大模型微调入门指南
大模型微调是指在预训练模型(已学习海量通用知识)的基础上(可以理解为大厂开源模型即经过预训练的通用大模型),通过少量领域数据进一步训练,使模型适应特定任务(如医疗问答、法律文本分析等)。这一过程会调整模型参数,强化其在目标领域的表现。微调 vs 预训练预训练:耗费数千块GPU、学习通用语言模式(如语法、常识)。微调:仅需少量GPU、耗时几小时至几天,聚焦特定任务优化(如情感分类)。一、模型微调的核
什么是大模型微调?
大模型微调是指在预训练模型(已学习海量通用知识)的基础上(可以理解为大厂开源模型即经过预训练的通用大模型),通过少量领域数据进一步训练,使模型适应特定任务(如医疗问答、法律文本分析等)。这一过程会调整模型参数,强化其在目标领域的表现。
微调 vs 预训练
预训练:耗费数千块GPU、学习通用语言模式(如语法、常识)。
微调:仅需少量GPU、耗时几小时至几天,聚焦特定任务优化(如情感分类)。
一、模型微调的核心分类
1. 全参数微调(Full Fine-tuning)
原理:更新模型所有参数,使其完全适应新任务。
适用场景:
任务与预训练目标差异大(如从语言生成转向文本分类)。
有充足标注数据和计算资源。
优缺点:
优点:性能最佳,适配性强。
缺点:计算成本高,容易过拟合,显存占用大。
2. 参数高效微调(PEFT)
核心思想:仅更新少量参数,减少计算和显存需求。
常见方法:
(1) LoRA(Low-Rank Adaptation)
原理:通过低秩分解模拟参数变化,仅更新少量低秩矩阵(如ΔW.x)。
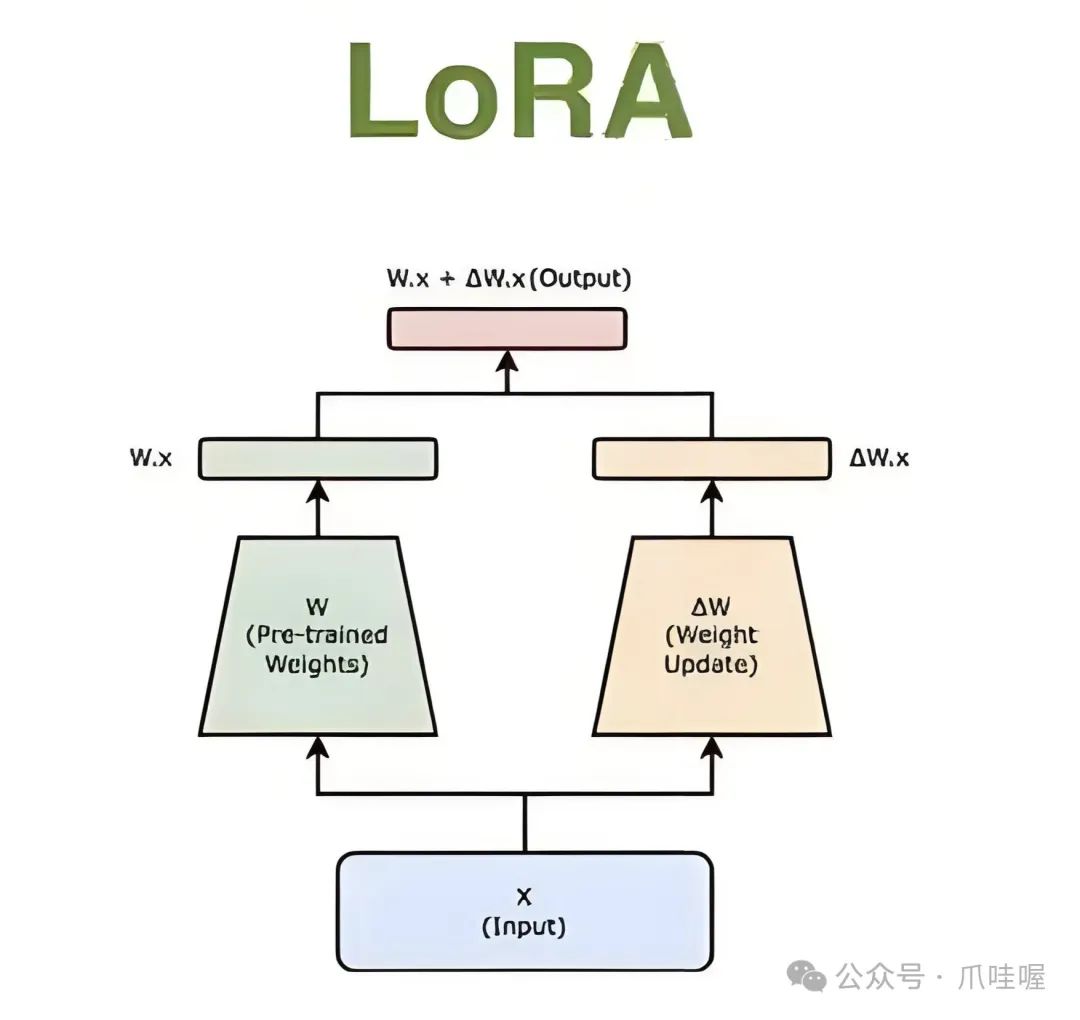
适用场景:资源有限但需高性能(如本地部署大模型)。
优点:参数量减少90%以上,显存占用低。
(2) Adapter Tuning(适配器微调)
原理:在模型层间插入轻量级适配器模块(如瓶颈结构的全连接层)。
适用场景:需快速适配且数据量小的任务(如领域迁移)。
优点:适配器参数独立,可复用预训练模型。
(3) Prefix Tuning(前缀微调)
原理:引入任务特定的前缀向量,与输入拼接后输入模型。
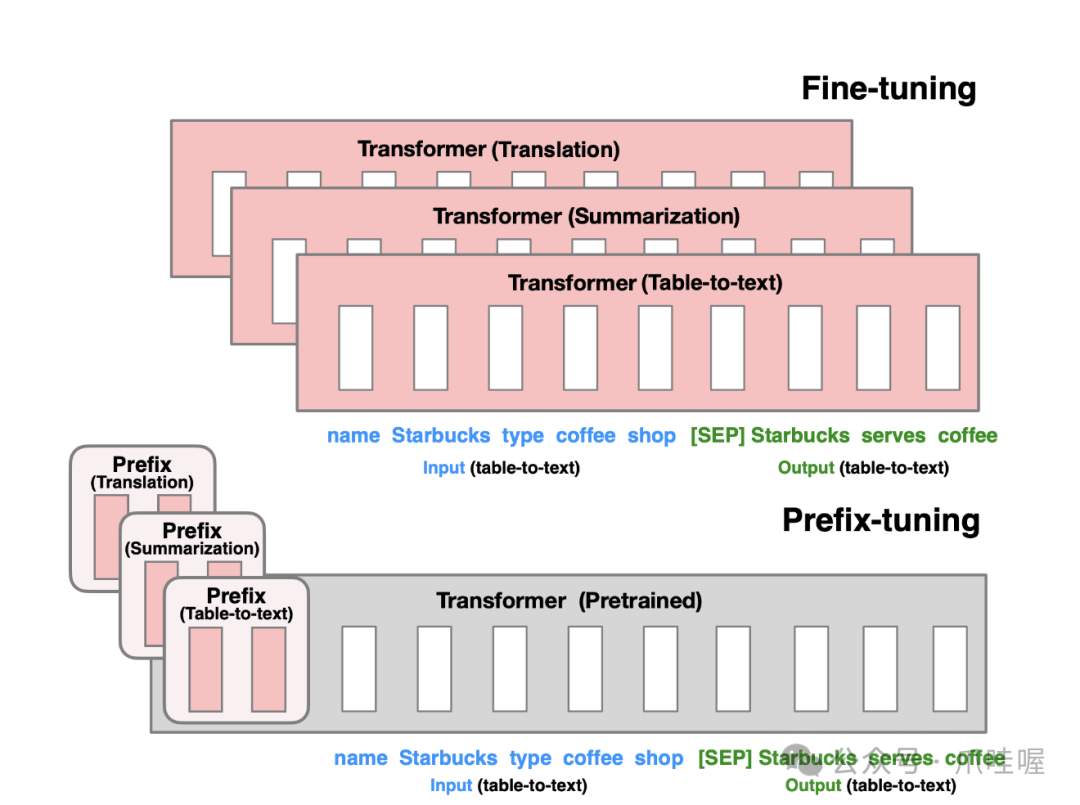
如上图:
Fine-tuning(微调):更新模型的所有参数(红色的Transformer块),需要为每个任务存储整个模型。
Prefix-tuning(前缀微调):冻结模型参数,仅优化前缀(红色的前缀块),只需为每个任务存储前缀参数。
适用场景:无需修改模型结构,适合生成任务(如对话系统)。
变体:P-tuning v2使用离散词嵌入表示前缀。
(4) QLoRA(量化+LoRA)
原理:结合模型量化(如4-bit)和LoRA,进一步降低显存需求。
