终于把 Transformer 算法搞懂了!!
今天给大家介绍一个超强的算法模型,TransformerTransformer 是一种基于自注意力机制(Self-Attention)的神经网络模型,最早由 Vaswani 等人在论文《Attention is All You Need》中提出,主要用于处理序列到序列的任务,例如自然语言处理(NLP)中的翻译任务。与传统的循环神经网络(RNN)和长短期记忆网络(LSTM)相比,Transforme
今天给大家介绍一个超强的算法模型,Transformer
Transformer 是一种基于自注意力机制(Self-Attention)的神经网络模型,最早由 Vaswani 等人在论文《Attention is All You Need》中提出,主要用于处理序列到序列的任务,例如自然语言处理(NLP)中的翻译任务。
与传统的循环神经网络(RNN)和长短期记忆网络(LSTM)相比,Transformer 通过完全摆脱循环结构,依赖于注意力机制来捕捉序列中的长依赖关系。
文末免费领取本文的 pdf 版本
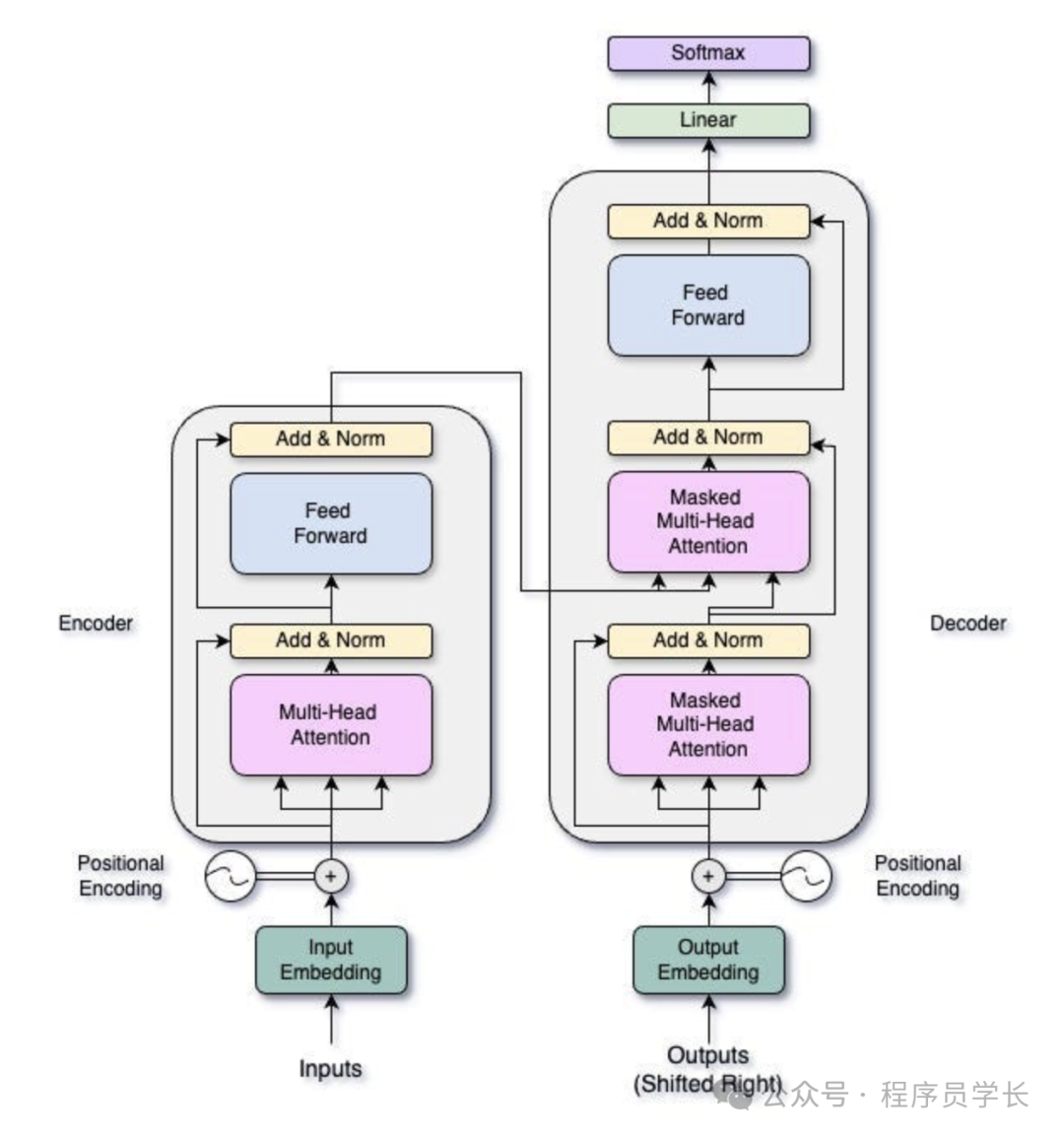
