w~大模型~合集25
还记得去年的「百模大战」吗?现在,科技领域的大模型军备竞赛形势已经有了改变,竞争不再是单纯的模型技术,而变成了拼体系 —— 除了模型技术的升级改进,各家厂商正在整合与调优基础底座,开放的趋势也在催生出逐渐繁荣的生态。如今,战火已经燃烧到了多模态技术的落地上。能够睁开眼睛看世界的大模型,为我们带来了更多的想象力。而为了在千行百业中用好它们,真正实现「重做所有产品」,一套完整的体系势必能让我们事半功倍
我自己的原文哦~ https://blog.51cto.com/whaosoft/12750431
#AI4Science
AI4Science还是伪命题吗?两年后workshop组织者重新审视AI4Science
2021年,一群热血青年提出了要把AI4Science(AI for Science)带入机器学习顶会NeurIPS。
什么?AI4Science是一门学科吗?是不是靠着AI蹭热点?各种质疑声接踵而来。
这些质疑和不解也反映在了第一届AI4Science workshop的较为平淡的群众参与度上。
时过境迁,两年的时间见证了DeepMind基于AlphaFold建立Isomorphic Lab,微软建立AI4Science Initiative, 以及国内深势科技,AISI等大力推动AI4Science建设的企业,学术机构的不断发展壮大。
2023年8月,Al4Science workshop组织者们还在《自然》杂志上发表了一篇综述文章,总结了过去几年里Al4Science在科学发现流程上的进展,并为未来指了指路。
去年12月NeurIPS,AI4Science workshop收到超过200篇投稿和上千人次的参与,俨然成为了NeurIPS最大的workshop之一。看到这些数字,似乎已经没有人再说AI4Science是伪命题了。
近日,Al4Science workshop组织者们发表一篇博客。提到了为什么要强调AI4Science?总结了AI4Science在2023年取得的进展,涵盖了从化学、生物、计算机科学/数学科学、物理、地球科学、神经科学到医学的各个领域。最后,组织者们送上了他们对AI4Science在2024年发展的期望。
Blog 地址:https://medium.com/@AI_for_Science/ai-for-science-in-2023-a-community-primer-d2c2db37e9a7
为什么要强调AI4Science?
随着AI在多个学科各放异彩,另一个问题接踵而至,为什么要强调AI4Science,大家分别做AI在子领域的应用,比如AI4Drug和AI4Materials,不就好了吗?组织者们指出了这样几个原因。
- 跨领域的协同作用:AI4Science的诞生,不仅促进了AI和各种科学学科之间的协同关系,还在AI和科学的不同子领域间搭建了桥梁。这种跨学科的互动,就像给科学研究加了一把火,不断在不同领域催生交融的解决方案。
- 知识的层级组织:就像学科的不同分类一样,AI4Science代表了一个更高阶的领域,它包含并超越了专门的子领域。AI4Science提供了一个宏观视角,将AI在特定科学领域的更专注应用连接起来,并赋予它们更广泛的背景和意义。
- 解决社群大挑战:AI4Science独具慧眼,专门解决广泛的、超越单一学科的社群大规模挑战。通过集合多元化的观点和专长,我们的社群不仅能对付科学难题,还能面对诸如多样性、资源、道德和教育等社群系统性挑战
- 独特的协作机会: AI4Science汇集了面临共同挑战和方法论的各领域专家,并且培养年轻一代共享知识,更有效地解决复杂问题的习惯。
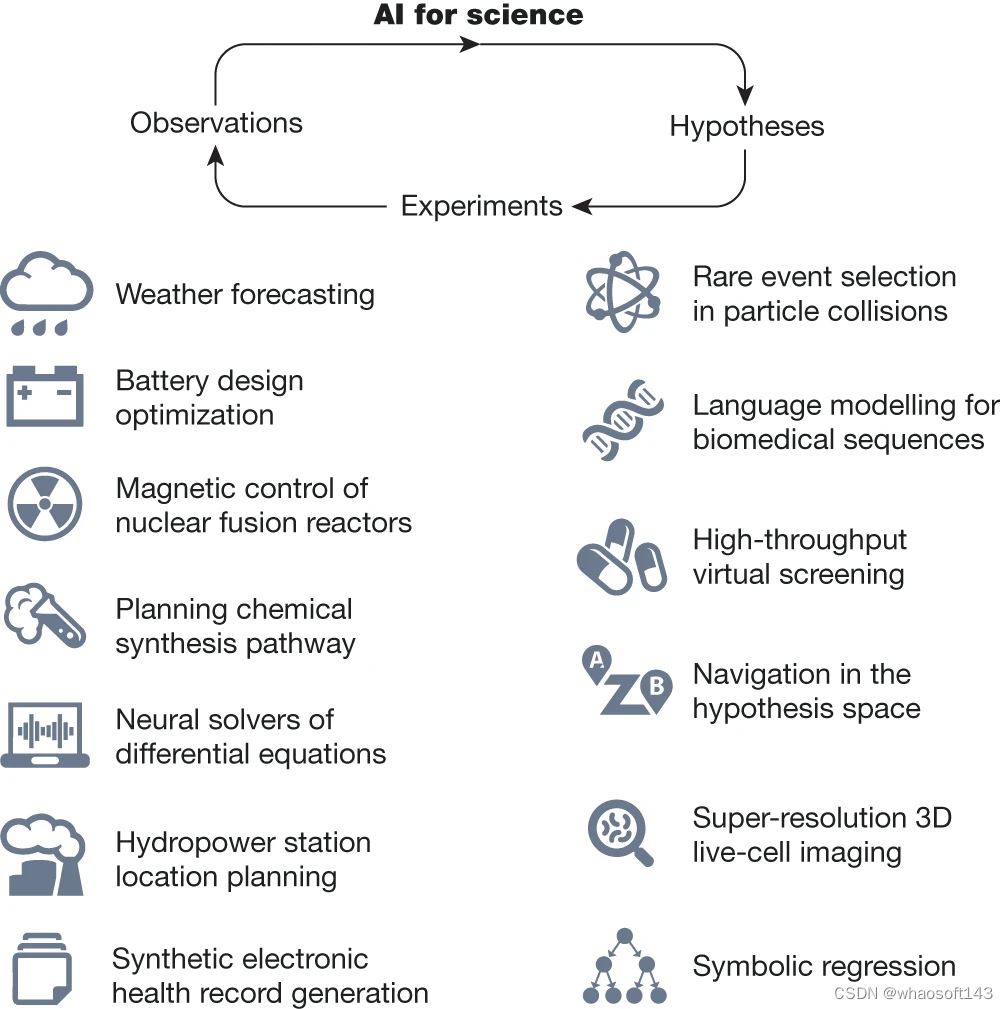
AI4Science在2023年到底有什么进展呢?
说了这么多,AI4Science在2023年到底有什么进展呢?组织者们先是给出了一些概括性的总结:
- 大型语言模型(LLMs)正影响着所有领域。它们改变了人类与机器的互动方式,并展示了在各个领域的影响力,从化学和生物学的实验规划,到计算机科学中寻找更好的算法,乃至在医学中扮演通才型AI代理。说白了,LLMs就像万金油,无所不能,不仅帮你搞对话小助手,还能帮你做实验。
- 自动化实验室用于数据生成和实验。过去一年里,将AI集成到实验规划中,并使用机器人进行自动化执行,这一大进步架起了实验合成和验证之间的桥梁。虽然这些举措还处于发展的初期阶段,但它们展示了不错的潜力,不仅能测试AI规划算法,还能显著提高数据生成的质量和数量。这反过来加速了实验验证,有助于完成AI发现的闭环。
- 生成模型用于设计。不只有LLM可以帮助我们生成,扩散模型也可以!扩散模型在多个领域,如设计新功能蛋白、捕获化学反应中的过渡结构、从大脑活动重构图像,和量子色动力学中采样场配置方面均取得了成功。
- 发展原子大模型。通用的预训练得到大模型,随后在下游任务中进行微调。这种做法在科学领域越来越流行。去年这一方面的努力,尤其是针对原子力场和生物系统的“基础大模型”,逐渐多了起来。
- 大型科技公司正在推动AI4Science的边界。微软、谷歌DeepMind、Meta、英伟达这样的大型科技公司对AI4Science投入明显增加。他们卓越的计算能力和AI科学家的储备在推动利用AI的各个科学领域的进步方面越来越有影响力。
- 开源闭源之争。遗憾的是,近一年越来越多的AI4Science工作选择不开源,连学术界都不例外。这呼吁我们重新探讨重点为可重复性的出版标准。这种讨论对于指导科学界负责任且有效的共享至关重要。毕竟AI相关的领域就是凭借着开源才一直高速发展的。
回顾2023一年的AI4Science,组织者们将七大学科分了分类,其中物理,化学材料,生物和医药的发展日益成熟,慢慢与实验结合并且逐渐走向商业化。
物理
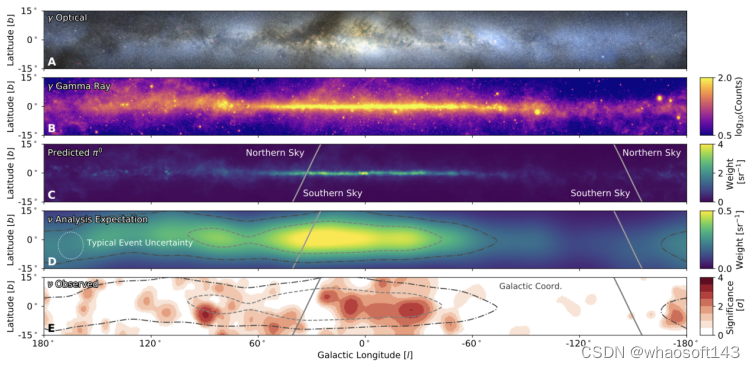
处理完首张黑洞照片后,AI又帮助人们识别了高能中微子信号。
IceCube团队使用机器学习模型分析来自IceCube Neutrino Observatory的数据,区分信号和背景数据,这使得高能中微子从银河平面的发射被以前所未有的精确度检测到。研究使用卷积神经网络进行事件选择,其高速推理(几毫秒)能力使得研究者可以采取更为复杂的事件筛选策略。
通过十年的观测数据,机器学习模型不断完善,学会了在宇宙噪声的背景下精准地锁定中微子的特征。这些发现揭示了具有4.5西格玛重要性的中微子发射,强调了银河系内潜在的来源。
在这一背景下,机器学习的创新使用不仅增强了天文台的检测能力,而且为未来的天体物理探索提供了模式。
化学与材料
AI在化学材料的各个领域大放异彩。在自动化化学和材料合成领域,如Koscher等人的研究以及Szymanski等人的A-Lab项目展示了人工智能与物理世界之间的桥梁。这些项目通过自动化实验室和基于云的方法,发现了新的染料分子和无机材料。
在大型语言模型的应用方面,如Coscientist和ChemCrow项目利用LLM规划实验,实现了与互联网、模型和实验设备的交互,展示了LLM在自动化任务和复杂实验室操作中的巨大潜力。
此外,DeepMind的GNoME团队通过机器学习的方法预测了大量的材料候选者,展示了深度学习在材料科学中的应用。
最后,像MIT和Cornell的研究团队开发的OA-ReactDiff扩散模型,在化学反应的过渡状态搜索方面取得了重要进展,提供了一种比传统方法更快更有效的替代方案,并能探索未预期的反应路径,助力新催化剂的发现和复杂反应的研究。
生物
领域聚焦到理解蛋白质与其他生物小分子和大分子的相互作用。
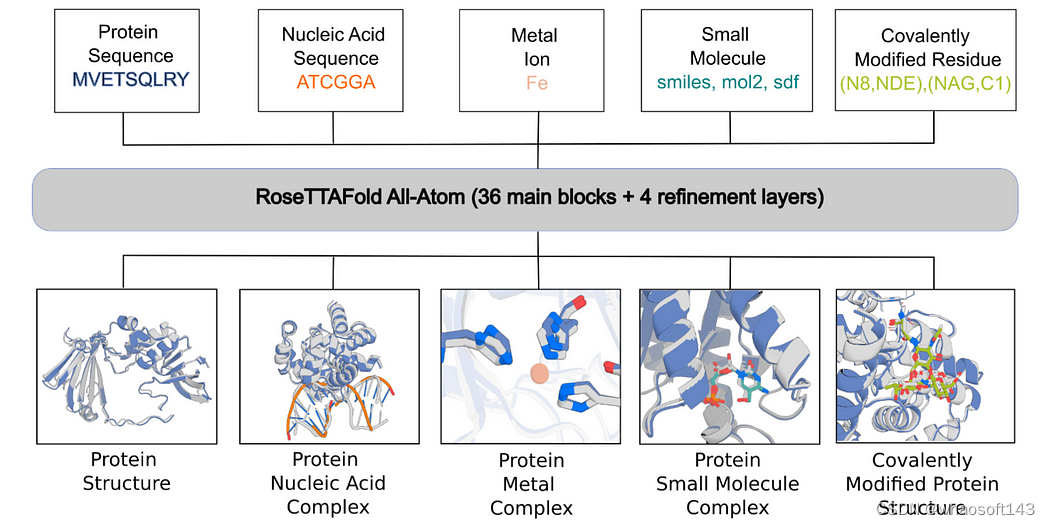
其中,RosettaFold-AA和AlphaFold-latest作为两个杰出的代表,不仅仅局限于蛋白质结构预测,还扩展到预测蛋白质与小分子、蛋白质、核酸等生物分子的相互作用。
除了对静态的蛋白结构的研究,大家的也将目光聚焦在了研究蛋白构象空间,比如AF-Cluster通过改变多序列比对来控制AlphaFold输出不同构象。
相对于对蛋白质结构和功能的理解,蛋白质设计专注于设计新的蛋白质或修改现有蛋白质以实现特定的结构和功能。
在几何深度学习和生成式AI领域(特别是扩散模型)取得进展的基础上,RFDiffusion和Chroma提出了包含空间对称性(旋转、平移和反射)的扩散模型,用于生成新蛋白质。
除了从头设计外,他们还提出了灵活设计和优化蛋白质的方法,比如基于结合靶标,功能,结构的条件,以及基于模型提供指导的结构或功能优化。
医药
AI在医药学方面的应用已经充分结合实际应用场景并趋于工程化。
Moor等人提出了一种通用医学人工智能(GMAI),该系统能够解释多模态数据,如影像学、电子健康记录、实验室结果、基因组学、图形或医学文本。GMAI以自监督方式在大规模、多样化的多模态数据上进行预训练,并能够执行多样化的医学应用。
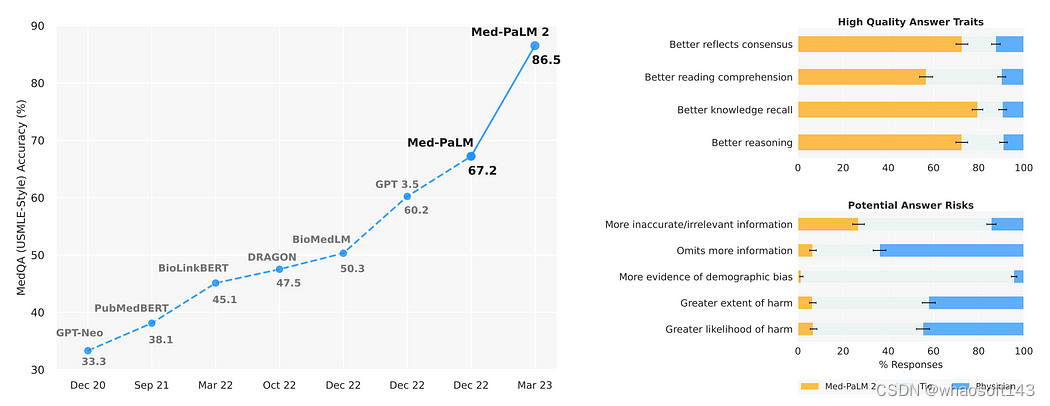
Singhal等人策划了一个在医学领域的大规模问答数据集,并提出了基于PaLM(Google的大型语言模型)的医学领域大型语言模型,也被称为Med-PaLM, 并首次作为AI模型通过美国医学执业考试。
几个月后,同一组作者提出了Med-PaLM的第二个版本(Med-PaLM 2)。如图所示,Med-PaLM 2取得了显著的里程碑(86.5%(Med-PaLM2),67.2%(Med-PaLM)),成为第一个达到与人类专家相媲美的水平,能够回答USMLE风格问题。医生们注意到该模型在回答消费者医学问题的长篇答案方面有显著的改进。
同时,AI4Science也在一些领域,比如数学理论,地球科学和神经科学开辟了新的赛道并在高速发展。
数学理论
今年,LLM开始发现新的理论和算法。DeepMind的一项最新研究(FunSearch)展示了LLM用于发现解决复杂组合问题的新程序的潜力。FunSearch的主要目标是找到更好的程序来解决难题。
具体来说,它采用了一种在预训练LLM和评估器之间的迭代和进化过程。在这个过程中,进化算法从程序池中选择最佳程序候选,输入到LLM中进行改进。然后,修订后的程序被评估、打分,并重新放回池中。在这个进化过程中,提出了更好和新的程序。他们验证了FunSearch在两个组合优化问题——cap set和在线装箱问题上的有效性,FunSearch找到了比已知最佳解决方案更好的解决方案。
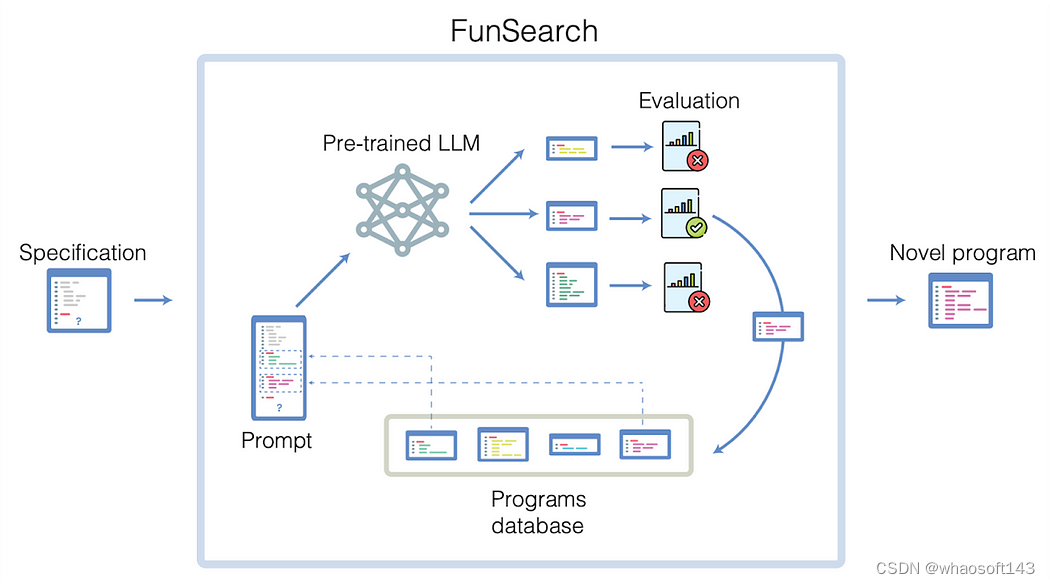
地球科学
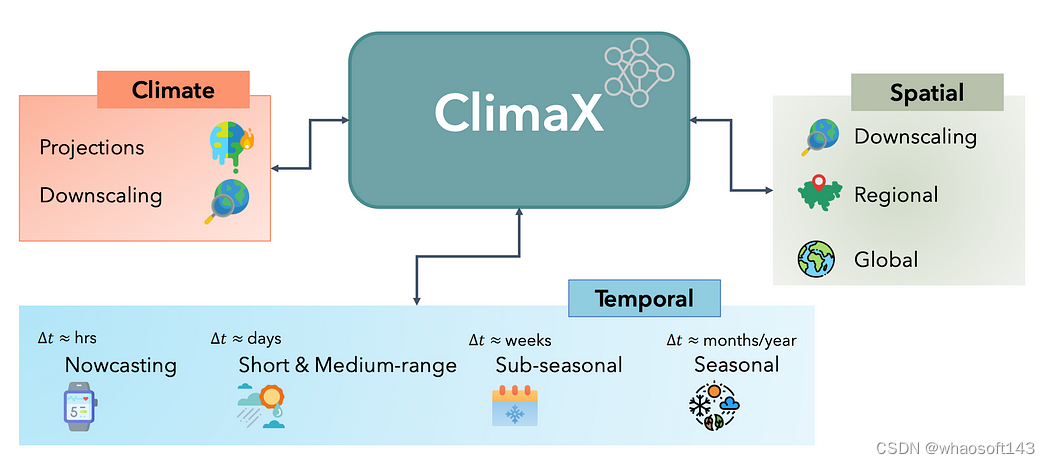
AI技术实现了在天气预测这一传统上极具挑战性的任务突破性的进展。
项目如ClimaX、GraphCast、Pangu-Weather、MetNet-3和PreDiff利用了数十年的历史天气数据和数值物理模拟结果,推动了在短期和中期天气预测方面的高分辨率时空预测技术。这些成就在很大程度上依赖于高性能计算资源和对大量数据的复杂处理。
特别值得一提的是,GraphCast通过其独特的“编码器-处理器-解码器”结构的图形神经网络,专门处理空间结构化的天气数据。而ClimaX则以其全球和区域范围的模型及通用基础模型而闻名,这些模型可以根据任意组合的输入变量预测任意时间点的天气情况。
除了天气预测,人工智能还在数据有限的地球科学领域取得了进展,例如地下结构、生物学和火山学。在这些领域,轻量级的人工智能代理模型正在替代传统的、计算密集型的数值物理模拟。这些模型不仅加快了预测速度,还提高了决策过程的效率。
神经科学
AI从脑波中重建图像,为人类提供了深入了解大脑中的世界模型的机会。尽管这一任务一直极具挑战性,生成模型的创新(尤其是隐空间扩散模型)使得这一任务变得可能。
如果将大脑活动数据解释为“文本”,那么我们就能够生成基于脑活动数据的图像。令人惊讶的是,这一任务无需训练复杂的神经网络,只需使用预训练的稳定扩散模型,仅训练从脑数据到潜在向量和上下文向量的线性映射。
此外,AI还被用于理解神经活动和行为的对应。一种称作CEBRA的方法能够应用于基于假设和探索性的分析,并展示了表示在多次实验、动物和模态之间对神经活动解释的一致性。这一方法最小程度地利用神经编码中的时间结构,大大提升了结果的鲁棒性,有希望成为神经科学研究中的有力工具。

