长序列(Long Context)大模型笔记
知乎:Rooters链接:https://zhuanlan.zhihu.com/p/926602895过去一年中,长序列大模型(LLM)的训练和推理方法在业界取得了显著进展,本文将从模型建模和机器学习系统两个方面进行总结,并讨论一些值得进一步探索的方向。欢迎大家提出意见、补充和讨论!位置编码(Position Embedding)ALIBI 和 RoPE在一年前刚开始探索长序列时,部分模型选择了A
知乎:Rooters
链接:https://zhuanlan.zhihu.com/p/926602895
过去一年中,长序列大模型(LLM)的训练和推理方法在业界取得了显著进展,本文将从模型建模和机器学习系统两个方面进行总结,并讨论一些值得进一步探索的方向。欢迎大家提出意见、补充和讨论!
位置编码(Position Embedding)
ALIBI 和 RoPE
在一年前刚开始探索长序列时,部分模型选择了ALIBI或RoPE作为位置编码方法。然而,随着时间的推移,大部分新模型(如 LLaMA、Mistral 和 Cohere)都倾向于使用 RoPE 作为默认选择。
ALIBI 最初有理论上的优势,原始论文声称它可以实现无损外推。然而,后续的工作发现,当训练的 token 数量达到一定阈值(如 1T)时,模型会过拟合到训练的长度。此外,ALIBI 没有类似 RoPE-NTK 这种微调方式,尽管也有像Position Interpolation 这样的尝试,但效果不尽如人意。
在系统方面,ALIBI 和 flash attention 并不兼容,需要将 bias mask 物化或者集成到 kernel 中。前者对于超长序列是一大瓶颈,而后者则需要额外的工程工作。此外,ALIBI 的建模方式也显得比较“朴素”,由于 bias 的设计,很多 attention heads,尤其是低层的,实际的 attention score 会趋近于一个非常小的窗口大小(类似滑动窗口)。
相比之下,RoPE 更为友好,它有一个数学上的基础,利用绝对位置来获取相对位置(感谢苏神的贡献),并且可以与 flash attention 适配(需要注意精度问题)。很多长序列的工作也基于 RoPE 做了外推,总体上比 ALIBI 更可靠。
RoPE Scaling / 外推
目前业界在长序列建模中比较常用且有效的方法是RoPE Scaling。一些其他相关术语如 NTK scaling 实质上是类似的概念。这个方向有很多扩展工作,例如Dynamic NTK、Yarn等,基本方法是在长序列微调阶段增大 RoPE 的 θ(theta)值。
还有其他类似的工作,例如 LongLoRA、PoSE、LLM-infinite、Focus Transformer、ReRoPE、LogN scaling 等,这些方法有很多创新性想法,但个人经验是,RoPE scaling 效果更稳定、好用。
特别推荐 Baichuan 论文中的一些推论和理解(第 4.1 和 4.2 节):
https://arxiv.org/html/2405.14591v1
论文中提到,随着训练长度的增加,应该相应地增大 RoPE 的 θ 值,并给出了推导的边界条件。还有一些工作使用较大的 RoPE base,比如 Gradient AI 提出的改进,也取得了不错的效果。
在实际应用中,大部分模型(如 LLaMA)会先进行预训练,再进行长序列预训练和长序列 SFT(Supervised Fine-Tuning),并在预训练或微调阶段增大 RoPE 值。个人实验发现,适度增加预训练阶段的 RoPE 参数可以提升某些 benchmark 的表现。
关于 RoPE 的分析,推荐一个很不错的帖子,讨论了 RoPE 的缺点及其原因:
https://zhuanlan.zhihu.com/p/717174366
关于位置编码的一些思考
目前基于 RoPE-NTK 的方法在长序列上常常遇到性能下降的问题,感觉这是 RoPE 模型在外推中的一个瓶颈。相较而言,Ruler Benchmark 显示,Gemini 和 Jamba-1.5B 在这方面表现较好,可能是因为它们采用了不同的架构变化(Gemini)或是基于混合模型的架构(Jamba)。未来的探索方向可能需要跳出 RoPE 框架,从 Transformer 层面或 attention 建模层面寻找新的突破。
