机器学习实战(第二版)读书笔记(5)——通俗易懂Transformer
一、前言:一、前言:2017年Google研究团队提出了“注意力就是你所需要 的一切”,首次创建名为Transformer架构。目前Transformer仍然很热,应用领域也很广,最近读书的时候再次看到了这个模型,所以想写一个总结,旨在全面,浅显得介绍此模型,方便日后回顾。如果有问题欢迎批评指正。阅读本文请先确保了解了一些编码器—解码器,attention机制相关知识。如若不然请先看。
一、前言:
2017年Google研究团队提出了“注意力就是你所需要 的一切”,首次创建名为Transformer架构。目前Transformer仍然很热,应用领域也很广,最近读书的时候再次看到了这个模型,所以想写一个总结,旨在全面,浅显得介绍此模型,方便日后回顾。如果有问题欢迎批评指正。
阅读本文请先确保了解了一些编码器—解码器,attention机制相关知识。如若不然请先看seq2seq模型&注意力机制(BahdanauAttention,LuongAttention)详解。
二、Transformer
Transformer架构如下图1所示,模型由编码器和解码器两部分组成,没有使用任何循环层或卷积层,只有注意力机制(加上嵌入层、密集层、归一化层、位置编码等)。下面将分别进行讲解。
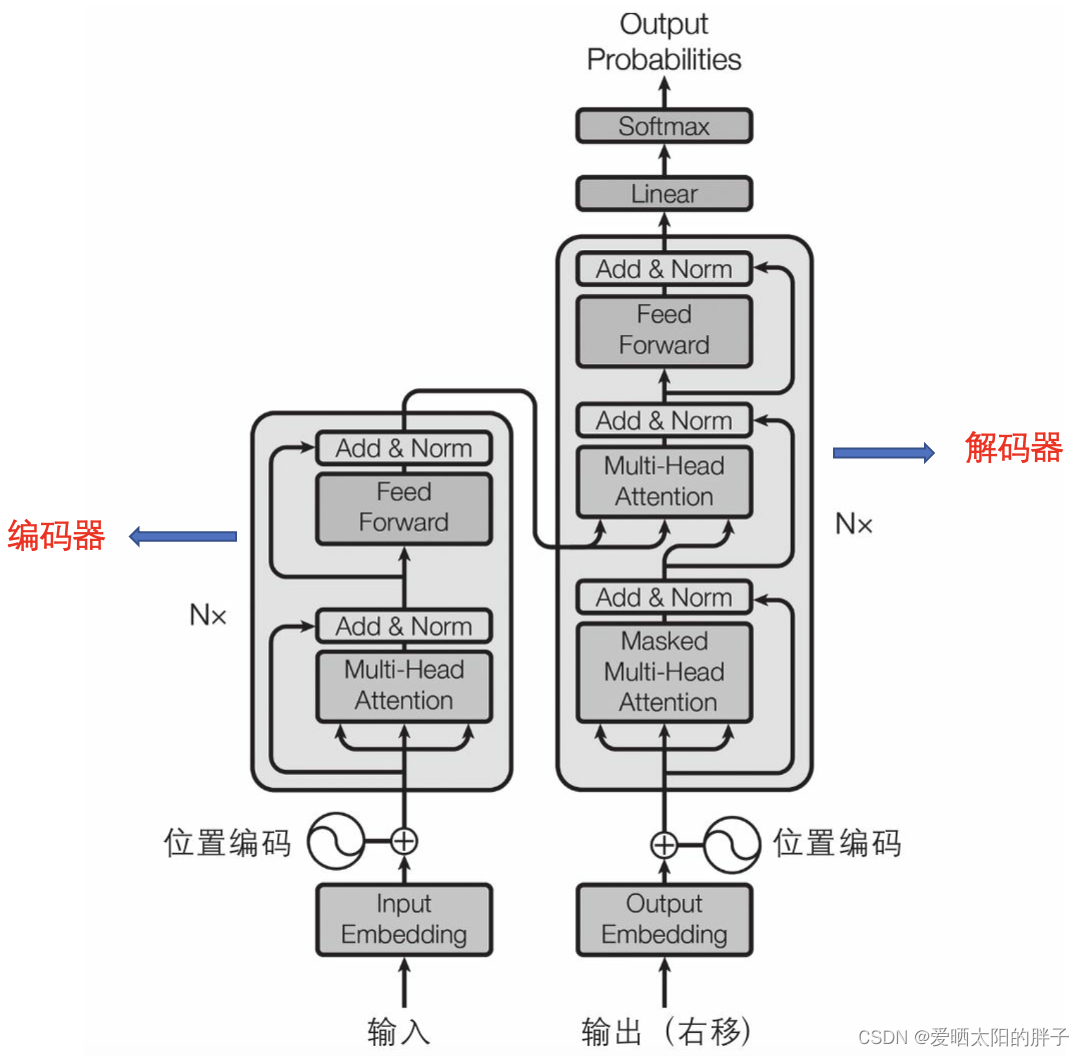
2.1 Transformer中Encoder
左侧是编码器(顶部堆叠了N次,论文中N=6)
作用:对输入的单词序列进行编码,序列中的每个单词的编码维度为512,
输入:[批处理大小,最大输入句子长度] -——>输出:[批处理大小,最大输入句子长度,512]
2.2 Transformer中Decoder
解码器的顶部也堆叠了N次(论文中N=6),编码器堆的输出在N 层的每层中都馈送到解码器。
训练期间:
- 输入:1、目标句子(ID的序列),向右移动一个时间步长(即在序列的开头插入一个序列开始令牌)。2、编码器的输出 (即来自左侧的箭头)。
- 输出:每个时间步长输出每个可能的下一个单词的概率(输出形状为[批处理大小,最大输出句子长度,词汇表长度])。
在推理期间:
- 输入:因无法向解码器提供目标值,因此改为提供先前输出的单词(从序列开始令牌开始)。
- 输出:每个时间步长输出每个可能的下一个单词的概率(在下一 回合中将其馈送到解码器,直到输出序列结束令牌)。
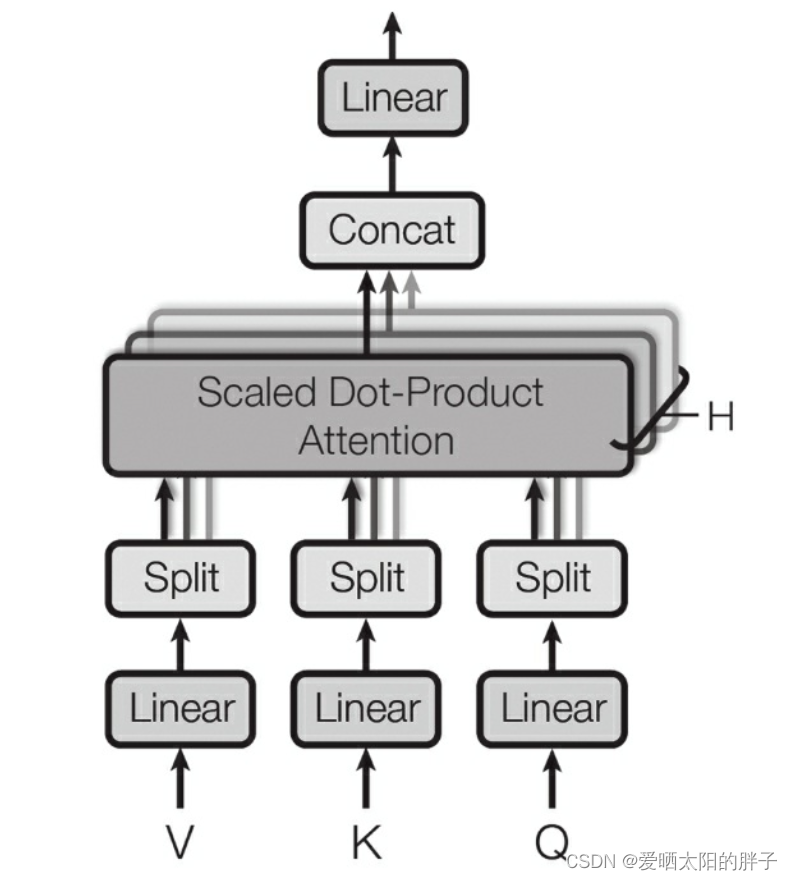
