【AI大模型】为什么Transformer需要Adam?
Transformer模型已成为AI发展的主要驱动力。然而,对Transformer训练的理解仍然有限。一个引人注目的现象是,Transformer的训练在很大程度上依赖于Adam优化器,相比之下,随机梯度下降与动量(SGD)在Transformer上的表现明显不如Adam(例如,见图3)。但是,造成这种性能差距的原因仍不清楚。
前言
最近在进行大模型的持续预训练,调研炼丹的过程中,看到了一篇关于优化器选择有关的论文《Why Transformers Need Adam: A Hessian Perspective 》,论文从 Hessian 矩阵的视角,去分析了为什么 Adam 优化器在 Transformer 模型上优于 SGD。一个非常有趣的发现,虽说现在大多数的训练框架,默认的优化器就是 Adam 或者 AdamW,但其机制和原理,这篇论文的作者给出了详细的实验分析。
1. 引言
Transformer模型已成为AI发展的主要驱动力。然而,对Transformer训练的理解仍然有限。一个引人注目的现象是,Transformer的训练在很大程度上依赖于Adam优化器,相比之下,随机梯度下降与动量(SGD)在Transformer上的表现明显不如Adam(例如,见图3)。但是,造成这种性能差距的原因仍不清楚。
本文通过Hessian矩阵的视角探索了为什么SGD在Transformer上表现不如Adam。研究从调查Transformer的完整Hessian谱开始,即Hessian的完整特征值密度(见图1)。理论上,完整的Hessian谱在很大程度上决定了基于梯度的方法的行为。
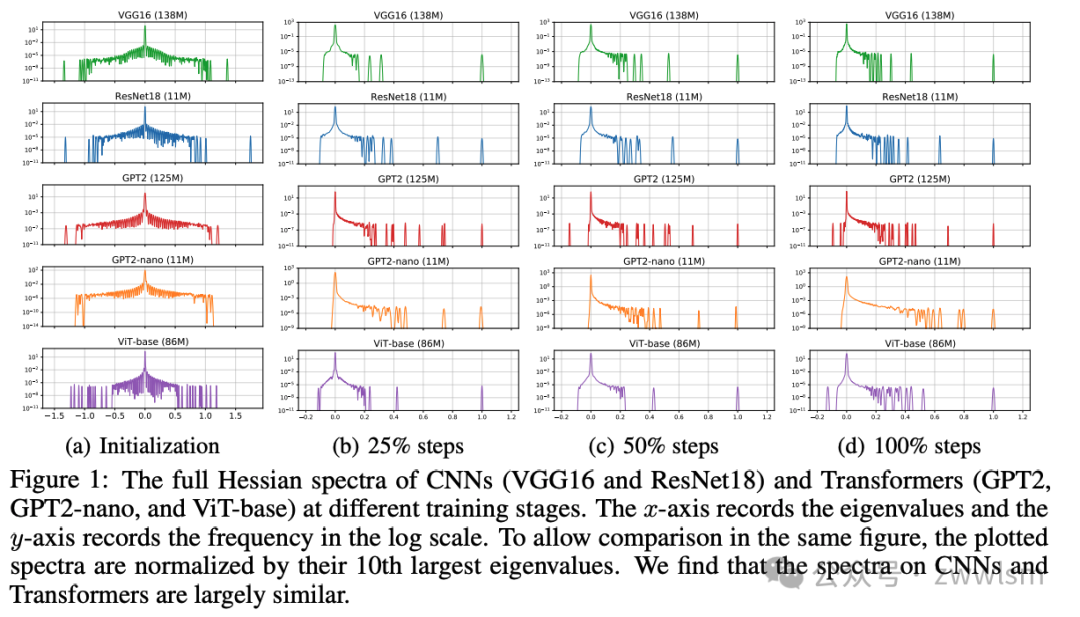
作者使用数值线性代数工具,比较了CNNs(SGD与Adam表现相当)和Transformers(SGD明显落后于Adam)的完整谱。然而,如图1所示,尽管优化器行为不同,CNNs和Transformers的谱通常非常相似。因此,作者未能在完整的Hessian谱中识别出与Transformer上Adam和SGD之间差距相关的关键特征。为了揭示原因,需要对Hessian进行更细粒度的研究。
通过分解CNNs和Transformers的结构,作者注意到CNNs是由相似参数块(卷积层)的重复堆叠构成,而Transformers涉及非顺序堆叠的不同参数块(例如,注意力中的Query、Key、Value块和MLP层)。
基于这些观察,作者提出了一种可能的解释:Transformer固有的"异质性"。他们提供了经验和理论证据来支持这一解释。主要贡献可以总结如下:
-
解释了为什么SGD在Transformer上表现不如Adam,通过检查块wise Hessian谱。
-
