图解大模型RLHF系列之:人人都能看懂的PPO原理与源码解读
1.1 强化学习整体流程1.2 价值函数。
过去在RLHF的初学阶段,有一个问题最直接地困惑着我:
- 如何在NLP语境下理解强化学习的框架?例如,我知道强化学习中有Agent、Environment、Reward、State等要素,但是在NLP语境中,它们指什么?语言模型又是如何根据奖励做更新的?
为了解答这个问题,我翻阅了很多资料,看了许多的公式推导,去研究RLHF的整体框架和loss设计。虽然吭吭哧哧地入门了,但是这个过程实在痛苦,最主要的原因是:理论的部分太多,直观的解释太少。
所以,在写这篇文章时,我直接从一个RLHF开源项目源码入手(deepspeed-chat),根据源码的实现细节,给出尽可能丰富的训练流程图,并对所有的公式给出直观的解释。希望可以帮助大家更具象地感受RLHF的训练流程。对于没有强化学习背景的朋友,也可以无痛阅读本文。 关于RLHF,各家的开源代码间都会有一些差异,同时也不止PPO一种RLHF方式。感兴趣的朋友,也可以读读别家的源码,做一些对比。后续有时间,这个系列也会对各种RLHF方式进行比较。
整体内容如下:
【一、强化学习概述】
1.1 强化学习整体流程
1.2 价值函数
【二、NLP中的强化学习】
【三、RLHF中的四个重要角色】
3.1 Actor Model
3.2 Reference Model
3.3 Critic Model
3.4 Reward Model
【四、RLHF中的loss计算】
4.1 Actor loss
(1) 直观设计
(2) 引入优势
(3) 重新设计奖励函数
(4) 重新设计优势
(5)ppo_epoch: 引入新约束,提升训练效率
(6) Actor loss小结
【五、Critic loss】
(1) 实际收益优化
(2) 预估收益优化
一、强化学习概述
1. 强化学习整体流程
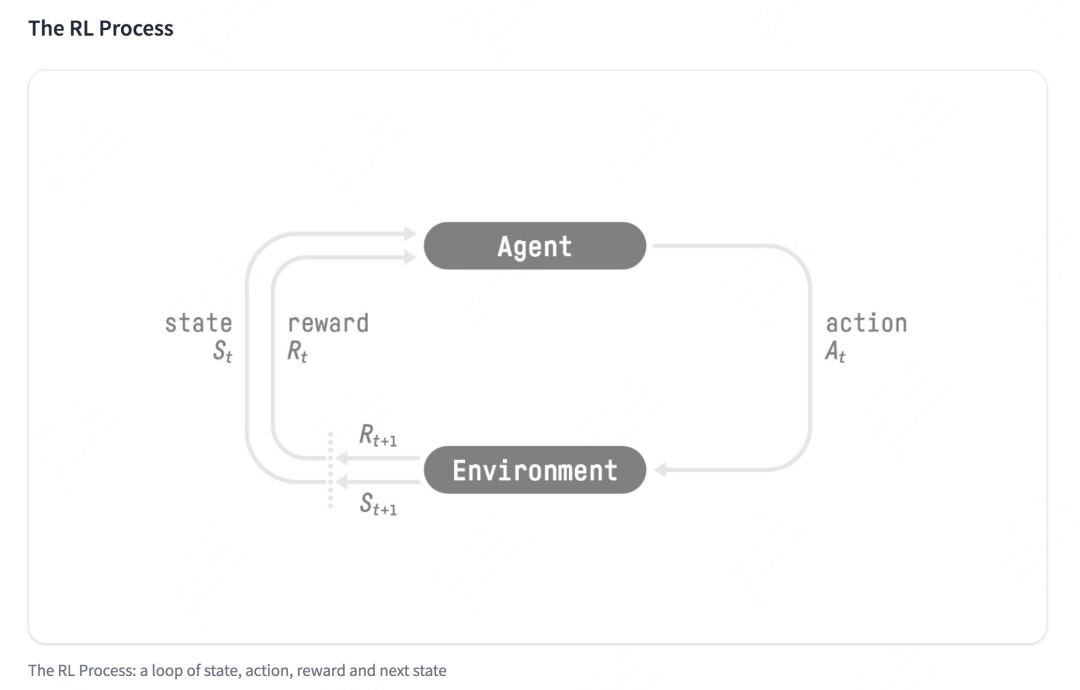
-
强化学习的两个实体:智能体(Agent)与环境(Environment)
-
强化学习中两个实体的交互:
-
- 状态空间S:S即为State,指环境中所有可能状态的集合
- 动作空间A:A即为Action,指智能体所有可能动作的集合
- 奖励R:R即为Reward,指智能体在环境的某一状态下所获得的奖励。
以上图为例,智能体与环境的交互过程如下:

1.2 价值函数

二、NLP中的强化学习
我们在第一部分介绍了通用强化学习的流程,那么我们要怎么把这个流程对应到NLP任务中呢?换句话说,NLP任务中的智能体、环境、状态、动作等等,都是指什么呢?
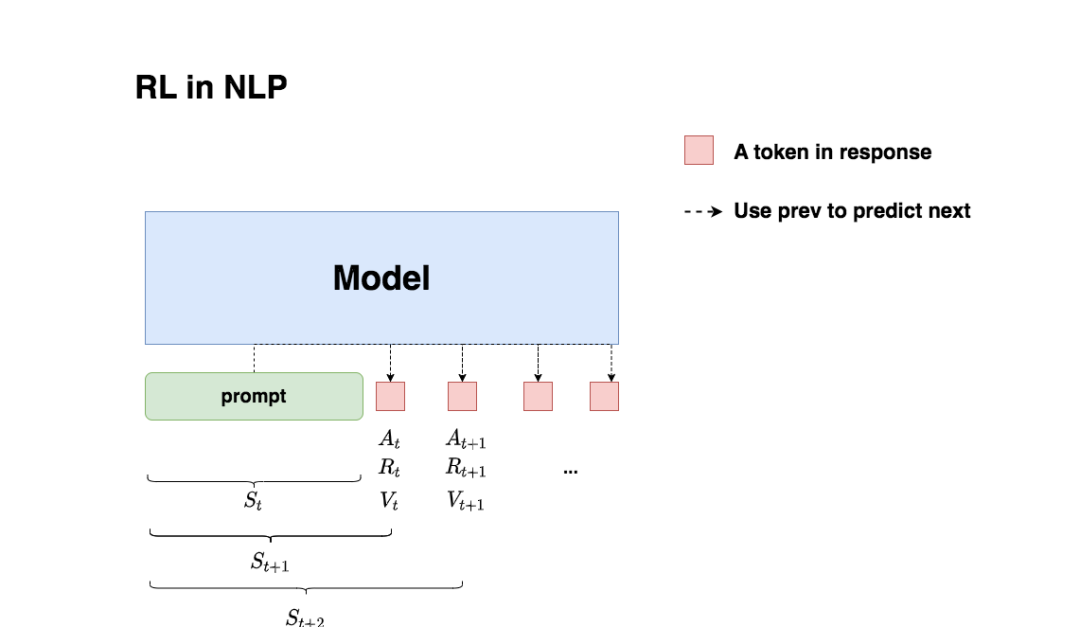


三、RLHF中的四个重要角色
在本节中,我们在第二部分的基础上更进一步:更详细理清NLP语境下RLHF的运作流程。
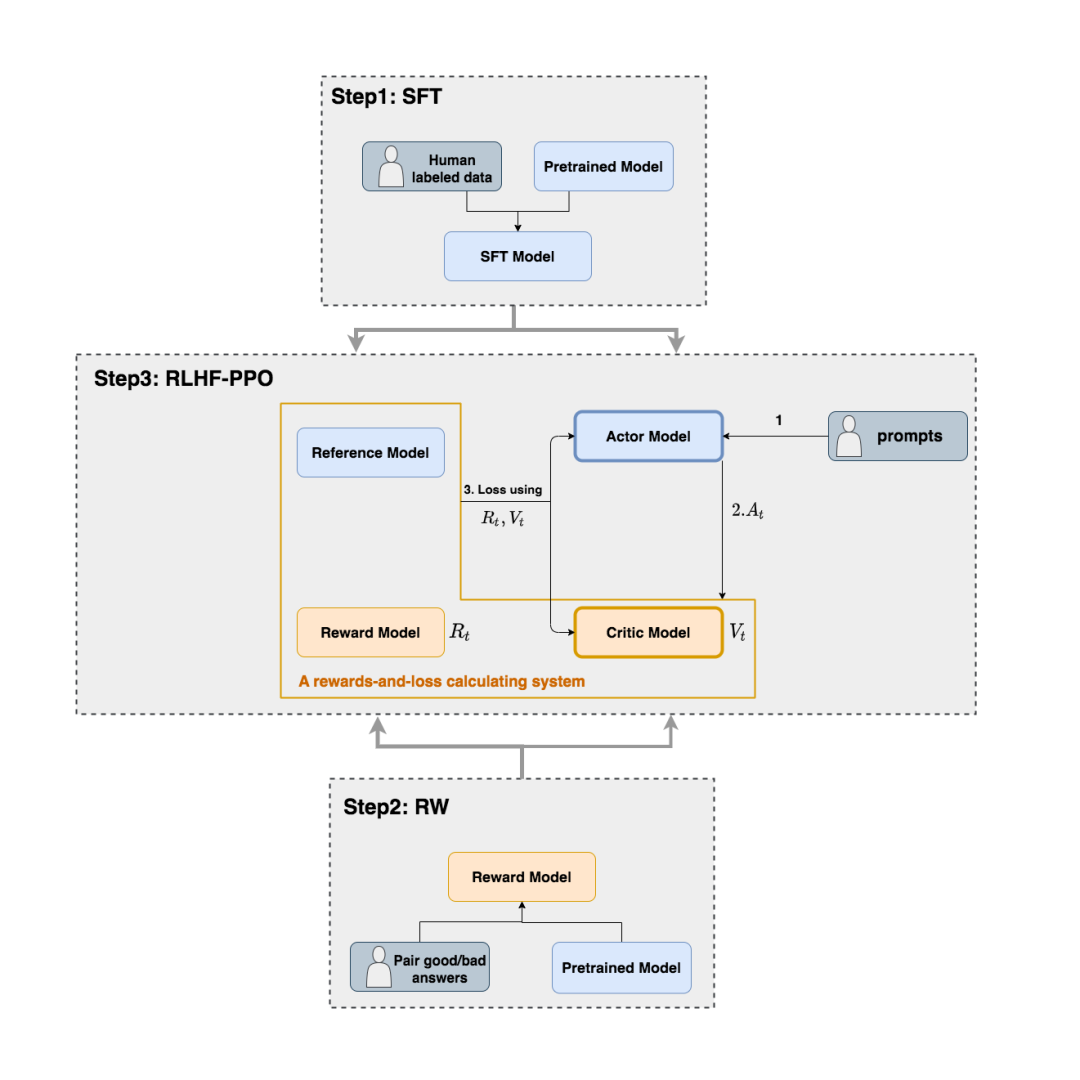
如上图,在RLHF-PPO阶段,一共有四个主要模型,分别是:

其中:
- Actor/Critic Model在RLHF阶段是需要训练的(图中给这两个模型加了粗边,就是表示这个含义);而Reward/Reference Model是参数冻结的。
- Critic/Reward/Reference Model共同组成了一个“奖励-loss”计算体系(我自己命名的,为了方便理解),我们综合它们的结果计算loss,用于更新Actor和Critic Model
我们把这四个部分展开说说。
3.1 Actor Model (演员模型)
正如前文所说,Actor就是我们想要训练的目标语言模型。我们一般用SFT阶段产出的SFT模型来对它做初始化。
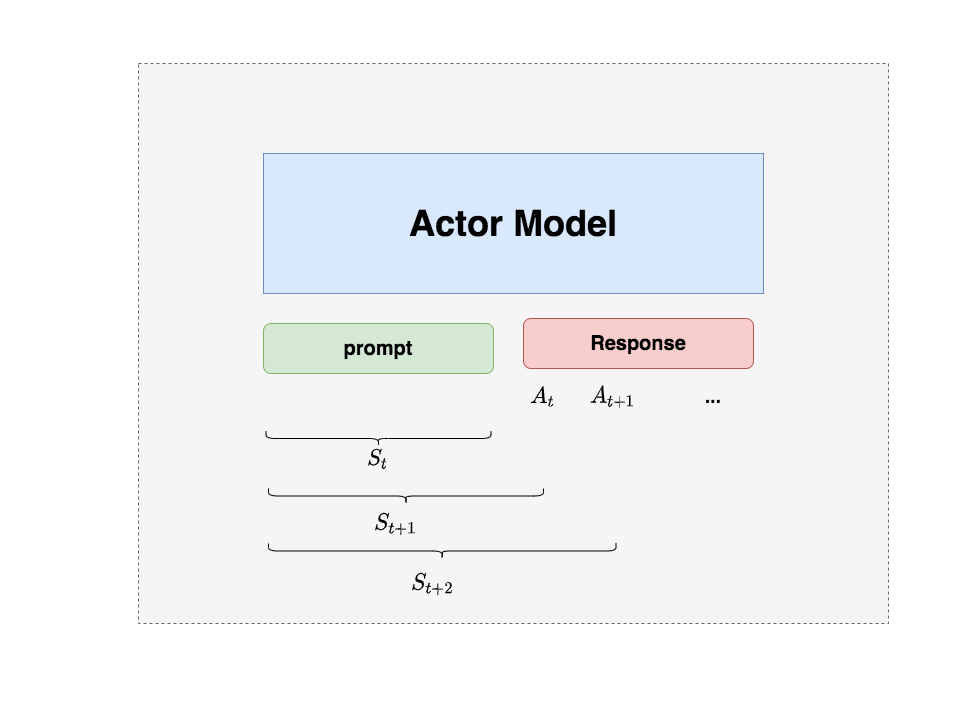
我们的最终目的是让Actor模型能产生符合人类喜好的response。所以我们的策略是,先喂给Actor一条prompt (这里假设batch_size = 1,所以是1条prompt),让它生成对应的response。然后,我们再将“prompt + response"送入我们的“奖励-loss”计算体系中去算得最后的loss,用于更新actor。
3.2 Reference Model(参考模型)
Reference Model(以下简称Ref模型)一般也用SFT阶段得到的SFT模型做初始化,在训练过程中,它的参数是冻结的。Ref模型的主要作用是防止Actor”训歪”,那么它具体是怎么做到这一点的呢?
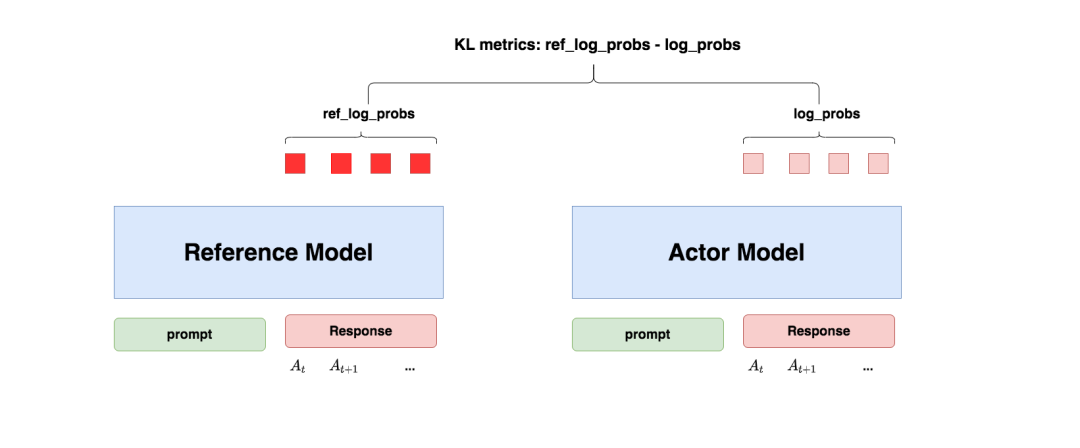
“防止模型训歪”换一个更详细的解释是:我们希望训练出来的Actor模型既能达到符合人类喜好的目的,又尽量让它和SFT模型不要差异太大。简言之,我们希望两个模型的输出分布尽量相似。那什么指标能用来衡量输出分布的相似度呢?我们自然而然想到了KL散度。
如图所示:
-
对Actor模型,我们喂给它一个prompt,它正常输出对应的response。那么response中每一个token肯定有它对应的log_prob结果呀,我们把这样的结果记为log_probs
-
对Ref模型,我们把Actor生成的"prompt + response"喂给它,那么它同样能给出每个token的log_prob结果,我们记其为ref_log_probs
-
那么这两个模型的输出分布相似度就可以用ref_log_probs - log_probs来衡量,我们可以从两个方面来理解这个公式:

注:你可能已经注意到,按照KL散度的定义,这里写成log_probs - ref_log_probs更合适一些。这里之所以写成ref_log_probs - log_probs,是为了方便大家从直觉上了解这个公式。
现在,我们已经知道怎么利用Ref模型和KL散度来防止Actor训歪了。KL散度将在后续被用于loss的计算,我们在后文中会详细解释。
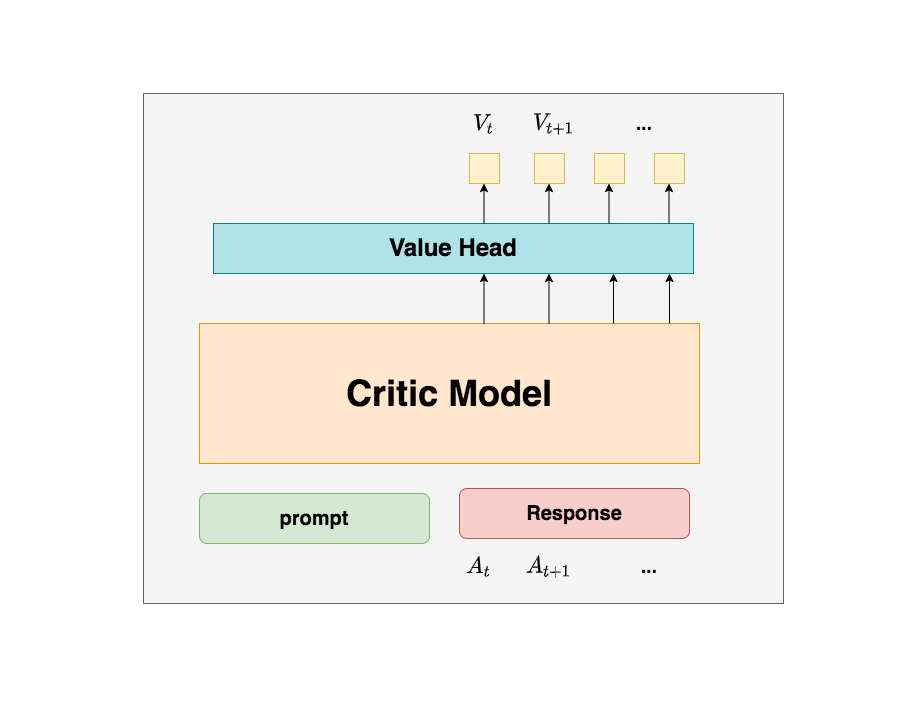
3.3 Critic Model(评论家模型)
Critic Model用于预测期望总收益,和Actor模型一样,它需要做参数更新。实践中,Critic Model的设计和初始化方式也有很多种,例如和Actor共享部分参数、从RW阶段的Reward Model初始化而来等等。我们讲解时,和deepspeed-chat的实现保持一致:从RW阶段的Reward Model初始化而来。
你可能想问:训练Actor模型我能理解,但我还是不明白,为什么要单独训练一个Critic模型用于预测收益呢?