一个最近的研究提出了Contextual Position Encoding,这是一种基于上下文的位置信息建模方法。它增强了语义背景和位置信息的交互,与早期的 DeBERTa 和 Mamba 的 selective SSM 有类似之处。这个方向的挑战在于如何优化 memory 需求,同时保证与例如 flash attention 这类系统兼容。
https://arxiv.org/abs/2405.18719
Attention
长序列模型中的 attention 主要有两个方向:
-
减少 attention 开销,例如线性 attention 和 SSM 等方法。
-
保持 attention 的熵,尤其是在长序列上的表现,如 LogN scaling。
Cheaper Attention
线性 attention 的研究相对较早,例如 Linformer、Linear Transformer 和 Sparse Transformer 等,这些方法在 2022 年之前很流行。然而,由于线性 attention 稳定性不佳,扩展规模后性能下降,业界应用较少。同时,dense attention 通过诸如 flash attention 和 ring attention 的发展,性价比变得更高。
相对有效的方法有 GQA、MQA、MLA 等。一些折衷方案如 Gated Attention Unit (GAU) 和基于 GAU 的 Mega, Mega2,虽然保留了 quadratic 的复杂度,但有效降低了 attention 计算开销。
此外,还有一些混合架构如稀疏和 dense attention 层的结合,或是 Mamba 和 dense layer 的结合。这些架构在超长序列(1M 长度以上)下显示出不错的外推能力,短期内可能是较为有效的策略。
Entropy
长序列 attention 的一个问题是,随着 token 数量的增加,attention 分布趋于平缓,导致熵值增加。将 attention logits 乘以一个 scaler 可以使 softmax attention 更加稀疏,从而使模型更能关注有用的信息。
例如,苏神的博客中提到的 LogN 缩放 方法已在 QWEN 模型中低调应用。个人实验发现,LogN scaling 和 RoPE scaling 并不完全叠加,长序列能力没有单独使用 NTK 时明显,但可能与调参有关。
https://spaces.ac.cn/archives/9444
最近的一个研究Differential Transformer 提出了通过计算两个 softmax 相减的方式来减少 attention 噪声。文章表明,这种方法可以让模型在长短序列以及 many-shot 评估中取得优异表现,并通过减少无关信息的分配,优化了 attention 分布。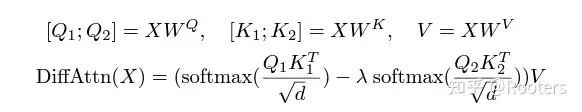
https://arxiv.org/abs/2410.05258
长序列数据与评估
预训练阶段的长序列数据需要注意数据比例和训练效率,例如以下细致的工作:
https://arxiv.org/abs/2402.10171
在指令微调阶段获取长序列数据比较麻烦,很多工作依赖于合成数据,如 LLaMA3:
https://ai.meta.com/research/publications/effective-long-context-scaling-of-foundation-models/
有些工作则认为拼接短文本比长序列文本更有助于长序列评估:
https://arxiv.org/abs/2410.02660
在对齐阶段目前没有发现太多work(欢迎了解的朋友分享)。感觉长序列preference data比较难整。楼主尝试过用类似sft的方式合成但是效果相当不好。而且如何在对齐阶段训练长序列也是个问题。
在评估上,Perplexity 和简单的大海捞针并不能很好地反映模型的实际性能。一些更好的评估方法如 Rulers 基于部分合成数据来评估长序列能力。大部分模型在 Ruler-128k 长度上依然有较大性能下降。LLM在长序列retrieval上的性能普遍强于其他性能,也有work基于这点做两步走(retrieve -> answer) 生成长序列回答的
https://arxiv.org/html/2410.03227v1
长序列训练框架
Flash Attention
要想获得较好的长序列效果,依赖外推还不够,许多产品级模型需要训练到实际长度。主要使用的 kernel 是 Flash Attention 和 Ring Attention。在 128k 左右的长度,通常不需要使用 Ring Attention 或 Sequence Parallel,因为长序列训练的 batch size 较小。