识别了一种称为"块异质性"的现象,指不同参数块之间的Hessian谱的巨大差异。
-
验证了块异质性阻碍了SGD的性能。
-
在二次模型上的理论结果,构建了有和没有块异质性的凸二次问题,发现梯度下降(GD)在具有块异质性的问题上明显落后于Adam。
2. 主要结果
2.1 问题设置
作者引入了以下符号:
-
:训练损失
-
:神经网络参数
-
:训练损失相对于神经网络参数的梯度
-
:训练损失的Hessian矩阵
-
:表示索引集
-
: 上的任意划分,其中
-
: 被划分成的 个参数块,其中 由索引在第 个块 中的参数组成
-
$ [\nabla^2 L(w)]l \in \mathbb{R}^{d_l \times d_l} : l 参数块 w_l 的,其中 [\nabla^2 L(w)]{l,i,j} = \frac{\partial^2}{\partial w_{l,i} \partial w_{l,j}}L(w_l) $
注意, 是 的第 个主对角块子矩阵。
2.2 完整Hessian谱的信息不足
作者首先研究了Transformer的完整Hessian谱,原因有二:
-
Hessian谱显著影响基于梯度的方法的行为。
-
先前研究表明,Hessian谱提供了对神经网络现象的洞察,如BatchNorm对训练速度的影响。
作者比较了CNNs(SGD与Adam表现相当)和Transformers(SGD明显落后于Adam)的完整谱,如图1所示。然而,结果表明,完整的Hessian谱可能不足以解释Adam和SGD在Transformer上的性能差距。作者详细分析了以下方面:
-
(A) 谱的离散程度:观察到不同模型的特征值离散程度相似,Transformers没有明显的大离群值。
-
(B) 谱的形状:对于所有CNNs和Transformers,在初始化时谱的形状大致对称分布在0周围。
-
© 训练过程中谱的演化:随着训练进行,大多数负特征值消失,形状演变为"主体"和一些"离群值"的组合。
由于CNNs和Transformers的谱形状和演化相当相似,这些特征无法解释为什么SGD在Transformer上表现较差。因此,需要对Hessian进行更细致的研究。
2.3 通过块wise Hessian谱的主要发现

作者发现了一些在完整Hessian谱分析中被忽视的关键特征:
-
Hessian结构:现有文献表明,MLPs的Hessian接近块对角矩阵。作者在小型Transformers中也观察到近似块对角的Hessian,如图2所示。
-
Transformer的构建规则:CNNs由相似参数块(卷积层)的重复堆叠构成,而Transformers包含非顺序堆叠的不同参数块(如注意力中的Query、Key、Value和MLP层)。
基于这些观察,作者假设块wise Hessian谱,即Hessian主对角块 的谱,可能提供额外的洞察。