Transformer 模型架构
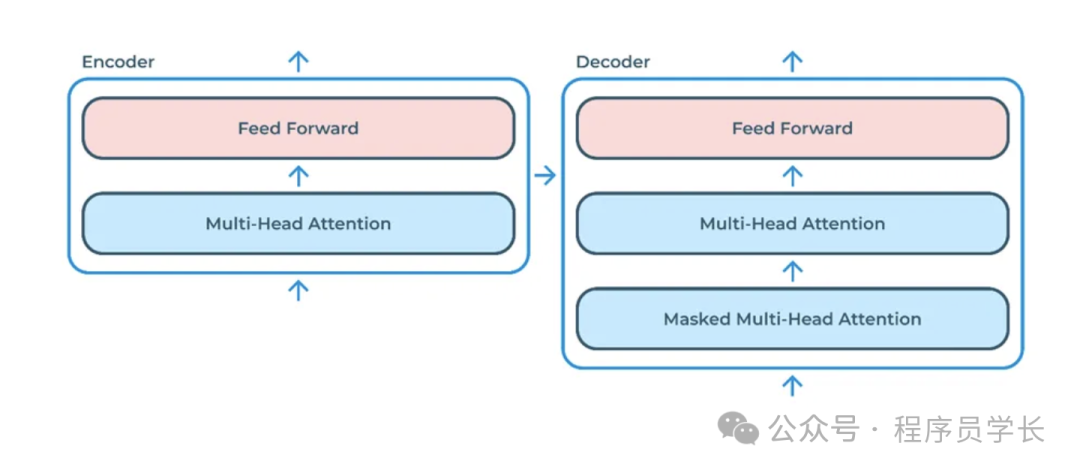
Transformer 由两个主要部分组成:编码器和解码器。
编码器负责接收输入序列并生成一组向量表示,解码器则利用这些向量生成输出序列。
编码器(Encoder)
编码器由多个相同的层组成,每个层都有两个主要子层
-
多头自注意力机制
-
前馈神经网络
解码器(Decoder)
解码器的结构与编码器类似,包含多个相同的层,但解码器的每一层有三个子层
-
掩蔽自注意力层
-
编码器-解码器注意力层
-
前馈神经网络
解码器的作用是生成每一步的输出,直到输出完整的序列。
核心组件
下面,我们来详细解释一下 transformer 中包括的核心组件。
1.输入
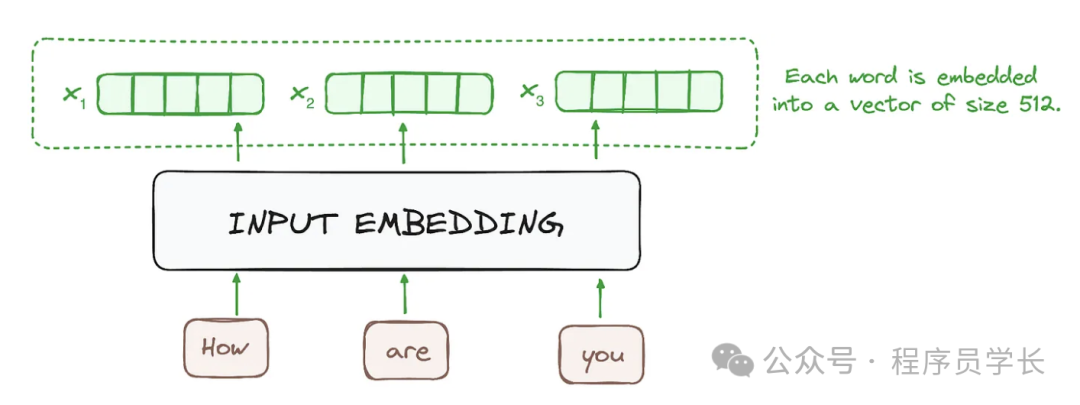
在自然语言处理(NLP)任务中,Transformer 模型的输入通常是一个符号序列,比如单词、子词或字符。
这个序列由一个个离散的符号构成,例如一个句子 “How are you” 就是一个符号序列。
