大模型全量微调和LoRA微调的区别与选择
模型微调(Fine-tuning)是指在已有预训练模型的基础上,针对特定任务或数据集进行进一步训练的过程。通过微调,可以在相对较小的数据集上取得较好的性能表现,同时减少从头开始训练模型所需的时间和计算资源。
模型微调(Fine-tuning)是指在已有预训练模型的基础上,针对特定任务或数据集进行进一步训练的过程。通过微调,可以在相对较小的数据集上取得较好的性能表现,同时减少从头开始训练模型所需的时间和计算资源。
微调的好处
- 节省时间与资源:相比于从零开始训练模型,微调利用了预训练模型已经学到的特征,大大减少了所需的计算资源和时间。
- 提高性能:对于小规模数据集,直接训练可能会导致过拟合问题,而微调能有效提升模型的泛化能力。
- 快速适应新领域:通过微调,可以迅速让模型适应新的应用场景或数据类型。
微调的应用场景
微调被广泛应用于各种需要深度学习模型的场景中,包括但不限于:
- 文本分类、情感分析等NLP任务
- 图像识别、目标检测等计算机视觉任务
- 语音识别、机器翻译等领域
一、全量微调(Full Fine-Tuning)
定义:
全量微调是指在迁移学习中,对预训练模型(如BERT、GPT)的所有参数进行更新,使其适应特定下游任务。
技术原理:
- 参数更新:通过反向传播调整模型每一层的权重(包括嵌入层、注意力层、全连接层等)。
- 优化目标:最小化任务特定损失函数(如交叉熵损失),利用梯度下降(如Adam)更新参数。
- 数学表示:
若原始模型参数为 WWW,微调后参数变为 W′=W+ΔWW' = W + \Delta WW′=W+ΔW,其中 ΔW\Delta WΔW 通过训练数据计算得出。
作用:
- 高适应性:全面调整模型参数,充分捕捉任务特征,通常在数据充足时性能更优。
- 适用场景:计算资源充足、任务与预训练领域差异较大时(如医学文本分类)。
缺点:
- 计算成本高:需存储和更新全部参数,对大型模型(如GPT-3)训练成本极高。
- 过拟合风险:小数据任务易过拟合,需额外正则化(如早停、Dropout)。
二、LoRA微调(Low-Rank Adaptation)
定义:
LoRA是一种参数高效微调方法,通过引入低秩矩阵(Low-Rank Matrices)调整模型部分参数,减少可训练参数量。
技术原理:
- 低秩分解:将权重更新 ΔW\Delta WΔW 分解为两个小矩阵的乘积:
ΔW=A⋅B(A∈Rd×r,B∈Rr×d,r≪d)\Delta W = A \cdot B \quad (A \in \mathbb{R}^{d \times r}, B \in \mathbb{R}^{r \times d}, r \ll d)ΔW=A⋅B(A∈Rd×r,B∈Rr×d,r≪d)
其中 rrr 为秩(通常为8-64),参数量从 d2d^2d2 降至 2dr2dr2dr。 - 冻结原始参数:保持预训练权重 WWW 不变,仅训练 AAA 和 BBB。
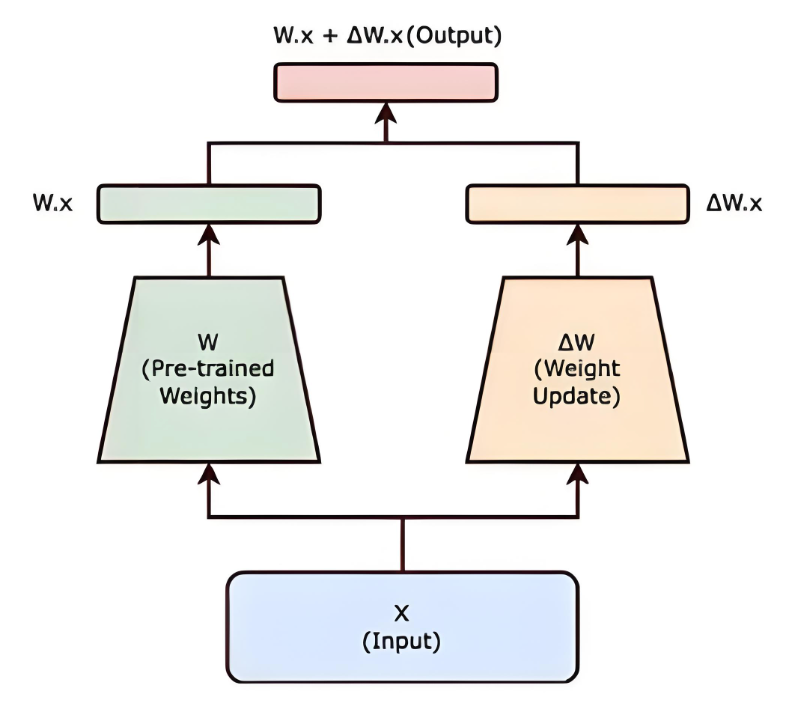
- 前向计算:调整后的输出为:
h=Wx+ΔWx=Wx+A(Bx)h = Wx + \Delta Wx = Wx + A(Bx)h=Wx+ΔWx=Wx+A(Bx)
作用:
- 高效训练:可训练参数减少90%以上,大幅降低显存占用和计算成本。
- 避免灾难性遗忘:保留原始模型知识,适合多任务学习。
- 适用场景:资源受限场景(如单卡训练)、需要快速迭代的任务(如对话系统)。
优点:
- 轻量化:可在消费级GPU(如RTX 3090)上微调大模型(如LLaMA-7B)。
- 模块化:训练后的 AAA 和 BBB 可单独保存,灵活组合不同任务适配器。
三、全量微调 vs LoRA 对比
| 维度 | 全量微调 | LoRA微调 |
|---|---|---|
| 可训练参数量 | 全部参数(如GPT-3的175B) | 仅低秩矩阵(如0.1%参数) |
| 显存占用 | 高(需存储参数+梯度+优化器状态) | 低(仅需额外存储A和B的梯度) |
| 训练速度 | 慢 | 快(参数少,通信开销低) |
| 适用模型规模 | 中小型模型(如BERT-base) | 大型模型(如LLaMA-65B) |
| 任务适配性 | 高(全面调整模型) | 中(依赖低秩近似能力) |
| 部署灵活性 | 需保存完整模型 | 可动态加载不同任务的适配器 |
四、技术细节与选择建议
-
LoRA实现要点:
- 层选择:通常应用于Transformer的注意力层(Q、K、V矩阵)和全连接层。
- 秩选择:秩 rrr 越大,表征能力越强,但参数量增加。实践中常取 r=8r=8r=8 或 r=16r=16r=16。