作者展示了VGG16(CNN)和BERT(Transformer)的块wise谱形状,如图3所示。在BERT中,嵌入层、注意力层和MLP块的Hessian谱差异很大。相比之下,在ResNet中,卷积层的谱相似。作者进一步计算了所有可能的块对之间特征值密度的Jensen-Shannon(JS)距离,结果如图4所示。
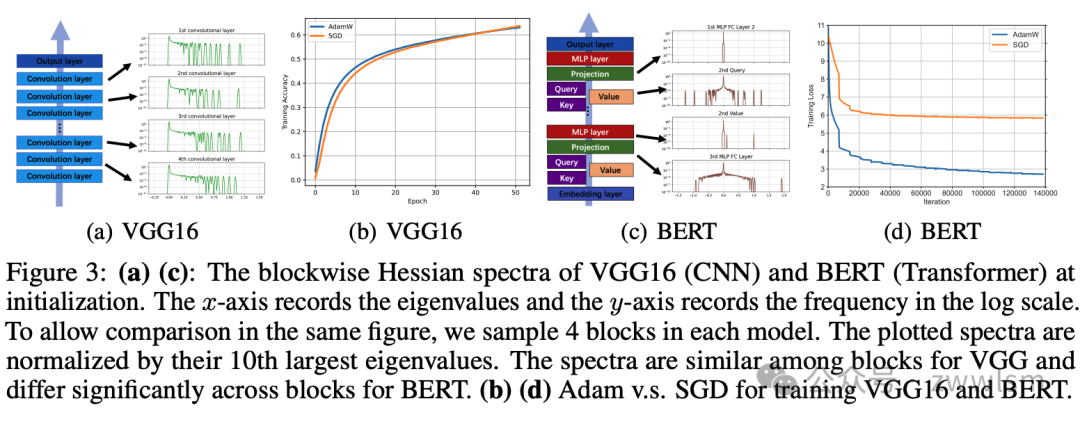
这些结果揭示了一个新现象:在所有检查的Transformers中,块wise Hessian谱在不同块之间差异很大。作者将这种现象称为"块异质性"。相比之下,CNNs的块wise Hessian谱相似,没有观察到块异质性。这表明块异质性是区分CNNs和Transformers的一个重要特征。
2.4 SGD在具有块异质性的各种任务上表现比Adam差
为了直接建立"块异质性"和"为什么SGD比Adam差"之间的联系,作者考虑了一个人为构造的例子和一个真实世界的例子:
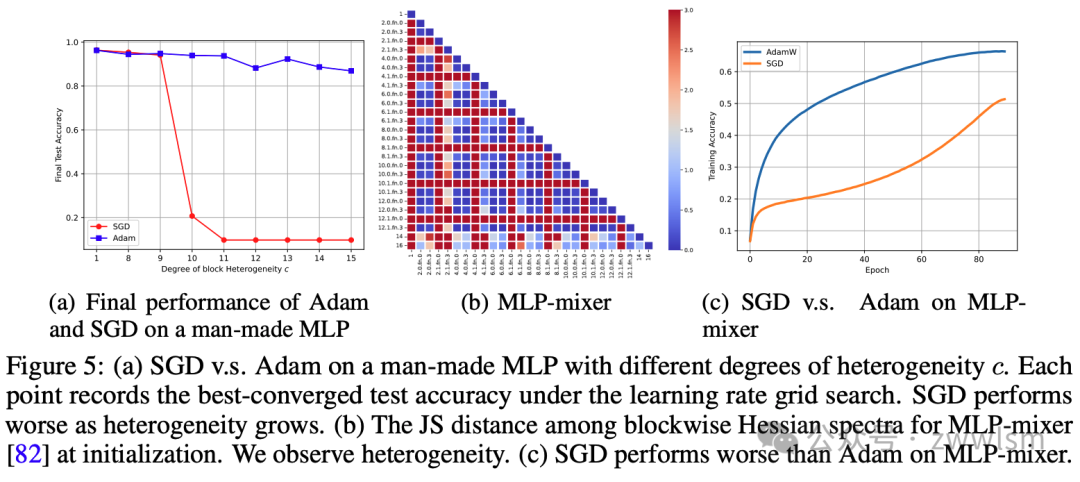
-
人为构造的MLP:作者考虑了在MNIST上训练的4层MLP,通过缩放每一层来改变异质性程度。图5(a)显示,随着异质性的增加,SGD的表现逐渐变差。
-
MLP-mixer:这是一个著名的全MLP架构,在某些视觉任务上优于CNNs和ViTs。图5(b)©显示,MLP-mixer的初始Hessian具有块异质性,SGD在这种架构上落后于Adam。
2.5 预训练Transformer中块异质性的减少
作者指出,不同的Transformers表现出不同程度的块异质性。虽然所有检查的Transformers都显示出强烈的块异质性,但这种异质性可以得到缓解,从而减少SGD的性能下降。
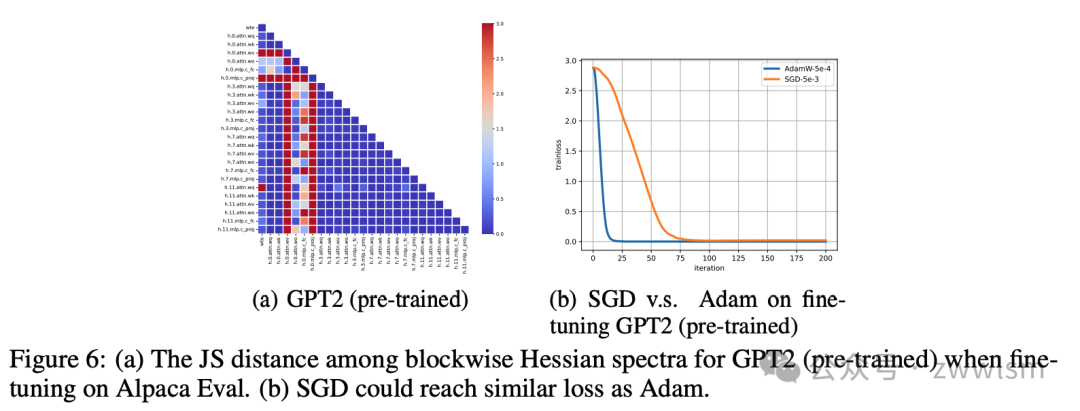
如图6所示,在SFT任务上预训练的GPT2比从头开始预训练的GPT2(图4(f))表现出更少的块异质性。在这种情况下,虽然SGD仍然比Adam慢,但最终达到了类似的损失。与从头开始训练GPT2相比(附录B中的图10(d)),SGD和Adam之间的性能差距显著缩小。
这些发现表明,由架构设计引起的异质性可以通过选择"好的"权重来缓解。这部分解释了为什么像SGD甚至其零阶版本这样的简单方法仍然可以有效地微调语言模型,尽管收敛速度较慢。
2.6 选择SGD或Adam的启示
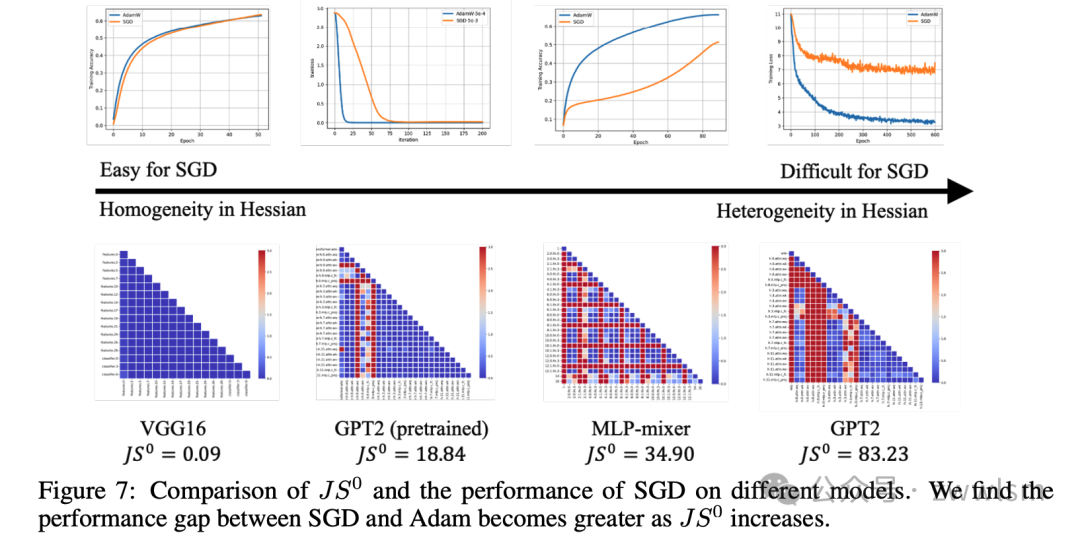
作者提出了一个定量指标,可以在训练开始前预测SGD的不适用性。这个指标是初始化时块wise Hessian谱之间的平均JS距离,记为 。表1列出了各种模型的 值。 建立了Transformer和CNNs损失景观之间的定量差异。此外, 独立于优化器,可以在训练之前检查。