模型并不能直接处理这些离散符号,需要将它们转换为模型可以理解的连续向量表示。
输入处理的步骤
-
分词
首先,句子会被分解成基本的符号单元(单词或子词)。
例如,句子 “How are you” 会被分解成三个符号:[How, are, you]。
-
词汇表映射
这些符号会映射为词汇表中的索引。
比如,假设词汇表中 “How” 的索引是 100,“are” 是 150,“you” 是 200,那么句子的输入表示为 [100, 150, 200]。
此时,这些索引依然是离散的整数,无法直接供神经网络处理,因此需要进一步转化为连续的向量表示。
2.输入嵌入
输入嵌入的目的是将这些离散的符号索引转换为连续的向量表示。
每个符号的嵌入向量保留了符号的语义信息,嵌入空间中的相似向量可以代表语义上相近的符号。
Transformer 使用一个可训练的嵌入矩阵来将符号索引映射为固定维度的向量。
嵌入矩阵的大小为 ,其中 是词汇表的大小(即有多少个不同的符号), 是嵌入向量的维度。
给定输入序列中的符号索引
每个索引都会通过查找嵌入矩阵得到其对应的嵌入向量
其中 ,每个 是一个 维度的向量。
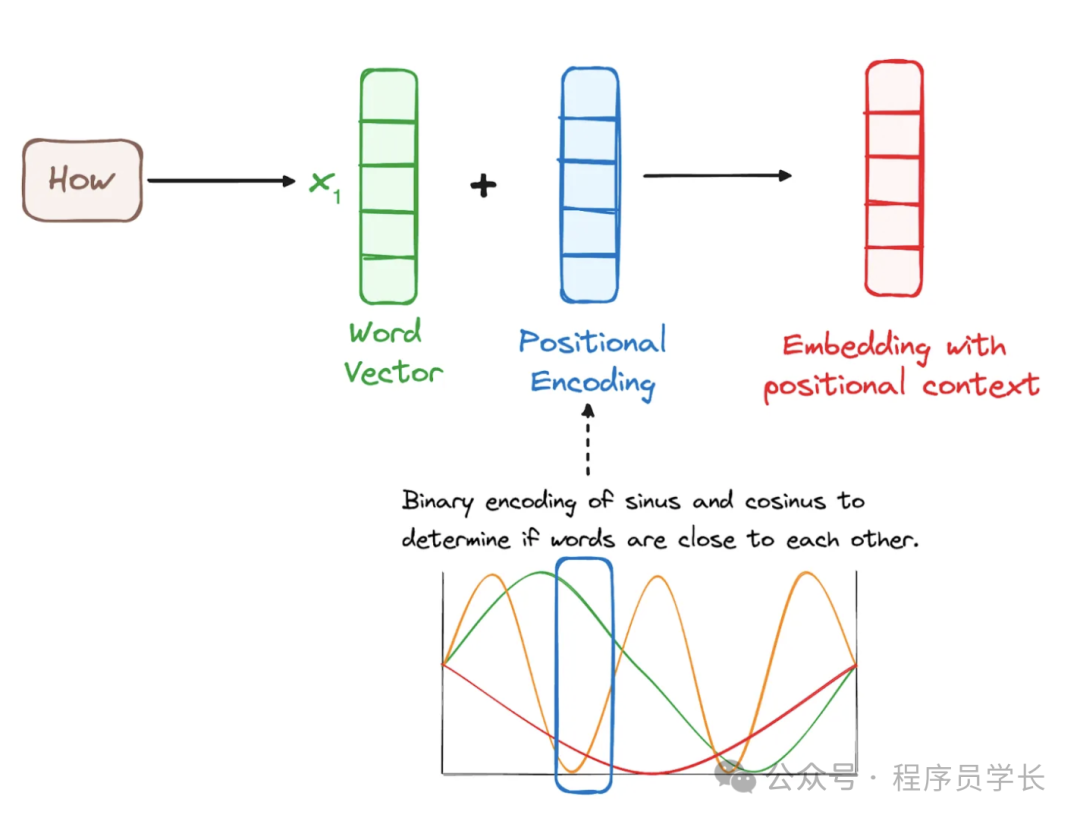
3.位置编码
Transformer 与传统的循环神经网络(RNN)不同,它在处理输入序列时不具有自然的顺序感。
为了解决这一问题,Transformer 引入了位置编码。
位置编码为每个输入符号引入一个与其位置相关的向量,并将该向量与符号的嵌入向量结合,以此传递位置信息。
位置编码的常见公式为:
其中:
-
表示符号在序列中的位置。
-
是嵌入向量的维度索引。
-
是嵌入向量的维度。
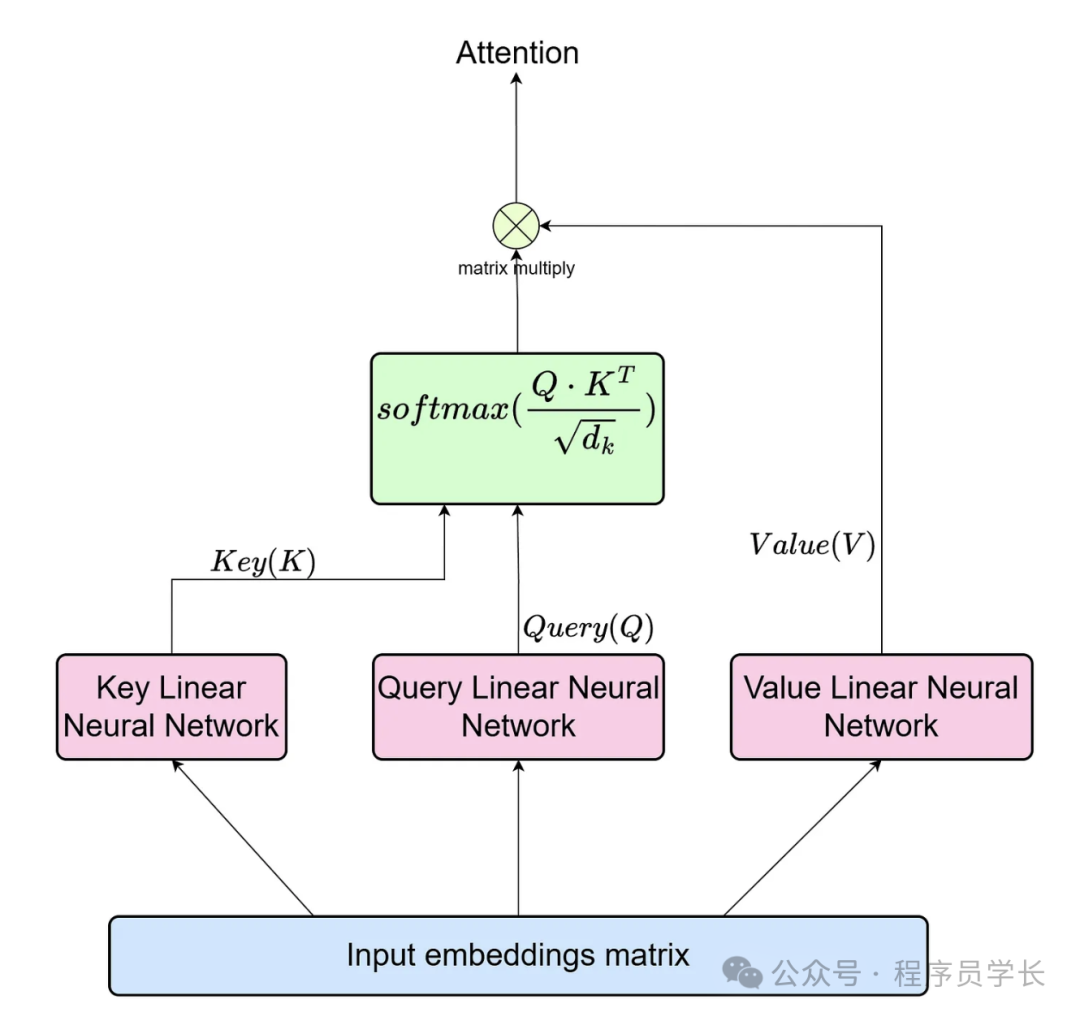
4.多头自注意力机制
多头自注意力机制是 Transformer 的核心组件之一,它通过并行计算多个不同子空间的自注意力来增强模型对序列中不同部分的关注能力。
这个机制能够让模型在不同的表示子空间中同时处理不同的注意力权重,从而捕捉更丰富的特征和关系。
自注意力机制
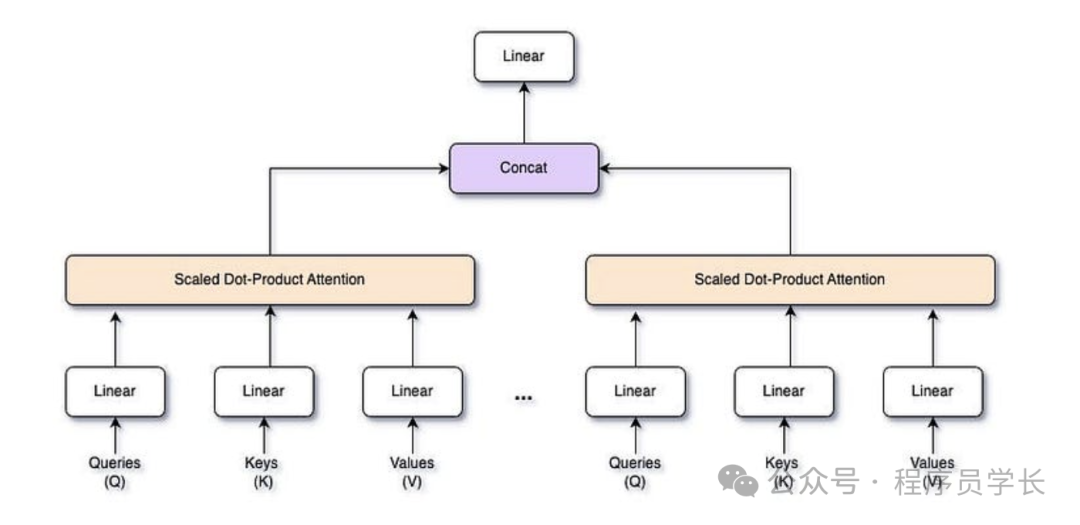
在理解多头自注意力机制之前,我们需要先理解基本的自注意力机制。