所以总结来说,在RLHF中,我们不仅要训练模型生成符合人类喜好的内容的能力(Actor),也要提升模型对人类喜好量化判断的能力(Critic)。 这就是Critic模型存在的意义。我们来看看它的大致架构:

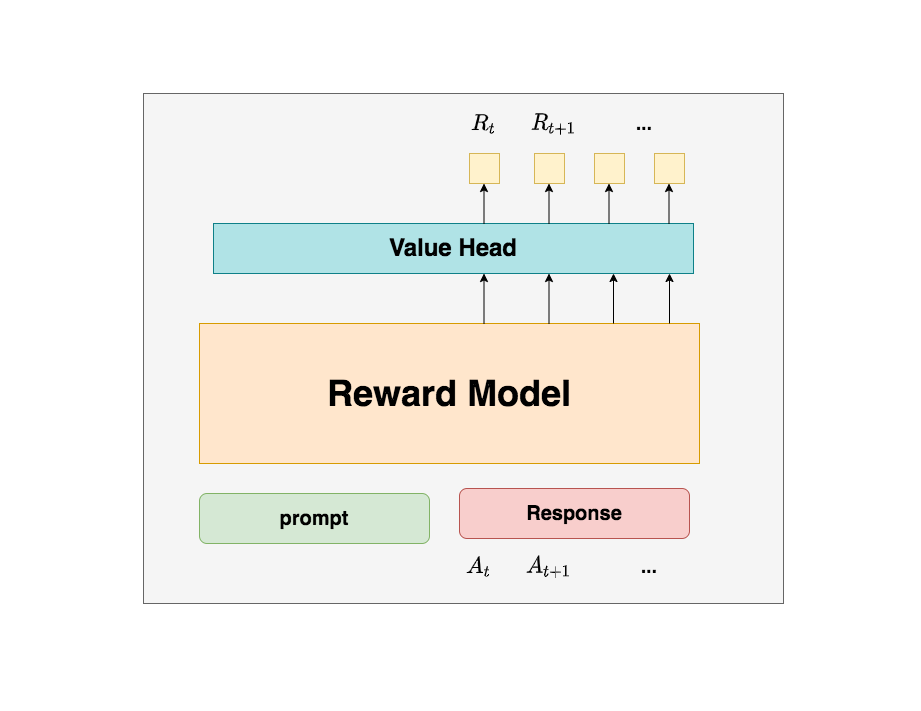
3.4 Reward Model(奖励模型)

Reward模型和critic模型非常相似,这里我们就只给出架构图,不再做过多的说明。关于Reward模型的训练过程,后续有时间也会出个原理和代码解析。
四、RLHF中的loss计算
到目前为止,我们已经基本了解了RLHF的训练框架,以及其中的四个重要角色(训练一个RLHF,有4个模型在硬件上跑,可想而知对存储的压力)。在本节中,我们一起来解读RLHF的loss计算方式。在解读中,我们会再一次理一遍RLHF的整体训练过程,填补相关细节。在这之后,我们就可以来看代码解析了。
在第三部分的讲解中,我们知道Actor和Critic模型都会做参数更新,所以我们的loss也分成2个:
- Actor loss:用于评估Actor是否产生了符合人类喜好的结果,将作用于Actor的BWD上。
- Critic loss:用于评估Critic是否正确预测了人类的喜好,将作用于Critic的BWD上。
我们详细来看这两者。
4.1 Actor loss
(1)直观设计
我们先来看一个直观的loss设计方式:

(2)引入优势(Advantage)
在开始讲解之前,我们举个小例子:
假设在王者中,中路想支援发育路,这时中路有两种选择:1. 走自家野区。2. 走大龙路。
中路选择走大龙路,当她做出这个决定后,Critic告诉她可以收1个人头。结果,此刻对面打野正在自家采灵芝,对面也没有什么苟草英雄,中路一路直上,最终收割2个人头。
因为实际收割的人头比预期要多1个,中路尝到了甜头,所以她增大了“支援上路走大龙路”的概率。
这个多出来的“甜头”,就叫做“优势”(Advantage)。
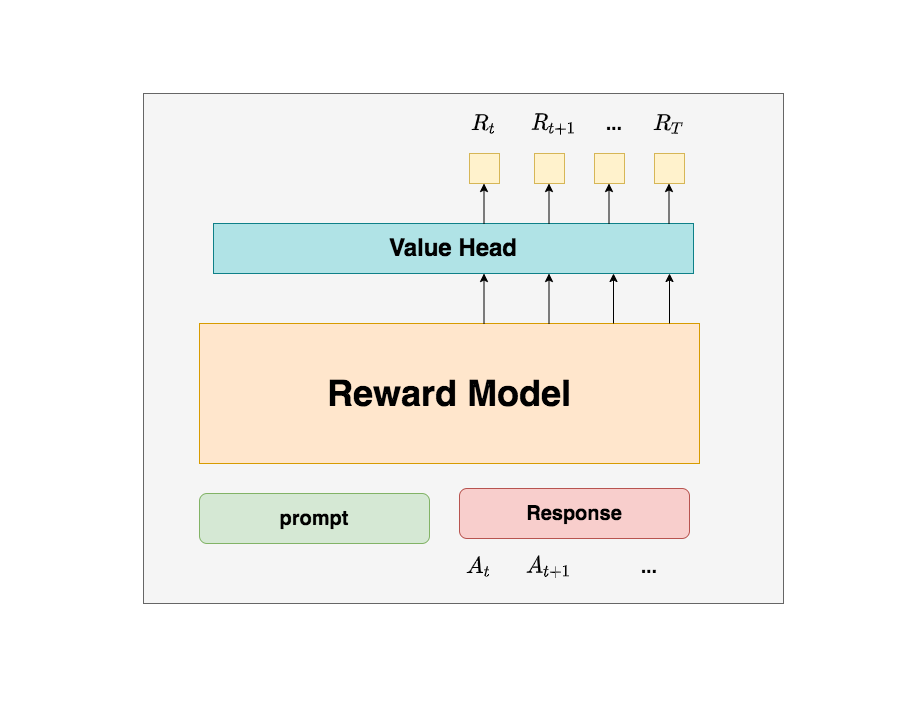

