视觉-语言-动作大模型openvla详解
最近在看具身智能领域一些代表性的模型,openvla是2024年中出的一个vla模型,详细的学习了一下,这个文章在工程实现方面写得还是非常详尽的(代码中的README和论文本身),包括环境安装,全量微调,lora微调,模型格式转换,甚至在效果不好时如何一步一步排查也写了,感觉作者是很用心的,值得我们学习。openvla模型比较经典,网络上的解读文章也比较多了,我在文末也列了2个,仅供参考。简单来说
最近在看具身智能领域一些代表性的模型,openvla是2024年中出的一个vla模型,详细的学习了一下,这个文章在工程实现方面写得还是非常详尽的(代码中的README和论文本身),包括环境安装,全量微调,lora微调,模型格式转换,甚至在效果不好时如何一步一步排查也写了,感觉作者是很用心的,值得我们学习。
openvla模型比较经典,网络上的解读文章也比较多了,我在文末也列了2个,仅供参考。简单来说,这个模型输入就是一个prompt和pic(vla中的vl),输出就是一个指令(vla中的a)。通过互联网海量数据预训练出来的base模型,提供较好的泛化性,然后用少量具身智能领域少量的数据finetune,以满足机器人场景的功能。
本文将核心的代码或过程进行关键性的解读。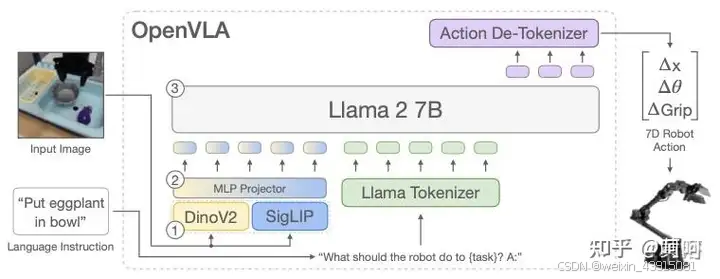
环境安装:建议按readme中的步骤进行安装,不会有问题。
1,Getting Started
本节通过一个简单的样例,具体的展现openvla的输入输出,让大家直观的看到这个模型干了啥。
直接可以运行vla-scripts/deploy.py就可以,我对这个文件作了小量修改如下,就是把代码中的http服务去掉,直接输入了一帧prompt和pic,进行前向推理。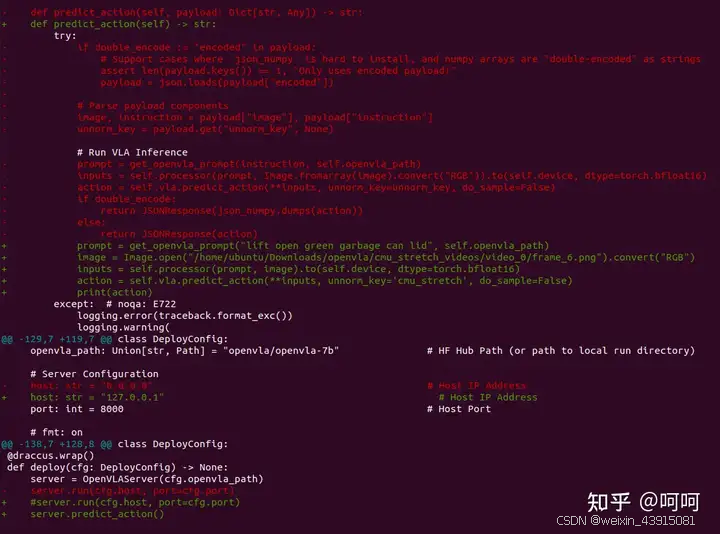
输入的prompt如下:
'In: What action should the robot take to lift open green garbage can lid?Out:'
通过processor类处理,首先通过tokenizer就上面的文字转换成id,其次通过图片vision backbone将图片resize, crop,norm等转换后,形成(1,6,244,244)的tensor,为什么第二个维度是6呢,是因为有2个vision backbone(融合DINOv2和 SigLIP 预训练特征的视觉编码器),每个backbone都有自己的前处理,所以合在一起就是3+3=6

最终输出:
[-4.87820307e-05 0.00000000e+00 5.41602040e-03 0.00000000e+00
0.00000000e+00 0.00000000e+00 9.96078431e-01]
可以看到输出是一个七维的action。这七维分别代表机器人末端机构的xyz坐标和roll pitch yaw角度,还有一个末端机构开合的程度。例如,针对cmu_stretch数据集(Open X-Embodiment数据集中的一个子集)是这样定义的:Robot action, consists of [3x ee pos, 3x ee rot 1x gripper binary action]。ee就是end effector。文章的作者将Open X-Embodiment数据集进行了统一的处理转换,形成了这七维通用的描述。
在模型训练时,作者将不同数据集进行打平,怎么打平呢,例如针对roll来说,A数据集的范围是从-0.2~0.2, B数据集的范围是-0.3~0.3,将每个数据集的min~max中间的值均分为255等分(就是代码中的bin的概念),如果某一帧的值是roll=0,那么就落在了第128个bin中。
llama默认的tokenizer中的token是32000个,作者使用了最后的255个代表action(不包含最后一个32000),上面所说的第128个bin的id=31872,[31872-127, 31872+127]即[31745, 31999]共255个id,代表action的取值。如果某一帧七个维度都是0,那么就是[31872,31872,31872,31872,31872,31872,31872],也就是label是[31872,31872,31872,31872,31872,31872,31872]。