自注意力机制用来计算输入序列中每个元素与其他所有元素之间的相关性,从而在捕捉句子中长依赖和全局上下文信息方面非常强大。
它的核心思想是,对于序列中的每一个位置,计算它与其他所有位置的依赖关系,并生成一个加权的值。这可以看作是从输入序列的不同位置中选择对当前位置最相关的部分进行关注。
自注意力机制的计算过程包括以下几个步骤。
-
对于输入序列 ,每个元素会生成三个不同的向量:查询向量(Query)**,**键向量(Key) 和 值向量(Value)。
这些向量通过线性变换得到
其中 、 和 是可学习的权重矩阵。
-
接下来,计算查询向量 与键向量 的点积来得到注意力得分(Attention Scores),然后将其归一化为概率分布,再用这些分数加权值向量 V
-
通过 计算注意力得分,表示序列中不同元素之间的相关性。
-
通过缩放因子 控制数值的大小。
-
通过 softmax 函数将注意力得分归一化为概率分布。
-
通过加权求和生成每个位置的新表示。
多头注意力机制
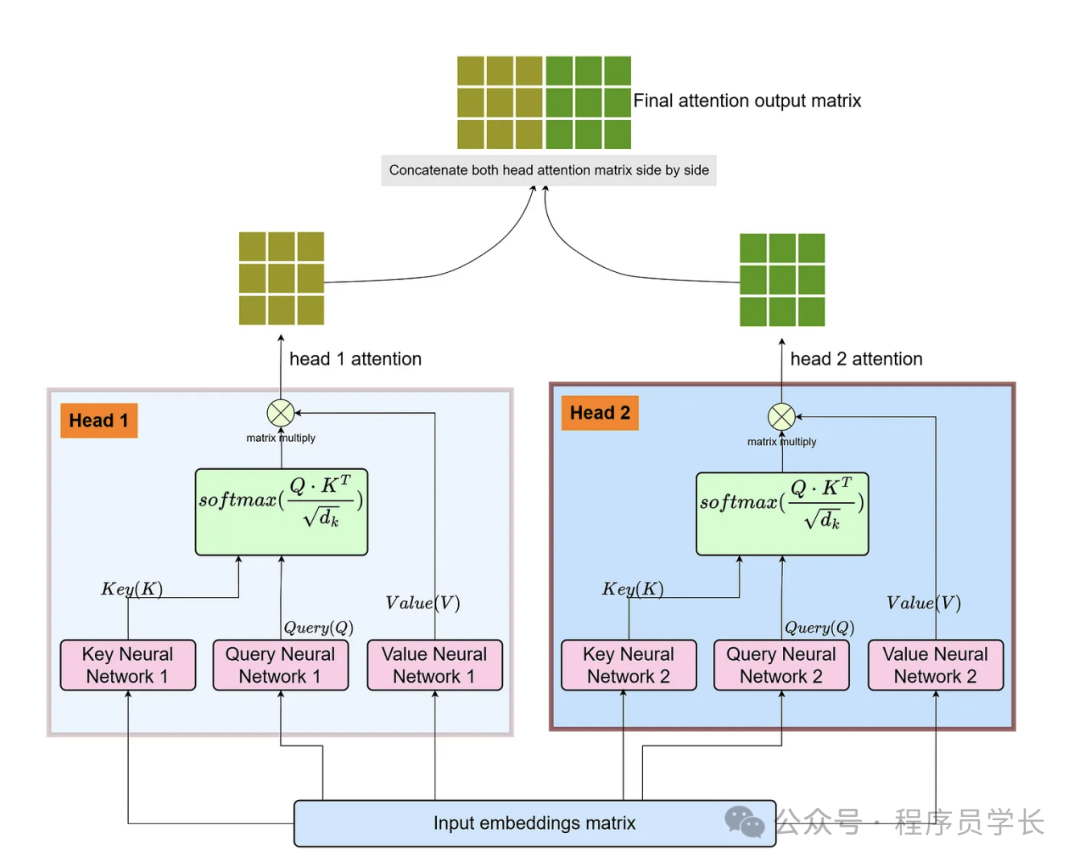
多头自注意力机制通过引入多个“头”并行计算多个自注意力,让模型在不同的表示子空间中学习到不同的特征,从而增强模型的表达能力和灵活性。