为了验证 的有效性,作者总结了不同模型的 和相应的SGD性能,如图7所示。他们发现,随着 的增加,SGD和Adam之间的性能差距变大。因此, 可以作为预测SGD是否可能表现不如Adam的潜在指标。
3. 二次模型的案例研究和初步理论
3.1 实验观察
作者研究了具有块对角Hessian的二次函数,有和没有块异质性两种情况。他们考虑以下二次最小化问题:

-
Transformer类型谱的Hessian
-
CNN类型谱的Hessian
-
简化的异质谱Hessian
-
简化的同质谱Hessian
他们研究了两类优化器:
-
单一学习率优化器:梯度下降(GD)
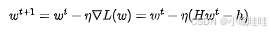
-
坐标wise学习率优化器:Adam(简化版本,无偏差修正)
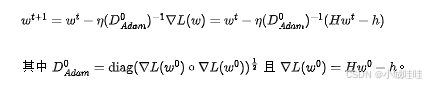
实验观察总结:
-
对于具有异质块的Hessian(情况1和3),GD明显落后于Adam。
-
对于具有同质块的Hessian(情况2和4),GD与Adam表现相当。
作者假设GD表现不佳是因为它对所有块使用单一学习率,无法处理块之间的异质性。这种异质性可以通过使用不同的学习率来更好地处理,这正是Adam的设计特点。
3.2 初步理论结果
作者提供了初步的理论结果,描述了GD如何在具有异质Hessian的问题上落后于Adam。他们首先给出了GD的下界:
命题1(GD的下界)
考虑最小化 ,其中 是正定矩阵,。令 为GD 步后的输出。存在一个块对角矩阵 , 和一个初始点 ,使得对任意 ,都有: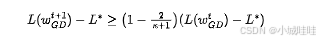
其中 是 的条件数。命题1表明GD的复杂度为 ,且这个复杂度是紧的。
接下来,作者证明Adam可以实现更好的复杂度。这是因为Adam通过其对角预处理器 为不同的块子矩阵 选择不同的学习率。作者考虑了覆盖常用分布(如高斯分布、均匀分布等)的通用随机初始化。
假设1(随机初始化)假设初始化 是从一个连续分布中采样的,即(由 诱导的)任何零Lebesgue测度集的概率为0。
定理1(Adam with 的上界)
考虑与命题1相同的设置,考虑 且 的Adam,如式(2)所示。假设初始化满足假设1。令 为Adam 步后的输出。令 。那么以概率1,我们有: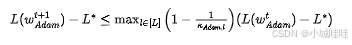
其中 , 是 的条件数,常数 与 相关,定义为:
$ r = \frac\max_{l \in [L]} C_{l,2}^2}{\min_{l \in [L]} C_{l,1}^2}, \text{其中} C_{l,1} = \min_{i \in [d_l]}\frac{[\nabla L(w^0)]_{l,i|}\lambda_{l,1}}, C_{l,2} = \max_{i \in [d_l]}\frac{[\nabla L(w^0)]_{l,i|}{\lambda_{l,1}} $
