详解大模型架构——MLA
DeepSeekV2提出了一种优化MQA的方法:MLA(Multi-head Latent Attention)在推理的过程中,所有的key,value都需要被cache以加速推理,因此MHA需要为每个token缓存。在模型部署时,这种大量的KVcache是一个瓶颈,它限制了最大batch size和序列长度。一般MHA会把QKV分成。
·
参考
https://arxiv.org/pdf/2405.04434
https://blog.csdn.net/bqw18744018044/article/details/138751458
https://zhuanlan.zhihu.com/p/714761319
https://spaces.ac.cn/archives/10091
DeepSeekV2提出了一种优化MQA的方法:MLA(Multi-head Latent Attention)
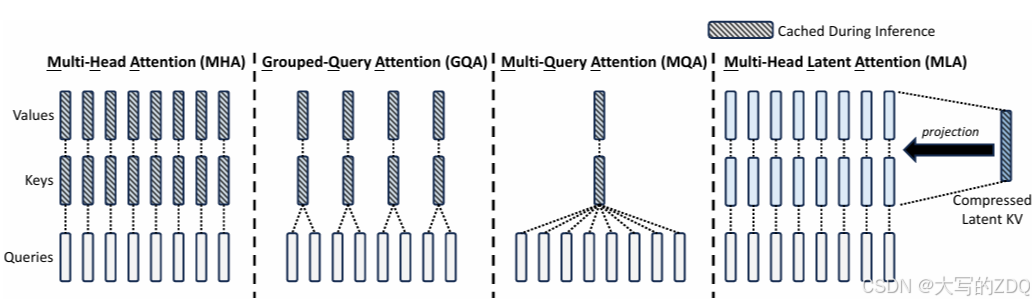
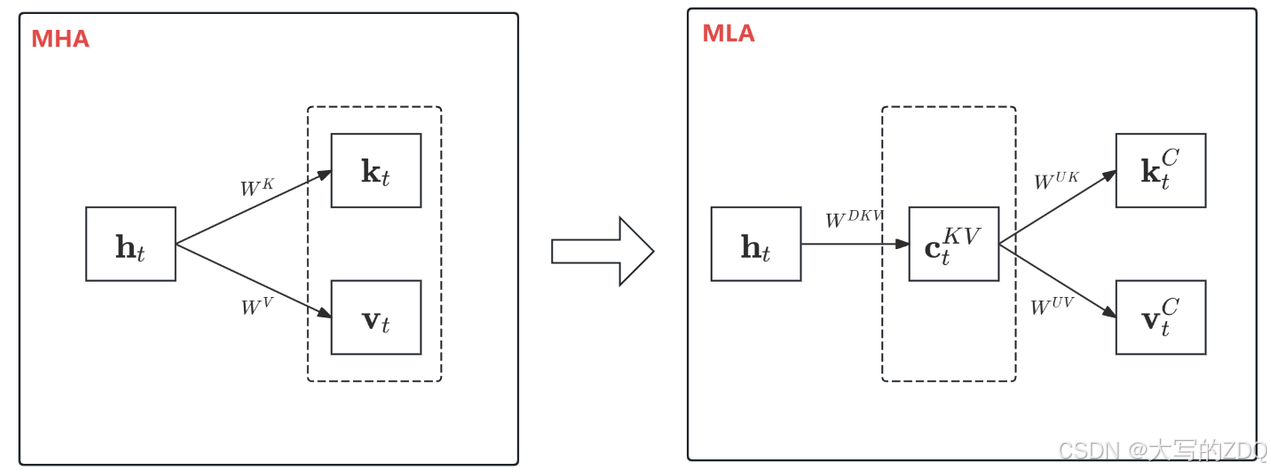
一般MHA会把QKV分成nhnhnh个头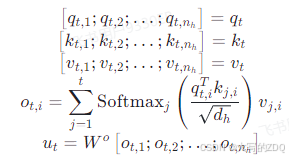
在推理的过程中,所有的key,value都需要被cache以加速推理,因此MHA需要为每个token缓存2nhdhl2nhdhl2nhdhl.
在模型部署时,这种大量的KVcache是一个瓶颈,它限制了最大batch size和序列长度



总结:

欢迎加入 MCP 技术社区!与志同道合者携手前行,一同解锁 MCP 技术的无限可能!
更多推荐


 9
9 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)