神经形态中间表示(NIR):类脑计算的统一指令集 | Nat. Commun
近年来,神经形态计算(Neuromorphic Computing)作为一种模仿大脑计算机制的技术,受到了广泛关注。这种计算方法通过模拟神经元的动力学和突触传输过程,旨在实现更高效的计算方式,尤其是在能耗方面远超传统的冯·诺伊曼架构。神经形态计算通常依赖于硬件和软件的紧密耦合,但其多样性和复杂性使得跨平台复现模型的研究变得困难。目前,神经动力学的数学基础已经非常完备,但由于神经形态硬件和软件的多样

近年来,神经形态计算(Neuromorphic Computing)作为一种模仿大脑计算机制的技术,受到了广泛关注。这种计算方法通过模拟神经元的动力学和突触传输过程,旨在实现更高效的计算方式,尤其是在能耗方面远超传统的冯·诺伊曼架构。神经形态计算通常依赖于硬件和软件的紧密耦合,但其多样性和复杂性使得跨平台复现模型的研究变得困难。

目前,神经动力学的数学基础已经非常完备,但由于神经形态硬件和软件的多样性,各种实现方式难以直接迁移或复现。本论文提出了一种称为NIR的抽象层,用于在数字神经形态系统中执行计算任务。NIR定义了一套通用的计算模型原语,这些原语能够结合连续时间的动力学和离散事件系统。通过这种方式,NIR能够在多个不同的硬件和软件平台之间实现互操作性,同时解决了跨平台研究中的一致性问题。
具体来说,NIR通过将计算任务抽象为图结构,其中每个节点代表一种计算原语。这些计算原语被设计为通用的动力系统,可以在多个硬件和模拟器上运行。本文通过在七个不同的神经形态模拟器和四个不同的硬件平台上复现三种不同的尖峰神经网络模型,证明了NIR的广泛适用性。
研究方法
本文提出的神经形态中间表示(NIR)提供了一种通用的、可组合的计算模型,能够在多个神经形态硬件和软件平台之间实现无缝互操作。NIR的核心思想是通过图结构来表示计算任务,每个图的节点代表一个计算原语,这些原语由一组混合系统定义,结合了连续时间的动力学系统和离散事件。NIR的设计旨在解决现有神经形态平台之间缺乏互操作性的问题,特别是在硬件和软件的开发上经常出现的耦合现象。
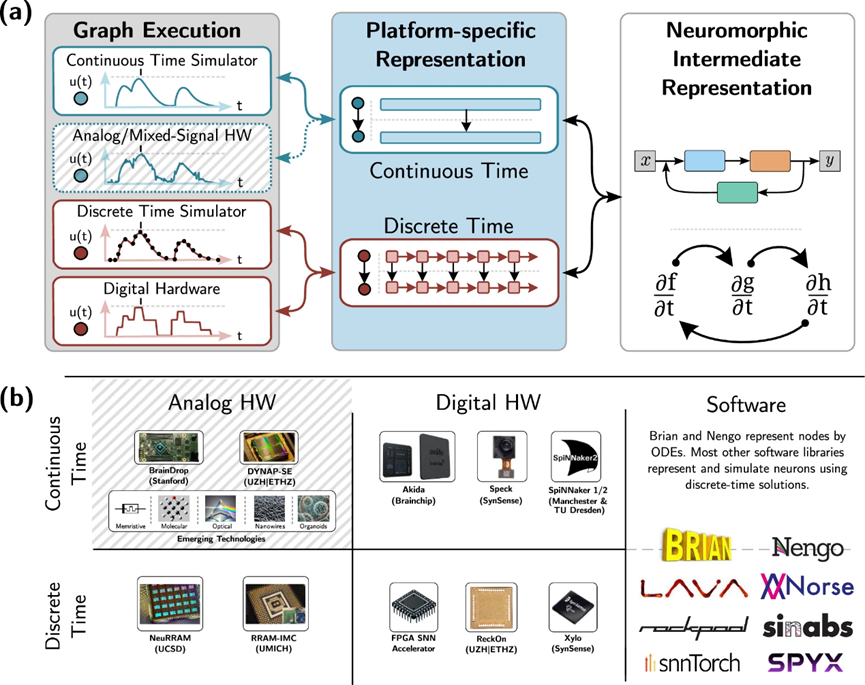
图1 | NIR的概述。a NIR允许特定模型的连续时间表示,然后可以在连续时间硬件或模拟器上执行,或者离散化后用于离散时间硬件或模拟器。b 离散和连续时间硬件和模拟器的分类。展示了一些代表性的硬件系统。模拟连续时间:BrainDrop, DYNAP-SE,以及新兴技术。这些系统被标灰,因为本文不涉及。模拟离散时间:NeuRRAM97, UMich RRAM-IMC98。数字连续时间:Akida, SpiNNaker 1/2, Speck。注意我们在这个类别中包括了具有异步路由的芯片。数字离散时间:通用基于FPGA的SNN加速器,ReckOn, Xylo。
