多模态大模型综述《A Survey on Multimodal Large Language Models》
在单模态的基础上,加了新的模态,encoder后,通过mlp或者其他方式与text对齐,再输入大模型。如果需要生成新的膜套,可以再通过生成器。(此处与SD不太一样),chatGPT不会生成图片,可以对图片进行理解。LLM 辅助的视觉推理:利用 LLM 强大的内嵌知识与能力,并借助其他工具,设计各种视觉推理系统,解决各种现实问题。多模态幻觉:可以增加图像分辨率、提高数据质量,图像token表征、图像
·
架构图
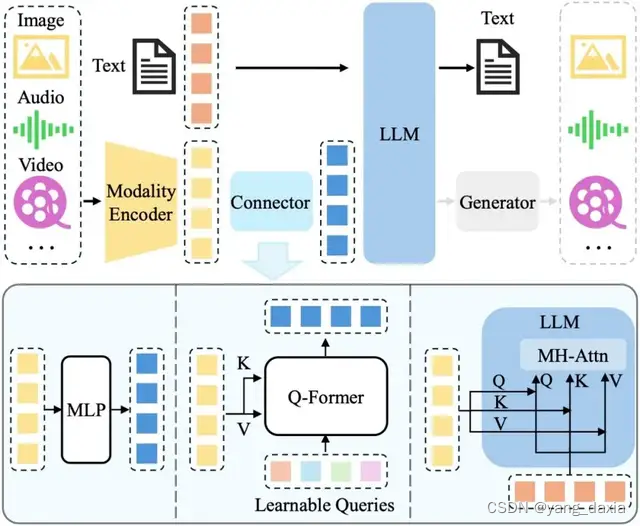
在单模态的基础上,加了新的模态,encoder后,通过mlp或者其他方式与text对齐,再输入大模型。如果需要生成新的膜套,可以再通过生成器。(此处与SD不太一样),chatGPT不会生成图片,可以对图片进行理解。
训练方式
一般多个阶段。预训练、指令微调、对齐微调(RLHF)。
- 预训练是通用能力。使得图像对齐到llm表征空间,数据来源于互联网上的图像对。
- 指令微调是专业能力,提升在下游任务上的性能。数据来源于VQA、OCR、目标检测等数据
- 对齐微调是纠错能力,类似LLM通过强化学习、人工打分排序,使得输出符合人类要求
其他技术方向
多模态幻觉:可以增加图像分辨率、提高数据质量,图像token表征、图像文本的对齐方式等
多模态上下文学习:Flamingo通过在图文交错的数据上训练来提升模型关注上下文的能力。
多模态思维链:将复杂的问题分解为较简单的子问题,然后分别解决并汇总。
LLM 辅助的视觉推理:利用 LLM 强大的内嵌知识与能力,并借助其他工具,设计各种视觉推理系统,解决各种现实问题。
https://www.qbitai.com/2024/04/134649.html

欢迎加入 MCP 技术社区!与志同道合者携手前行,一同解锁 MCP 技术的无限可能!
更多推荐


 4
4 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)