代码实践如下:
def compute_rewards(self, prompts, log_probs, ref_log_probs, reward_score,
action_mask):
"""
reward_function:计算最终的reward分数
复习一下几个相关参数的默认值:
self.kl_ctl = 0.1
self.clip_reward_value = 5
对于batch中的某个prompt来说,它最终的reward分数为:
(1) 先计算actor和ref_model的logit相似度: -self.kl_ctl * (log_probs - ref_log_probs)
其实写成self.kl_ctl * (ref_log_probs - log_probs)更好理解些
这个值越大,说明ref_model对actor生成的结果的认可度越高(即表明rlhf没有训歪),
没有训歪的情况下我们也应该给模型一些奖励,这个奖励就是self.kl_ctl * (ref_log_probs - log_probs)
(2)由于我们只取最后一个token对应位置的分数作为reward_score,因此我们只需要:
self.kl_ctl * (ref_log_probs - log_probs)的最后一位 + reward_score
(3) 同时我们对reward_score也做了大小限制,最大不超过self.clip_reward_value(超过统一给成self.clip_reward_value),
最小不低于-self.clip_reward_value(低于统一给成-self.clip_reward_value)
(4) 最后返回的rewards大小为:(batch_size, 各条数据的长度),对batch中的每条数据来说:
- response的最后一位:self.kl_ctl * (ref_log_probs - log_probs)的最后一位 + reward_score
- response的其余位置:self.kl_ctl * (ref_log_probs - log_probs)
"""
kl_divergence_estimate = -self.kl_ctl * (log_probs - ref_log_probs)
rewards = kl_divergence_estimate
# ---------------------------------------------------------------------------------------------------
# response开始的位置
# (因为我们对prompt做过padding处理,因此batch中每个prompt长度一致,也就意味着每个response开始的位置一致)
# (所以这里start是不加s的,只是一个int)
# ---------------------------------------------------------------------------------------------------
start = prompts.shape[1] - 1
# ---------------------------------------------------------------------------------------------------
# response结束的位置
# (因为一个batch中,每个response的长度不一样,所以response的结束位置也不一样)
# (所以这里end是加s的,ends的尺寸是(batch_size,)
# ---------------------------------------------------------------------------------------------------
ends = start + action_mask[:, start:].sum(1) + 1
# ---------------------------------------------------------------------------------------------------
# 对rewards_score做限制
# ---------------------------------------------------------------------------------------------------
reward_clip = torch.clamp(reward_score, -self.clip_reward_value,
self.clip_reward_value)
batch_size = log_probs.shape[0]
for j in range(batch_size):
rewards[j, start:ends[j]][-1] += reward_clip[j] #
return rewards
(4)重新设计优势

代码实践如下(其中返回值中的returns表示实际收益,将被用于计算Critic模型的loss,可以参见4.2,其余细节都在代码注释中):
def get_advantages_and_returns(self, values, rewards, start):
"""
Adopted from https://github.com/CarperAI/trlx/blob/main/trlx/models/modeling_ppo.py#L134
没有引入GAE前的t时刻的优势值:
detal_t = r_t + gamma * V_t+1 - V_t
其中:
- r_t表示t时刻的即时收益
- V_t+1表示未来时刻的预期收益
- r_t + gamma * V_t+1可理解成t时刻的实际预期收益
- V_t可理解成t时刻的预估预期收益(是模型,例如critic model自己估算出来的)
引入GAE后的t时刻的优势值:
A_t = delta_t + gamma * lambda * A_t+1
粗暴理解为在t时刻时,不仅考虑当下优势,还考虑了未来的优势
为了知道A_t, 我们得知道A_t+1,所以在本算法中采取了从后往前做动态规划求解的方法,也即:
假设T是最后一个时刻,则有A_T+1 = 0, 所以有: A_T = delta_T
知道了A_T, 就可以依次往前倒推,把A_t-1, A_t-2之类都算出来了
引入GAE后t时刻的实际预期收益
returns_t = A_t + V_t
= delta_t + gamma * lambda * A_t+1 + V_t
= r_t + gamma * V_t+1 - V_t + gamma * lambda * A_t+1 + V_t
= r_t + gamma * (V_t+1 + lambda * A_t+1)
注意,这里不管是advantages还是returns,都只算response的部分
"""
# Adopted from https://github.com/CarperAI/trlx/blob/main/trlx/models/modeling_ppo.py#L134
lastgaelam = 0
advantages_reversed = []
length = rewards.size()[-1]
# 注意这里用了reversed,是采取从后往前倒推计算的方式
for t in reversed(range(start, length)):
nextvalues = values[:, t + 1] if t < length - 1 else 0.0
delta = rewards[:, t] + self.gamma * nextvalues - values[:, t]
lastgaelam = delta + self.gamma * self.lam * lastgaelam
advantages_reversed.append(lastgaelam)
advantages = torch.stack(advantages_reversed[::-1], dim=1) # 优势
returns = advantages + values[:, start:] # 实际收益
# values: 预期收益
return advantages.detach(), returns
(5) PPO-epoch: 引入新约束