适用场景:在边缘设备部署超大规模模型(如笔记本或移动设备)。
3. 冻结层微调(Frozen Layers Fine-tuning)
原理:仅更新模型顶层参数,冻结底层参数。
适用场景:任务与预训练任务相似(如文本分类)。
优点:计算成本低,保留底层特征。
4. 强化学习微调(RLHF)
原理:结合监督微调(SFT)和强化学习,通过人类偏好优化输出。
适用场景:需要符合人类价值观的任务(如对话系统、内容生成)。
步骤:
SFT阶段:用标注数据训练模型。
奖励模型:用人类反馈数据训练奖励模型。
强化学习:最大化奖励评分。
缺点:需要大量人类标注数据,计算复杂。
5. 混合专家微调(MoE + PEFT)
原理:将轻量级PEFT适配器作为混合专家模型的专家模块。
适用场景:需平衡参数效率和模型容量的任务(如多任务学习)。
优点:仅更新0.32%的参数,显著降低计算成本。
6. 无监督微调(如UPFT)
原理:通过初始词元(前缀)引导推理,无需标注数据。
适用场景:数据稀缺但需快速生成(如数学问题求解)。
二、适合个人用户的微调方式推荐
根据个人资源(计算能力、数据量、硬件条件),以下是推荐方案:
1. 资源有限(显存小/数据少)
推荐方法:LoRA + QLoRA
原因:
LoRA仅更新少量参数,显存占用低(如32B模型可用12GB显存)。
QLoRA结合量化,适合笔记本或轻量级GPU(如RTX 3060)。
适用场景:本地部署推理或小规模微调(如问答系统)。
2. 数据充足但计算资源一般
推荐方法:Adapter Tuning + 冻结层微调
原因:
Adapter插入轻量模块,冻结底层参数,减少计算量。
适合文本分类、情感分析等任务。
3. 需要高质量生成(如对话系统)
推荐方法:RLHF(简化版)
原因:
通过人类反馈优化输出质量,但需简化步骤(如用小奖励模型)。
可结合LoRA降低参数量,如C-RLFT框架)。
4. 无标注数据
推荐方法:Prefix Tuning + UPFT
原因:
通过设计任务相关的前缀(如“请解决数学问题:”)引导生成。
无需标注数据,适合推理任务。
5. 预训练模型为代码/多模态
推荐方法:混合专家(MoE) + PEFT
原因:
在代码或多模态模型中,MoE可灵活适配不同任务。
仅更新少量参数,适合资源有限的场景。
三、关于模型微调后问题
3.1 会生成独立的新模型
微调后的模型会保存为独立文件(如PyTorch的`.bin`文件),与原始预训练模型完全解耦,可单独部署。
3.2 部署灵活性
本地部署:支持导出为ONNX或TensorRT格式加速推理。
云端部署:可通过AWS SageMaker、Hugging Face Inference API等服务托管。
限制:需遵守模型许可证(如LLaMA不可商用),硬件需匹配计算需求(如GPU显存)。