未来的展望和挑战
最后,经历了2023年的疯狂,组织者们送上了他们对AI4Science在2024年发展的期望:
- 开源是加速科学发现的关键。开源强调可复制和降低各个领域之间的沟通壁垒。这在AI4Science这样的大融合的方向更为重要。2023年,我们注意到社区趋向于更加封闭。因此我们在迈向未来的路上,倡导AI4Science社群拥抱开源科学的理念。
- 某些AI4Science领域正从概念验证阶段转向实际应用,把我们的理论知识变成科学发现中的可靠工具。这是一个大挑战,不仅需要理念上的,还需要工程和教育上的努力以及资源的支持。相比于LLMs大众每天都可以看见的进展,由于科学偏“toB”的属性,AI4Science的商业化进程会缓慢很多。不过,这是深化和拓宽科学发现的必要步骤。人类对于科学的探索和转化本身就是一个没有终点的长跑,需要耐力和坚持!
- 想要解决科学领域的宏大挑战,需要跨多个领域的知识,而构建一个协作环境对于推进人工智能和科学研究至关重要。这也是我们AI4Science组织者希望给大家打造的环境。
- 随着社群的不断扩大,AI4Science工具被滥用的风险也在增长。在开发新的算法进步时,大家应该牢记伦理和安全问题。
更为详尽的英文原稿博客见:https://medium.com/@AI_for_Science/ai-for-science-in-2023-a-community-primer-d2c2db37e9a7
#SenseChat
大模型的未来时刻,已经来了? 比肩GPT-4,商汤日日新大幅升级4.0,多模态能力领先一步
速度太快了。
商汤一下子把多模态大模型的发展进度条,快进到了落地阶段。
商汤的大模型体系「日日新 SenseNova」今天刚刚发布了 4.0 版,不论语言能力还是文生图能力都有全面升级,还自带低门槛的落地工具。
新一代 SenseNova 不仅在大语言模型、文生图模型等方面进行了重大升级,部分垂直领域能力超越 GPT-4,还发布了全新多模态大模型,并面向数据分析、医疗等场景提供了全新版本,让大模型通用能力适配到了更多领域。
API 申请网址:https://platform.sensenova.cn/
与此同时,商汤还推出了日日新・商量大语言模型 Function call & Assistants API 版本,除了对话能力外,还支持多种内置工具,包括图片生成 (文生图)、智能识图 (图生文)、数据分析(代码解释器)、在线检索。
这是全球首个支持了文生图、图生文,并可支持不同模态工具调用的工具,跑在了 OpenAI 的前面。
这一系列发布,从技术进步到落地「两翼齐飞」,可谓把通用大模型技术卷上了天。看来在技术竞争中,国内科技公司逐渐有了反超的趋势。
最高支持 128k 长窗口
商量 SenseChat 测试全方位比肩 GPT-4
自 ChatGPT 出现以来,大模型成为了 AI 赛道的主力军。商汤的大模型体系正在「大模型 + 大装置」的战略布局下快速迭代。
去年 4 月,商汤公布了「日日新 SenseNova」大模型体系,一上来就在自然语言处理、文生图创作、数字人生成、3D 场景和物体生成,自动化数据标注、自定义模型训练等多个领域全面发力。
与此同时,商汤还直接提供图片生成、自然语言对话、视觉推理和标注服务的 API 接口。
此后,该大模型体系持续推陈出新,在基础能力、API 服务、模型应用等多个方面不断进步,给用户和开发者们带来了越来越好用的技术。
如今,近 10 个月过去了,商汤新一代「日日新 SenseNova 4.0」在 2024 年的新春之际与大家见面了, 不仅对已有多个大模型进行全方位升级,还有一些「新面孔」。
升级之后,日日新在长文本理解、综合推理(包括数字推理)、代码生成、多模态交互等整体表现上「更上一层楼」,不仅全面超越了 GPT-3.5,并且大部分接近甚至超越了 GPT-4 系列模型。
用下面一组核心数据说话,SenseNova 4.0 的:
- 推理能力:达到 GPT-4 Turbo 的 99%;
- 代码能力:在 HumanEval 代码生成基准测试上准确率达到 75.6,超越 GPT-4(74.4);
- 多模态能力:在 MMBench 多模态大语言模型综合评估基准上的整体性能超越了 GPT-4V(84.4 vs 74.4);
- 数据分析能力:正确率(85.71%)超越 GPT-4(84.62%);
- 在部分垂直领域能力超越 GPT-4 Turbo。
而日日新全维度、无死角的能力飙升,首要归功于商量大语言模型 SenseChat 的重大升级。
此次发布的商量大语言模型-通用版本(SenseChat V4) 在整体能力比肩 GPT-4,并相较于 GPT-3.5 实现显著超越。如下两图为 SenseChat V4 与GPT-3.5、GPT-4 在整体、考试、语言、知识、推理、数理、编程等数据集上的性能比较数据。
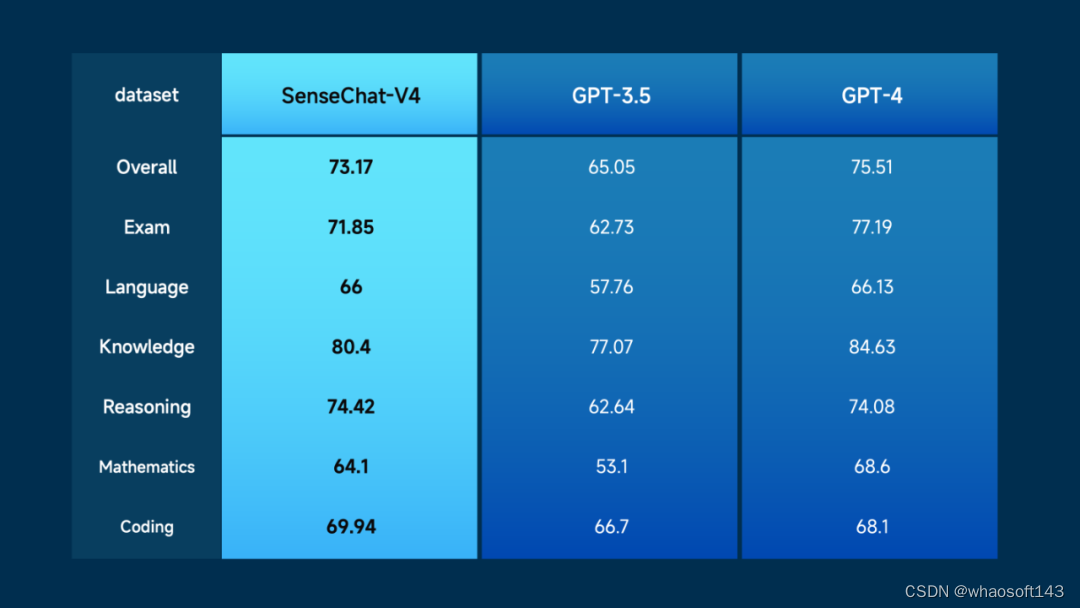
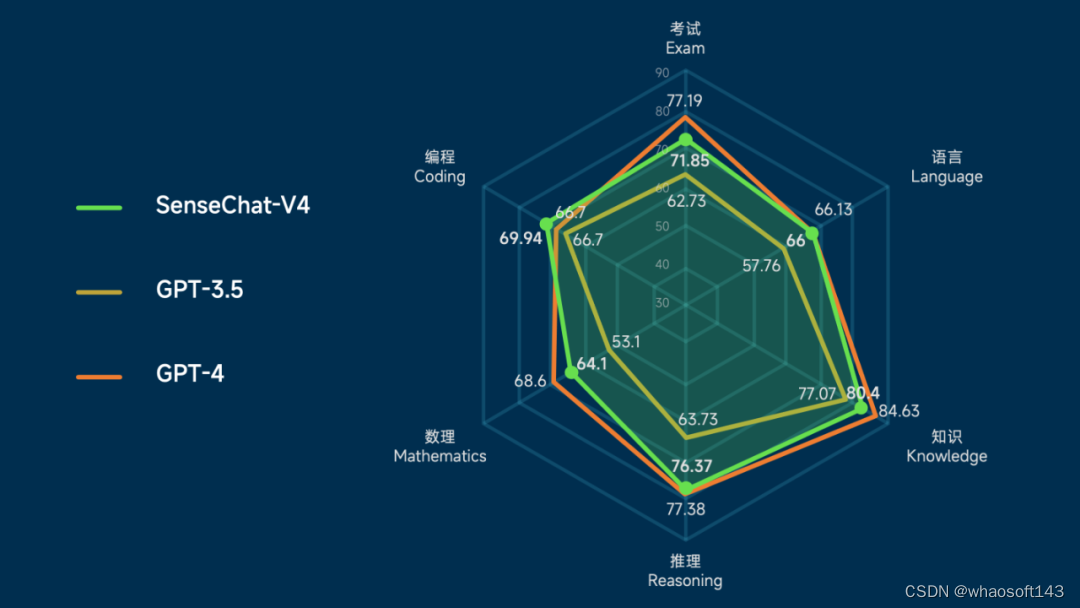
至于为何能有如此明显的性能提升,SenseChat 4.0 在以下多个方面获得了加强。
首先是更全面的知识覆盖,新增了包括业务通用数据、数学能力数据、K12 考试数据、文学期刊数据等在内约 600B tokens 的中英文预训练语料,这样理解多领域内容更加得心应手。同时,模型质量也通过数据清洗和增强得到进一步提高。
其次推理能力变得更加可靠。从初始 1.0 版本以来,前后四次超强预训练的积累让模型在阅读理解、综合推理、代码能力等多项任务上实现了 5%-10% 的定向性提升。
最后也是此次 4.0 版本升级的重点 —— 更强的长文本理解分析能力,更新了 3 种不同上下文窗口的全新模型,即 SenseChat-4K、SenseChat-32k 和 SenseChat-128k,不仅使得模型理解上下文的能力迎来史诗级加强,还提升了模型的适应能力,拓宽了应用范围,为用户提供根据需求自由选择模型的机会。
在与 GPT-3.5、GPT-4 的多任务较量中,我们直观地看到了 SenseChat 不同上下文窗口版本的真正实力。
其中,SenseChat-4K 虽然支持最少的 4k tokens(约 4000 中文字)的输入和输出,但仍然在写作总结、知识问答、闲聊娱乐、专业技能、安全测试等主客观题和安全性能上超越了 GPT-4。另外,新增的引文功能还可以返回在线搜索的知识来源。
SenseChat-32k 则能够处理 32k tokens(约 3 万中文字)的长文本总结,总能力平均得分达到了同等上下文窗口 GPT-4-32k 能力的 90% 以上水平,中文理解能力则超越了后者。
铺开来讲,SenseChat-32k 在平均考试能力和理解能力、以及 HellaSwag、C3、LAMBADA、CHID 等推理和理解类测试集中超越 GPT-4-32k;在 LongBench 长文本理解测试基准以及 tpo、multidocqa、scientificqa、PassageRetrieval-zh 等长文本测试集上均超越了 GPT-4–32k。
对于支持最长 128k tokens(约 12 万以上中文字)长文本的 SenseChat-128k,它的中文理解能力也超过了 GPT-4 的水平。
下表 1 和 2 分别为 SenseChat 三个版本模型与 GPT 系列在长文本理解和推理等测试集上的平均得分比较。
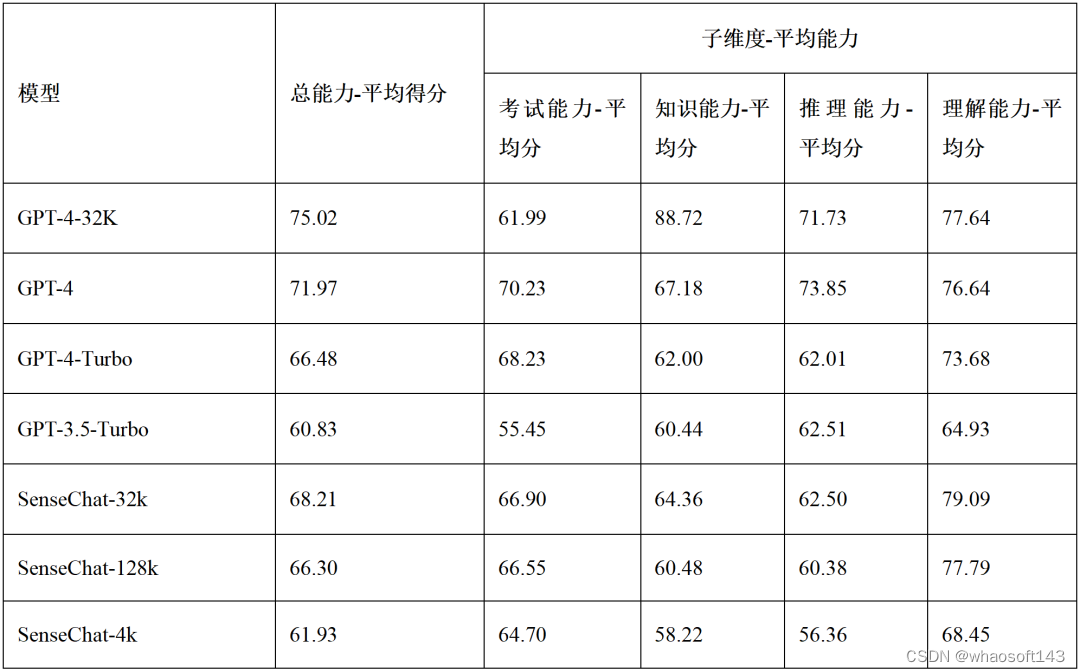
表 1:Normalbench v1-4 万题对比结果。
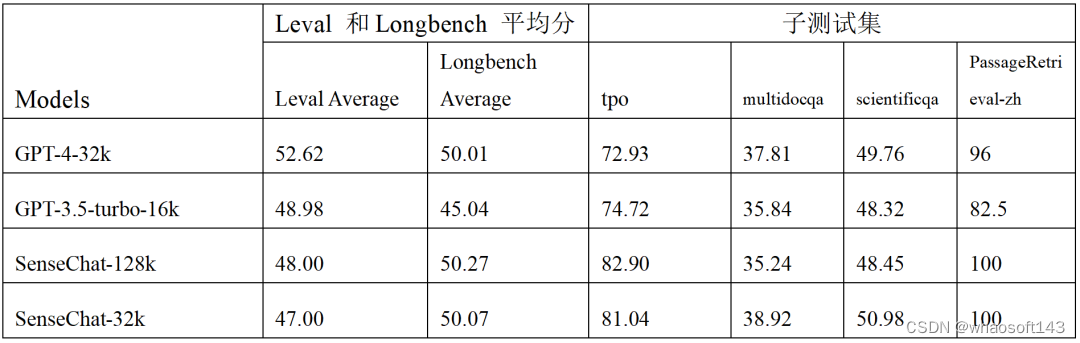
表 2:长文本 Leval 和 Longbench 测试集对比结果。
看起来,SenseChat V4 不仅在主客观题方面达到了 GPT-4 的水平,更在长文本理解和推理能力上实现了全面超越。
作为商汤「日日新 SenseNova」大模型体系的通用基础模型,SenseChat V4 的大幅度升级使得人们在使用模型处理多样化语言任务时更高效、更准确,让国产大模型拥有不输于 GPT-4 的使用体验。
对于更多人来说,未来在商量 SenseChat 大语言模型的基础上开展学术研究、技术创新、商业应用也有了更多机会。
填补行业空缺,打造专用大模型
首家开放支持多模态的 Assistants API
基础模型之外,商汤也希望能通过高效融合垂直领域知识,帮助人们构建各类专业大模型,降低大模型的下游应用成本和门槛。
多模态是人工智能大模型重要的技术演进方向,新一代「日日新 SenseNova」推出了拥有 300 亿参数的日日新·商量多模态大模型(SenseChat-Vision V4),其图文感知能力处于全球领先水平,在权威评测基准测试集 MME Benchmark 上综合得分排名首位。
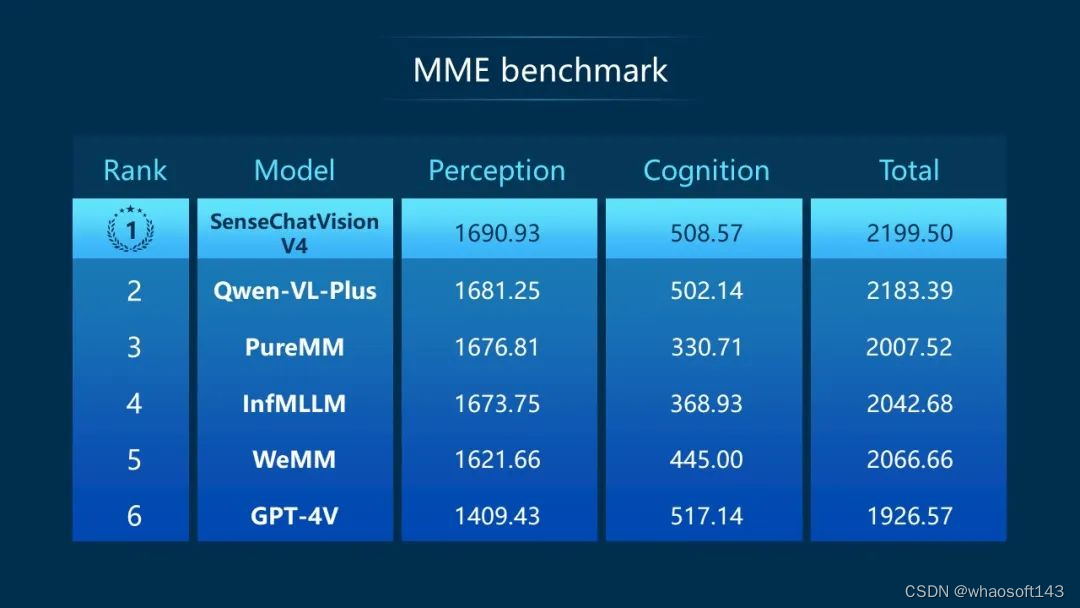
目前,该模型可以支持智能驾驶、智能车舱、电力行业等多个实际场景的应用。