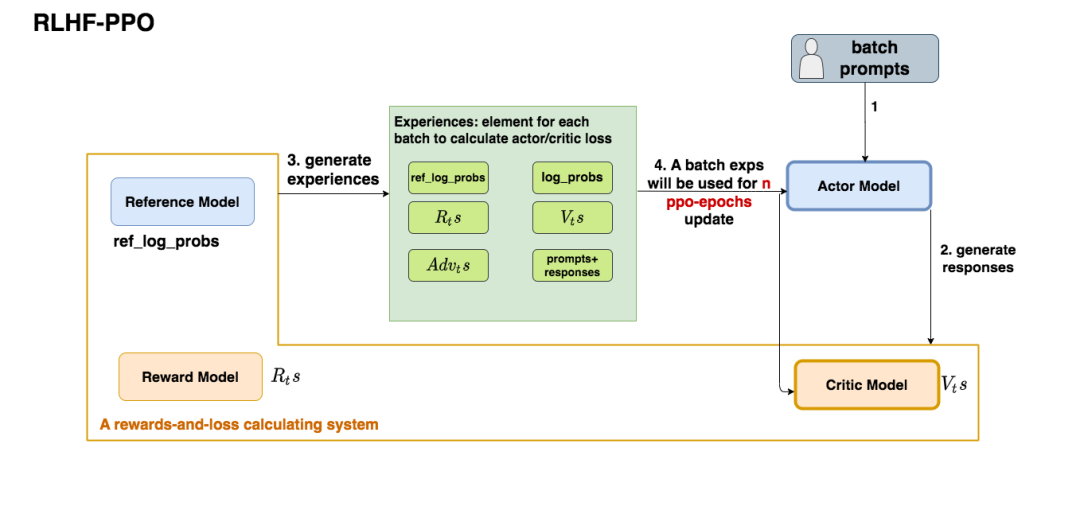
- 第一步,我们准备一个batch的prompts
- 第二步,我们将这个batch的prompts喂给Actor模型,让它生成对应的responses
- 第三步,我们把prompt+responses喂给我们的Critic/Reward/Reference模型,让它生成用于计算actor/critic loss的数据,按照强化学习的术语,我们称这些数据为经验(experiences)。critic loss我们将在后文做详细讲解,目前我们只把目光聚焦到actor loss上
- 第四步,我们根据这些经验,实际计算出actor/critic loss,然后更新Actor和Critic模型
这些步骤都很符合直觉,但是细心的你肯定发现了,文字描述中的第四步和图例中的第四步有差异:图中说,这一个batch的经验值将被用于n次模型更新,这是什么意思呢?
我们知道,在强化学习中,收集一个batch的经验是非常耗时的。对应到我们RLHF的例子中,收集一次经验,它要等四个模型做完推理才可以,正是因此,一个batch的经验,只用于计算1次loss,更新1次Actor和Critic模型,好像有点太浪费了。
所以,**我们自然而然想到,1个batch的经验,能不能用来计算ppo-epochs次loss,更新ppo-epochs次Actor和Critic模型?**简单写一下伪代码,我们想要:
# --------------------------------------------------------------
# 初始化RLHF中的四个模型
# --------------------------------------------------------------
actor, critic, reward, ref = initialize_models()
# --------------------------------------------------------------
# 训练
# --------------------------------------------------------------
# 对于每一个batch的数据
for i in steps:
# 先收集经验值
exps = generate_experience(prompts, actor, critic, reward, ref)
# 一个batch的经验值将被用于计算ppo_epochs次loss,更新ppo_epochs次模型
# 这也意味着,当你计算一次新loss时,你用的是更新后的模型
for j in ppo_epochs:
actor_loss = cal_actor_loss(exps, actor)
critic_loss = cal_critic_loss(exps, critic)
actor.backward(actor_loss)
actor.step()
critc.backward(critic_loss)
critic.step()
而如果我们想让一个batch的经验值被重复使用ppo_epochs次,等价于我们想要Actor在这个过程中,模拟和环境交互ppo_epochs次。举个例子:
- 如果1个batch的经验值只使用1次,那么在本次更新完后,Actor就吃新的batch,正常和环境交互,产出新的经验值
- 但如果1个batch的经验值被使用ppo_epochs次,在这ppo_epochs中,Actor是不吃任何新数据,不做任何交互的,所以我们只能让Actor“模拟”一下和环境交互的过程,吐出一些新数据出来。


