了从数据集中学习到的海量“知识”,这些“知识”正是AI之所以“聪明”的原因,需另外下载。为了方便管理我都保存在 weights 目录。
猛击下载 tiny-yolo.weights
猛击下载 yolo.weights
PART 3: How to use YOLO
完成 PART 2 后,来看看YOLO究竟有多Cool,先来识别2张作者大神提供的官方图片。
先试试高配豪华版 YOLOv2,运行过程会有点慢,但准确率很高,命令行输入:
./darknet detect cfg/yolo.cfg weights/yolo.weights data/dog.jpg再试试低配乞丐版 Tiny YOLO,运行过程很快,以损失一些准确率作为代价,命令行输入:
./darknet detect cfg/tiny-yolo.cfg weights/tiny-yolo.weights data/dog.jpg运行后,命令行输出的信息包含:神经网络(没错,就是用这个很炫酷的东西实现的)模型每一层的参数,最终的分类结果和分类结果自信度(0.81可以理解为81%概率属于该分类)。(这部分看不懂的玩家可以自行忽略,其实很重要的喂!)
在 darknet 根目录下会生成一张结果图片 predictions.png,操作不太友好的是识别不同图片永远都只会生成同一个结果图片文件名,并且覆盖之前的结果图片。


此处应有掌声,很多玩家会“Wow!“一声,感叹AI的强大
PART 4 章节为码农必修,小白选修
PART 4: Make your hands dirty
PART 3 的2张结果图片引发了一系列思考:
这么Cool的应用能不能应用到视频检测?
这么Cool的应用我该怎么拿来调用,让我的产品智商向阿法狗看齐?
......接下来我们要做的,就是撸起袖子敲代码
Step 1. 封装YOLO
调用YOLO的原理本质是调用 PART 2 编译好的库文件 libdarknet.so 里的方法。Python ctypes(详见技能4)能帮助我们使用Python调用C++库里的方法,这里还是要感谢作者大神已经为我们写好了 python/darknet.py,该文件的作用是把YOLO库中的C++方法一一翻译成Python方法并封装成Python模块,让我们完全可以忽略C++部分,只需要实现调用Python方法即可。
Step 2. 检测图片
站在大神的肩膀上,只敲了6行Python代码,就能检测任意图片了
import python.darknet as dn
dn.set_gpu(0)
net = dn.load_net(str.encode("cfg/tiny-yolo.cfg"),
str.encode("weights/tiny-yolo.weights"), 0)
meta = dn.load_meta(str.encode("cfg/coco.data"))
r = dn.detect(net, meta, str.encode("data/dog.jpg"))
print(r)运行结果:
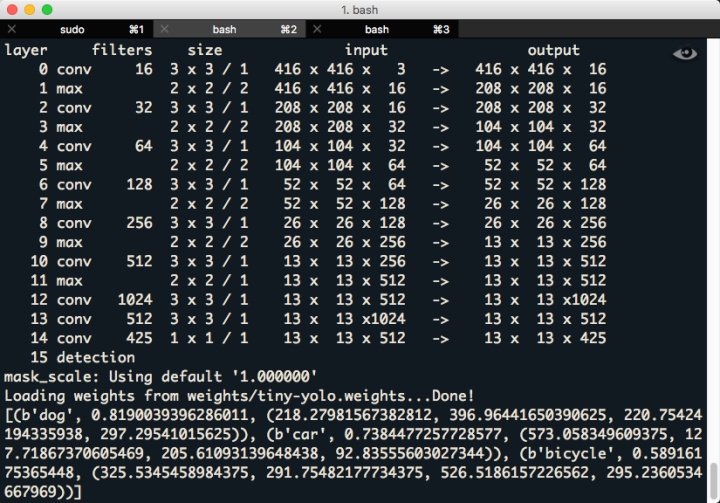
注意几点:
- Python2使用原始字符串"cfg/tiny-yolo.cfg",Python3必须使用str.encode("cfg/tiny-yolo.cfg")进行字符串格式转换,因为2个版本的Python字符串数据结构有差异,作者大神封装的API是Python2版本,需要向下兼容
- 我的本子只有CPU,所以这里用了低配乞丐版 Tiny YOLO 保证运行速度,GPU玩家可以根据自己的情况替换 cfg 和 weights 文件。(贫穷限制了AI的运算能力)
- meta 是数据集分类配置文件,因为使用的 cfg 和 weights 文件是基于COCO数据集训练的,所以检测的分类结果也得对应COCO数据集分类结果
- 输出结果 r 是一维数组 [(物体1), (物体2), (物体3)],代表了一共检测到几个物体,每个物体均包含以下信息:(分类名称, 分类自信度, (物体中心x, 物体中心y, 物体宽度, 物体高度))