与常规的 OCR 能力不同,它不仅可以理解图中的文字和物体,并且可以根据逻辑进行推理,实现了一定程度的认知能力。
在办公与数据分析领域,商汤推出了日日新·商量语言大模型-数据分析版本(SenseChat-DataAnalysisCode V4),它可以通过自然语言输入,结合商汤大模型的意图识别、逻辑理解与代码解释器的能力,自动将数据转化为有意义的分析和可视化结果。
目前,该工具已经支持 xls、xlsx、csv、txt、json 等格式的文件和表格处理。就实际效果而言,办公小浣熊在 1000 + 测试集精度上略胜于 GPT-4。
体验入口:https://raccoon.sensetime.com/office
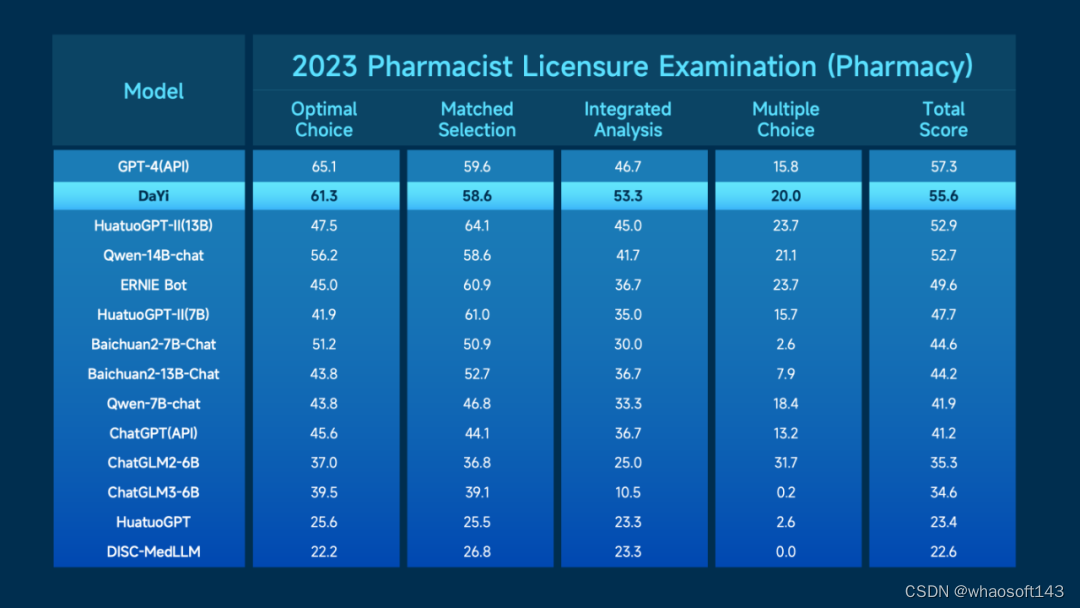
在医疗健康领域,大语言模型的医疗版本也有全新升级,日日新·商量语言大模型-医疗版本“大医”(SenseChat-Medical V4)在本次更新后可以有效实现专业医学问答及复杂医学任务推理,并支持更多模态医学文件的智能解读和交互问答。据介绍,“大医”在两项行业权威评测 —— 2023 年职业药剂师考试大模型评测和中文医疗大语言模型开放评测平台 MedBench 中,均实现综合评分排名第二,性能接近 GPT-4。
商汤自研的日日新-秒画文生图大模型(SenseMirage V4)较此前版本,参数量提升至百亿量级,通过 Mixture of text experts、Spatial-aware CFG 等算法优化,语义理解能力与图像质感细节表现显著增强,可达成电影级海报生成水平。同时结合 Adversarial Distillation 算法,秒画 SenseMirage-Turbo V4 也对外发布,相较于基础版本,可达到 10 倍推理加速效果。
秒画一键生成电影海报级的精美图像
再进一步,商汤还把调用不同模态的能力,做到了一个端口上,这就是全球首个支持调用不同模态的 Assistants API。
去年 11 月,OpenAI 在其首届开发者大会上推出专门构建的 AI 工具 ——Assistants API,通过代码解释器、检索和函数调用等新功能帮助开发者构建高质量的 AI 应用。不过,至今这个工具也没有支持构建视觉相关的多模态应用。
商汤提出的 Assistants API 填补了这一空缺。作为一个基于商量大语言模型构建的、具有状态的多轮对话接口,它不仅首次支持了文生图、图生文的不同模态工具调用,还内置数据分析、搜索引擎工具。
如果把大模型看作是大脑,Assistants API 相当于给 AI 增加了眼睛和手,能够自主理解人类下达的任务,并做出正确规划,使用合适的资源和工具。Assistants API 提供了一个桥梁,将先进的大模型与各类应用服务工具连接起来,支持图文结合的多模态交互和代码执行结果的直观呈现,可以帮助人们快速解决复杂的问题。
目前,商汤的大模型体系已经在全面落地。在全行业层面上,自发布以来已经拥有了超过 3000 家企业用户,累积调用量已达近 9000 万次,服务的行业包含互联网娱乐、游戏、文娱、教育、医疗健康、金融、编程等方面。
结语
还记得去年的「百模大战」吗?现在,科技领域的大模型军备竞赛形势已经有了改变,竞争不再是单纯的模型技术,而变成了拼体系 —— 除了模型技术的升级改进,各家厂商正在整合与调优基础底座,开放的趋势也在催生出逐渐繁荣的生态。
如今,战火已经燃烧到了多模态技术的落地上。能够睁开眼睛看世界的大模型,为我们带来了更多的想象力。
而为了在千行百业中用好它们,真正实现「重做所有产品」,一套完整的体系势必能让我们事半功倍。
在这一方面,商汤已经做到了更好。
#Nomic Embed
模型参数量只有 137M,5 天就能训练好。
一周前,OpenAI 给广大用户发放福利,在下场修复 GPT-4 变懒的问题后,还顺道上新了 5 个新模型,其中就包括更小且高效的 text-embedding-3-small 嵌入模型。击败OpenAI,权重、数据、代码全开源,能完美复现的嵌入模型来了
我们知道,嵌入是表示自然语言或代码等内容中概念的数字序列。嵌入使得机器学习模型和其他算法更容易理解内容之间的关联,也更容易执行聚类或检索等任务。可见,嵌入在 NLP 领域是非常重要的。
不过,OpenAI 的嵌入模型并不是免费给大家使用的,比如 text-embedding-3-small 的收费价格是每 1k tokens 0.00002 美元。
现在,比 text-embedding-3-small 更好的嵌入模型来了,并且还不收费。
AI 初创公司 Nomic AI 宣布推出 Nomic Embed,这是首个开源、开放数据、开放权重、开放训练代码、完全可复现和可审核的嵌入模型,上下文长度为 8192,在短上下文和长上下文基准测试中击败 OpenAI text-embeding-3-small 和 text-embedding-ada-002。
文本嵌入是现代 NLP 应用程序的一个组成部分,为 LLM 和语义搜索提供了检索增强生成 (RAG)。该技术将有关句子或文档的语义信息编码为低维向量,然后用于下游应用程序,例如用于数据可视化、分类和信息检索的聚类。目前,最流行的长上下文文本嵌入模型是 OpenAI 的 text-embedding-ada-002,它支持 8192 的上下文长度。不幸的是,Ada 是闭源的,并且训练数据不可审计。
不仅如此,性能最佳的开源长上下文文本嵌入模型(例如 E5-Mistral 和 jina-embeddings-v2-base-en)要么由于模型大小而不适合通用用途,要么无法超越其 OpenAI 对应模型的性能。
Nomic-embed 的发布改变了这一点。该模型的参数量只有 137M ,非常便于部署,5 天就训练好了。
论文地址:https://static.nomic.ai/reports/2024_Nomic_Embed_Text_Technical_Report.pdf
论文题目:Nomic Embed: Training a Reproducible Long Context Text Embedder
项目地址:https://github.com/nomic-ai/contrastors
如何构建 nomic-embed
现有文本编码器的主要缺点之一是受到序列长度限制,仅限于 512 个 token。为了训练更长序列的模型,首先要做的就是调整 BERT,使其能够适应长序列长度,该研究的目标序列长度为 8192。
训练上下文长度为 2048 的 BERT
该研究遵循多阶段对比学习 pipeline 来训练 nomic-embed。首先该研究进行 BERT 初始化,由于 bert-base 只能处理最多 512 个 token 的上下文长度,因此该研究决定训练自己的 2048 个 token 上下文长度的 BERT——nomic-bert-2048。
受 MosaicBERT 的启发,研究团队对 BERT 的训练流程进行了一些修改,包括:
- 使用旋转位置嵌入来允许上下文长度外推;
- 使用 SwiGLU 激活,因为它已被证明可以提高模型性能;
- 将 dropout 设置为 0。
并进行了以下训练优化:
- 使用 Deepspeed 和 FlashAttention 进行训练;
- 以 BF16 精度进行训练;
- 将词表(vocab)大小增加到 64 的倍数;
- 训练的批大小为 4096;
- 在掩码语言建模过程中,掩码率为 30%,而不是 15%;
- 不使用下一句预测目标。
训练时,该研究以最大序列长度 2048 来训练所有阶段,并在推理时采用动态 NTK 插值来扩展到 8192 序列长度。
实验
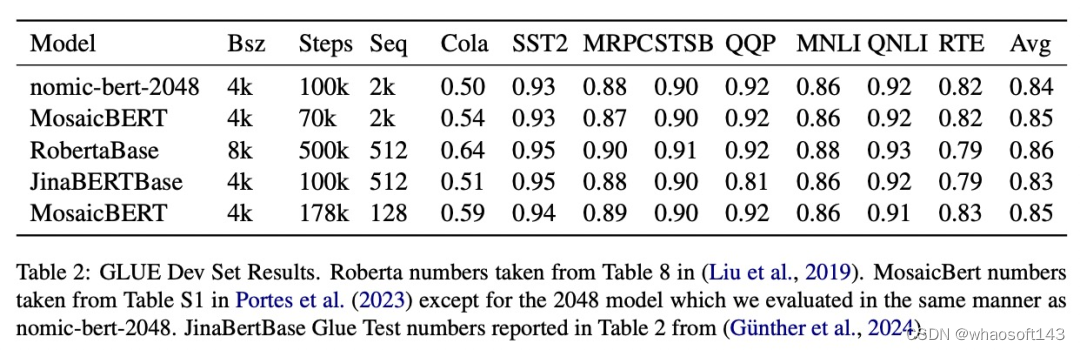
该研究在标准 GLUE 基准上评估了 nomic-bert-2048 的质量,发现它的性能与其他 BERT 模型相当,但具有显著更长的上下文长度优势。
nomic-embed 的对比训练
该研究使用 nomic-bert-2048 初始化 nomic-embed 的训练。对比数据集由约 2.35 亿文本对组成,并在收集过程中使用 Nomic Atlas 广泛验证了其质量。
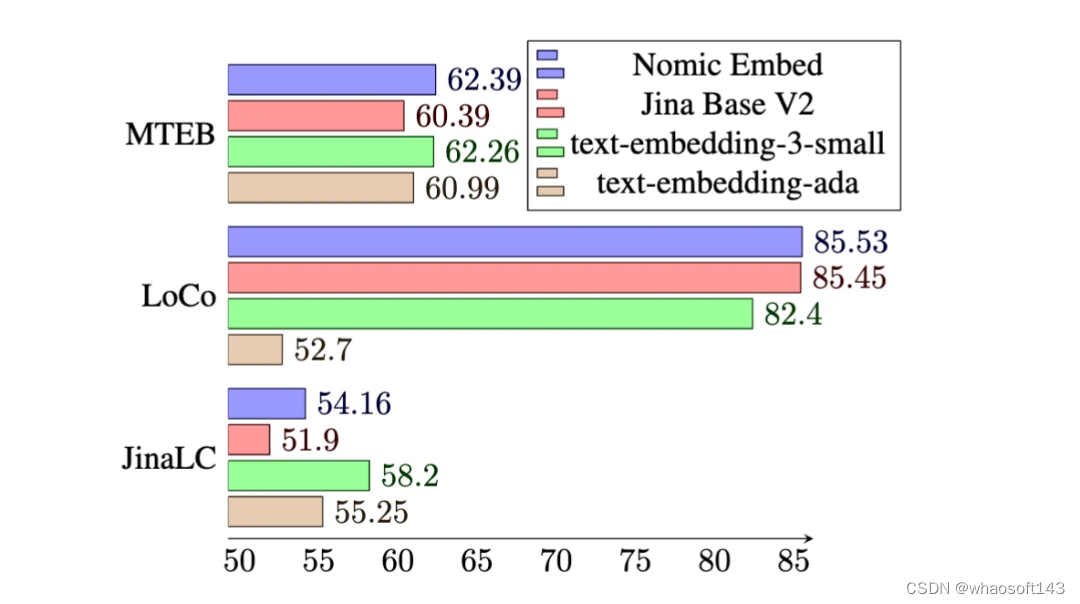
在 MTEB 基准上,nomic-embed 的性能优于 text-embedding-ada-002 和 jina-embeddings-v2-base-en。
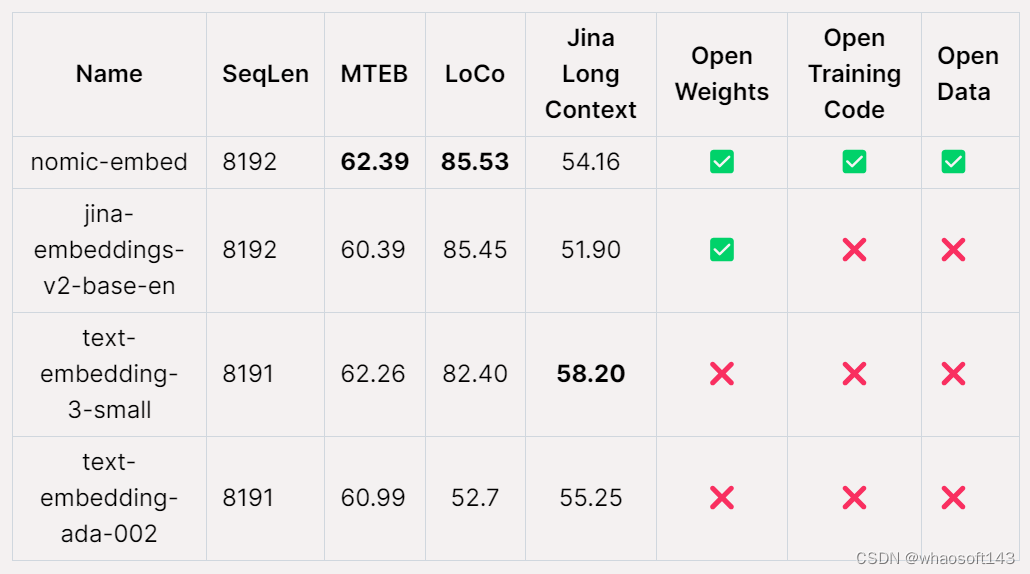
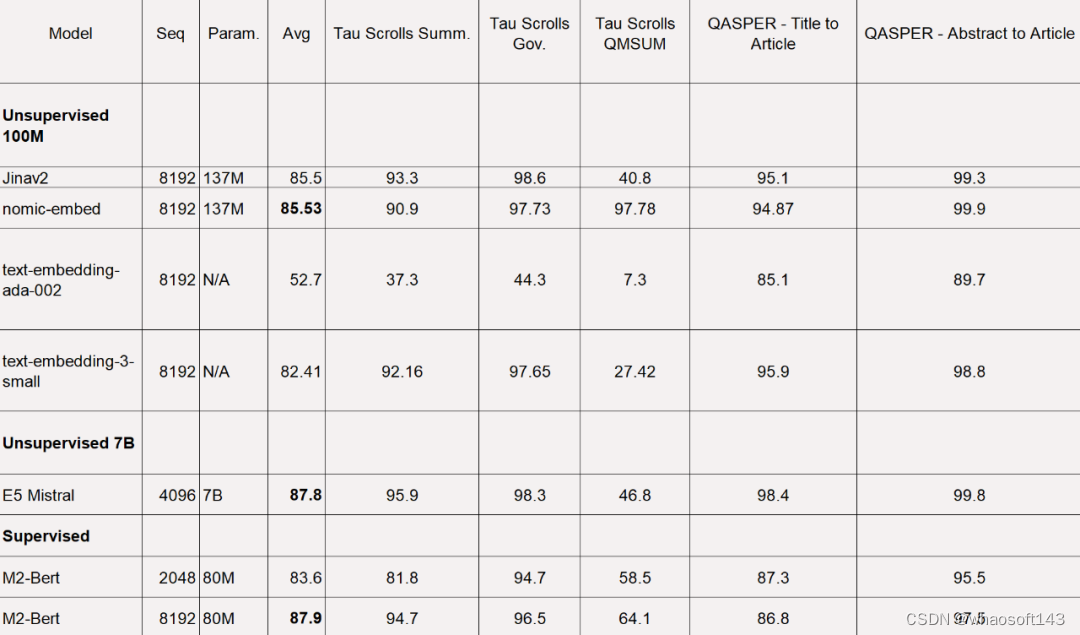
然而,MTEB 不能评估长上下文任务。因此,该研究在最近发布的 LoCo 基准以及 Jina Long Context 基准上评估了 nomic-embed。
对于 LoCo 基准,该研究按照参数类别以及评估是在监督或无监督设置中执行的分别进行评估。
如下表所示,Nomic Embed 是性能最佳的 100M 参数无监督模型。值得注意的是,Nomic Embed 可与 7B 参数类别中表现最好的模型以及专门针对 LoCo 基准在监督环境中训练的模型媲美:
在 Jina Long Context 基准上,Nomic Embed 的总体表现也优于 jina-embeddings-v2-base-en,但 Nomic Embed 在此基准测试中的表现并不优于 OpenAI ada-002 或 text-embedding-3-small:
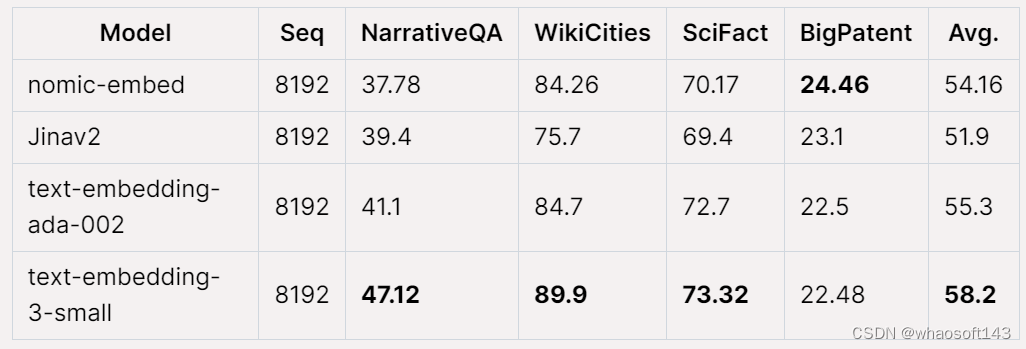
总体而言,Nomic Embed 在 2/3 基准测试中优于 OpenAI Ada-002 和 text-embedding-3-small。
该研究表示,使用 Nomic Embed 的最佳选择是 Nomic Embedding API,获得 API 的途径如下所示:

最后是数据访问:为了访问完整数据,该研究向用户提供了 Cloudflare R2 (类似 AWS S3 的对象存储服务)访问密钥。要获得访问权限,用户需要先创建 Nomic Atlas 帐户并按照 contrastors 存储库中的说明进行操作。
contrastors 地址:https://github.com/nomic-ai/contrastors?tab=readme-ov-file#data-access
参考链接:
https://blog.nomic.ai/posts/nomic-embed-text-v1
#Eagle7B
Eagle 7B 可将推理成本降低 10-100 倍。基于RWKV,推理成本降低10-100 倍
在 AI 赛道中,与动辄上千亿参数的模型相比,最近,小模型开始受到大家的青睐。比如法国 AI 初创公司发布的 Mistral-7B 模型,其在每个基准测试中,都优于 Llama 2 13B,并且在代码、数学和推理方面也优于 LLaMA 1 34B。
与大模型相比,小模型具有很多优点,比如对算力的要求低、可在端侧运行等。
近日,又有一个新的语言模型出现了,即 7.52B 参数 Eagle 7B,来自开源非盈利组织 RWKV,其具有以下特点:
- 基于 RWKV-v5 架构构建,该架构的推理成本较低(RWKV 是一个线性 transformer,推理成本降低 10-100 倍以上);
- 在 100 多种语言、1.1 万亿 token 上训练而成;
- 在多语言基准测试中优于所有的 7B 类模型;
- 在英语评测中,Eagle 7B 性能接近 Falcon (1.5T)、LLaMA2 (2T)、Mistral;
- 英语评测中与 MPT-7B (1T) 相当;
- 没有注意力的 Transformer。
前面我们已经了解到 Eagle 7B 是基于 RWKV-v5 架构构建而成,RWKV(Receptance Weighted Key Value)是一种新颖的架构,有效地结合了 RNN 和 Transformer 的优点,同时规避了两者的缺点。该架构设计精良,能够缓解 Transformer 所带来的内存瓶颈和二次方扩展问题,实现更有效的线性扩展,同时保留了使 Transformer 在这个领域占主导的一些性质。
目前 RWKV 已经迭代到第六代 RWKV-6,由于 RWKV 的性能与大小相似的 Transformer 相当,未来研究者可以利用这种架构创建更高效的模型。
关于 RWKV 更多信息,大家可以参考「Transformer 时代重塑 RNN,RWKV 将非 Transformer 架构扩展到数百亿参数」。
值得一提的是,RWKV-v5 Eagle 7B 可以不受限制地供个人或商业使用。
在 23 种语言上的测试结果
不同模型在多语言上的性能如下所示,测试基准包括 xLAMBDA、xStoryCloze、xWinograd、xCopa。
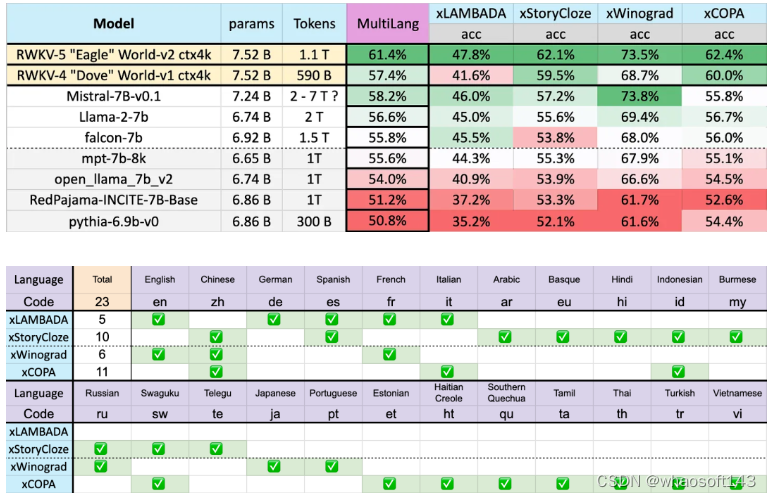
共 23 种语言
这些基准测试包含了大部分常识推理,显示出 RWKV 架构从 v4 到 v5 在多语言性能上的巨大飞跃。不过由于缺乏多语言基准,该研究只能测试其在 23 种较常用语言上的能力,其余 75 种以上语言的能力目前仍无法得知。
在英语上的性能
不同模型在英语上的性能通过 12 个基准来判别,包括常识性推理和世界知识。