具体来说,它将自注意力机制的计算过程复制 h 次,每次使用不同的查询、键、值的线性变换。
最后,将这些头的输出拼接起来,并通过一个线性变换得到最终的输出。
其中,每个 是自注意力机制的输出, 是一个可学习的线性变换矩阵。
5.前馈神经网络
前馈神经网络是编码器层和解码器层中的一个关键组件,它负责对自注意力机制的输出进行进一步的非线性处理,增强模型的表达能力。
前馈神经网络是一个简单的两层全连接网络,结构如下
-
第一层是一个线性变换,将输入向量从 维度映射到一个更高的维度。
-
然后通过一个非线性激活函数(通常是 ReLU)。
-
第二层是另一个线性变换,将激活后的向量映射回原始维度
其公式可以表示为
其中
-
和 是线性变换的权重矩阵
-
和 是偏置向量
FFN 的作用是通过非线性映射提升模型的表达能力。
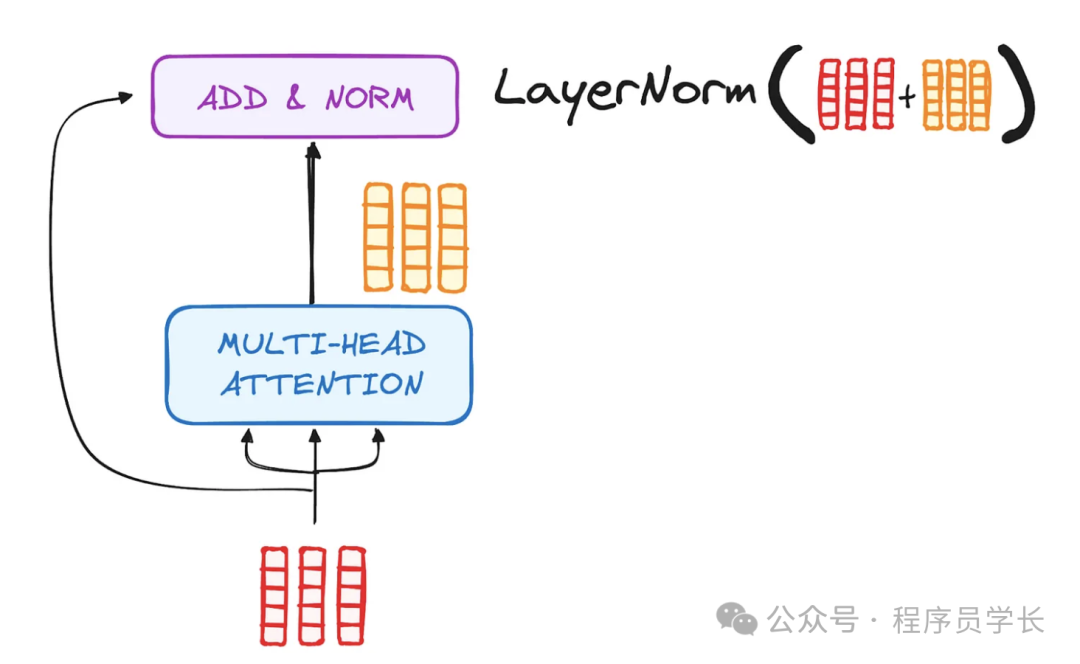
6.层归一化和残差连接
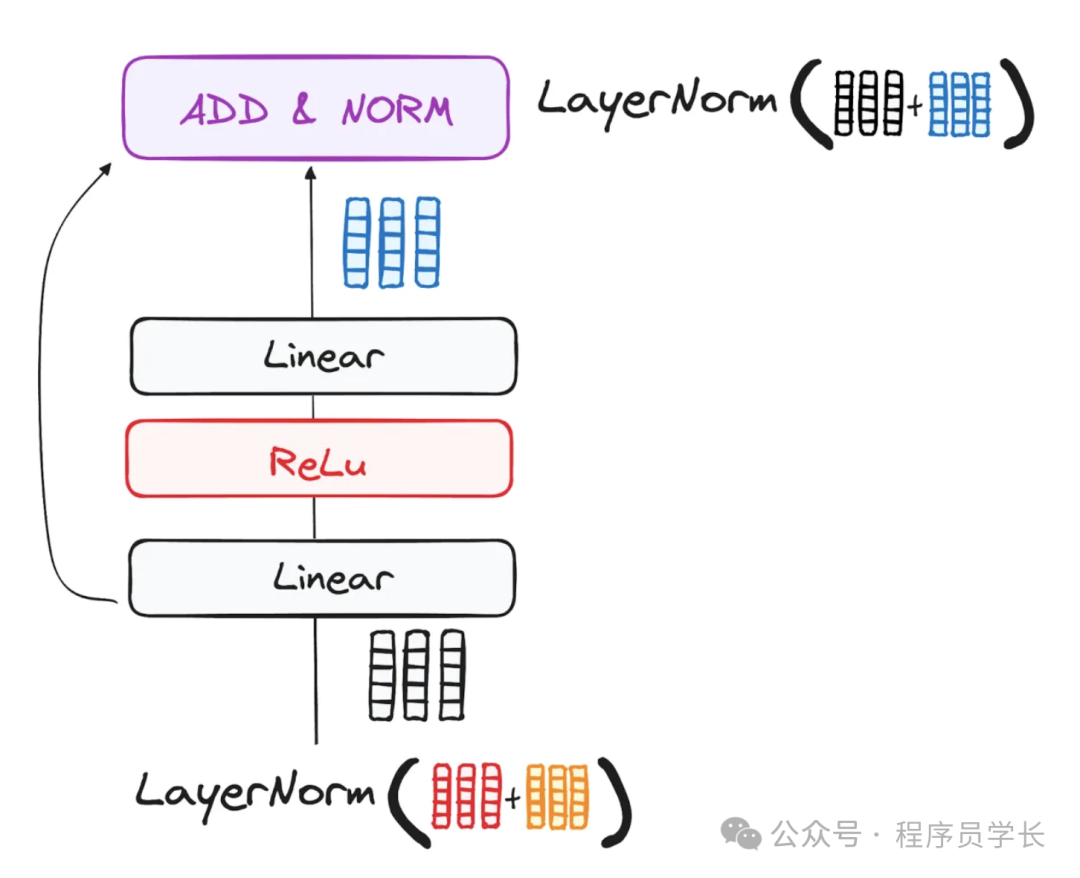
为了加速训练并解决梯度消失或爆炸的问题,Transformer 在每个子层后面引入了残差连接和层归一化。