- 初始化:矩阵 AAA 使用高斯初始化,BBB 初始化为零矩阵,确保训练初始阶段 ΔW=0\Delta W = 0ΔW=0。
-
选择建议:
- 数据量充足 → 全量微调(性能优先)。
- 资源有限或需快速迭代 → LoRA(效率优先)。
- 多任务学习 → LoRA(灵活部署不同适配器)。
五、微调总结
- 全量微调:资源允许时的性能最优解,适合领域差异大的任务。
- LoRA:资源受限场景的高效替代方案,平衡性能与成本,尤其适合大模型轻量化微调。
- 趋势:LoRA与QLoRA(量化+LoRA)等技术结合,进一步推动大模型平民化应用。
六、微调原理的简单示例
6.1. 全量微调(Full Fine-Tuning)
核心思想:调整模型的所有参数,使其适应新任务。
类比:就像重新装修一栋房子,所有房间的墙壁、地板、家具都要修改。
简单例子(线性回归模型)
假设有一个预训练好的简单模型,用于预测房价:
y=w1⋅x1+w2⋅x2+by = w_1 \cdot x_1 + w_2 \cdot x_2 + by=w1⋅x1+w2⋅x2+b
- x1x_1x1: 房屋面积
- x2x_2x2: 房间数量
- w1,w2w_1, w_2w1,w2: 权重参数
- bbb: 偏置项
预训练阶段:模型已学习到 w1=100w_1=100w1=100, w2=50w_2=50w2=50, b=10b=10b=10(单位:万元)。
全量微调:
- 新任务:预测办公室租金(与住宅特征不同)。
- 调整方式:通过新数据(办公室租金数据)重新训练 所有参数 w1,w2,bw_1, w_2, bw1,w2,b,最终可能变为 w1=80w_1=80w1=80, w2=30w_2=30w2=30, b=20b=20b=20。
特点:
- 所有参数都被修改。
- 计算成本高(需调整每个参数)。
6.2. LoRA微调(Low-Rank Adaptation)
核心思想:通过低秩矩阵调整部分参数,减少计算量。
类比:在原有房子上添加可拆卸的模块化家具(如书架、隔断),而不是拆墙重建。
简单例子(矩阵分解)
假设原模型有一个权重矩阵 W∈R1000×1000W \in \mathbb{R}^{1000 \times 1000}W∈R1000×1000(100万参数),用于提取特征:
h=W⋅xh = W \cdot xh=W⋅x
LoRA微调步骤:
- 冻结原参数:保持 WWW 不变。
- 引入低秩矩阵:
- 分解权重更新量 ΔW\Delta WΔW 为两个小矩阵的乘积:
ΔW=A⋅B(A∈R1000×8,B∈R8×1000)\Delta W = A \cdot B \quad (A \in \mathbb{R}^{1000 \times 8}, B \in \mathbb{R}^{8 \times 1000})ΔW=A⋅B(A∈R1000×8,B∈R8×1000) - 参数总量:1000×8+8×1000=16,0001000 \times 8 + 8 \times 1000 = 16,0001000×8+8×1000=16,000(仅为原参数的1.6%)。
- 分解权重更新量 ΔW\Delta WΔW 为两个小矩阵的乘积:
- 调整输出:
h=W⋅x+A⋅(B⋅x)h = W \cdot x + A \cdot (B \cdot x)h=W⋅x+A⋅(B⋅x)
效果:
- 仅训练 AAA 和 BBB,不改变原始 WWW。
- 例如,原 WWW 学习的是通用特征,而 A⋅BA \cdot BA⋅B 学习任务特定特征(如办公室租金与住宅的差异)。
6.3. 对比总结
| 场景 | 全量微调 | LoRA微调 |
|---|---|---|
| 参数调整 | 调整所有参数(100万个) | 仅调整低秩矩阵(1.6万个) |
| 计算成本 | 高(需更新所有参数梯度) | 低(梯度计算量减少98%以上) |
| 适用性 | 数据充足、任务差异大 | 数据少、资源有限、需快速迭代 |
| 结果保存 | 保存整个模型(100MB) | 仅保存小矩阵 AAA 和 BBB(16KB) |
七、现实类比
- 全量微调:重新训练一只狗学会所有新技能(坐下、握手、装死),需要从头调整所有行为。
- LoRA微调:给狗戴上一个“技能模块”(如语音指令接收器),只需训练它响应新指令,原有技能保持不变。
通过这种高效调整,LoRA既能保留预训练模型的通用能力,又能快速适配新任务。

欢迎加入 MCP 技术社区!与志同道合者携手前行,一同解锁 MCP 技术的无限可能!
更多推荐


 7
7 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)