从结果可以再次看出 RWKV 从 v4 到 v5 架构的巨大飞跃。v4 之前输给了 1T token 的 MPT-7b,但 v5 却在基准测试中开始追上来,在某些情况下(甚至在某些基准测试 LAMBADA、StoryCloze16、WinoGrande、HeadQA_en、Sciq 上)它可以超过 Falcon,甚至 llama2。
此外,根据给定的近似 token 训练统计,v5 性能开始与预期的 Transformer 性能水平保持一致。
此前,Mistral-7B 利用 2-7 万亿 Token 的训练方法在 7B 规模的模型上保持领先。该研究希望缩小这一差距,使得 RWKV-v5 Eagle 7B 超越 llama2 性能并达到 Mistral 的水平。
下图表明,RWKV-v5 Eagle 7B 在 3000 亿 token 点附近的 checkpoints 显示出与 pythia-6.9b 类似的性能:
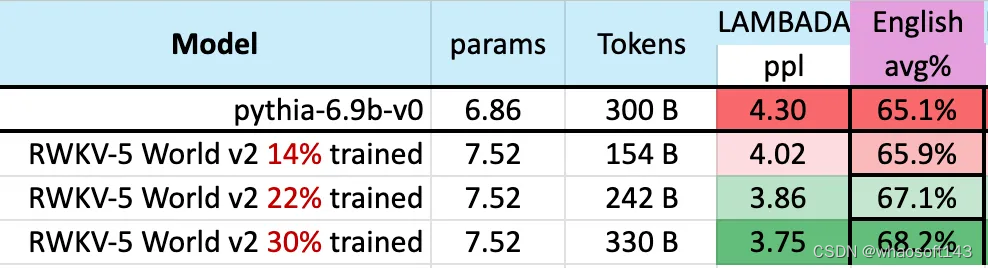
这与之前在 RWKV-v4 架构上进行的实验(pile-based)一致,像 RWKV 这样的线性 transformers 在性能水平上与 transformers 相似,并且具有相同的 token 数训练。
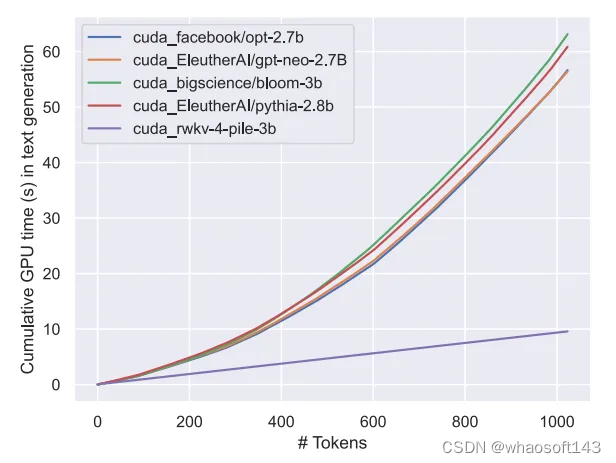
可以预见,该模型的出现标志着迄今为止最强的线性 transformer(就评估基准而言)已经来了。
参考链接:https://blog.rwkv.com/p/eagle-7b-soaring-past-transformers
#OLMo~
随着全球急速向部署既高效又安全的 AI 模型迈进,开源 LLM 的需求急剧上升。开源和闭源的 AI 模型都被广泛采用,导致我们理解如何构建这些模型的能力已经远远落后。OLMo 的推出将为业界提供深入探索 AI 模型内部运作的窗口。媲美Llama 2,第一个正真开源的大模型OLMo发布
今日,艾伦人工智能研究所(AI2)发布了 OLMo 7B,这是一个完全开源的而且非常先进的 LLM,与之配套的还有预训练数据和训练代码,这在目前的开源模型中是独一无二的。这使得研究者和开发者能够利用顶尖的开源模型,共同推动语言模型科学的进步。
艾伦人工智能研究所等5机构最近公布了史上最全的开源模型「OLMo」,公开了模型的模型权重、完整训练代码、数据集和训练过程,为以后开源社区的工作设立了新的标杆。
Meta 首席 AI 科学家 Yann LeCun 表示:“开放的基础模型对于激发生成式 AI 的创新和发展至关重要。开源社区的活力是构建 AI 未来最快、最高效的途径。”
OLMo 及其框架旨在支持研究人员训练和试验 LLM。它们可通过 Hugging Face 和 GitHub 直接下载,这得益于与哈佛大学的 Kempner 自然与人工智能研究所以及包括 AMD、芬兰科学 IT 中心(CSC)、华盛顿大学 Paul G. Allen 计算机科学与工程学院和 Databricks 等合作伙伴的合作。
多年来,语言模型一直是自然语言处理(NLP)技术的核心,考虑到模型背后的巨大商业价值,最大最先进的模型的技术细节都是不公开的。现在,真·完全开源的大模型来了!
来自艾伦人工智能研究所、华盛顿大学、耶鲁大学、纽约大学和卡内基梅隆大学的研究人员,联合发表了一项足以载入AI开源社区史册的工作——
他们几乎将从零开始训练一个大模型过程中的一切数据和资料都开源了!
论文:https://allenai.org/olmo/olmo-paper.pdf
权重:https://huggingface.co/allenai/OLMo-7B
数据:https://huggingface.co/datasets/allenai/dolma
评估:https://github.com/allenai/OLMo-Eval
适配:https://github.com/allenai/open-instruct
Hugging Face:https://huggingface.co/allenai/OLMo-7B
GitHub:https://github.com/allenai/OLMo
该框架提供了一套完全开源的 AI 开发工具,涵盖了:
- 完整预训练数据:模型建立在 AI2 的 Dolma 数据集上,拥有三万亿的开放语料库用于语言模型预训练,包括生成这些训练数据的代码。
- 训练代码与模型权重:OLMo 框架为四种不同的模型变体提供了完整的模型权重,每种模型都至少经过了 2 万亿次 Token 的训练。此外,还提供了推理代码、训练指标和训练日志。
- 评估工具:我们发布了开发中使用的评估工具套件,每个模型包含超过 500 个检查点,每训练 1000 步就记录一次,评估工具套件还包括 Catwalk 项目下的评估代码。
在构建强大的开放模型过程中,AI2 借鉴了多个其他开放或部分开放模型的经验,整个项目期间将它们作为与 OLMo 竞争的基准进行了比较 —— 包括 EleutherAI 的 Pythia 套件、MosaicML 的 MPT 模型、TII 的 Falcon 模型以及 Meta 的 Llama 系列模型。
AI2 认为,OLMo 7B 模型是一个与众不同且性能出色的选择,相比于如 Llama 2 这样的热门模型,它在某些方面表现更优,在其他方面则可能有所不足。
下面展示了 OLMo 7B 与其同行模型的评估结果。前九项任务基于 AI2 当前对预训练模型进行的内部评估,而后三项任务则是为了使评估结果在 HuggingFace 的 Open LLM 排行榜上更加完整而加入的。值得注意的是,评估结果的下半部分涉及了不同的比较方法,因此并非所有的数据都能够进行一一对比。
具体来说,艾伦人工智能研究所推出的这个开放大语言模型(Open Language Model,OLMo)实验和训练平台,则提供了一个完全开源的大模型,以及所有和训练开发这个模型有关的数据和技术细节——
训练和建模:它包括完整的模型权重、训练代码、训练日志、消融研究、训练指标和推理代码。
预训练语料:一个包含了高达3T token的预训练开源语料库,以及产生这些训练数据的代码。
模型参数:OLMo框架提供了四个不同架构、优化器和训练硬件体系下的7B大小的模型,以及一个1B大小的模型,所有模型都在至少2T token上进行了训练。
同时,也提供了用于模型推理的代码、训练过程的各项指标以及训练日志。
评估工具:公开了开发过程中的评估工具套件,包括每个模型训练过程中每1000 step中包含的超过500个的检查点以及评估代码。
所有数据都在apache 2.0下授权使用(免费商用)。
如此彻底的开源,似乎是给开源社区打了个样——以后不像我这样开源的,就别说自己是开源模型了。
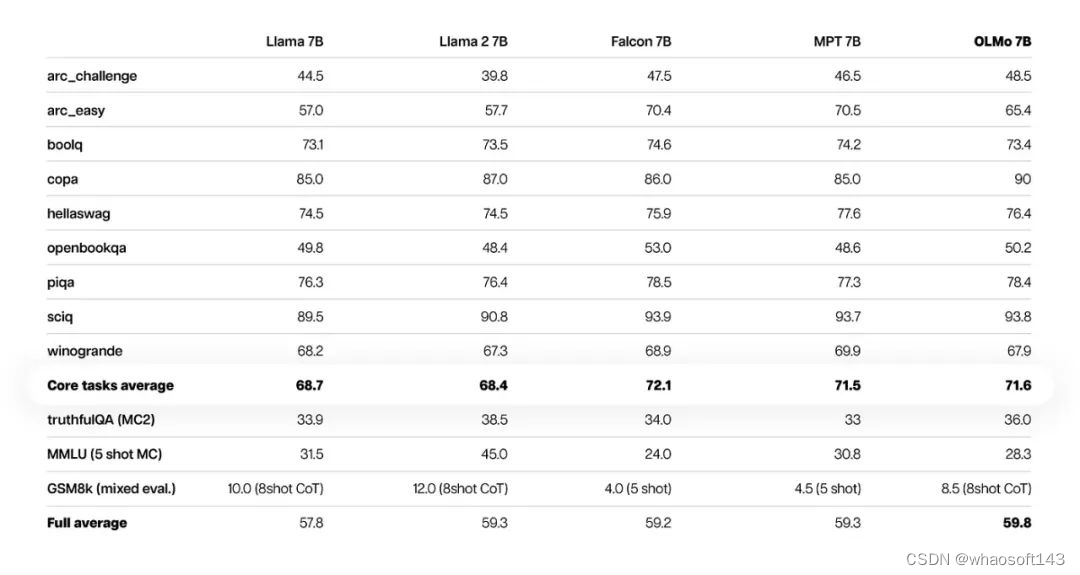
在多个生成式任务或阅读理解(如 truthfulQA 这类任务)上,OLMo 7B 在性能上略微超越了 Llama 2。然而,在诸如 MMLU 或 Big-bench Hard 这样的知名问答任务上,OLMo 7B 的表现则略有不及。
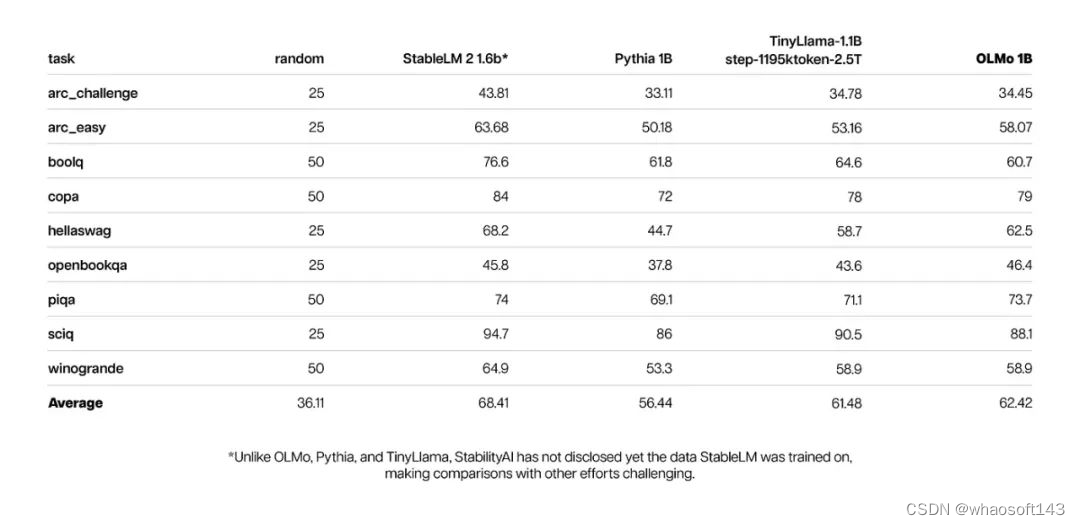
对于 1B 版本的 OLMo 模型:
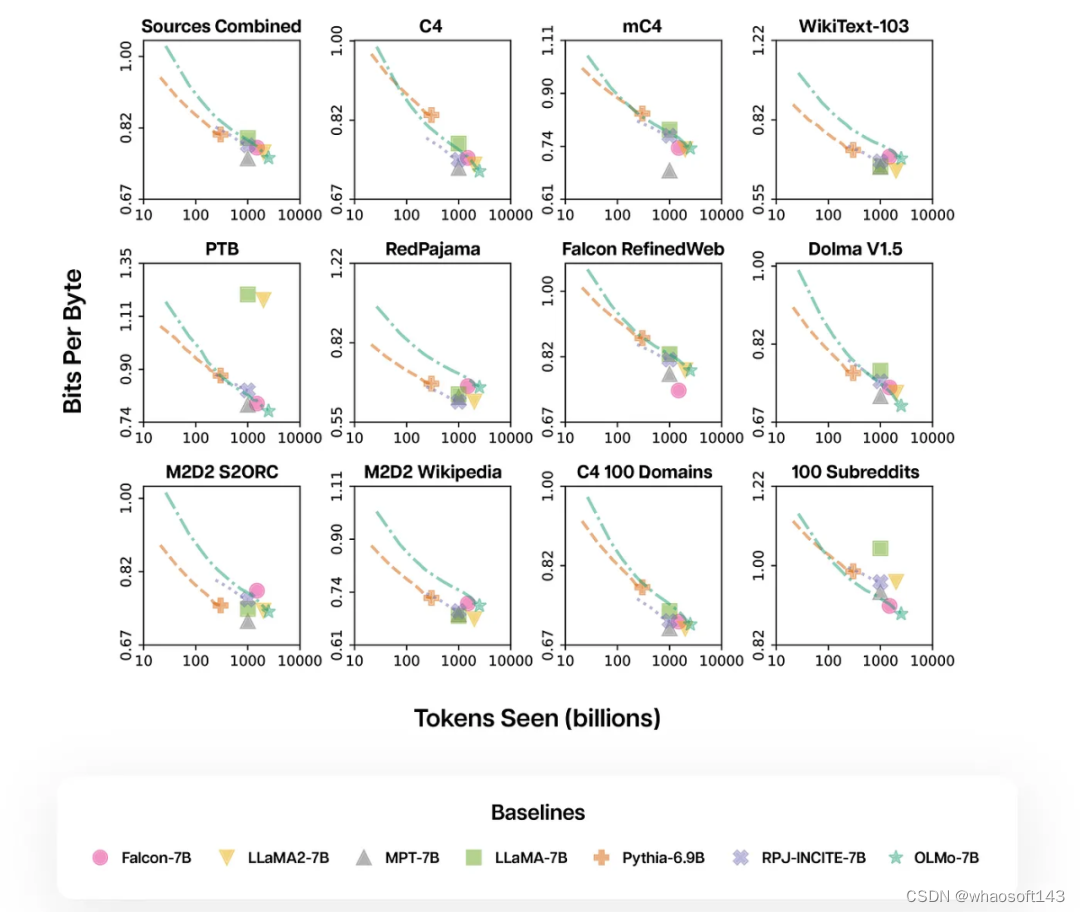
通过使用 AI2 的 Paloma 工具和 GitHub 上提供的代码检查点,AI2 探讨了模型在语言预测上的表现与其规模因素(例如,训练使用的 Token 数量)之间的联系。Paloma 的目标是通过从各个领域平等地抽样,更公平地反映出在 LLM 应用中可能接触到的广泛领域。这种方法与传统基于网页抓取的数据集(例如,由 Common Crawl 精选出的 C4 数据集)所混合的多领域数据进行评估的方式相比,提供了一种全新的视角。
如下所示,较低的 Bits per Byte(每字节位数)意味着更好的性能,OLMo 7B 在这方面与其他流行模型持平,而 Llama 模型则位于 OLMo 的训练轨迹之上。
AI2 在架构、数据处理,以及其他相关领域进行了众多实验,以打造出这个初版模型。模型架构采纳了近期研究中的多项技术,包括不使用偏置项(以增强模型的稳定性,如同 PaLM 中的做法)、采用了 PaLM 和 Llama 所用的 SwiGLU 激活函数、旋转位置嵌入(RoPE),以及一种从 GPT-NeoX-20B 改进而来的基于 BPE 的 Tokenizer,这种改进旨在减少模型处理数据时产生的个人可识别信息。
为了了解在模型开发过程中遇到的问题、考虑的模型架构,以及未来如何有效训练 LLM,建议阅读 OLMo 7B 技术报告:
https://allenai.org/olmo/olmo-paper.pdf
微软首席科学官兼 AI2 科学顾问委员会创始成员 Eric Horvitz 表示:“我非常期待 OLMo 能被 AI 研究人员所使用。这个新资源延续了艾伦 AI 提供宝贵开源模型、工具和数据的传统,这些资源已经推动了全球社区中的众多 AI 的发展。”
AI2 通过将 OLMo 及其训练数据完全公开,迈出了向合作打造世界上最佳开放语言模型的重要一步。在接下来的几个月中,AI2 将继续完善 OLMo,引入更多的模型大小、模态、数据集和功能。
“如今,许多语言模型发布时缺乏足够的透明度。研究人员如果没有访问训练数据,就无法科学地理解模型的工作机制。这就像在没有临床试验的情况下进行药物发现,或在没有望远镜的情况下研究太阳系一样。”OLMo 项目负责人、AI2 高级 NLP 研究主任及华盛顿大学艾伦学院教授 Hanna Hajishirzi 说。“通过我们的新框架,研究人员终于可以深入研究 LLM 的科学原理,这对于开发下一代安全可靠的 AI 至关重要。”
通过 OLMo,AI 研究人员和开发者将能够:
- 提高精度:完全了解模型背后的训练数据,研究人员可以更快地工作,无需再依赖对模型性能的感性判断,而是能够进行科学的测试。
- 减少碳排放:目前,一次模型训练的碳排放量相当于九个美国家庭一年的排放量。通过开放完整的训练和评估生态系统,我们大幅度减少了开发过程中的重复工作,这对于 AI 的碳减排至关重要。
- 实现持久成果:保持模型及其数据集开放,而不是封闭在 API 后面,使研究人员能够借鉴以往的模型和成果进行学习和构建。
“OLMo 真正实现了开放,这意味着 AI 研究社区的每个人都将能够全面接触到模型创建的所有方面,包括训练代码、评估方法和数据等,”OLMo 项目负责人、AI2 高级 NLP 研究主任以及华盛顿大学艾伦学院教授 Noah Smith 表示。“AI 曾是一个以开放研究社区为中心的领域,但随着模型规模的增加、成本的上升,并开始转向商业产品,AI 的开发逐渐转入了封闭的空间。通过 OLMo,我们希望逆转这一趋势,赋予研究社区以科学的方式更好地理解和参与语言模型的开发,引领更负责任的 AI 技术,使其惠及每一个人。”
AI2 在自然语言处理方面的深厚知识,加上 AMD 的高性能计算能力,使得在 AMD EPYC™ CPU 和 AMD Instinct™ 加速器支持下的 LUMI 超级计算机开发的 OLMo 模型,为 AI 的实验和创新提供了前所未有的扩展机会,推动了整个行业的发展。这个新的开放框架为全球 AI 研究社区提供了可靠的资源和一个平台,使他们能够直接对语言模型做出贡献。
——AMD AI 解决方案高级总监 Ian Ferreria
我们很高兴能够通过提供 LUMI 超级计算机的计算资源及我们的专业知识,为这一重要倡议做出贡献。公共超级计算机如 LUMI 在构建开放和透明的 AI 基础设施中发挥着关键作用。
——CSC 科学与技术总监 Pekka Manninen 博士
芬兰的 LUMI 超级计算机由 CSC 托管,由 EuroHPC 联合企业和 10 个欧洲国家共有,是欧洲最快的超级计算机,以完全无碳运营而著称,对 OLMo 的预训练工作提供了关键支持。
我们很高兴能与艾伦人工智能研究所合作发布他们的 OLMo 开源模型和框架。OLMo 为开放所代表的真正意义树立了新标准。无论是学术界、工业界还是更广泛的社区,都将从这种开放中获得巨大的收益,不仅仅是模型本身,还包括所有训练细节,如数据、代码和中间检查点。我特别自豪这个模型是在我们的 Mosaic AI 模型训练平台上开发的。正如所有伟大的开源发布一样,现在这些工具和资料已经交到了社区手中,最精彩的部分即将到来。
——Databricks 神经网络首席科学家 Jonathan Frankle
性能评估
从核心的评估结果来看,OLMo-7B与同类开源模型相比略胜一筹。
在前9项评测中,OLMo-7B有8项排名前三,其中有2项超越了其他所有模型。
在很多生成任务或阅读理解任务(例如truthfulQA)上,OLMo-7B都超过了Llama 2,但在一些热门的问答任务(如MMLU或Big-bench Hard)上表现则要差一些。
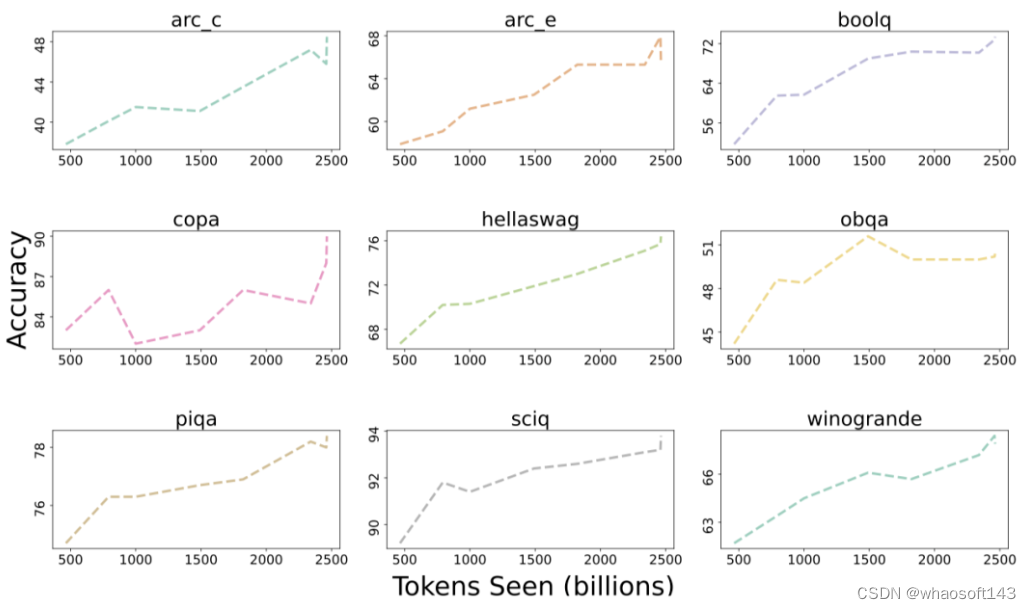
下图展示了9个核心任务准确率的变化趋势。
除了OBQA外,随着OLMo-7B接受更多数据的训练,几乎所有任务的准确率都呈现上升趋势。
与此同时,OLMo 1B与其同类模型的核心评估结果表明,OLMo与它们处于同一水平。
通过使用艾伦AI研究所的Paloma(一个基准测试)和可获取的检查点,研究人员分析了模型预测语言能力与模型规模因素(例如训练的token数量)之间的关系。
可以看到,OLMo-7B在性能上与主流模型持平。其中,每字节比特数(Bits per Byte)越低越好。
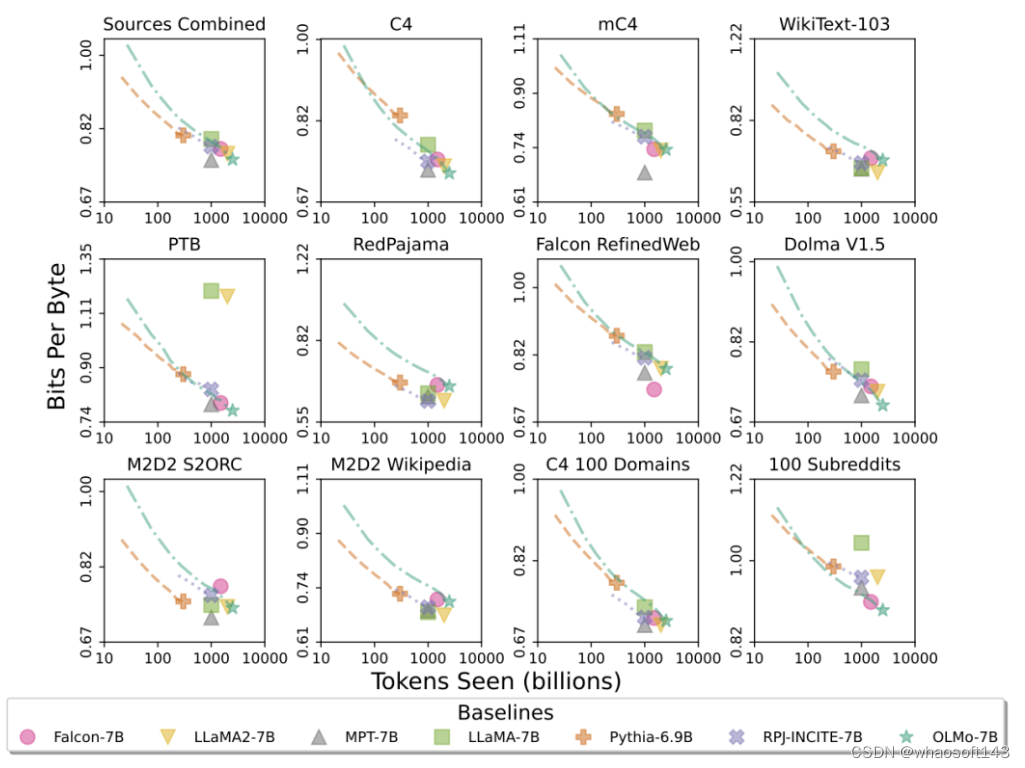
通过这些分析,研究人员发现模型在处理不同数据源时的效率差异较大,这主要取决于模型训练数据与评估数据的相似度。
特别地,OLMo-7B在主要基于Common Crawl的数据源上表现出色(比如C4)。
不过,在与网络抓取文本关系不大的数据源上,如WikiText-103、M2D2 S2ORC和M2D2 Wikipedia,OLMo-7B与其他模型相比效率较低。
RedPajama的评估也体现了相似的趋势,可能是因为它的7个领域中只有2个来源于Common Crawl,且Paloma对每个数据源中的各个领域给予了相同的权重。
鉴于像Wikipedia和arXiv论文这样的精选数据源提供的异质数据远不如网络抓取文本丰富,随着预训练数据集的不断扩大,维持对这些语言分布的高效率会很更加困难。
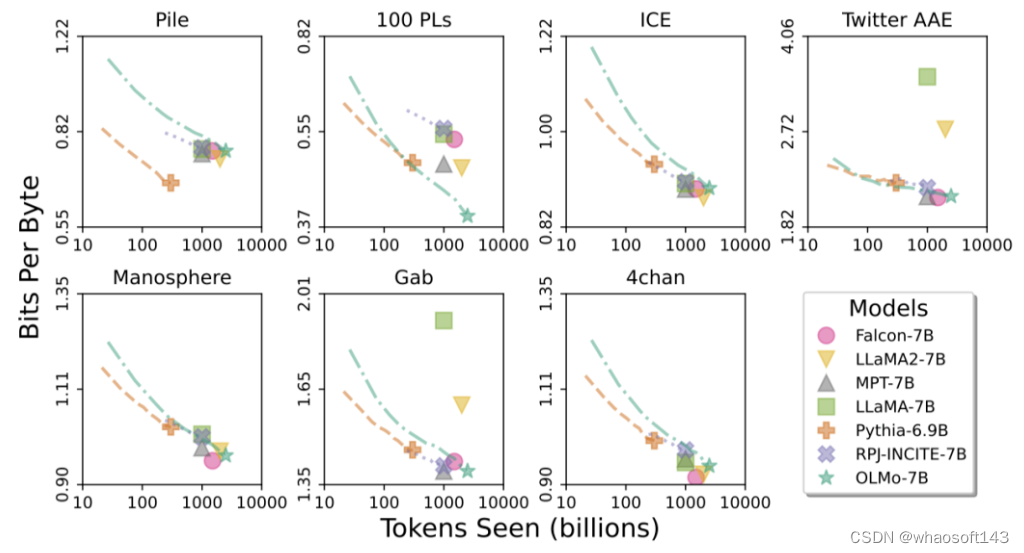
OLMo架构
在模型的架构方面,团队基于的是decoder-only的Transformer架构,并采用了PaLM和Llama使用的SwiGLU激活函数,引入了旋转位置嵌入技术(RoPE),并改进了GPT-NeoX-20B的基于字节对编码(BPE)的分词器,以减少模型输出中的个人可识别信息。
此外,为了保证模型的稳定性,研究人员没有使用偏置项(这一点与PaLM的处理方式相同)。
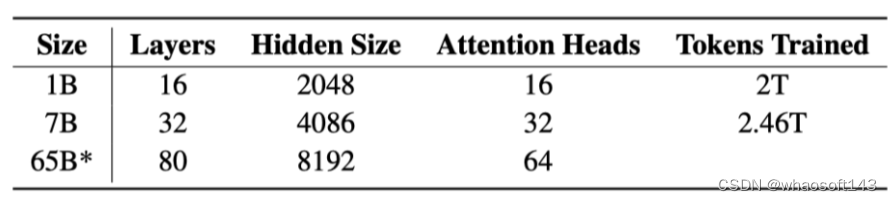
如下表所示,研究人员已经发布了1B和7B两个版本,同时还计划很快推出一个65B的版本。
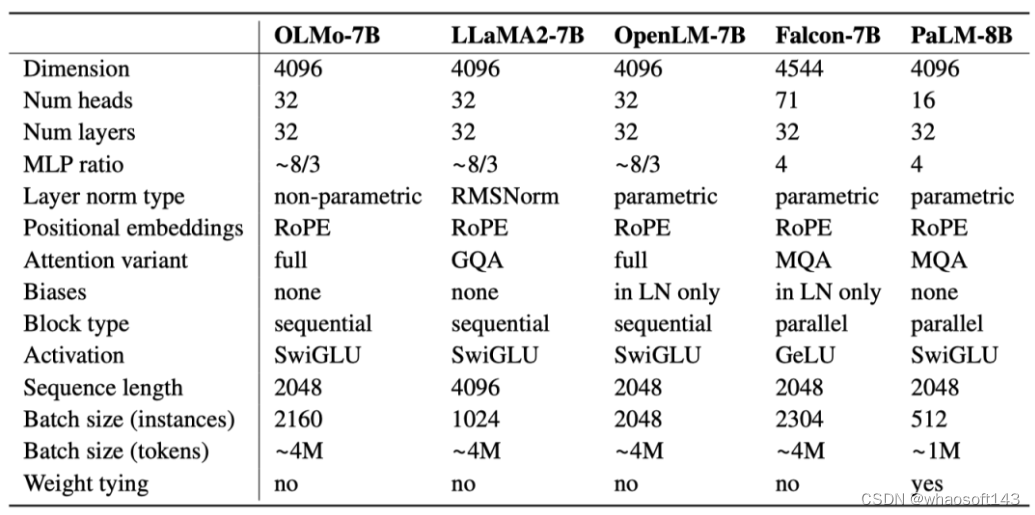
下表详细比较了7B架构与这些其他模型在相似规模下的性能。
预训练数据集:Dolma
虽然研究人员在获取模型参数方面取得了一定的进展,但开源社区目前预训练数据集的开放程度还远远不够。
之前的预训练数据往往不会随着模型的开源而公开(闭源模型就更不用说了)。
而且有关这些数据的说明文档也常常缺乏足够的细节,但是这些细节对于想要复现研究或完全理解相关工作至关重要。
这一情况加大了语言模型研究的难度——比如,了解训练数据如何影响模型能力和其局限性。
为了推动语言模型预训练领域的开放研究,研究人员构建并公开了预训练数据集Dolma。
这是一个包含了从 7 种不同数据来源获取的3万亿个token的多样化、多源语料库。
这些数据源一方面在大规模语言模型预训练中常见,另一方面也能被普通大众所接触。
下表给出了来自各个数据源的数据量的概览。
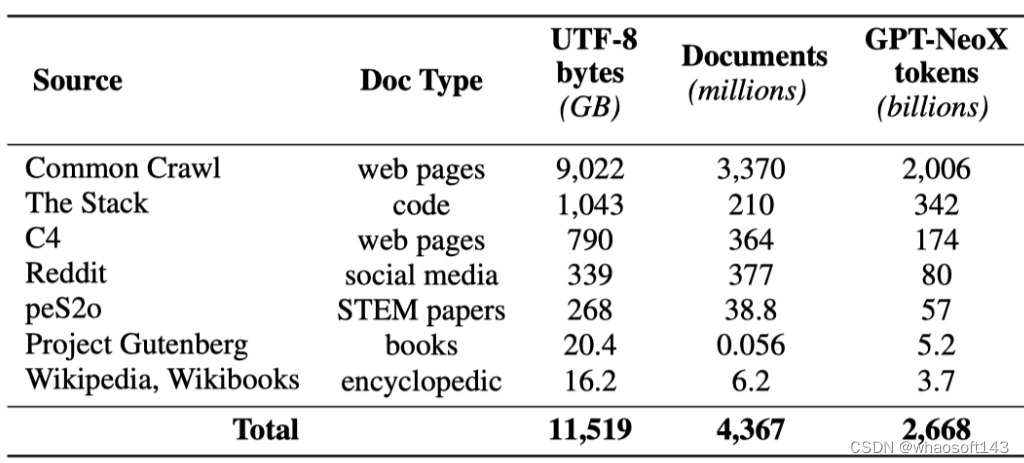
Dolma的构建过程包括六个步骤:语言过滤、质量过滤、内容过滤、去重、多源混合和token化。
在整理和最终发布Dolma过程中,研究人员确保各数据源的文档保持独立。
他们还开源了一套高效的数据整理工具,这套工具能够帮助进一步研究Dolma、复制成果,并简化预训练语料库的整理工作。
此外,研究人员也开源了WIMBD工具,以助于数据集分析。
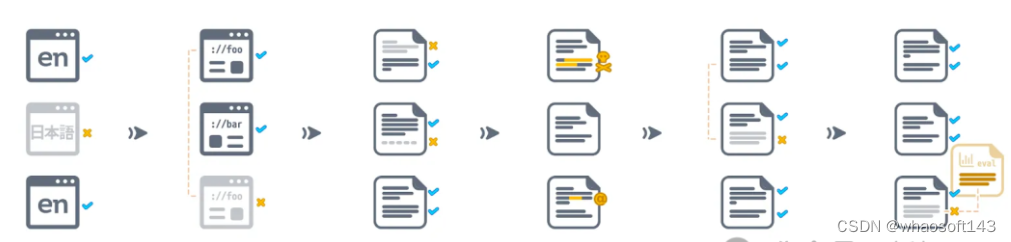
网络数据处理流程
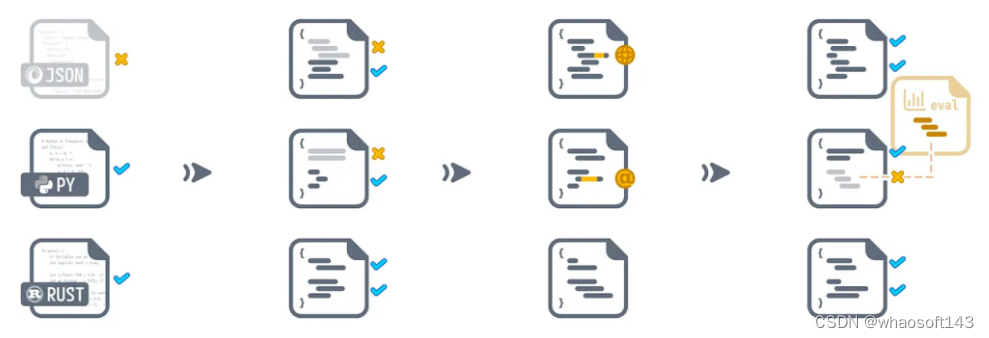
代码处理流程
训练OLMo
分布式训练框架
研究人员利用PyTorch的FSDP框架和ZeRO优化器策略来训练模型。这种方法通过将模型的权重和它们对应的优化器状态在多个GPU中进行分割,从而有效减少了内存的使用量。
在处理高达7B规模的模型时,这项技术使研究人员能够在每个GPU上处理4096个token的微批大小,以实现更高效的训练。
对于OLMo-1B和7B模型,研究人员固定使用大约4M token(2048个数据实例,每个实例包含2048个token的序列)的全局批大小。
而对于目前正在训练中的OLMo-65B模型,研究人员采用了一个批大小预热策略,起始于大约2M token(1024个数据实例),之后每增加100B token,批大小翻倍,直至最终达到大约16M token(8192个数据实例)的规模。
为了加快模型训练的速度,研究人员采用了混合精度训练的技术,这一技术是通过FSDP的内部配置和PyTorch的amp模块来实现的。
这种方法特别设计,以确保一些关键的计算步骤(例如softmax函数)始终以最高精度执行,以保证训练过程的稳定性。
与此同时,其他大部分计算则使用一种称为bfloat16的半精度格式,以减少内存使用并提高计算效率。
在特定配置中,每个GPU上的模型权重和优化器状态都以最高精度保存。
只有在执行模型的前向传播和反向传播,即计算模型的输出和更新权重时,每个Transformer模块内的权重才会临时转换为bfloat16格式。
此外,各个GPU间同步梯度更新时,也会以最高精度进行,以确保训练质量。
优化器
研究人员采用了AdamW优化器来调整模型参数。
无论模型规模大小如何,研究人员都会在训练初期的5000步(大约处理21B个token)内逐渐增加学习率,这一过程称为学习率预热。
预热结束后,学习率将按线性规律逐渐减少,直到降至最高学习率的十分之一。
此外,研究人员还会对模型参数的梯度进行裁剪,确保其总的 L1 范数不会超过 1.0。
在下表中,研究人员将自己在7B模型规模下的优化器配置与近期其他使用AdamW优化器的大型语言模型进行了对比。
数据集
研究人员利用开放数据集Dolma中的一个2T token的样本,构建了他们的训练数据集。
研究人员将每篇文档的token连接起来,每篇文档的末尾都会加上一个特殊的 EOS token,接着将这些 token 分成每组 2048 个,形成训练样本。
这些训练样本在每次训练时都会以同样的方式进行随机打乱。研究人员还提供了一些工具,使得任何人都可以复原每个训练批次的具体数据顺序和组成。
研究人员已经发布的所有模型至少都经过了一轮(2T token)的训练。其中一些模型还进行了额外的训练,即在数据上进行第二轮训练,但采用了不同的随机打乱顺序。
根据之前的研究,这样重复使用少量数据的影响是微乎其微的。
英伟达和AMD都要YES!
为了确保代码库能够同时在英伟达和AMD的GPU上都能高效运行,研究人员选择了两个不同的集群进行了模型训练测试:
利用LUMI超级计算机,研究人员部署了最多256个节点,每个节点搭载了4张AMD MI250X GPU,每张GPU 拥有128GB内存和800Gbps的数据传输速率。
通过MosaicML (Databricks) 的支持,研究人员使用了27个节点,每个节点配备了8张英伟达A100 GPU,每张GPU拥有40GB内存和800Gbps的数据传输速率。
虽然研究人员为了提高训练效率对批大小进行了微调,但在完成2T token的评估后,两个集群的性能几乎没有差异。
总结
与以往大多数仅仅提供模型权重和推理代码的模型不同,研究人员开源了OLMo的全部内容,包括训练数据、训练和评估代码,以及训练日志、实验结果、重要发现以及Weights & Biases的记录等等。
此外,团队正在研究如何通过指令优化和不同类型的强化学习(RLHF)来改进OLMo。而这些微调代码、数据和经过微调后的模型也都会被开源。
研究人员致力于持续支持和发展OLMo及其框架,推动开放语言模型(LM)的发展,助力开放研究社区的发展。为此,研究人员计划引入更多不同规模的模型、多种模态、数据集、安全措施和评估方法,丰富OLMo家族。
#MiniCPM 2B
千元机也能本地运行。2B参数性能超Mistral-7B:面壁智能多模态端侧模型开源
在大模型不断向着大体量方向前进的同时,最近一段时间,人们在优化和部署方面也取得了成果。
2 月 1 日,面壁智能联合清华 NLP 实验室在北京正式发布了旗舰端侧大模型「面壁 MiniCPM」。新一代大模型被称为「性能小钢炮」,直接拥抱终端部署,同时也具有同量级最强的多模态能力。
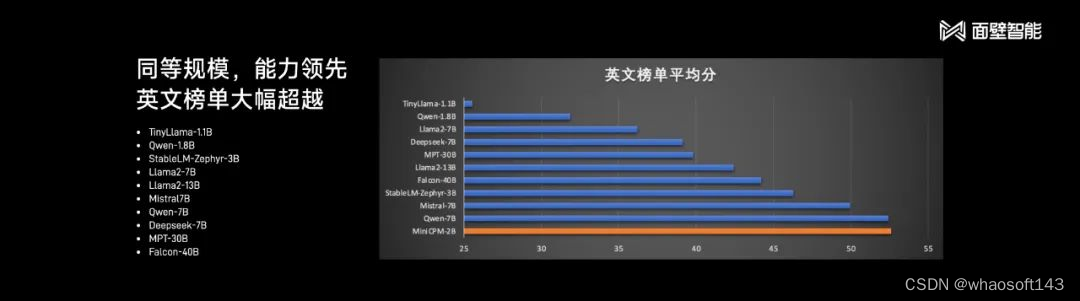
面壁智能本次提出的 MiniCPM 2B 参数量仅有 20 亿,使用 1T token 的精选数据训练。这是一个参数量上与 2018 年 BERT 同级的模型,面壁智能在其之上实现了极致的性能优化与成本控制,让该模型可以「越级打怪」。
面壁智能联合创始人、CEO 李大海将新模型与业内知名开源大模型 Mistral-7B 进行了对比,在多项主流评测榜单上,MiniCPM 2B 的性能全面超越了后者。