Step 3. 视频实时检测
视频的每一帧本质是一张图片,所以我们设计了一个处理管道(func pipeline)循环处理每一帧图片:
1)输入待处理图片(img)
2)使用YOLO检测,并获得检测结果(result)
3)在待处理图片(img)上画出检测结果(result),生成最终图片(img_final)
4)输出最终图片(img_final)
def pipeline(img):
# image data transform:
# img - cv image
# im - yolo image
im = array_to_image(img)
dn.rgbgr_image(im)
result = detect(net, meta, im)
print(result)
img_final = draw_boxes(img, result)
return img_final主程序使用 OpenCV 调用摄像头,并从摄像头获取视频流,按'q'退出主程序
import numpy as np
import cv2
count_frame, process_every_n_frame = 0, 1
# get camera device
cap = cv2.VideoCapture(0)
while(True):
# get a frame
ret, frame = cap.read()
count_frame += 1
# show a frame
img = cv2.resize(frame, (0, 0), fx=0.5, fy=0.5) # resize image half
cv2.imshow("Video", img)
# if running slow on your computer, try process_every_n_frame = 10
if count_frame % process_every_n_frame == 0:
cv2.imshow("YOLO", pipeline(img))
# press keyboard 'q' to exit
if cv2.waitKey(1) & 0xFF == ord('q'):
break
cap.release()
cv2.destroyAllWindows()-->附赠完整代码攻略,猛戳下载<--
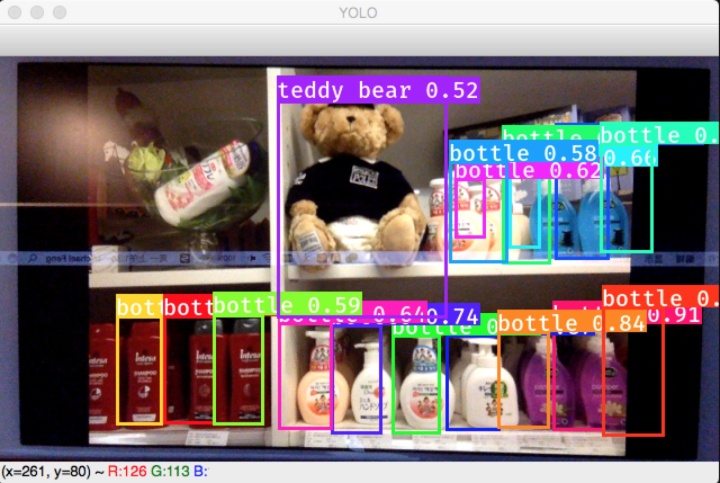
此刻掌声应再次响起,可以打开手机相册对着摄像头多检测一些图片,恭喜你创造了一个连泰迪熊和单身狗也能准确识别的AI,这还只是CPU配Tiny YOLO的结果,如果用GPU搭配YOLOv2,AI表现会更理想
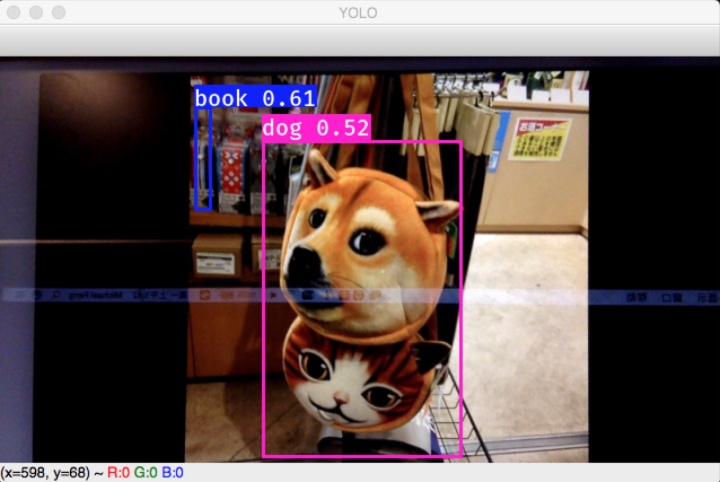
PART 5: Use YOLO in our life
常见的YOLO可使用场景例如:
- 停车场的车牌自动识别
- 相机的人脸自动识别
- 无人驾驶的车辆、行人和交通标志识别
- 商场和街道的人流、车流检测统计
PART FINAL: 更多攻略,Have fun!
想要了解 YOLO 工作原理,穿越去 5分钟学会AI - How YOLO only look once
想要了解 YOLO 核心技术,穿越去 5分钟学会AI - Convolution Neural Network in YOLO
YOLO Official
Keras 也能用 YOLO: YAD2K - Yet Another Darknet 2 Keras
iPhone 也能用 YOLO: YOLO with Core ML
如需合作或转载请联系本文作者,跪谢

欢迎加入 MCP 技术社区!与志同道合者携手前行,一同解锁 MCP 技术的无限可能!
更多推荐


 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)