大模型项目注意事项与成本核计随笔记
大模型项目注意事项与成本核计随笔记
文章目录
1 大模型的成本与耗时间的地方
1.1 成本形式1:调用已知的API的成本
如果你的项目是调用大厂的API,这块的成本就会必不可少
- 一个汉字约等于 2 个 token
- OpenAI GPT 4 Turbo 的价格是:输入$0.01/K token,输出$0.03/K token
总结 5000 字的文章总金额 = 0.01 ✖️ 输入 token 数/1000 + 0.03 ✖️ 输入 token 数/1000 = $0.13
1.2 私有部署,训练成本与训练数据
如果你要自己训练模型,那么肯定不会是训练一次到完美模型,然后就直接上线。通常花个个把月,很正常,而且这过程中,大多数需要反正折腾训练数据,好的数据是制胜关键,后续才是调参等等。
这是文章【做大模型AI应用一定要了解的成本计算公式】总结的训练成本:
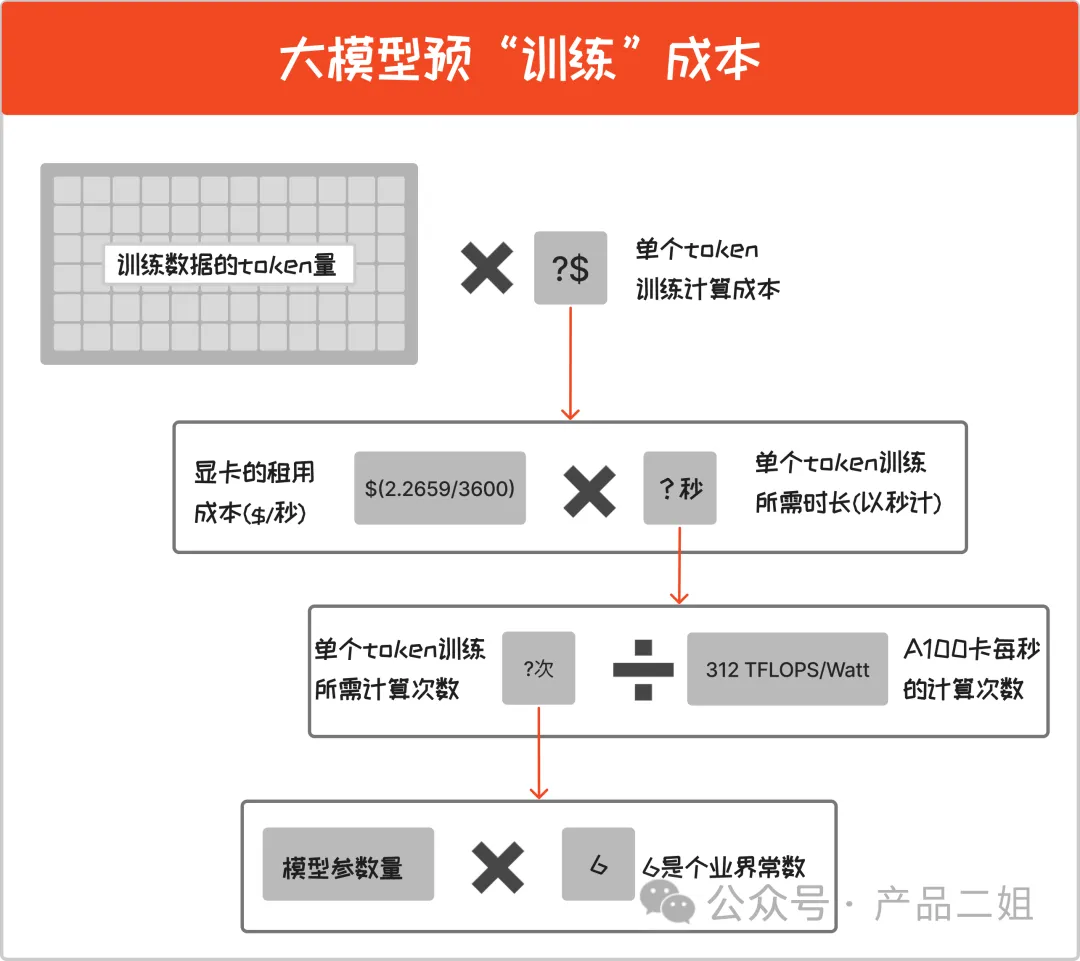
预训练成本 = ( 模型参数量 ✖️ 6 /A100 卡每秒的计算次数) ✖️ 显卡的租用成本 ✖️ 训练数据的 token 量
此时公众号作者给出的预估:
- GPT3 的参数量是 175B,训练数据的 token 量 500B,约 105 万美元*5 折,约 372.75 万元。
- GPT4 的参数量是 1800B,训练数据的 token 量 13T, 费用是 GPT3 的 280 倍,约 1.45 亿美元,人民币 10 亿元。