与微软近期提出的「小模型」Phi-2 相比,MiniCPM 也有很大优势。
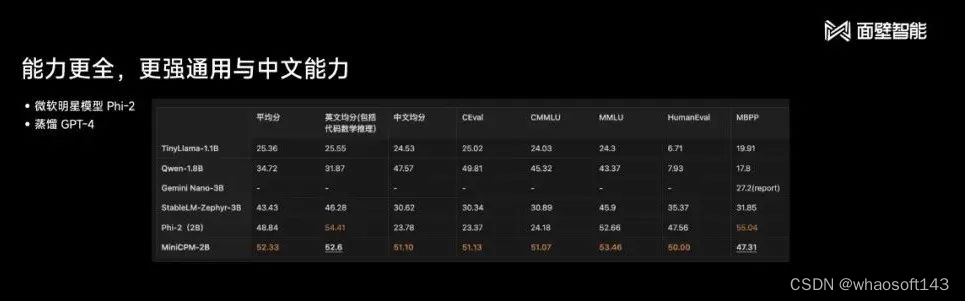
李大海表示,面壁智能的新模型还能越级实现 13B、30B 甚至 40B 模型的能力。在最接近用户体验的评测榜单 MT-Bench 上,MiniCPM 取得了 7 分的成绩(GPT-4-Turbo 为 9 分)。
在现场,面壁智能也演示了 MiniCPM 的实际应用效果。虽然参数量不大,但该模型可以实现文本翻译、角色扮演等诸多大模型应有的能力,并拥有丰富的知识,难度较高的代码解释任务也不在话下。

因为能够部署在端侧,在面临一些突发事件时,MiniCPM 也可以给人们提供及时帮助:

最近,各家手机厂商纷纷提出了端侧大模型,在把大语言模型压缩到较小体量之后,我们就能用它连接更多场景,在算力、内存受限的情况下获得更高程度的智能。相比之下,面壁智能提出的新技术更加轻便,可适用于更低配置,或较早期型号的手机。
据面壁智能介绍,MiniCPM 端侧模型经历了 Int4 量化后压缩了 75% 体量,只占用 2G 内存,与此同时性能几乎没有损失,因此已在各类常见型号的手机上实现了跑通。
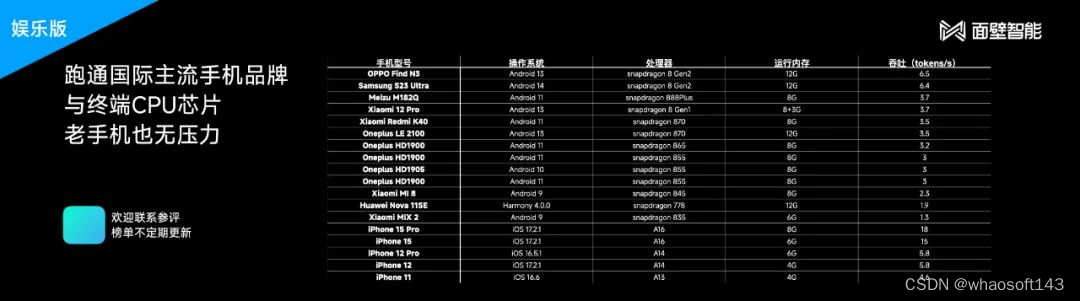
因为支持移动端 CPU 的推理,MiniCPM 可以很大程度上节约使用成本。面壁智能为我们算了一笔账:一台搭载骁龙 855 的手机使用 MiniCPM,一块钱电费可处理 170 万 token,这个价格仅为云端运行的 Mistral-Medium 的 1%。
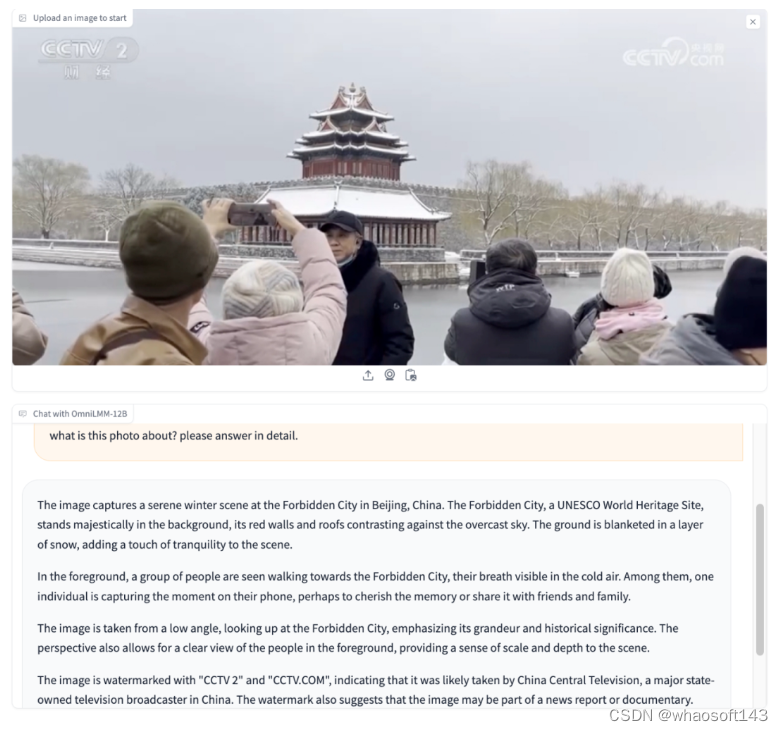
除了端侧模型,面壁智能还展示了其在多模态大模型方面的探索,并开源了 12B 参数量的 OmniLMM。在发布会上,面壁智能演示了 Gemini 发布时同款的石头剪刀布 demo。用英文向 AI 提问:我正在玩什么游戏?大模型会回答:石头剪子布。

与此同时,OmniLMM 也可以认出人类的手势,还能告诉你如果要赢应该出什么。
OmniLMM 还可以理解很多图片中的信息并进行推理,如地标建筑、电视台的台标、人们组织的活动等内容。
看来,我们距离真正多模态的大模型,以及新形态的应用已经不远了。
面壁智能大模型极致性能的背后,源于该公司长期以来的技术积累。自 2021 年,面壁智能就构建了高效的技术栈,集中在 Infra、算法和数据方法论三个方向。其中,自研的 BMTrain 高效训练框架至关重要。