2.3 Multi-Head attention
编码器的多头注意力(Multi-Head Attention)层(图2所示)目的对同一句子中每个单词与其他单词之间的关系进行编码,更加关注最相关的单词。它是缩放点积注意力的堆叠(论文中H=8),所以要理解“多头注意力”层如何工作,我们必须首先理解自注意力及缩放点积注意力。
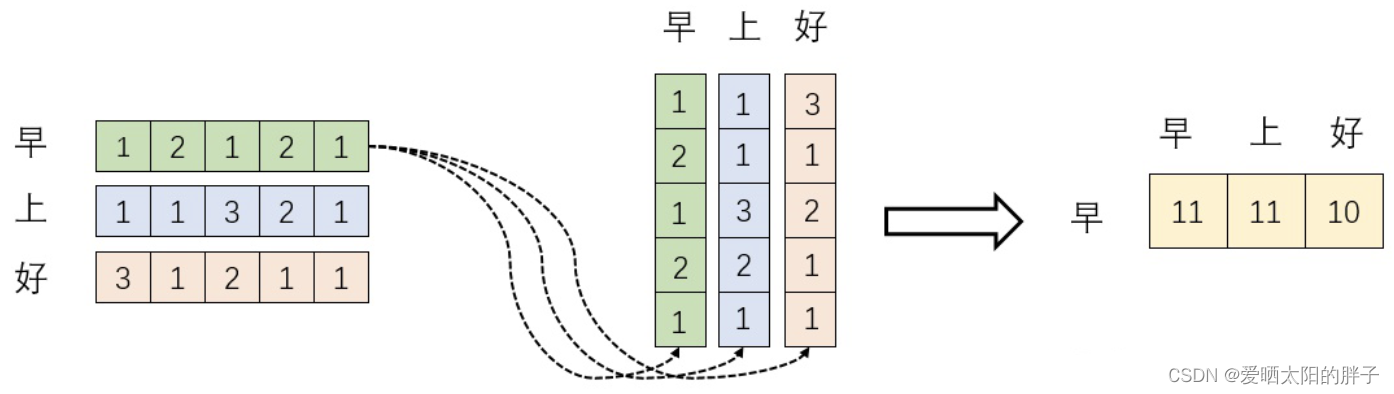
2.3.1 自注意力(self-attention)
为自注意力最原始的公式,
对应下面的图,对应“早”字embedding之后的结果,以此类推。矩阵
是一个方阵,里面保存了每个向量和自己与其他向量进行内积运算的结果,与Luong注意力一样,它表示每个单词与其他单词及本身的相关度。到这,相信这个公式就不难理解了。
2.3.2 缩放点积注意力
公式如图三所示,是不是和上面的公式差不多,只是X换成了Q,K,V。
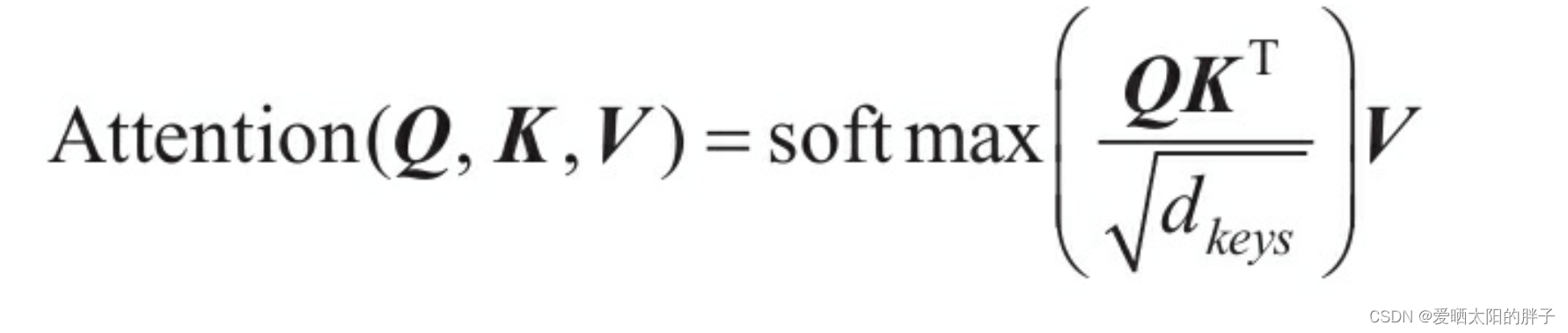
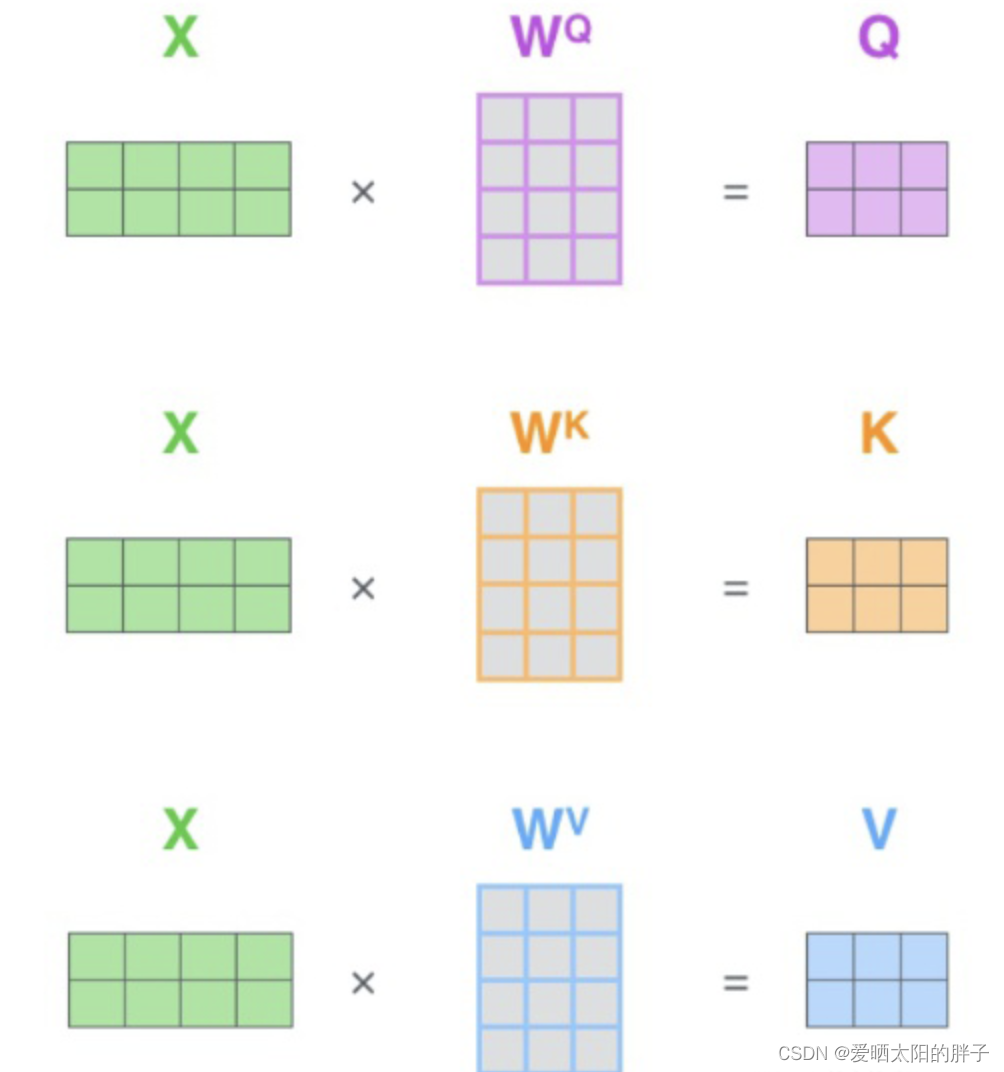
Q,K,V怎么来的呢?其实都是与矩阵的乘积,本质上都是
的线性变换(因为矩阵