- GPT4 Turbo 的参数量是 8*222B ,训练数据的 token 量 13T,费用与 GPT4 差不多
关于数据方面, 参考文献心法利器[119] | 大模型落地困境讨论与解决思路可以有一些经验之谈:
数据匮乏下:
- 不微调的大尺寸,例如72b左右级别,效通过prompt或者in-context learning之类的手段,会有个还不错的baseline。
- 微调大尺寸的成本不低(回归到成本问题),而且大尺寸做小任务也觉得不划算,也难以收敛。
- 微调14b或者6b左右的档位,数据会显得不太足够,收敛可能会过拟合,微调后的效果可能和bert之类的拉不开距离。
数据比较充裕的场景:
- 微调,大尺寸做小任务会觉得很亏,无论是训练还是后续的部署成本。
- 不微调的大尺寸往往已经比不过14b甚至6b微调的版本了,大尺寸模型的位置就比较尴尬。
- 到了0.3B-0.5B的级别,其实就是上个版本所谓的large级别,可能会和6B左右差1-3个点,这个差距在论文里肯定是天差地别,不过在实际应用中,就不得不加入成本的因素了。
1.3 私有部署,推断成本
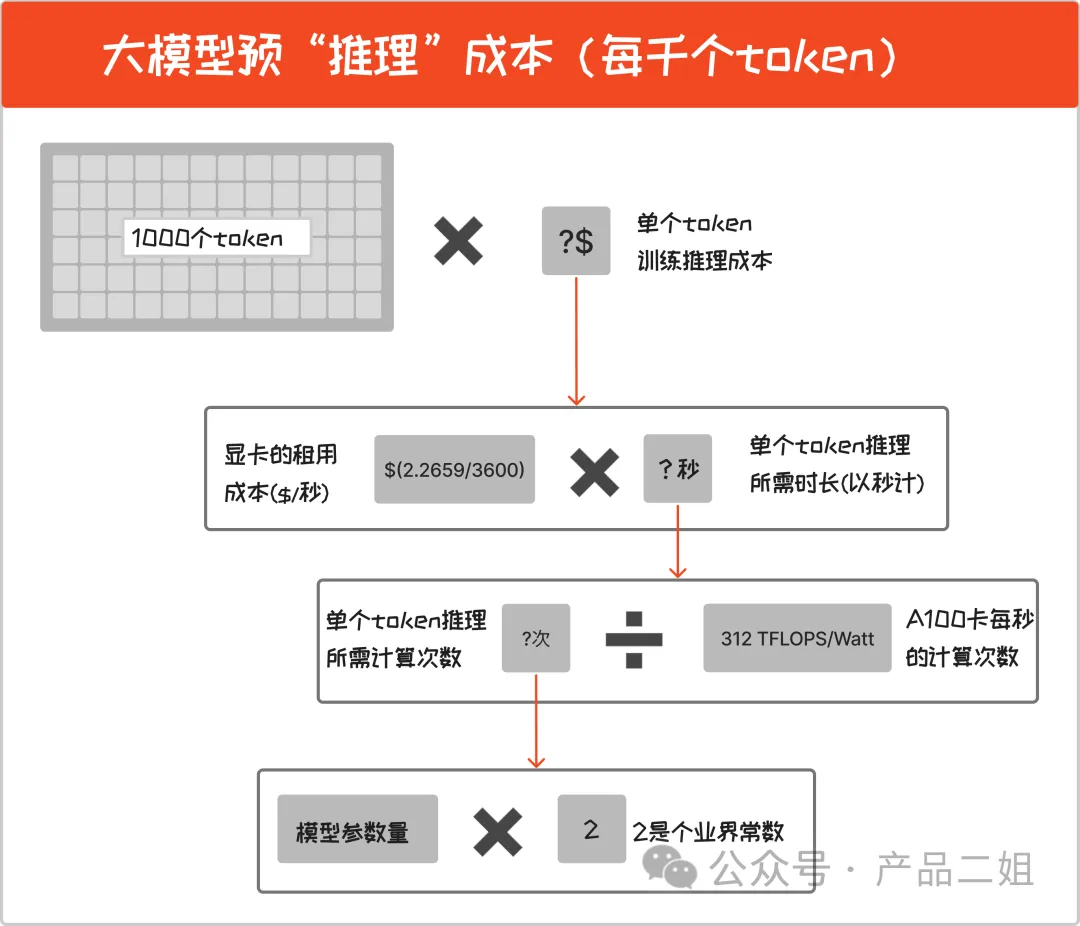
每千个 token 推理成本 = 1000✖️( 模型参数量✖️2 /A100 卡每秒的计算次数)✖️显卡的租用成本
1.4 工程师与模型成本
好的工程师:无价!