在算法层面上,面壁智能也积累了模型沙盒体系,把大模型从炼丹提升到了实验科学的程度,在理论上不断寻找超参数和规模的最优解,如最优的 batch size、所有尺寸模型通用的超参数配置。
目前,面壁智能已积累了大量高质量的数据。在昨天的发布后,面壁智能开源了自身的新一代大模型系列(包含 MiniCPM-SFT / DPOMiniCPM-V & MiniCPM-SFT / DPO-int4),以及训练 MiniCPM 两个阶段的数据配方以供行业参考。
开源地址(含技术报告):
MiniCPM GitHub:https://github.com/OpenBMB/MiniCPM
OmniLMM GitHub:https://github.com/OpenBMB/OmniLMM
面壁智能源于清华 NLP 实验室,是在国内较早开展大模型研究的团队之一,其在 2018 年发布了全球首个基于知识指导的预训练模型 ERNIE。2022 年 8 月开始公司化运作的面壁智能,去年经历了两轮融资,其推出的应用「面壁露卡」也拿到了网信办第二批大模型备案。
#大模型微调对齐面试题整理
我面试过很多深度学习算法岗候选人,近一年转到阶跃星辰做大模型对齐,
最近招人很多,迫切先给自己训练一下面试题
我从知乎精华回答里挑一些问题,并给出自己的民科参考回答
参考素材:花甘者浅狐:大模型面试八股,一蓑烟雨:大模型强化学习面经
大模型微调相关:
- 大模型微调的时候,要关注什么超参数,如何选择优化?
- 预训练/微调训练 loss 炸掉了,如何解决?
- 微调过程和结束时,应该看什么评测指标?
- 微调的训练集的格式?
- 如何配比一堆微调训练集?
- 有什么轻量级微调的经验(比如 lora)?
- 如何避免 / 缓解微调时的过拟合?
- 如何快速评估和提升大模型中数据集的质量?
- 微调以后发现模型比预训练还差,可能的情况是?
- 评测微调过程中间结果,有些指标出乎意料的低,可能是为什么?
- 假设要做金融(举个例子)领域,怎么覆盖尽可能全的金融计算公式?
- 微调小模型在哪些方面效果会比大模型差很多?
- 为什么很多国产模型宣称 GPT4 能力?
- 模型输出重复和幻觉如何微调解决?
- 反向做微调修 badcase 的方案?
后文是我的回答,风格比较意识流
我的基本态度 1. 本来炼丹就是炼丹,大模型一般人做不起多少实验,科学结论就更少了,基本人云亦云 2. 既然是找工作,就要有力大砖飞的觉悟 3. 我尽力输出我训练100B+模型获得的认识
大模型微调的时候,要关注什么超参数,如何选择优化?
一句话:微调阶段基本没人调超参数
基本可以参照很多论文来选择,微调是个预训练的简化版本,比如参照预训练的工作 OPT 来选,或者直接参照做微调的论文 Deepseek Report,一般框架都选好了
真要答的话:有多少显存就开多大 batchsize,context length 看需求,一般 2048 往上吧,学习率衰减无脑 cosine 最好调试,learning rate 从论文里抄一个(按 batchsize 大小缩放一下);clip grad 设一个比较稳 0.3 吧,weight decay 有人用 0.1 也有用 0 的;其它更没什么可调了
预训练/微调训练 loss 炸掉了,如何解决?
一句话:预训练魔改重启,微调阶段没多少数据量都能炸,有点离谱吧
预训练炸掉的原因非常难监测,基本上就是一堆统计量某一两个飞了,可以加载前一个 ckpt 调学习率或加约束项尝试渡劫
赶紧 git clone 一个好的框架吧求求了,设小一点学习率再 clip grad 都不知道怎么炸
人家预训练容易炸是因为几千卡,向很多工程问题妥协才引入了一些训练不稳定的问题,就这样也几天才飞一次 loss
微调过程和结束时,应该看什么评测指标?
一句话:KPI 是什么就看什么,主观不好评价的就雇标注员
客观指标我推荐看 GSM8K,MMLU 和 BBH,关心 coding 可以看 Humaneval,能自己建个私有的保证没漏题的榜肯定更好
主观效果没有标注员自己攒个几十条每次扫一眼看看
微调的训练集的格式?
一句话:其实无所谓,看线上怎么用
常见的两种是 "System: Human: Assistant:" 和 "Instruct: Input: Output:" ,前者越来越流行了
多轮的时候就 "System: Human: Assistant: Human: Assistant: ...",难道用的模型不支持这种形式吗?那得看看 包包大人:大模型微调样本构造trick
如何配比一堆微调训练集?
一句话:含错误越少的数据可以占比越高
比如专家写的数据基本多多益善,编程和数学数据训练副作用都还比较小,爬虫爬的题库或者 chatGPT 造的数据比较容易有问题
实践时建议用 orca 这种数据集打个底,多样性不错,容易保持指令遵循能力,又是大模型风格的回答
警惕一些风格怪异的数据,比如说 system prompt 没有任何解释,但是回答却都通过写代码来解题(POT),这种训练完以后模型可能默认行为改变
有什么轻量级微调的经验(比如 lora)?
一句话:别用轻量级微调,租点卡训全参数吧
我知道 lora 似乎在垂域上的效果还行,但都工业界的人了,能不能花点钱租卡,只盯着几千条数据规模实验的话能不能不招人直接外包
反正我宁愿费卡也不愿意引入这种容易锁上限和引入新的问题的技术,我相信可训练参数量大了没坏处
本来大模型就是一把梭的实验风格,把卡省下来然后呢?
正经技术:CW不要無聊的風格:当红炸子鸡 LoRA,是当代微调 LLMs 的正确姿势?
如何避免 / 缓解微调时的过拟合?
一句话:数据去重后选大模型,只训练一个 epoch
不要小瞧大模型,只有孱弱到 7B 13B 的模型才需要多个 epoch,才要想着过拟合的问题!70B 一般也只有在 coding/math 这种数据 2 epoch,而且涨点有限。如果卡真的那么多就选更大的模型!
一个 epoch 也能过拟合?那就不要堆格式全都一样的数据,做点高质量的。再说一遍,把 orca 加进去打底,LIMA,no_robot 也好啊。
实在非得上小模型,花点钱加数据量不行吗?
训 MOE 模组?那是我僭越了,MOE 多 epoch 加 dropout 还是好使的
如何快速评估和提升大模型中数据集的质量?
一句话:肉眼抽样看,和 GPT4 的回答对比感受一下哪个好,不如 GPT4 的话调 API 生成数据
训练完有问题再反查,比如学会了某种机械的答题格式,那就把该类数据清洗或者加增广;比如模型生成了怪东西,就把相关污染找出来
微调以后发现模型比预训练还差,可能的情况是?
一句话:抄个成熟方案,做增量实验,实在不行在别人微调完的基础上再微调
尽量训练末期降低学习率,前文说了用 cosine 不亏
监测微调过程中间结果,尽早发现问题
有极少的任务,比如创作生成类任务,可能微调完模型就是创造力缺乏,感觉遏制了模型的天性
除此之外就只能是 bug 或者数据投毒了
评测微调过程中间结果,有些指标出乎意料的低,为什么?
一句话:如果过一会儿就好了,说明在有些评测集上回答格式崩了
比如 GSM8K 可能要求以 “The answer is: ”回答,模型有的时候可能不完全听指令,这时候最好微调带一点相关训练集
loss 炸了跳转第 3 条
假设要做金融(举个例子)领域,怎么覆盖尽可能全的金融计算公式?
一句话:学知识交给继续预训练,微调就是图个激发
知识量靠微调来灌是不行的,一种数据量太大就从通用模型变专用模型了,本来微调对模型的改动相对预训练就是很微弱的
微调小模型在哪些方面效果会比大模型差很多?
一句话:硬核任务体现大模型优势,大模型 COT 也更强
数学和代码是一般模型和 GPT4 最大的差距所在,我还发现模型越大,似乎天然越理解人类价值观
为什么很多国产模型宣称 GPT4 能力?
一句话:防泄题/作弊非常重要,通用和垂域分开看
因为目前几B几十B参数量下,模型记忆力离谱的好,局部泛化能力很强,所以有些小模型能在某些特定榜单刷的巨高,还有很多榜 GPT4 不高但是国产模型可厉害
说不定和测试集很像的东西进了训练集
举个例子,MMLU(英文) 和 CEval(中文) 是比较相似的,都是学科选择题,但是如果后者很高前者不行,那说明喂了很多中文做题数据;还有比如说模型数学题 MATH,GSM8K 刷的巨好,但是看 MMLU 和 CEval 的数学选择题却又很差,基本上是有意或无意地泄题了
训了一个70B模型,结果指标被人家3B、7B模型打爆,这种指标绕着走
如果专精小领域,那数据为王,GPT4 不会的领域还很多
模型输出重复和幻觉如何微调解决?
一句话:修 badcase 还得看强化学习
合成数据放多了微调可能也会提高重复,但是调数据不好压下去,强化学习不香吗
幻觉也是可以造负样本来修
反向做微调修 badcase 的方案?
一句话:得不偿失,还是靠强化学习
虽然这样处理负样本确实会有效果,但是很容易把模型能力搞废
#MoE-LLaVA
将多模态大模型稀疏化,MoE-LLaVA只有3B个稀疏激活参数,表现与LLaVA-1.5-7B在各种视觉理解数据集上相当,并且在物体幻觉基准测试中甚至超越了LLaVA-1.5-13B。
对于大型视觉语言模型(LVLM)而言,扩展模型可以有效提高模型性能。然而,扩大参数规模会显著增加训练和推理成本,因为计算中每个 token 都会激活所有模型参数。将多模态大模型稀疏化,3B模型MoE-LLaVA媲美LLaVA-1.5-7B
基于此,来自北京大学、中山大学等机构的研究者联合提出了一种新颖的 LVLM 训练策略 ——MoE-Tuning。MoE-Tuning 可以构建参数数量惊人但计算成本恒定的稀疏模型,并有效解决通常与多模态学习和模型稀疏性相关的性能下降问题。该研究还提出了一种基于 MoE 的新型稀疏 LVLM 架构 ——MoE-LLaVA 框架。该框架独特地在部署过程中通过路由算法仅激活 top-k 专家(expert),其余专家保持非活动(inactive)状态。
- 论文地址:https://arxiv.org/abs/2401.15947
- 项目地址:https://github.com/PKU-YuanGroup/MoE-LLaVA
- Demo地址:https://huggingface.co/spaces/LanguageBind/MoE-LLaVA
- 论文题目:MoE-LLaVA: Mixture of Experts for Large Vision-Language Models
MoE-LLaVA 只有 3B 个稀疏激活参数,表现却与 LLaVA-1.5-7B 在各种视觉理解数据集上相当,甚至在物体幻觉基准测试中甚至超越了 LLaVA-1.5-13B。通过 MoE-LLaVA,该研究旨在建立稀疏 LVLMs 的基准,并为未来研究开发更高效和有效的多模态学习系统提供宝贵的见解。MoE-LLaVA 团队已经开放了所有的数据、代码和模型。
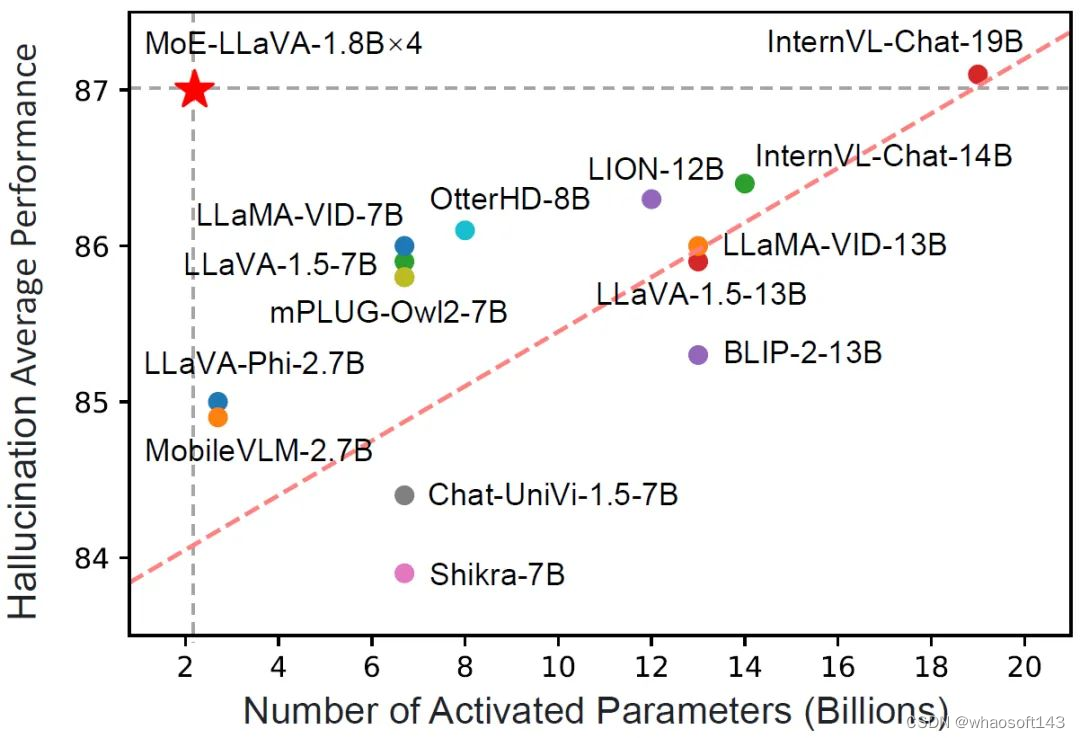
图 1 MoE-LLaVA 在幻觉性能上和其他 LVLM 的比较
方法简介
MoE-LLaVA 采用三阶段的训练策略。
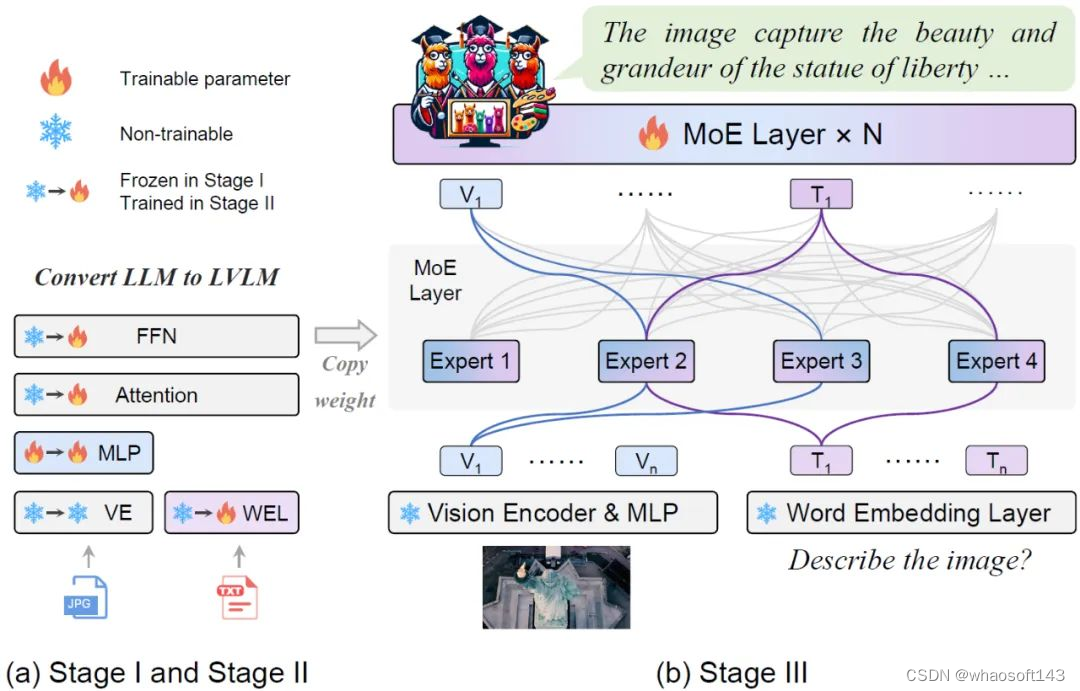
图 2 MoE-Tuning 的流程图
如图 2 所示,视觉编码器(vision encoder)处理输入图片得到视觉 token 序列。利用一个投影层将视觉 token 映射成 LLM 可接受的维度。类似地,与图片配对的文本经过一个词嵌入层(word embedding layer)被投影得到序列文本 token。
阶段 1:如图 2 所示,阶段 1 的目标是让视觉 token 适应到 LLM,赋予 LLM 看懂图片的实体有哪些的能力。MoE-LLaVA 采用一个 MLP 来将图片 token 投影到 LLM 的输入域,这意味着一个个图片小 patch 被 LLM 当作伪文本 token。在这个阶段,LLM 被训练学会描述图片,理解更高层次的图片语义。在这个阶段 MoE 层不会被应用到 LVLM 中。
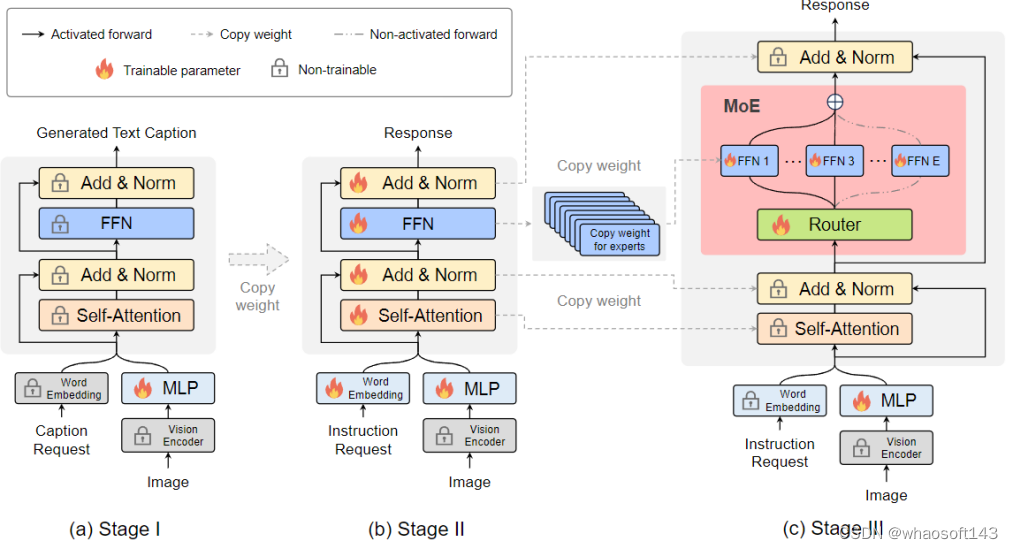
图 3 更具体的训练框架和训练策略
阶段 2:用多模态的指令数据来微调是提高大模型能力和可控性的关键技术,并且在这个阶段 LLM 被调整为有多模态理解能力的 LVLM。在这个阶段该研究加入更复杂的指令,包含图片逻辑推理,文字识别等高级任务,要求模型有更强的多模态理解能力。通常来说,稠密模型的 LVLM 到此就训练完成,然而研究团队发现同时将 LLM 转为 LVLM 和把模型稀疏化是具有挑战的。因此,MoE-LLaVA 将使用第二阶段的权重作为第三阶段的初始化以降低稀疏模型学习的难度。
阶段 3:MoE-LLaVA 将 FFN 复制多份作为专家集合的初始化权重。当视觉 token 和文本 token 被喂入 MoE 层时,router 会计算每一个 token 和专家们的匹配权重,然后每个 token 会被送入最匹配的 top-k 个专家进行处理,最后根据 router 的权重加权求和汇聚成输出。当 top-k 个专家被激活时,其余的专家保持非活动状态,这种模型构成了具有无限可能的稀疏通路的 MoE-LLaVA。
实验
如图 4 所示,由于 MoE-LLaVA 是第一个基于 LVLM 搭载 soft router 的稀疏模型,因此该研究将之前的模型归纳为稠密模型。研究团队在 5 个图片问答 benchmark 上验证了 MoE-LLaVA 的性能,并报告了激活的参数量和图片分辨率。与 SOTA 方法 LLaVA-1.5 相比,MoE-LLaVA-2.7B×4 展现了强大的图片理解能力,在 5 个 benchmark 上性能非常接近 LLaVA-1.5。其中 MoE-LLaVA 用 3.6B 的稀疏激活参数在 SQAI 上超过了 LLaVA-1.5-7B 1.9%。值得注意的是,由于 MoE-LLaVA 的稀疏结构,只需要 2.6B 的激活参数量就能全面超过 IDEFICS-80B。
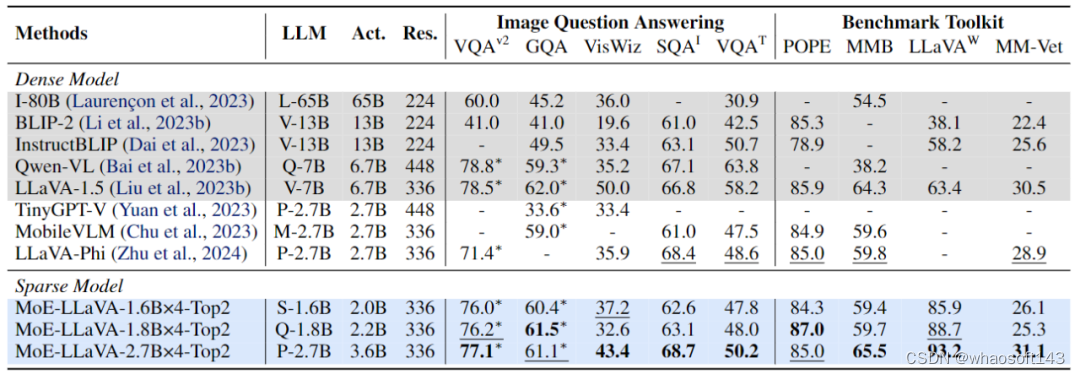
图 4 MoE-LLaVA 在 9 个 benchmark 上的性能
另外,研究团队还关注到最近的小视觉语言模型 TinyGPT-V,MoE-LLaVA-1.8B×4 在相当的激活参数下在 GQA 和 VisWiz 分别超过 TinyGPT-V 27.5% 和 10%,这标志着 MoE-LLaVA 强大的理解能力在自然视觉中。
为了更全面地验证 MoE-LLaVA 的多模态理解能力,该研究在 4 个 benchmark toolkit 上评估了模型性能。benchmark toolkit 是验证模型能否能自然语言问答的工具包,通常答案是开放性的并且无固定模板。如图 4 所示,MoE-LLaVA-1.8B×4 超过了 Qwen-VL,后者使用更大的图片分辨率。这些结果都展示了 MoE-LLaVA 这一稀疏模型可以用更少的激活参数达到和稠密模型相当甚至超过的性能。
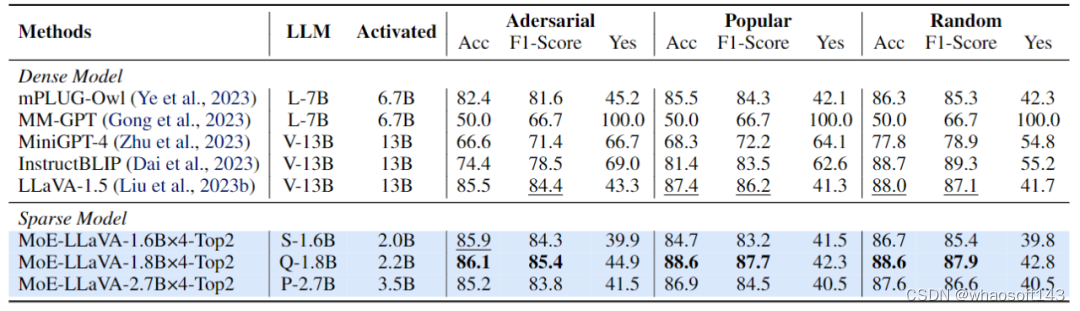
图 5 MoE-LLaVA 在幻觉物体检测上的性能评估
该研究采用 POPE 评估 pipeline 来验证 MoE-LLaVA 的物体幻觉,结果如图 5 所示,MoE-LLaVA 展现出最好的性能,意味着 MoE-LLaVA 倾向于生成与给定图像一致的对象。具体的,MoE-LLaVA-1.8B×4 以 2.2B 的激活参数超过了 LLaVA。另外,研究团队观察到 MoE-LLaVA 的 yes ratio 占比处于较均衡状态,这表明稀疏模型 MoE-LLaVA 能够根据问题做出正确的反馈。
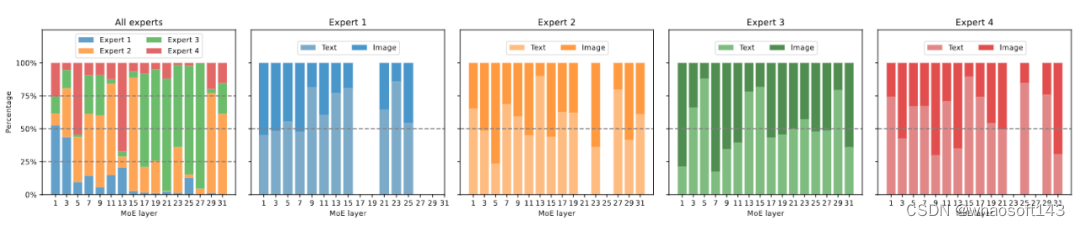
图 6 专家负载可视化
图 6 展示了在 ScienceQA 上 MoE-LLaVA-2.7B×4-Top2 的专家负载。整体上,在训练初始化时,所有的 MoE 层 中的专家的负载比较平衡。然而随着模型逐渐被稀疏化,第 17 到 27 层的专家的负载突然增大,甚至几乎包揽了所有 token。对于浅层的 5-11 层,主要是由专家 2、3、4 共同协作。值得关注的是,专家 1 几乎只在第 1-3 层工作,随着模型变深,专家 1 逐渐退出了工作。因此,MoE-LLaVA 的专家们学到了某种特定的模式,它能够按照一定的规律进行专家分工。
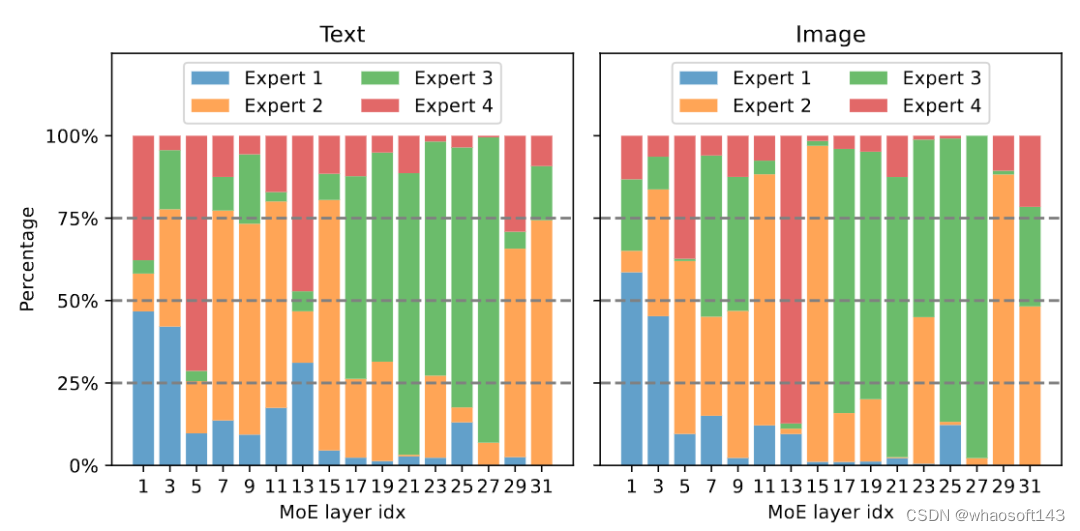
图 7 模态分布可视化
图 7 展示了不同专家的模态分布。该研究发现 text 和 image 的路由分布极其相似,例如当专家 3 在 17-27 层努力工作时,它所处理的 text 和 image 的占比是相似的。这表明 MoE-LLaVA 对于模态并无明显的偏好。
该研究还在 token level 上观察了专家们的行为,并在下游任务上跟踪所有 token 在稀疏网络中的轨迹。对 text 和 image 所有激活的通路,该研究采用 PCA 降维得到主要的 10 条通路,如图 8 所示。研究团队发现对于某个未见的 text token 或 image token,MoE-LLaVA 始终偏向于派发专家 2 和 3 来处理模型深层。专家 1、4 倾向于处理初始化的 token。这些结果能够帮助我们更好地理解稀疏模型在多模态学习上的行为,并探索未知的可能。
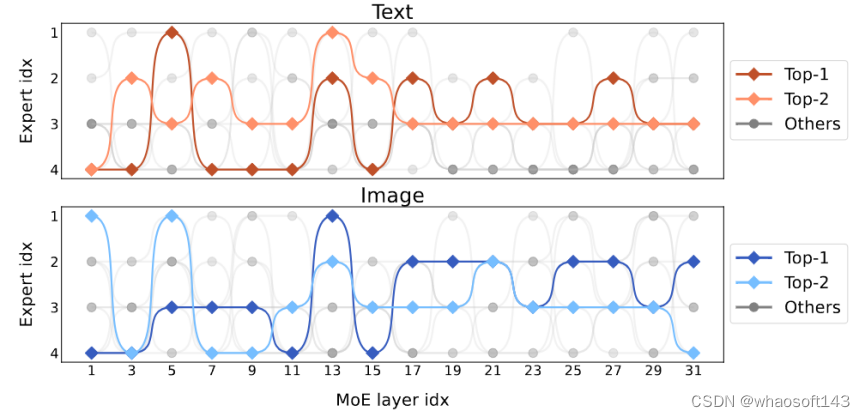
图 8 激活通路可视化
#Llama2~PromptEngineering
Meta官方的Prompt工程指南:Llama 2这样用更高效, 随着大型语言模型(LLM)技术日渐成熟,提示工程(Prompt Engineering)变得越来越重要。一些研究机构发布了 LLM 提示工程指南,包括微软、OpenAI 等等。
最近,Llama 系列开源模型的提出者 Meta 也针对 Llama 2 发布了一份交互式提示工程指南,涵盖了 Llama 2 的快速工程和最佳实践。
以下是这份指南的核心内容。
Llama 模型
2023 年,Meta 推出了 Llama 、Llama 2 模型。较小的模型部署和运行成本较低,而更大的模型能力更强。
Llama 2 系列模型参数规模如下:

Code Llama 是一个以代码为中心的 LLM,建立在 Llama 2 的基础上,也有各种参数规模和微调变体:

部署 LLM
LLM 可以通过多种方式部署和访问,包括:
自托管(Self-hosting):使用本地硬件来运行推理,例如使用 llama.cpp 在 Macbook Pro 上运行 Llama 2。优势:自托管最适合有隐私 / 安全需要的情况,或者您拥有足够的 GPU。
云托管:依靠云提供商来部署托管特定模型的实例,例如通过 AWS、Azure、GCP 等云提供商来运行 Llama 2。优势:云托管是最适合自定义模型及其运行时的方式。
托管 API:通过 API 直接调用 LLM。有许多公司提供 Llama 2 推理 API,包括 AWS Bedrock、Replicate、Anyscale、Together 等。优势:托管 API 是总体上最简单的选择。
托管 API
托管 API 通常有两个主要端点(endpoint):
1. completion:生成对给定 prompt 的响应。
2. chat_completion:生成消息列表中的下一条消息,为聊天机器人等用例提供更明确的指令和上下文。
token
LLM 以称为 token 的块的形式来处理输入和输出,每个模型都有自己的 tokenization 方案。比如下面这句话:
Our destiny is written in the stars.
Llama 2 的 tokenization 为 ["our", "dest", "iny", "is", "writing", "in", "the", "stars"]。考虑 API 定价和内部行为(例如超参数)时,token 显得尤为重要。每个模型都有一个 prompt 不能超过的最大上下文长度,Llama 2 是 4096 个 token,而 Code Llama 是 100K 个 token。
Notebook 设置
作为示例,我们使用 Replicate 调用 Llama 2 chat,并使用 LangChain 轻松设置 chat completion API。
首先安装先决条件:
pip install langchain replicatefrom typing import Dict, List
from langchain.llms import Replicate
from langchain.memory import ChatMessageHistory
from langchain.schema.messages import get_buffer_string
import os
# Get a free API key from https://replicate.com/account/api-tokens
os.environ ["REPLICATE_API_TOKEN"] = "YOUR_KEY_HERE"
LLAMA2_70B_CHAT = "meta/llama-2-70b-chat:2d19859030ff705a87c746f7e96eea03aefb71f166725aee39692f1476566d48"
LLAMA2_13B_CHAT = "meta/llama-2-13b-chat:f4e2de70d66816a838a89eeeb621910adffb0dd0baba3976c96980970978018d"
# We'll default to the smaller 13B model for speed; change to LLAMA2_70B_CHAT for more advanced (but slower) generations
DEFAULT_MODEL = LLAMA2_13B_CHAT
def completion (
prompt: str,
model: str = DEFAULT_MODEL,
temperature: float = 0.6,
top_p: float = 0.9,
) -> str:
llm = Replicate (
model=model,
model_kwargs={"temperature": temperature,"top_p": top_p, "max_new_tokens": 1000}
)
return llm (prompt)
def chat_completion (
messages: List [Dict],
model = DEFAULT_MODEL,
temperature: float = 0.6,
top_p: float = 0.9,
) -> str:
history = ChatMessageHistory ()
for message in messages:
if message ["role"] == "user":
history.add_user_message (message ["content"])
elif message ["role"] == "assistant":
history.add_ai_message (message ["content"])
else:
raise Exception ("Unknown role")
return completion (
get_buffer_string (
history.messages,
human_prefix="USER",
ai_prefix="ASSISTANT",
),
model,
temperature,
top_p,
)
def assistant (content: str):
return { "role": "assistant", "content": content }
def user (content: str):
return { "role": "user", "content": content }
def complete_and_print (prompt: str, model: str = DEFAULT_MODEL):
print (f'==============\n {prompt}\n==============')
response = completion (prompt, model)
print (response, end='\n\n')Completion API
complete_and_print ("The typical color of the sky is:")complete_and_print ("which model version are you?")Chat Completion 模型提供了与 LLM 互动的额外结构,将结构化消息对象数组而不是单个文本发送到 LLM。此消息列表为 LLM 提供了一些可以继续进行的「背景」或「历史」信息。
通常,每条消息都包含角色和内容:
具有系统角色的消息用于开发人员向 LLM 提供核心指令。
具有用户角色的消息通常是人工提供的消息。
具有助手角色的消息通常由 LLM 生成。
response = chat_completion (messages=[
user ("My favorite color is blue."),
assistant ("That's great to hear!"),
user ("What is my favorite color?"),
])
print (response)
# "Sure, I can help you with that! Your favorite color is blue."LLM 超参数
LLM API 通常会采用影响输出的创造性和确定性的参数。在每一步中,LLM 都会生成 token 及其概率的列表。可能性最小的 token 会从列表中「剪切」(基于 top_p),然后从剩余候选者中随机(温度参数 temperature)选择一个 token。换句话说:top_p 控制生成中词汇的广度,温度控制词汇的随机性,温度参数 temperature 为 0 会产生几乎确定的结果。
def print_tuned_completion (temperature: float, top_p: float):
response = completion ("Write a haiku about llamas", temperature=temperature, top_p=top_p)
print (f'[temperature: {temperature} | top_p: {top_p}]\n {response.strip ()}\n')
print_tuned_completion (0.01, 0.01)
print_tuned_completion (0.01, 0.01)
# These two generations are highly likely to be the same
print_tuned_completion (1.0, 1.0)
print_tuned_completion (1.0, 1.0)
# These two generations are highly likely to be differentprompt 技巧
详细、明确的指令会比开放式 prompt 产生更好的结果:
complete_and_print (prompt="Describe quantum physics in one short sentence of no more than 12 words")
# Returns a succinct explanation of quantum physics that mentions particles and states existing simultaneously.我们可以给定使用规则和限制,以给出明确的指令。
- 风格化,例如:
- 向我解释一下这一点,就像儿童教育网络节目中教授小学生一样;
- 我是一名软件工程师,使用大型语言模型进行摘要。用 250 字概括以下文字;
- 像私家侦探一样一步步追查案件,给出你的答案。
- 格式化
- 使用要点;
- 以 JSON 对象形式返回;
- 使用较少的技术术语并用于工作交流中。
- 限制
- 仅使用学术论文;
- 切勿提供 2020 年之前的来源;
- 如果你不知道答案,就说你不知道。
以下是给出明确指令的例子:
complete_and_print ("Explain the latest advances in large language models to me.")
# More likely to cite sources from 2017
complete_and_print ("Explain the latest advances in large language models to me. Always cite your sources. Never cite sources older than 2020.")
# Gives more specific advances and only cites sources from 2020零样本 prompting
一些大型语言模型(例如 Llama 2)能够遵循指令并产生响应,而无需事先看过任务示例。没有示例的 prompting 称为「零样本 prompting(zero-shot prompting)」。例如:
complete_and_print ("Text: This was the best movie I've ever seen! \n The sentiment of the text is:")
# Returns positive sentiment
complete_and_print ("Text: The director was trying too hard. \n The sentiment of the text is:")
# Returns negative sentiment少样本 prompting
添加所需输出的具体示例通常会产生更加准确、一致的输出。这种方法称为「少样本 prompting(few-shot prompting)」。例如:
def sentiment (text):
response = chat_completion (messages=[
user ("You are a sentiment classifier. For each message, give the percentage of positive/netural/negative."),
user ("I liked it"),
assistant ("70% positive 30% neutral 0% negative"),
user ("It could be better"),
assistant ("0% positive 50% neutral 50% negative"),
user ("It's fine"),
assistant ("25% positive 50% neutral 25% negative"),
user (text),
])
return response
def print_sentiment (text):
print (f'INPUT: {text}')
print (sentiment (text))
print_sentiment ("I thought it was okay")
# More likely to return a balanced mix of positive, neutral, and negative
print_sentiment ("I loved it!")
# More likely to return 100% positive
print_sentiment ("Terrible service 0/10")
# More likely to return 100% negativeRole Prompting
Llama 2 在指定角色时通常会给出更一致的响应,角色为 LLM 提供了所需答案类型的背景信息。
例如,让 Llama 2 对使用 PyTorch 的利弊问题创建更有针对性的技术回答:
complete_and_print ("Explain the pros and cons of using PyTorch.")
# More likely to explain the pros and cons of PyTorch covers general areas like documentation, the PyTorch community, and mentions a steep learning curve
complete_and_print ("Your role is a machine learning expert who gives highly technical advice to senior engineers who work with complicated datasets. Explain the pros and cons of using PyTorch.")
# Often results in more technical benefits and drawbacks that provide more technical details on how model layers思维链
简单地添加一个「鼓励逐步思考」的短语可以显著提高大型语言模型执行复杂推理的能力(Wei et al. (2022)),这种方法称为 CoT 或思维链 prompting:
complete_and_print ("Who lived longer Elvis Presley or Mozart?")
# Often gives incorrect answer of "Mozart"
complete_and_print ("Who lived longer Elvis Presley or Mozart? Let's think through this carefully, step by step.")
# Gives the correct answer "Elvis"自洽性(Self-Consistency)
LLM 是概率性的,因此即使使用思维链,一次生成也可能会产生不正确的结果。自洽性通过从多次生成中选择最常见的答案来提高准确性(以更高的计算成本为代价):
import re
from statistics import mode
def gen_answer ():
response = completion (
"John found that the average of 15 numbers is 40."
"If 10 is added to each number then the mean of the numbers is?"
"Report the answer surrounded by three backticks, for example:```123```",
model = LLAMA2_70B_CHAT
)
match = re.search (r'```(\d+)```', response)
if match is None:
return None
return match.group (1)
answers = [gen_answer () for i in range (5)]
print (
f"Answers: {answers}\n",
f"Final answer: {mode (answers)}",
)
# Sample runs of Llama-2-70B (all correct):
# [50, 50, 750, 50, 50] -> 50
# [130, 10, 750, 50, 50] -> 50
# [50, None, 10, 50, 50] -> 50检索增强生成
有时我们可能希望在应用程序中使用事实知识,那么可以从开箱即用(即仅使用模型权重)的大模型中提取常见事实:
complete_and_print ("What is the capital of the California?", model = LLAMA2_70B_CHAT)
# Gives the correct answer "Sacramento"然而,LLM 往往无法可靠地检索更具体的事实或私人信息。模型要么声明它不知道,要么幻想出一个错误的答案:
complete_and_print ("What was the temperature in Menlo Park on December 12th, 2023?")
# "I'm just an AI, I don't have access to real-time weather data or historical weather records."
complete_and_print ("What time is my dinner reservation on Saturday and what should I wear?")
# "I'm not able to access your personal information [..] I can provide some general guidance"检索增强生成(RAG)是指在 prompt 中包含从外部数据库检索的信息(Lewis et al. (2020))。RAG 是将事实纳入 LLM 应用的有效方法,并且比微调更经济实惠,微调可能成本高昂并对基础模型的功能产生负面影响。
MENLO_PARK_TEMPS = {
"2023-12-11": "52 degrees Fahrenheit",
"2023-12-12": "51 degrees Fahrenheit",
"2023-12-13": "51 degrees Fahrenheit",
}
def prompt_with_rag (retrived_info, question):
complete_and_print (
f"Given the following information: '{retrived_info}', respond to: '{question}'"
)
def ask_for_temperature (day):
temp_on_day = MENLO_PARK_TEMPS.get (day) or "unknown temperature"
prompt_with_rag (
f"The temperature in Menlo Park was {temp_on_day} on {day}'", # Retrieved fact
f"What is the temperature in Menlo Park on {day}?", # User question
)
ask_for_temperature ("2023-12-12")
# "Sure! The temperature in Menlo Park on 2023-12-12 was 51 degrees Fahrenheit."
ask_for_temperature ("2023-07-18")
# "I'm not able to provide the temperature in Menlo Park on 2023-07-18 as the information provided states that the temperature was unknown."程序辅助语言模型
LLM 本质上不擅长执行计算,例如:
complete_and_print ("""
Calculate the answer to the following math problem:
((-5 + 93 * 4 - 0) * (4^4 + -7 + 0 * 5))
""")
# Gives incorrect answers like 92448, 92648, 95463Gao et al. (2022) 提出「程序辅助语言模型(Program-aided Language Models,PAL)」的概念。虽然 LLM 不擅长算术,但它们非常擅长代码生成。PAL 通过指示 LLM 编写代码来解决计算任务。
complete_and_print (
"""
# Python code to calculate: ((-5 + 93 * 4 - 0) * (4^4 + -7 + 0 * 5))
""",
model="meta/codellama-34b:67942fd0f55b66da802218a19a8f0e1d73095473674061a6ea19f2dc8c053152"
)# The following code was generated by Code Llama 34B:
num1 = (-5 + 93 * 4 - 0)
num2 = (4**4 + -7 + 0 * 5)
answer = num1 * num2
print (answer)#LeptonSearch
来了,贾扬清承诺的 Lepton Search 开源代码来了。
前天,贾扬清在 Twitter 上公布了 Lepton Search 的开源项目链接,并表示任何人、任何公司都可以自由使用开源代码。
项目链接:https://github.com/leptonai/search_with_lepton
也就是说,你也可以用不到 500 行 Python 代码构建自己的对话搜索引擎了。
今天,Lepton Search 又登上了 GitHub trending 榜单。
此外已经有人将这个开源项目用来构建自己的 Web 应用程序了,并表示质量非常高,与 AI 驱动的搜索引擎 Perplexity 不相上下。
而就在几天前,关于 Lepton Search 项目,贾扬清还与 Perplexity 这家 AI 搜索引擎初创公司的印度裔创始人展开了一场「隔空对话」。
demo 被内涵,贾扬清选择开源
自贾扬清离开阿里创业之后,有关新公司 Lepton AI 的动态一直挺受社区的关注。
1 月 25 日,贾扬清在 Twitter 上宣传了一个 demo,用不到 500 行 Python 代码实现了 AI 对话搜索引擎,展现了构建 AI App 变得如此简单。
据了解,Lepton Search 具有以下特征:
- 内置支持大语言模型(LLM)
- 内置支持搜索引擎
- 自定义 UI 界面
- 搜索结果可共享、缓存
此外,Lepton Search 背后使用 MistralAI 开源的 Mixtral-8x7b作为支撑模型,运行在 LeptonAI 的 playground 托管平台上,吞吐量高达 200 tokens / 秒。该搜索引擎目前使用的是必应搜索 API,Lepton KV 作为无服务器存储。
贾扬清表示,Lepton Search 的 idea 受到了 Perplexity AI、Phind 等由 LLM 驱动的搜索引擎的启发。
其中, Perplexity AI 成立于 2022 年 8 月,是世界上首个对话式搜索引擎,通过 GPT 这样的先进 AI 技术,它能够为问题直接生成答案,并对准确率与效率有很高的标准。该公司由前 OpenAI 研究科学家 Aravind Srinivas (Perplexity CEO)与前 Meta 研究科学家 Denis Yarats(Perplexity CTO)等合伙人共同创办。
该搜索引擎在发布后广受欢迎,被越来越多的人使用,并对谷歌等传统搜索引擎发起挑战。1 月初,该公司宣布完成了 7360 万美元 B 轮融资,最新估值 5 亿美元。
在看到贾扬清 Lepton Search 的 demo 后,Aravind Srinivas 发表了一段话,「非常高兴看到 Perplexity 成为未来融资活动的标杆,连前阿里巴巴技术副总裁都来借鉴。这说明了 Perplexity 的影响力不再停留在产品自身,还延伸到了整个生态圈层和行业发展。」
评论区的网友更是直白,认为 Lepton Search「复刻」了 Perplexity AI 的界面。
面对 Aravind Srinivas 的善意之言(kind words),贾扬清回应称,自己非常喜欢 Perplexity,它从根本上改变了人们对搜索的看法。Lepton AI 则专注于让创作者更轻松构建 AI 应用程序的现代云解决方案,Lepton Search 的 demo 展示了如何实现这一目标。当然该搜索项目的代码也会开源。
于是,我们看到了「search_with_lepton」项目。目前,该项目已经积累了 1.1k 的 Star 量。贾扬清也兑现了自己的开源承诺。

欢迎加入 MCP 技术社区!与志同道合者携手前行,一同解锁 MCP 技术的无限可能!
更多推荐


 10
10 0
0- 0



 已为社区贡献29条内容
已为社区贡献29条内容

所有评论(0)