都是可以训练的,起到一个缓冲的效果,提高模型的拟合能力。 Multi-Head attention就是有8组不同的
,
,
,计算出8组不同的Q,K,V,然后得到8组不通的Attention(Q,K,V),然后讲他们concat。
的意义:这使得的softmax分布的陡峭程度和d成功解耦,从而使得Transformer在训练过程中的梯度值保持稳定
2.4、位置嵌入
为什么需要位置编码:
如果词语出现位置不同,意思可能发生翻天覆地的变化。Transformer 的是基于self-Attention地,而self-attention是不能获取词语位置信息地,就算打乱一句话中词语的位置,每个词还是能与其他词之间计算attention值。
位置编码公式如下,具体怎么来的可以去看原文:
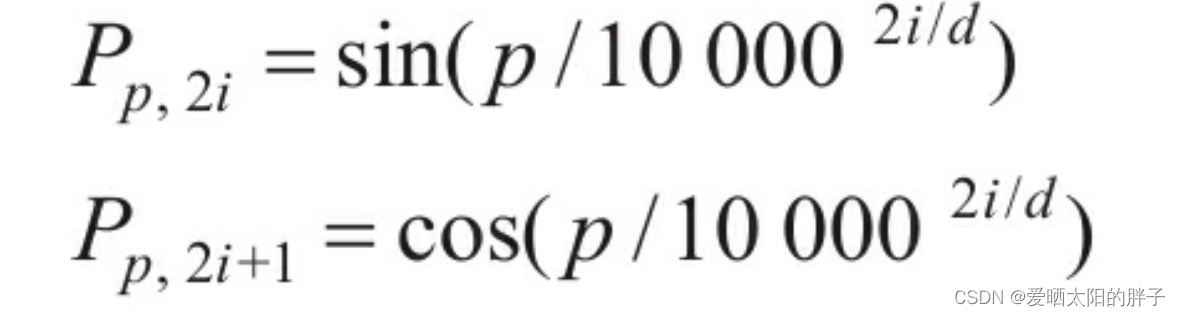
位置嵌入和特征嵌入明显是异构的那么为什么不是连接,而是累加:
有上面公式可以看出两者效果相同,但 concat会引入额外参数。

欢迎加入 MCP 技术社区!与志同道合者携手前行,一同解锁 MCP 技术的无限可能!
更多推荐


 2
2 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)