研究方法的具体实现可以分为以下几个步骤:
1. NIR原语的设计与定义
NIR的核心是其计算原语。计算原语是通过定义一组连续时间输入信号和输出信号的变换来描述计算过程。这些原语可以表示常见的神经形态计算组件,如泄漏积分器、线性映射、卷积运算以及尖峰阈值函数等。在NIR中,这些原语被建模为混合系统,可以通过微分方程来描述它们在时间上的演化。
此外,NIR还支持组合更复杂的高阶原语。例如,泄漏积分与发火(LIF)神经元被定义为由一个泄漏积分器和尖峰函数组合而成,这种组合可以描述神经元的行为。
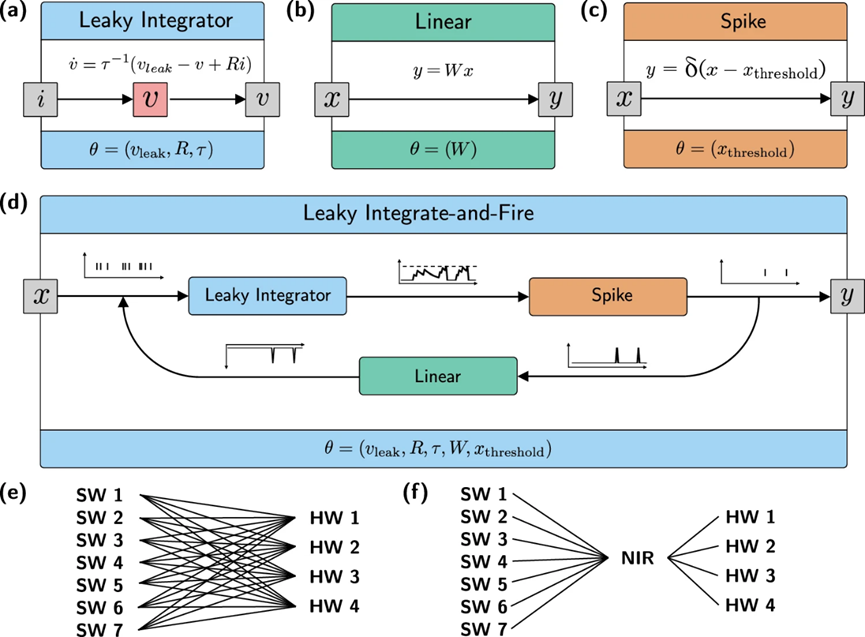 图2 | 原语的组合及其与软件和硬件系统的映射。a-d展示了四种NIR原语,其中原语的名称在顶部突出显示,实现的计算在白色框中说明,与NIR图一起存储的参数在底部突出显示。a展示了一个有状态原语,而(b)和(c)展示了无状态原语,(d)展示了一个高阶原语。e-f说明了中间表示(IR)的概念,包括7个软件(SW)和4个硬件(HW)后端。此外,相较于需要30个不同的编译器来覆盖所有m×n情况(e),实际只需要m+n个接口在每个硬件和软件平台与NIR之间(f)。
图2 | 原语的组合及其与软件和硬件系统的映射。a-d展示了四种NIR原语,其中原语的名称在顶部突出显示,实现的计算在白色框中说明,与NIR图一起存储的参数在底部突出显示。a展示了一个有状态原语,而(b)和(c)展示了无状态原语,(d)展示了一个高阶原语。e-f说明了中间表示(IR)的概念,包括7个软件(SW)和4个硬件(HW)后端。此外,相较于需要30个不同的编译器来覆盖所有m×n情况(e),实际只需要m+n个接口在每个硬件和软件平台与NIR之间(f)。
2. 计算图的构建
在NIR中,所有计算都被表示为计算图。这些图由计算节点(即原语)和连接节点的边构成,每条边表示节点之间的信号传输。计算节点代表神经网络中的基本运算单元,如线性变换、卷积运算或神经元模型;而图中的边则代表从一个节点的输出端口到另一个节点的输入端口的有向连接。
每个计算节点可以包含多个输入端口和输出端口,通过暴露这些端口,原语可以接收多个输入信号并发送多个输出信号。例如,一个神经元可能会接收一个模拟的突触电流输入,同时还接收另一个作为神经调节信号的输入。
3. 平台无关的图转换与实现
NIR的一个主要特点是,它的图结构与底层硬件平台无关。这意味着NIR图可以在多个平台上部署,而不必依赖特定的硬件实现。为了证明这一点,作者设计了几个实验,将相同的NIR图部署到七个神经形态模拟器和四个硬件平台上,包括英特尔的Loihi 2、SynSense Speck、SpiNNaker 2以及SynSense Xylo。这些平台各自具有不同的硬件架构和计算能力,但通过NIR的抽象层,它们能够执行相同的计算任务。