整体代码如下:
def actor_loss_fn(self, logprobs, old_logprobs, advantages, mask):
"""
logprobs: 实时计算的,response部分的prob(只有这个是随着actor实时更新而改变的)
old_logprobs:老策略中,response部分的prob (这个是固定的,不随actor实时更新而改变)
advantages: 老策略中,response部分每个token对应的优势(这个是固定的,不随actor实时更新而改变)
mask:老策略中,response部分对应的mask情况这个是固定的,不随actor实时更新而改变)
之所以要引入logprobs计算actor_loss,是因为我们不希望策略每次更新的幅度太大,防止模型训歪
self.cliprange: 默认值是0.2
"""
## policy gradient loss
# -------------------------------------------------------------------------------------
# 计算新旧策略间的KL散度
# -------------------------------------------------------------------------------------
log_ratio = (logprobs - old_logprobs) * mask
ratio = torch.exp(log_ratio)
# -------------------------------------------------------------------------------------
# 计算原始loss和截断loss
# -------------------------------------------------------------------------------------
pg_loss1 = -advantages * ratio
pg_loss2 = -advantages * torch.clamp(ratio, 1.0 - self.cliprange, 1.0 + self.cliprange)
pg_loss = torch.sum(torch.max(pg_loss1, pg_loss2) * mask) / mask.sum() # 最后是取每个非mask的response token的平均loss作为最终loss
return pg_loss
(6)Actor loss小结

- 我们已经对****进行来改造,使其能够衡量Actor模型是否遵从了Ref模型的约束
- 我们已经对****进行改造,使其不仅考虑了当前时刻的优势,还考虑了未来的优势
- 我们重复利用了1个batch的数据,使本来只能被用来做1次模型更新的它现在能被用来做ppo_epochs次模型更新。我们使用真正吃了batch,产出经验值的那个时刻的Actor分布来约束ppo_epochs中更新的Actor分布
- 我们考虑了剪裁机制(clip),在ppo_epochs次更新中,一旦Actor的更新幅度超过我们的控制范围,则不对它进行参数更新。
4.2 Critic loss
我们知道,1个batch产出的经验值,不仅被用来更新Actor,还被用来更新Critic。对于Critic loss,我们不再像Actor loss一样给出一个“演变过程”的解读,我们直接来看它最后的设计。
首先,在之前的解说中,你可能有这样一个印象:
(1)实际收益优化

(2)预估收益优化

# self.cliprange_value是一个常量
# old_values: 老critic的预测结果
# values:新critic的预测结果
values_clipped = torch.clamp(
values,
old_values - self.cliprange_value,
old_values + self.cliprange_value,
)

代码如下:
def critic_loss_fn(self, values, old_values, returns, mask):
"""
values: 实时critic跑出来的预估预期收益(是变动的,随着ppo epoch迭代而改变)
old_values:老critic跑出来的预估预期收益(是固定值)
returns:实际预期收益
mask:response部分的mask
self.cliprange_value = 0.2
"""
## value loss
# 用旧的value去约束新的value
values_clipped = torch.clamp(
values,
old_values - self.cliprange_value,
old_values + self.cliprange_value,
)
if self.compute_fp32_loss:
values = values.float()
values_clipped = values_clipped.float()
# critic模型的loss定义为(预估预期收益-实际预期收益)**2
vf_loss1 = (values - returns)**2
vf_loss2 = (values_clipped - returns)**2
vf_loss = 0.5 * torch.sum(
torch.max(vf_loss1, vf_loss2) * mask) / mask.sum() # 同样,最后也是把critic loss平均到每个token上
return vf_loss
至此,关于RLHF-PPO训练的核心部分和代码解读就讲完了,建议大家亲自阅读源码,如果有硬件条件,可以动手实践。源码地址:
https://github.com/microsoft/DeepSpeedExamples/tree/master/applications/DeepSpeed-Chat/training/step3_rlhf_finetuning
如何学习大模型
现在社会上大模型越来越普及了,已经有很多人都想往这里面扎,但是却找不到适合的方法去学习。
作为一名资深码农,初入大模型时也吃了很多亏,踩了无数坑。现在我想把我的经验和知识分享给你们,帮助你们学习AI大模型,能够解决你们学习中的困难。
下面这些都是我当初辛苦整理和花钱购买的资料,现在我已将重要的AI大模型资料包括市面上AI大模型各大白皮书、AGI大模型系统学习路线、AI大模型视频教程、实战学习,等录播视频免费分享出来,需要的小伙伴可以扫取。

一、AGI大模型系统学习路线
很多人学习大模型的时候没有方向,东学一点西学一点,像只无头苍蝇乱撞,我下面分享的这个学习路线希望能够帮助到你们学习AI大模型。

二、AI大模型视频教程

三、AI大模型各大学习书籍

四、AI大模型各大场景实战案例

五、结束语
学习AI大模型是当前科技发展的趋势,它不仅能够为我们提供更多的机会和挑战,还能够让我们更好地理解和应用人工智能技术。通过学习AI大模型,我们可以深入了解深度学习、神经网络等核心概念,并将其应用于自然语言处理、计算机视觉、语音识别等领域。同时,掌握AI大模型还能够为我们的职业发展增添竞争力,成为未来技术领域的领导者。
再者,学习AI大模型也能为我们自己创造更多的价值,提供更多的岗位以及副业创收,让自己的生活更上一层楼。
因此,学习AI大模型是一项有前景且值得投入的时间和精力的重要选择。

欢迎加入 MCP 技术社区!与志同道合者携手前行,一同解锁 MCP 技术的无限可能!
更多推荐


 32
32 0
0- 0



 已为社区贡献87条内容
已为社区贡献87条内容

所有评论(0)