逻辑回归模型的总结和理解
最近在学习吴恩达的深度学习和神经网络的课程,下面是对于逻辑回归神经网络的一些理解和总结。对于逻辑回归模型,可以理解成是有两个步骤的模型,第一步是计算x+b,第二步是计算sigmoid函数 。 构建上图最上面的单层的神经网络,其实是希望通过样本数据(,),其中m表示样本的个数,k表示输入值x的特征向量数,得到一个全局成本函数的值最小的和b。当有输入新的输入数据x时(新的输入数据x也必...
最近在学习吴恩达的深度学习和神经网络的课程,下面是对于逻辑回归神经网络的一些理解和总结。
对于逻辑回归模型,可以理解成是有两个步骤的模型,第一步是计算x+b,第二步是计算sigmoid函数
。
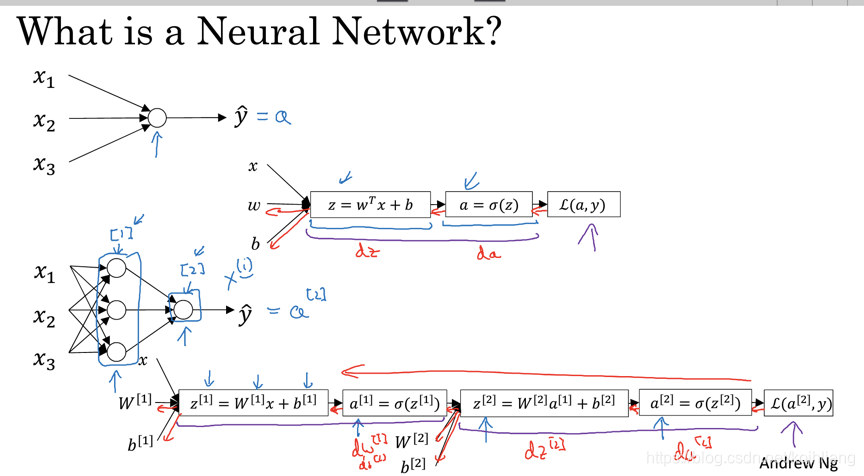
构建上图最上面的单层的神经网络,其实是希望通过样本数据(,
),其中m表示样本的个数,k表示输入值x的特征向量数,得到一个全局成本函数的值最小的
和b。当有输入新的输入数据x时(新的输入数据x也必须要包含k个特征向量)时,根据
和b,能够得到y的预测值
。总体步骤有两步:
第一步:先梯度下降法,求得相对合理的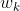 和b。假设特征向量有两个,步骤如下
和b。假设特征向量有两个,步骤如下
-
先初始化
,
..
-
然后通过反向求导,求得各个特征向量

3.然后不断迭代进行梯度下降,找出成本函数J(w,b)的相对最小值。当迭代至J(w,b)的值为最小值时,记录下当前的w和b,则该w,b即为该逻辑回归模型的最优解。

图1
每次迭代下降w和b的逻辑如下:
:=
+ a*d(
)
b:= b + a*d(b)
注意:每次迭代,都需要重新算d()和d(b),因为它会随着
和b的变化而变化
计算全局成本函数J(w,b)公式如下:
注意:为针对1个样本的损失函数,其计算公式在图1和第二步都有定义。
每次计算的值时,都会随着
的变化而变化。
第二步:根据第一步得到的和b,计算新的输入值x的预测值
第一步做完后,这个神经网络模型就算成功建立起来了。接着根据这个神经网络模型,如果再来一个新的样本数据x,那么就可以根据第一步得到的和b计算出y的预测值
的值,计算公式如下:
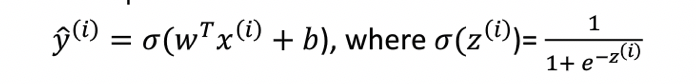
假设我们建立好的神经网络模型已经是相对最优模型,也就是损失函数会最小。损失函数的计算公式如下:
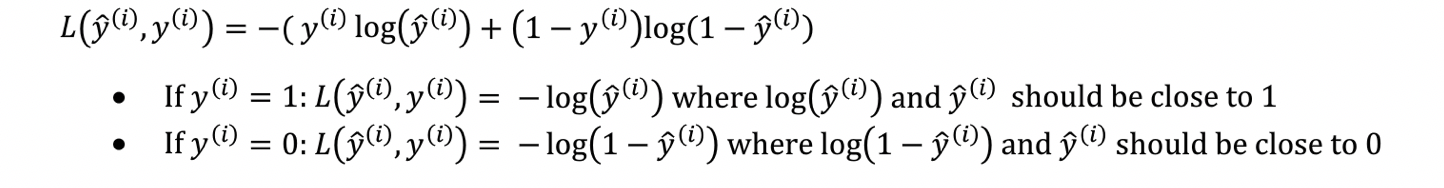
如果的值为1,则y的实际值应该也是为1,因为这样损失函数的值才为0,才是最小值。
如果的值为0,则y的实际值应该也是为0,因为这样损失函数的值才为0,才是最小值。
假设1代表某样事物为真,0为假,也就是代表了对于一个新的样本数据x,如果计算出来预测值的值越接近1,则越大概率为真;而值越接近0,则表示越大概率为假。如果值为0.5,这样就属于这个样本是比较难以区分到底是真是假。

欢迎加入 MCP 技术社区!与志同道合者携手前行,一同解锁 MCP 技术的无限可能!
更多推荐


 2
2 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)