4. 实验设置
在实验部分,作者选择了三种代表性的神经网络模型,分别是单个泄漏积分与发火(LIF)神经元、尖峰卷积神经网络(SCNN)和尖峰递归神经网络(SRNN)。这些任务代表了神经形态计算中常见的任务类型,涵盖了从简单的神经元动力学到复杂的时序关系建模。
1. LIF神经元模型实验:该实验的目的是测试在不同的硬件平台和模拟器上执行相同LIF神经元模型的结果是否一致。作者在所有平台上输入相同的尖峰序列,并记录每个平台的电压变化轨迹和输出尖峰。
2. 尖峰卷积神经网络(SCNN)实验:该实验使用Neuromorphic MNIST数据集训练了一个九层的尖峰卷积网络,网络的架构包括二维卷积、求和池化以及尖峰神经元模型。作者将训练好的网络通过NIR导出,并在不同平台上复现,比较它们在隐藏层的活动和测试集上的准确率。
3. 尖峰递归神经网络(SRNN)实验:此实验使用盲文字符识别任务训练了一个递归神经网络。该网络包含一个隐藏层,使用基于电流的LIF神经元。作者在snnTorch中使用时间反向传播和代理梯度进行训练,然后将网络导出为NIR模型,并在其他平台上进行评估。
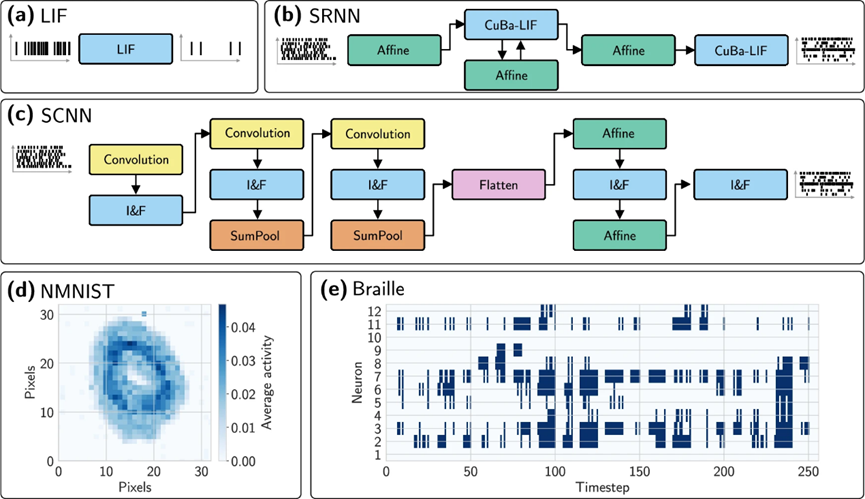 图3 | 实验中使用的计算图和样本数据。a 一个单个的泄漏积分-发射神经元模型(LIF),(b) 一个使用基于电流的泄漏积分-发射(CuBa-LIF)在尖峰递归神经网络(SRNN)中的盲文分类模型,以及 (c) 一个尖峰卷积神经网络(SCNN)。d、e 分别显示了N-MNIST和盲文数据集的样本数据。N-MNIST活动是在300个时间步上平均的。
图3 | 实验中使用的计算图和样本数据。a 一个单个的泄漏积分-发射神经元模型(LIF),(b) 一个使用基于电流的泄漏积分-发射(CuBa-LIF)在尖峰递归神经网络(SRNN)中的盲文分类模型,以及 (c) 一个尖峰卷积神经网络(SCNN)。d、e 分别显示了N-MNIST和盲文数据集的样本数据。N-MNIST活动是在300个时间步上平均的。
研究结果分析
在实验结果分析部分,作者展示了不同平台上执行相同任务的表现,并通过多个指标对比了NIR的跨平台表现。
1. LIF神经元模型的结果
LIF神经元任务是一个简单的任务,旨在评估不同平台上计算的视觉相似性。通过对相同输入尖峰序列的操作,作者比较了各个平台的电压轨迹和输出尖峰。在所有平台上,电压轨迹和尖峰时间基本一致,表明NIR能够有效地跨越不同平台,实现一致的计算表现。然而,也存在一些平台特定的差异。例如,Rockpool和Sinabs在积分方案上有所不同,它们在检查阈值交叉时,会先对输入信号积分再更新泄漏项,而大多数其他平台则会立即更新泄漏项。这样的差异导致了这些平台上的神经元更早地接近触发阈值。