3.3 微调后对ReAct、RAG有什么影响 ?
1 增强ReAct的任务分解能力
ReAct(Reasoning + Acting) 依赖模型的任务规划能力。通过微调注入领域知识后,模型能更精准地拆解复杂问题(如将“分析财报”分解为“计算利润率→对比行业基准”)。
2 优化RAG的检索适配性
RAG
(Retrieval-Augmented Generation)中,微调可让模型更高效地利用检索到的文档。例如在医疗场景中,模型能更准确识别检索结果中的关键症状描述。
3.4 注意事项
(1) 微调后的模型可能需要调整ReAct的提示模板。
(2) RAG的检索器(如ElasticSearch)是否需要同步优化,取决于领域数据的专业程度。
四、新手实践建议
1. 从小数据集开始:先尝试100-1000条数据,验证训练流程。
2. 使用Hugging Face生态:利用[TRL](https://huggingface.co/docs/trl)、[PEFT](https://github.com/huggingface/peft)等库简化代码。
3. 监控训练损失:若损失值不下降,可能是学习率过高或数据噪声过大。

大模型&AI产品经理如何学习
求大家的点赞和收藏,我花2万买的大模型学习资料免费共享给你们,来看看有哪些东西。
1.学习路线图

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
2.视频教程
网上虽然也有很多的学习资源,但基本上都残缺不全的,这是我自己整理的大模型视频教程,上面路线图的每一个知识点,我都有配套的视频讲解。


(都打包成一块的了,不能一一展开,总共300多集)
因篇幅有限,仅展示部分资料,需要点击下方图片前往获取
3.技术文档和电子书
这里主要整理了大模型相关PDF书籍、行业报告、文档,有几百本,都是目前行业最新的。

4.LLM面试题和面经合集
这里主要整理了行业目前最新的大模型面试题和各种大厂offer面经合集。

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。

1.AI大模型学习路线图
2.100套AI大模型商业化落地方案
3.100集大模型视频教程
4.200本大模型PDF书籍
5.LLM面试题合集
6.AI产品经理资源合集***
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓


欢迎加入 MCP 技术社区!与志同道合者携手前行,一同解锁 MCP 技术的无限可能!
更多推荐


 24
24 0
0- 0



 已为社区贡献138条内容
已为社区贡献138条内容

所有评论(0)