模型,用免费的话,不要钱! 上QWEN!
1.5 硬件成本与技术要求
可能是成本最高的一项
目前大模型已经被分为好几个档位,如最近新出的qwen2.5从72B到0.5B都已经覆盖了;
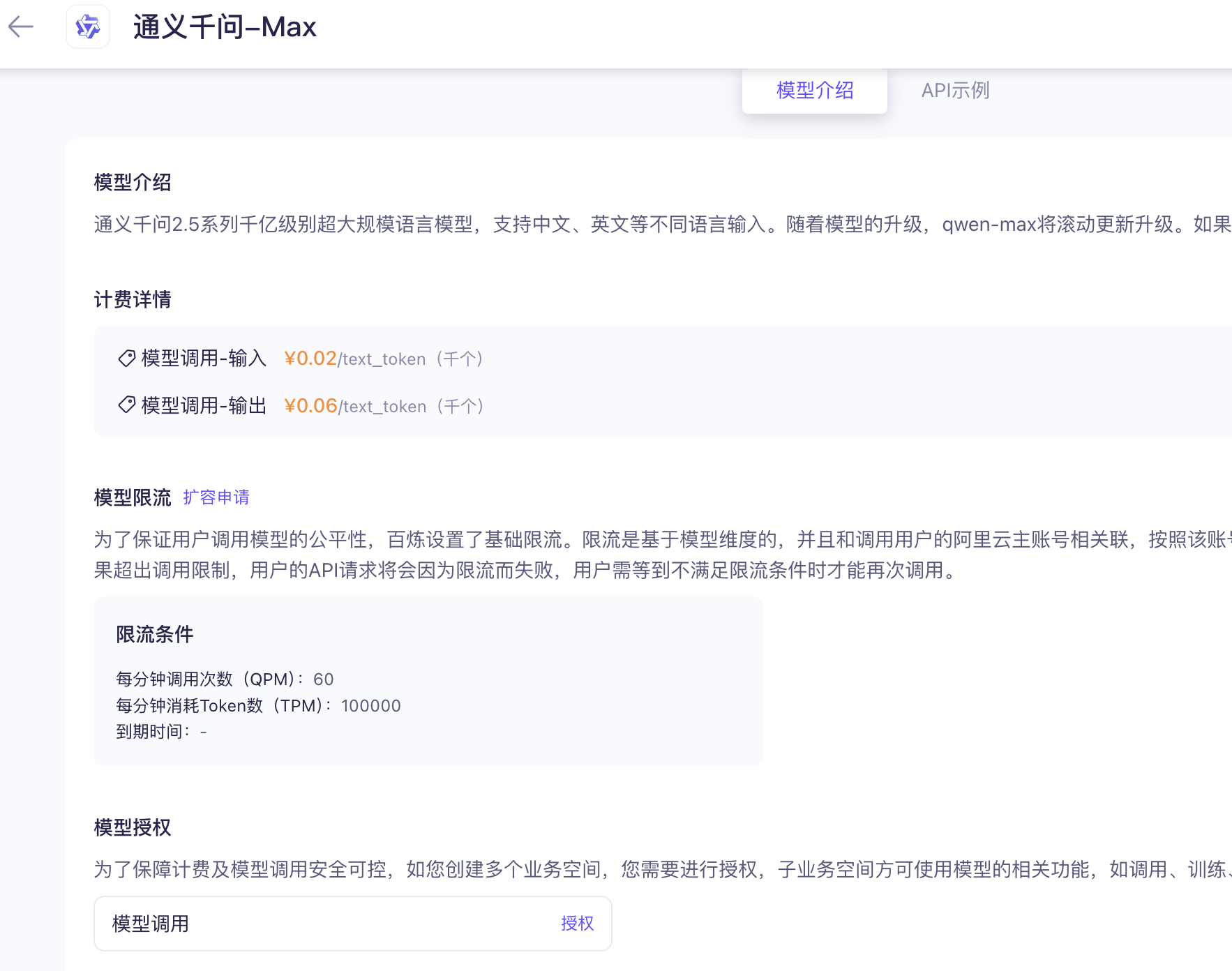
同时这里面的技术要求一项,对于不同的场景要求还不太一样,来看一下通义千问的限流条件,就会有QPM的要求。
限流条件
每分钟调用次数(QPM):60
每分钟消耗Token数(TPM):100000
到期时间:-
同时,有的在线应用还会对大模型的首次响应时间有非常高的要求,也就是用户总不可能干等你全部生成好,所以大多数为了快速响应,留住用户,都是使用steam的方式。
不过,类似一些agent中的大模型操作,内部还反复调用多次大模型,在实际应用中的问题就会被进一步放大,此时哪怕流式生成能让用户更耐心,内部做路由、推理的大模型流程,也让首字出现的时间被大大拉长,显然不合理。
1.6 知识RAG更新 / 定期微调