此外,作者还发现,Lava和Loihi 2平台的尖峰时间普遍延迟了一个时间步,这是由于它们在添加输入之前根据膜电位判断神经元是否触发,而其他平台是在膜电位更新之后进行判断。这种系统性差异表明,在信息通过尖峰之间的时间进行编码时,平台的不同实现可能会对模型性能产生影响。
2. SCNN实验的结果
在尖峰卷积神经网络(SCNN)实验中,作者研究了在不同平台上训练和测试SCNN的表现。通过使用Neuromorphic MNIST数据集训练网络,作者将其在各个平台上的表现进行了对比。在保留的测试集上,所有平台的准确率接近,平均测试准确率为97.7%,标准差为0.9%。这些结果表明,NIR能够作为基于速率的尖峰卷积网络的中间表示,在所有测试平台上保持任务的最终性能。
同时,作者进一步分析了SCNN隐藏层的活动,使用时间平均活动的余弦相似度(cosine similarity)作为比较指标。余弦相似度的结果表明,大多数平台的动态表现几乎相同,而Rockpool、Sinabs、snnTorch和Speck由于它们的离散化选择表现出了明显的差异。尽管如此,由于测试集上的准确率相对接近,说明该网络的速率编码和前馈结构对于这些不匹配具有一定的鲁棒性。
3. SRNN实验的结果
在尖峰递归神经网络(SRNN)的实验中,作者观察到不同平台之间的表现差异更加明显。该网络在盲文字符识别任务中训练,经过训练后导出为NIR模型,并在多个平台上执行。然而,与LIF神经元和SCNN相比,SRNN在不同平台上的任务完成性能显示出显著差异。作者推测,这种差异可能是由于SRNN中的循环连接加剧了不同平台在动力学上的细微差异,尤其是在尖峰触发和膜电位复位机制上。这表明,递归网络的复杂动态可能会放大平台之间的实现差异,从而导致最终任务表现的显著差异。
例如,某些平台上的循环神经元模型与训练平台存在细微差异,这些差异可能会影响SRNN的整体性能。作者通过测量循环层的尖峰活动和输出准确率,进一步量化了这些差异,结果表明SRNN模型对平台的具体实现细节更为敏感。
4. 平台之间的错配分析
在讨论平台之间的错配时,作者总结了导致不同平台表现差异的几个主要原因:
神经元模型的实现:不同平台的神经元模型在实现上存在差异,即使是对于看似简单的LIF神经元,也可能由于尖峰和复位时间的不同或离散化选择的差异导致动力学变化。
量化误差:许多神经形态芯片为了降低内存需求和计算功耗,使用了量化技术。量化带来的舍入误差会导致神经元活动的改变,进而影响网络的整体性能。本文仅使用了训练后的量化技术,并未深入研究量化感知训练(QAT)在减少错配方面的效果。