定理1表明Adam(with )的复杂度为 。系数 取决于每个块的初始梯度与主特征值之比,较小的比值会带来更快的收敛速度。
作者进一步指出, 的条件是必要的,因为任何 都会导致非收敛问题。他们重述了先前研究的结果:
命题2(常数学习率Adam with 的非收敛性)
考虑最小化 。考虑 且 的Adam,如式(3)所示。令 为Adam 步后的输出。对于式(3)存在一个离散极限环,且
现在,作者比较了Adam和GD的复杂度。根据定理1,当 时,Adam比GD更快。在具有异质块的二次模型(情况3)中,作者的模拟表明,使用标准高斯随机初始化时,以 的概率 。由于 ,我们有 ,大概率下比 小约5倍。因此,Adam可能比GD快5倍左右,这在图8中得到了验证,Adam明显优于GD。
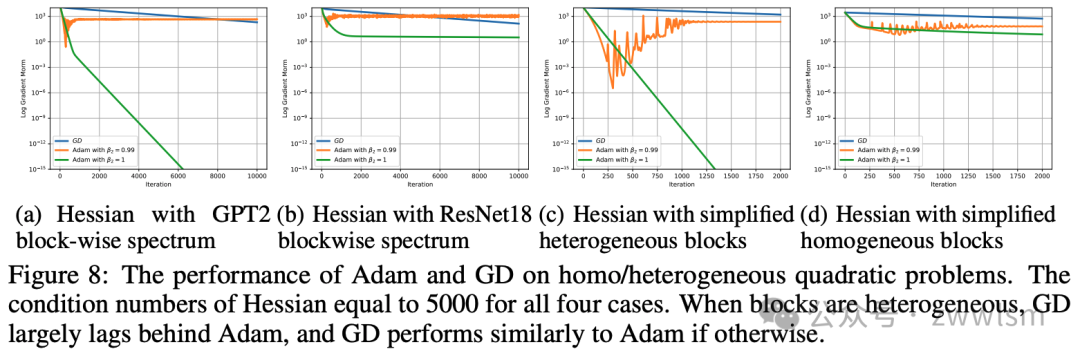
作者在表2中总结了GD和Adam的复杂度:
| 优化器 | GD | Adam with and (2) | Adam with and (3) |
|---|---|---|---|
| 复杂度 | ✗ (不收敛) |
其中 和 分别表示全Hessian和块子矩阵的条件数, 如前面定义。
作者指出,虽然还有改进Adam复杂度上界的空间,但这可能具有挑战性。他们提供了一些技术讨论,指出如果没有 的额外结构,改进因子 可能会很困难。关键的技术步骤是限制预处理矩阵的条件数 。直观上,当 本身具有近似对角结构(如纯对角、三对角或对角占优)时,对角预处理器对 最有效。然而,目前还不清楚这些结构是否在Transformer中成立。
尽管Adam的预处理可能不总是减少"局部"条件数 ,但复杂度中的系数现在独立于"全局"条件数 。如前所述,这种系数的变化可能导致对GD的显著改进。这种复杂度的改进归因于Hessian的块对角结构及其异质的块wise谱。
作者的理论表明:对于具有块异质性的问题,像GD这样的单一学习率方法可能会大大落后于像Adam这样的坐标wise学习率方法。
4. 结论
这篇论文探讨了为什么SGD在Transformer上的表现明显不如Adam。主要发现如下:
-
通过引入"块异质性"的概念,作者解释了SGD在Transformer上表现不佳的原因。块异质性指的是不同参数块之间的Hessian谱的巨大差异。
-
作者在各种Transformers、CNNs和MLPs上验证了块异质性阻碍SGD性能的现象。在具有块异质性的问题上,SGD始终表现比Adam差;而在没有块异质性的问题上,SGD可以与Adam表现相当。
-
在二次模型上的理论分析显示,GD在具有块异质性的问题上可能比Adam慢。这是因为GD对所有块使用单一学习率,而Adam通过为不同块分配不同学习率来缓解这个问题。