总结一下,一帧prompt和pic输入后,会固定输出7维的action,通过这7个token的id,反解析出具体的数值。
action = self.vla.predict_action(**inputs, unnorm_key='cmu_stretch', do_sample=False)
可以看到,在推理的时候指定了一个数据集的名称(例:cmu_stretch),每个数据集都会有一些action的统计信息,例如min,max等,结合上面的token的id,就可以解析出适配这个数据集的action的数值,可以直接下发给机器人,上面示例中的action值就是可直接下发给机器人的数值。
前向推理gpu需要15G左右的显存。
数据集的可视化,下面这篇文章讲得较好,可参考。
2,finetune
通过lora微调
官方也建议这个方式,可以有效的减少对资源的要求,我在本地的一个3090上,batchsize=2,显存占用21.7G,因为共76亿参数量,通过lora训练的只有1.44%,可以大大的减少对资源的需求,效果也不差。
核心就是通过hf的peft库,再配合torch官方的ddp分布式训练,感觉使用起来对代码的改造量并不大。
全量微调
全量对资源的需求较高,下面图是全量微调仅仅把代码跑起来,我用了autodl上5个32g的GPU,bs=2*5=10,再调大就显存不够了。
当然,官方代码也提供了冻结部分模块,例如vision backbone,llm的最后一层等,相应的可以减少资源需求。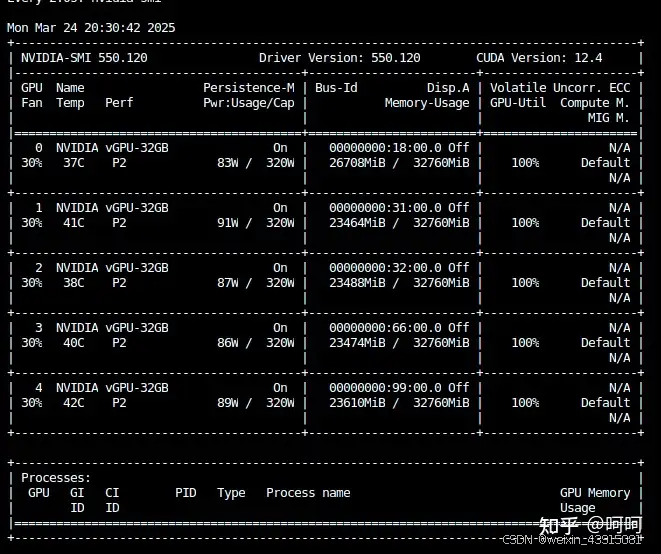
全量微调作者使用了torch官方的FSDP分布式训练能力,经过初步调研,FSDP=zero3级别,FSDP可能并没有deepspeed等第三方的库好用,稳定性上也差一些,对正常代码的侵入也比较多一些,所以精力有限的情况下,后续感觉还是重点研究学习deepspeed较好。个人想法,不对请批评指正。
finetune这块写得并不多,后续再补充一些详细的内容,大家想了解什么信息,可以评论区留言。这2种模式我都跑过,也都读过它们的代码,感觉确实lora方式代码更清爽一些。
3,将Prismatic模型转为hf格式:
补充:为什么样会有格式转换呢,参考:视觉-语言-动作大模型openvla类图
将训练时的checkpoint格式的模型转换成hf格式的,checkpoint格式如下,核心就是pt格式的,附带一些配置文件,例如config.json,可以从训练过程中得到,也可以直接从hf上下载一个(openvla/openvla-7b-prismatic)用于测试,大小29G。
├── README.md -> ../../blobs/307c4566c5ed62c39e3d0acea3de9d6722e764d3
├── checkpoints
│ ├── latest-checkpoint.pt -> step-295000-epoch-40-loss=0.2200.pt
│ └── step-295000-epoch-40-loss=0.2200.pt -> ../../../blobs/2c2497cd9e0ecced65e54b0771172f22e3ed64d0c0af339e094349715d3b3602
├── config.json -> ../../blobs/50e13ac3ece0ce029e891655593584c8330d2776
├── config.yml -> ../../blobs/f41279b2fd739ee42de3d586896b74eb97b307db
├── dataset_statistics.json -> ../../blobs/a1ea5b6edd45f2eeabcb498d98693de4e1450294
└── run-metrics.jsonl -> ../../blobs/300de24a49c2d94c12fd8256bc256d5b5f5e455a
运行脚本进行转换:
python vla-scripts/extern/convert_openvla_weights_to_hf.py --openvla_model_path_or_id /root/autodl-tmp/huggingface_cache/hub/models--openvla--openvla-7b-prismatic/snapshots/5e44aaf23f992e150f26b257500144225ab6643b --output_hf_model_local_path convert2hf/
转换后就生成了下面一个文件列表,哪些文件由哪行代码生成,已经写在注释中了。其中preprocessor_config.json是一些图片的前处理配置,就将图片crop, resize, norm等处理流程,hf的auto类加载模型时,会通过这个生成的配置文件来初始化图片前处理模块。hf_processor类中包含2个成员,一个是vision backbone,一个是tokenizer,vision backbone参数已经在模型文件中了,没有生成单独的文件,tokenizer生成了5个文件。
模型转换需要内存50G以上,内存不足会被kill
# 下面六个文件是通过代码:hf_model.save_pretrained(cfg.output_hf_model_local_path, max_shard_size="7GB")生成的
-rw-r--r-- 1 root root 60554 Mar 24 23:33 config.json
-rw-r--r-- 1 root root 136 Mar 24 23:33 generation_config.json
-rw-r--r-- 1 root root 6948961960 Mar 24 23:34 model-00001-of-00003.safetensors
-rw-r--r-- 1 root root 6971232040 Mar 24 23:34 model-00002-of-00003.safetensors
-rw-r--r-- 1 root root 1162406824 Mar 24 23:34 model-00003-of-00003.safetensors
-rw-r--r-- 1 root root 94764 Mar 24 23:34 model.safetensors.index.json
# 下面一个文件通过代码生成:hf_image_processor.save_pretrained(cfg.output_hf_model_local_path)
-rw-r--r-- 1 root root 1492 Mar 24 23:35 preprocessor_config.json
# 下面5个文件通过代码生成:hf_processor.save_pretrained(cfg.output_hf_model_local_path)
-rw-r--r-- 1 root root 552 Mar 24 23:35 special_tokens_map.json
-rw-r--r-- 1 root root 1842976 Mar 24 23:35 tokenizer.json
-rw-r--r-- 1 root root 499723 Mar 24 23:35 tokenizer.model
-rw-r--r-- 1 root root 1108 Mar 24 23:35 tokenizer_config.json
-rw-r--r-- 1 root root 21 Mar 24 23:35 added_tokens.json
# 下面1个文件通过代码生成:output_dataset_statistics_json = cfg.output_hf_model_local_path / "dataset_statistics.json"
-rw-r--r-- 1 root root 53393 Mar 24 23:37 dataset_statistics.json
参考文章:

欢迎加入 MCP 技术社区!与志同道合者携手前行,一同解锁 MCP 技术的无限可能!
更多推荐


 37
37 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)