-
残差连接
将输入直接加到子层的输出上,其公式为
-
层归一化
对每个子层的输出进行归一化处理,提升模型的稳定性
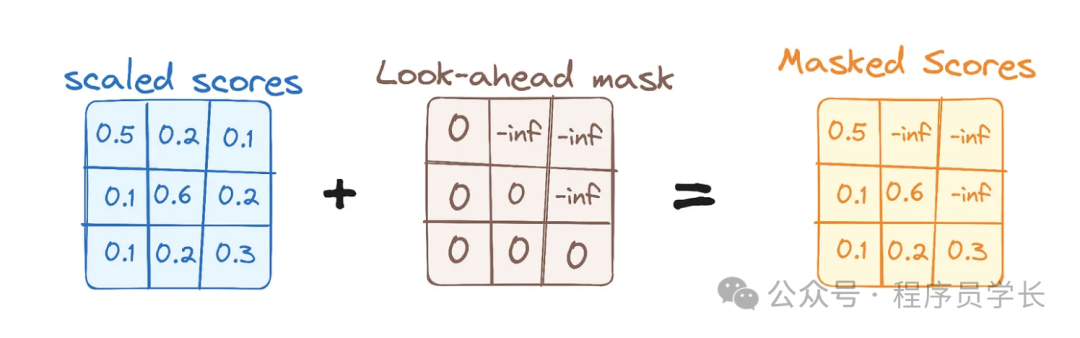
7.Masked 多头自注意力子层
Masked 多头自注意力子层是 Transformer 解码器中的一个重要部分。
在解码器中,每个时间步生成输出的词时,只能依赖之前已经生成的词,而不能访问未来的词。
为了确保这一点,Masked 多头自注意力机制通过在注意力矩阵中对未来位置进行掩码,使其权重为负无穷,从而保证模型只能关注到之前的位置。
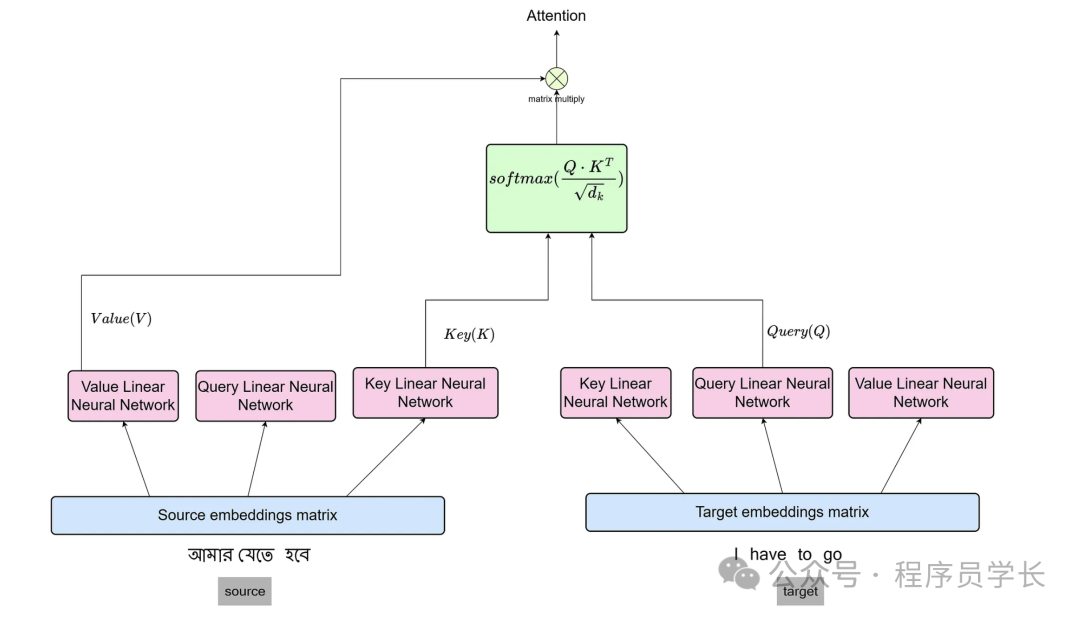
8.编码器-解码器多头注意力子层
编码器-解码器多头注意力子层在 Transformer 的解码器中起到了关键作用,它使解码器能够有效地关注输入序列,从而在生成序列时参考原始输入信息。
具体来说,编码器-解码器多头注意力的基本思想是通过对编码器输出(Key 和 Value)和解码器当前输入(Query)来生成新的表示。
如何系统的去学习大模型LLM ?
大模型时代,火爆出圈的LLM大模型让程序员们开始重新评估自己的本领。 “AI会取代那些行业?”“谁的饭碗又将不保了?”等问题热议不断。
不如成为「掌握AI工具的技术人」,毕竟AI时代,谁先尝试,谁就能占得先机!
但是LLM相关的内容很多,现在网上的老课程老教材关于LLM又太少。所以现在小白入门就只能靠自学,学习成本和门槛很高
针对所有自学遇到困难的同学们,我帮大家系统梳理大模型学习脉络,将这份 LLM大模型资料 分享出来:包括LLM大模型书籍、640套大模型行业报告、LLM大模型学习视频、LLM大模型学习路线、开源大模型学习教程等, 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓
👉[CSDN大礼包🎁:全网最全《LLM大模型入门+进阶学习资源包》免费分享(安全链接,放心点击)]()👈


欢迎加入 MCP 技术社区!与志同道合者携手前行,一同解锁 MCP 技术的无限可能!
更多推荐


 9
9 0
0- 0



 已为社区贡献64条内容
已为社区贡献64条内容

{kind=link}
所有评论(0)