-
作者提出了一个定量指标 (初始化时块wise Hessian谱之间的平均JS距离),可以在训练开始前预测SGD的不适用性。
这项研究为理解Transformer训练和更广泛的神经网络优化提供了新的视角。通过引入块wise Hessian谱的概念,作者揭示了Transformer和CNN之间的本质差异,这可能对未来的模型设计和优化策略产生影响。
然而,这项研究也存在一些局限性。例如,由于计算资源的限制,作者无法在更大规模的模型上验证他们的发现。此外,虽然他们提供了初步的理论分析,但还需要更深入的理论工作来完全解释观察到的现象。
未来的研究方向可能包括:
-
在更大规模的模型上验证块异质性现象。
-
开发新的优化算法,能更好地处理块异质性。
-
探索块异质性与其他Transformer现象(如梯度消失/爆炸)之间的潜在联系。
-
研究如何通过架构设计或初始化策略来减少块异质性,从而改善SGD在Transformer上的表现。
最后的最后
感谢你们的阅读和喜欢,作为一位在一线互联网行业奋斗多年的老兵,我深知在这个瞬息万变的技术领域中,持续学习和进步的重要性。
为了帮助更多热爱技术、渴望成长的朋友,我特别整理了一份涵盖大模型领域的宝贵资料集。
这些资料不仅是我多年积累的心血结晶,也是我在行业一线实战经验的总结。
这些学习资料不仅深入浅出,而且非常实用,让大家系统而高效地掌握AI大模型的各个知识点。如果你愿意花时间沉下心来学习,相信它们一定能为你提供实质性的帮助。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
大模型知识脑图
为了成为更好的 AI大模型 开发者,这里为大家提供了总的路线图。它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。
经典书籍阅读
阅读AI大模型经典书籍可以帮助读者提高技术水平,开拓视野,掌握核心技术,提高解决问题的能力,同时也可以借鉴他人的经验。对于想要深入学习AI大模型开发的读者来说,阅读经典书籍是非常有必要的。

实战案例
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

面试资料
我们学习AI大模型必然是想找到高薪的工作,下面这些面试题都是总结当前最新、最热、最高频的面试题,并且每道题都有详细的答案,面试前刷完这套面试题资料,小小offer,不在话下

640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

欢迎加入 MCP 技术社区!与志同道合者携手前行,一同解锁 MCP 技术的无限可能!
更多推荐


 23
23 0
0- 0



 已为社区贡献70条内容
已为社区贡献70条内容

所有评论(0)