模型一旦训好,对于后续的更新和迭代都会有问题,对于不需要频繁更新的领域,类似开放域的百科知识,大模型具有很强的优势,但是到细分的落地场景,更新频率的问题需要高度关注。
1.7 AIGC内容安全
受限于大模型结果的不可控性,以及上线后问题出现的严重性,都有必要花费很多时间来对大模型的结果进行安全控制
一般的大模型输出内容安全通常会经过前后处理,前处理如prompt,后处理会做各种安全、敏感词检测等,进行重重把关,甚至人工审核,最终才能实现面客。
2 openAI的一些成本考量
文字来自: OpenAl宕机,并非算力不够,而是……

微软是OpenAI大金主,做大语言模型推理,
GPU资源分配情况:最多60000 台 GPU ,最少 4700 台 GPU
这些 GPU是专门用于推理任务,而不是训练用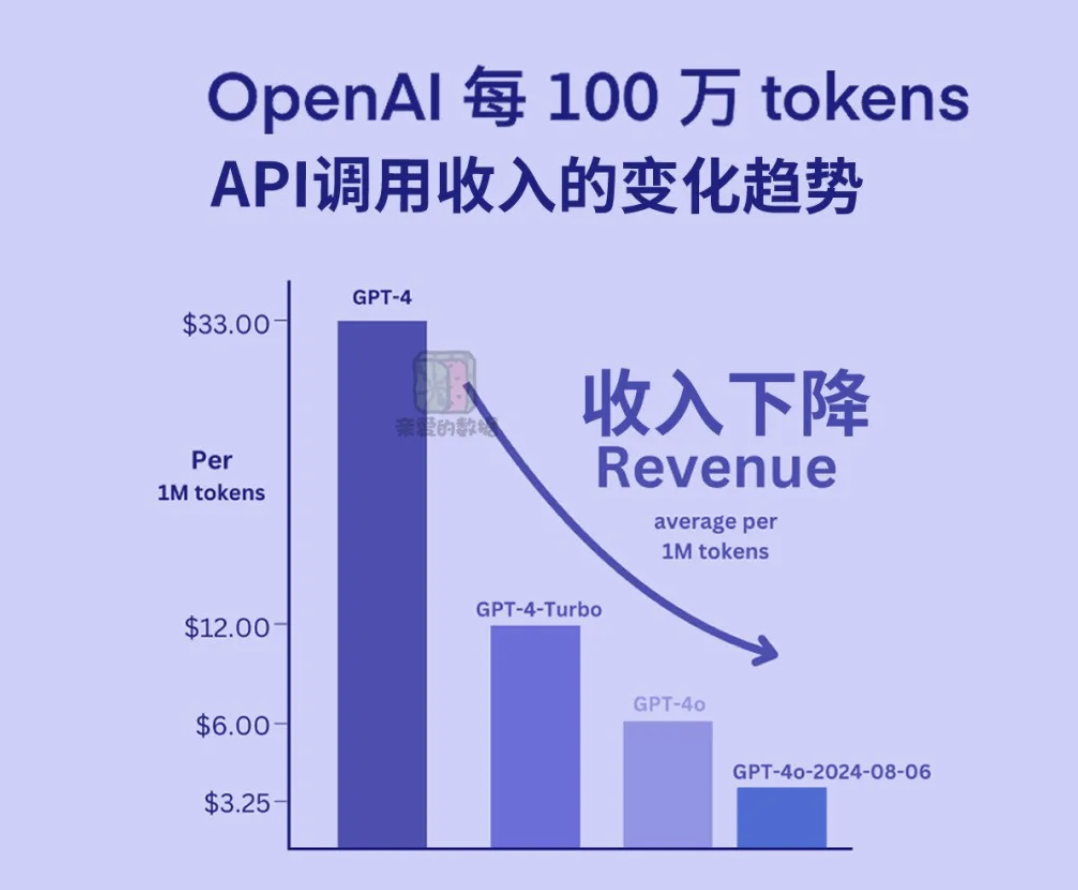
输入和输出的Token算在一起,通常以每100万token为单位计费。
除了算力费用,还有基础软件与运维费用,当然,还得加上电费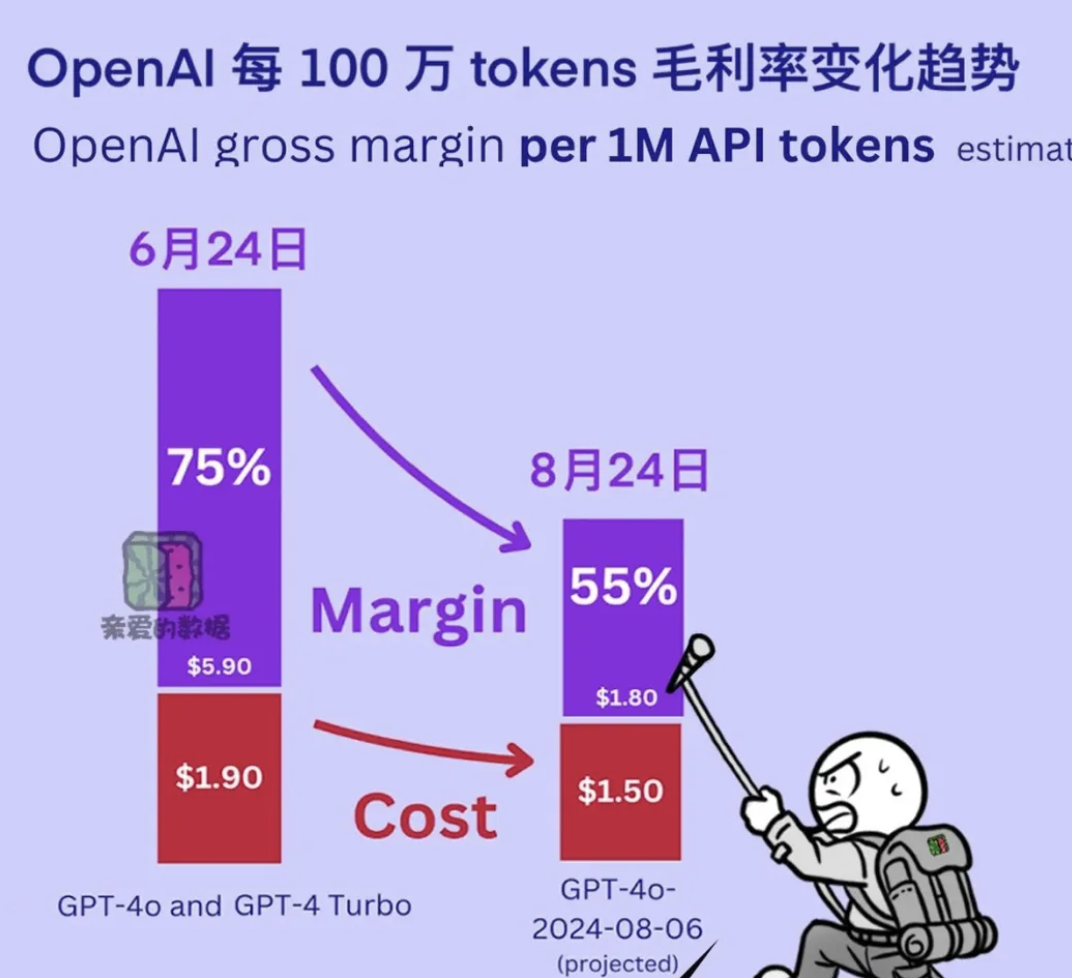
OpenAI他们每代模型都在减少推理成本
从2024年6月到8月,每百万词元的推理成本,‘从大约从人民币14块(1.9美元),降到11块(1.5美元)。
如何提高推理效率?
- 第一个答案,提高芯片制程,提高半导体制造工艺的技术水平
- 软硬件配合度:
- 软硬件配合包括模型结构与芯片架构适配
- 软硬件配合包括选择合适的批次大小
- 好好改进算法:Transformer在回答问题时,需计算每个字和其他所有字之间的关系
- 降低点精度:从16位浮点数减少到8位或4位。AI模型精度与芯片的I/O和数据传输量直接相关
3 参考文献
心法利器[119] | 大模型落地困境讨论与解决思路
做大模型AI应用一定要了解的成本计算公式
AI应用省钱攻略–降低模型成本的七大策略

欢迎加入 MCP 技术社区!与志同道合者携手前行,一同解锁 MCP 技术的无限可能!
更多推荐


 25
25 0
0- 0



 已为社区贡献36条内容
已为社区贡献36条内容

所有评论(0)