Sequence Parallel
再长一点(256k+)或许需要sequence parallel,不过也不一定要用ring attention。可以选择比如deepspeed Ulysses这种在sequence parallel和tensor parallel来回切换的,注意这个时候sharding的dimension被注意力头的数量限制,比如num_heads=32的话最大的sharding也必须是32,这是相对于ring attention的一个限制。有的工作也有把sp和tp一起用。
类似的,llama3提出来(section 3.3.2)可以用context parallel+all gather KV的方式,相当于把attention matrix计算按row切分。其中的all gather相对便宜一些因为GQA/MQA使得KV的size远小于Q,导致communication造成的cost可以接受。楼主之前尝试过这种方法,和causal结合起来需要kernel计算时根据index做一些改变或者用non causal+mask的方法。速度相对来讲也可以接受。
Ring attention的好处是按sequence切分之后就没有communication的需要,attention时传输理论上和计算时间重叠,不算。后续ffn也是独立在sequence dimension计算的。sequence parallel的维度也不受注意力头的限制。楼主ring attention实际体验的效果不是很好。一个原因是ring attention在tpu上相对友好,tpu相对topology比较平均也可以调整。在GPU上遇到问题是,如果Node内GPU间传输的话NVlink相对速度快一些,attention的计算和传输也比较重叠;当sp>8需要进行node之间的传输时会出现传输变慢并且计算和传输不能同步进行。尝试了很多方法也没有搞出来,最后放弃转向其他方案了:( (有了解的朋友求指教)。
其他
做训练时一个其他的问题是让以上框架和其他feature比如varlen(segment mask),sparse attention,多模态的prefix-LM结合起来跑。比如用类似llama3的方法时,和sparse attention结合可以减少communication的量以及每个shard上的计算等。楼主用Jax,很多诸如flash attention的支持不如torch那边全面,ring attention没跑出来可能和这个也有关系 ...... 而且在pallas这个层面做的kernel相比之下performance不够强,比较好的方法是直接在Jax层面连GPU的kernel,不过需要很多调试和协作(XLA有时很不友好)。如果有朋友了解相关的内容请多交流指教。
推理相关内容
推理阶段最关注的一个问题是 KV 压缩。长序列会导致
KV cache 占用大量显存,如何筛选出有用的 KV cache 以保持 attention 效果,同时减少不必要的内存占用是一个重要问题。
相关工作包括 H2O、SnapKV 等:
https://arxiv.org/abs/2306.14048
https://arxiv.org/abs/2404.14469
目前这类work的瓶颈是大部分在prefill这个阶段静态选取需要的KV cache,然后decode阶段根据筛选好的kv cache进行计算。导致如果多轮对话中话题内容变化很大,模型回答效果影响很大。而且基于长序列的对话很可能是会频繁切换内容的,对话会focus在context的不同位置(用户很少会给一本书就问其中一小块吧,还不够买token钱回本的)。动态的kv 筛选对于这点是比较重要的,一些相关work通过speculative decoding或者cache offloading减小kv的内存需求:
https://arxiv.org/abs/2404.11912
https://arxiv.org/abs/2408.11049
work很多,不都分享了。
备注:昵称-学校/公司-方向/会议(eg.ACL),进入技术/投稿群

id:DLNLPer,记得备注呦

欢迎加入 MCP 技术社区!与志同道合者携手前行,一同解锁 MCP 技术的无限可能!
更多推荐


 2
2 0
0- 0



 已为社区贡献107条内容
已为社区贡献107条内容

所有评论(0)