确定性差异:虽然大多数仿真框架在计算上是确定的,但异步硬件(如Speck和SpiNNaker2)并不完全是确定性的,这种可变性可能导致不同平台之间的活动差异。
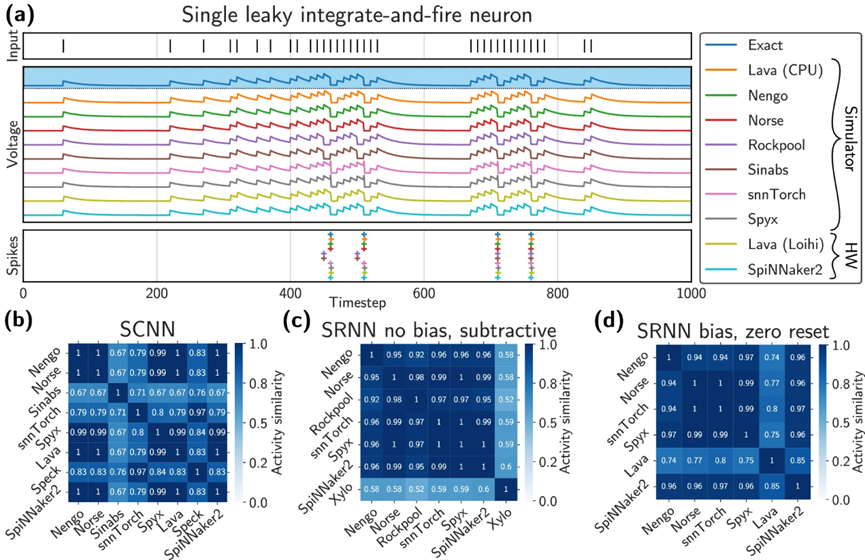
图4 | 实验结果。a 单个泄漏积分-发射神经元在不同平台上的顺序从上到下:输入尖峰、电压迹线和输出激活。尖峰的时间步在Rockpool和Sinabs上由于离散化差异而系统性地有所不同,但整体上是良好对齐的。膜电位被归一化,使其位于静息电位 Vrest=0 和发射阈值 θ 之间,以忽略关于数值表示的特定平台细节。b 尖峰卷积神经网络:使用余弦相似度(1表示完全重叠)对第一个尖峰层的尖峰活动进行平台间比较。Sinabs、snnTorch和Speck由于它们的离散化选择而与大多数其他实现有所偏离。c、d 尖峰递归神经网络:带偏置和重置为零的SRNN与不带偏置和减法重置的SRNN之间,第一个CuBa-LIF层的尖峰活动相似性度量。有关相似性度量的详细信息,请参见正文。
结论展望
通过本文的研究,作者提出并证明了神经形态中间表示(NIR)的有效性,它能够在多个神经形态平台上实现一致的计算表现,并通过其抽象性解决了现有神经形态硬件和软件之间的互操作性问题。NIR的设计使得研究者能够在不同的硬件平台上复现相同的神经网络模型,从而大大简化了跨平台的开发和实验。
展望未来,NIR有望进一步扩展,支持更多复杂的神经网络模型,特别是多室神经元模型、自适应阈值机制以及共振-发火机制等。NIR的模块化设计和平台无关性使其成为神经形态计算领域中一个关键的工具,推动了跨平台互操作性和能效优化的研究发展。
综上所述,本文的研究展示了NIR作为神经形态计算统一中间表示的潜力,并为实现更高效的脑启发计算系统奠定了基础。随着NIR的进一步发展,它将推动神经形态计算领域与现有的深度学习技术并驾齐驱,帮助解决更多实际问题。
仅用于学术分享,若侵权请留言,即时删侵!


加入社群
欢迎加入脑机接口社区交流群,
探讨脑机接口领域话题,实时跟踪脑机接口前沿。
加微信群:
添加微信:RoseBCI【备注:姓名+行业/专业】。
加QQ群:913607986
欢迎来稿
1.欢迎来稿。投稿咨询,请联系微信:RoseBCI
点击投稿:脑机接口社区学术新闻投稿指南
2.加入社区成为兼职创作者,请联系微信:RoseBCI



一键三连「分享」、「点赞」和「在看」
不错过每一条脑机前沿进展

欢迎加入 MCP 技术社区!与志同道合者携手前行,一同解锁 MCP 技术的无限可能!
更多推荐


 23
23 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)