文末赠书!大模型时代的基础架构,大模型算力中心建设指南重磅来袭!
--文末赠书--Nvidia(英伟达)作为GPU领域的Top供应商,从2010年起就推出了GPU虚拟化的方案,其大致的发展路线图如图8-1所示。在图8-1中,GPU虚拟化的发展路线分为三个阶段:以vCUDA为代表的APIRemoting阶段、以GRID vGPU为代表的Driver Virtualization(驱动虚拟化)阶段,以及以MIG为代表的Hardware Virtualization(
--文末赠书--
Nvidia(英伟达)作为GPU领域的Top供应商,从2010年起就推出了GPU虚拟化的方案,其大致的发展路线图如图8-1所示。
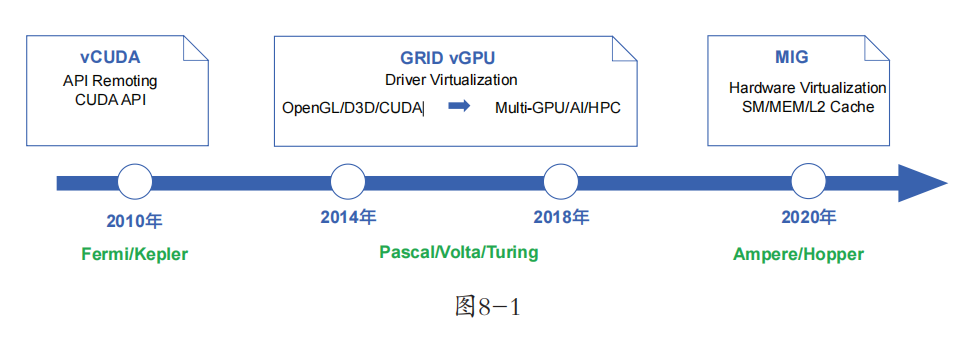
在图8-1中,GPU虚拟化的发展路线分为三个阶段:以vCUDA为代表的APIRemoting阶段、以GRID vGPU为代表的Driver Virtualization(驱动虚拟化)阶段,以及以MIG为代表的Hardware Virtualization(硬件虚拟化)阶段。
API Remoting与vCUDA
vCUDA技术出现于2010年前后,其实现思路是:在虚拟机中提供一个物理GPU的逻辑映像——虚拟GPU,在用户态拦截CUDA API,在虚拟GPU中重定向到真正的物理GPU上执行计算。同时,在宿主机上基于原生的CUDA运行时库和GPU驱动,运行vCUDA服务端,接管虚拟GPU拦截的CUDA API,同时进行计算任务的调度。
vCUDA的工作原理如图8-2所示。
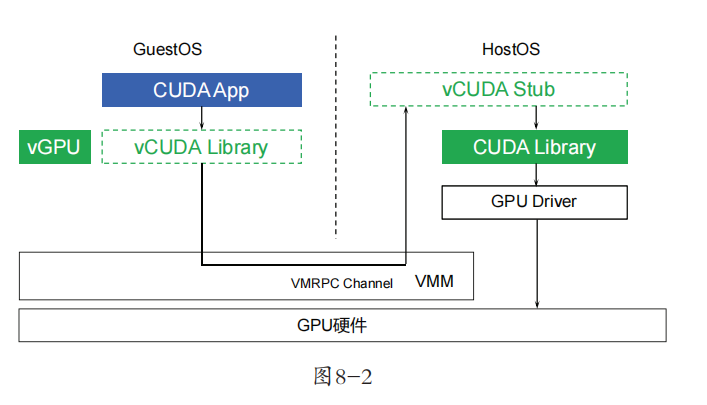
从图8-2可以看出,虚拟机的CUDA运行时库被替换为vCUDA,其作用就是拦截来自CUDA App的所有CUDA API调用。vCUDA运行时库会在内核中调用vGPU驱动(或称之为“客户端驱动”),vGPU驱动实际的作用就是通过虚拟机到宿主机的VMRPC(Virtual Machine Remote Procedure Call)通道,将CUDA调用发送到宿主机。宿主机的vCUDA Stub(管理端)接收到CUDA调用后,调用宿主机上真正的CUDA运行时库和物理GPU驱动,完成GPU运算。
在客户端驱动处理API之前,还需要向管理端申请GPU资源。每一个独立的调用过程都必须向宿主机的管理端申请GPU资源,从而实现GPU资源和任务的实时调度。
显然,vCUDA是一种时间片调度的虚拟化技术,也就是“时分复用”。此种实现对于用户的应用而言是透明的,无须针对虚拟GPU做任何修改,而且也可以实现非常灵活的调度,单GPU能服务的虚拟机数量不受限制。但缺点也是显而易见的:CUDA API只是GPU运算使用的API中的一种,业界还有DirectX/OpenGL等其他API标准,而且同一套API又有多个不同的版本(如DirectX 9和DirectX 11等),兼容性非常复杂。
本文节选自《大模型时代的基础架构:大模型算力中心建设指南》一书
书中不但讲解了大模型相关的基础技术,比如AI基本概念、GPU硬件、软件、虚拟化等,还讲解了大模型基础设施的核心内容,包括GPU集群存储、网络、I/O、算力调度、网络虚拟化、管理和运营等,并结合实际案例,讲解了如何进行机器学习应用开发与运行平台设计,在此过程中把本书中的重点内容“串联”起来进行了讲解,以期读者建立整体的认知。

限时五折优惠,快快抢购吧!
敲黑板!本次 民工哥技术之路 公众号联合 博文视点 为大家带来赠书福利,拼手气的时候到了,看看谁才是锦鲤?
点击下方公众号名片回复关键字 大模型架构 参与抽奖!
规则:
1、民工哥公众号读者专属(同一用户近期多次中奖无效,非IT技术读者请勿参与,发现作弊行为永久拉黑!请把机会留给其他人)。
2、中奖需于 12 小时内主动联系小编发送收货信息,逾期则视为自动放弃。
欢迎加入 MCP 技术社区!与志同道合者携手前行,一同解锁 MCP 技术的无限可能!
更多推荐


 0
0 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)