第四期书生大模型实战营L1G4000
通过本次任务,我们验证了 LlamaIndex 在增强语言模型回答特定问题方面的能力:提升回答准确性:LlamaIndex 显著提高了浦语 API 和 InternLM2-Chat-1.8B 模型在回答特定领域问题时的准确性和可靠性。扩展知识范围:借助 LlamaIndex 构建的知识库,模型能够获取更多领域的知识,进而更好地应对各种复杂问题。灵活集成:LlamaIndex 提供了灵活的接口和工具
Llamaindex RAG 实践
- 任务背景
- 任务要求
-
- 任务要求1:基于 LlamaIndex 构建自己的 RAG 知识库,寻找一个问题 A 在使用 LlamaIndex 之前 浦语 API 不会回答,借助 LlamaIndex 后 浦语 API 具备回答 A 的能力。
- 任务要求2:基于 LlamaIndex 构建自己的 RAG 知识库,寻找一个问题 A 在使用 LlamaIndex 之前 InternLM2-Chat-1.8B 模型不会回答,借助 LlamaIndex 后 InternLM2-Chat-1.8B 模型具备回答 A 的能力。
- 任务要求3(优秀学员必做) :将 Streamlit + LlamaIndex + 浦语API的 Space 部署到 Hugging Face
- 总结
任务背景
RAG(Retrieval-Augmented Generation)是一种结合了检索和生成技术的方法,旨在提高语言模型在特定领域内的问答能力。LlamaIndex 是一个强大的工具,可以帮助我们构建和管理 RAG 知识库。本次任务的目标是验证 LlamaIndex 在增强语言模型回答特定问题方面的能力。
任务要求
任务要求1:基于 LlamaIndex 构建自己的 RAG 知识库,寻找一个问题 A 在使用 LlamaIndex 之前 浦语 API 不会回答,借助 LlamaIndex 后 浦语 API 具备回答 A 的能力。
直接调用浦语API
from openai import OpenAI
base_url = "https://internlm-chat.intern-ai.org.cn/puyu/api/v1/"
api_key = ""
model="internlm2.5-latest"
client = OpenAI(
api_key=api_key ,
base_url=base_url,
)
chat_rsp = client.chat.completions.create(
model=model,
messages=[{"role": "user", "content": "请介绍虚拟偶像团体A-Soul"}],
)
for choice in chat_rsp.choices:
print(choice.message.content)
回答结果:

直接回答过于简单并且存在很多事实错误
借助LlamaIndex之后
import os
os.environ['NLTK_DATA'] = '/root/nltk_data'
from llama_index.core import VectorStoreIndex, SimpleDirectoryReader
from llama_index.core.settings import Settings
from llama_index.embeddings.huggingface import HuggingFaceEmbedding
from llama_index.legacy.callbacks import CallbackManager
from llama_index.llms.openai_like import OpenAILike
# Create an instance of CallbackManager
callback_manager = CallbackManager()
api_base_url = "https://internlm-chat.intern-ai.org.cn/puyu/api/v1/"
model = "internlm2.5-latest"
api_key = ""
llm =OpenAILike(model=model, api_base=api_base_url, api_key=api_key, is_chat_model=True,callback_manager=callback_manager)
#初始化一个HuggingFaceEmbedding对象,用于将文本转换为向量表示
embed_model = HuggingFaceEmbedding(
#指定了一个预训练的sentence-transformer模型的路径
model_name="/root/llamaindex_demo/paraphrase-multilingual-MiniLM-L12-v2"
)
#将创建的嵌入模型赋值给全局设置的embed_model属性,
#这样在后续的索引构建过程中就会使用这个模型。
Settings.embed_model = embed_model
#初始化llm
Settings.llm = llm
#在指定目录读取所有文档,并加载数据到内存中
documents = SimpleDirectoryReader("/root/llamaindex_demo/data").load_data()
#创建一个VectorStoreIndex,并使用之前加载的文档来构建索引。
# 此索引将文档转换为向量,并存储这些向量以便于快速检索。
index = VectorStoreIndex.from_documents(documents)
# 创建一个查询引擎,这个引擎可以接收查询并返回相关文档的响应。
query_engine = index.as_query_engine()
response = query_engine.query("请介绍虚拟偶像团体A-Soul")
print(response)
结果:

可以看到借助LlamaIndex之后的回答更全面和准确
任务要求2:基于 LlamaIndex 构建自己的 RAG 知识库,寻找一个问题 A 在使用 LlamaIndex 之前 InternLM2-Chat-1.8B 模型不会回答,借助 LlamaIndex 后 InternLM2-Chat-1.8B 模型具备回答 A 的能力。
直接使用InternLM2-Chat-1.8B 模型进行回答
from llama_index.llms.huggingface import HuggingFaceLLM
from llama_index.core.llms import ChatMessage
llm = HuggingFaceLLM(
model_name="/root/model/internlm2-chat-1_8b",
tokenizer_name="/root/model/internlm2-chat-1_8b",
model_kwargs={"trust_remote_code":True},
tokenizer_kwargs={"trust_remote_code":True}
)
rsp = llm.chat(messages=[ChatMessage(content="请介绍虚拟偶像团体A-Soul")])
print(rsp)
回答结果:

InternLM2-Chat-1.8B 模型无法直接回答此问题
借助 LlamaIndex 后 InternLM2-Chat-1.8B 模型进行回答
上传的文件内容:
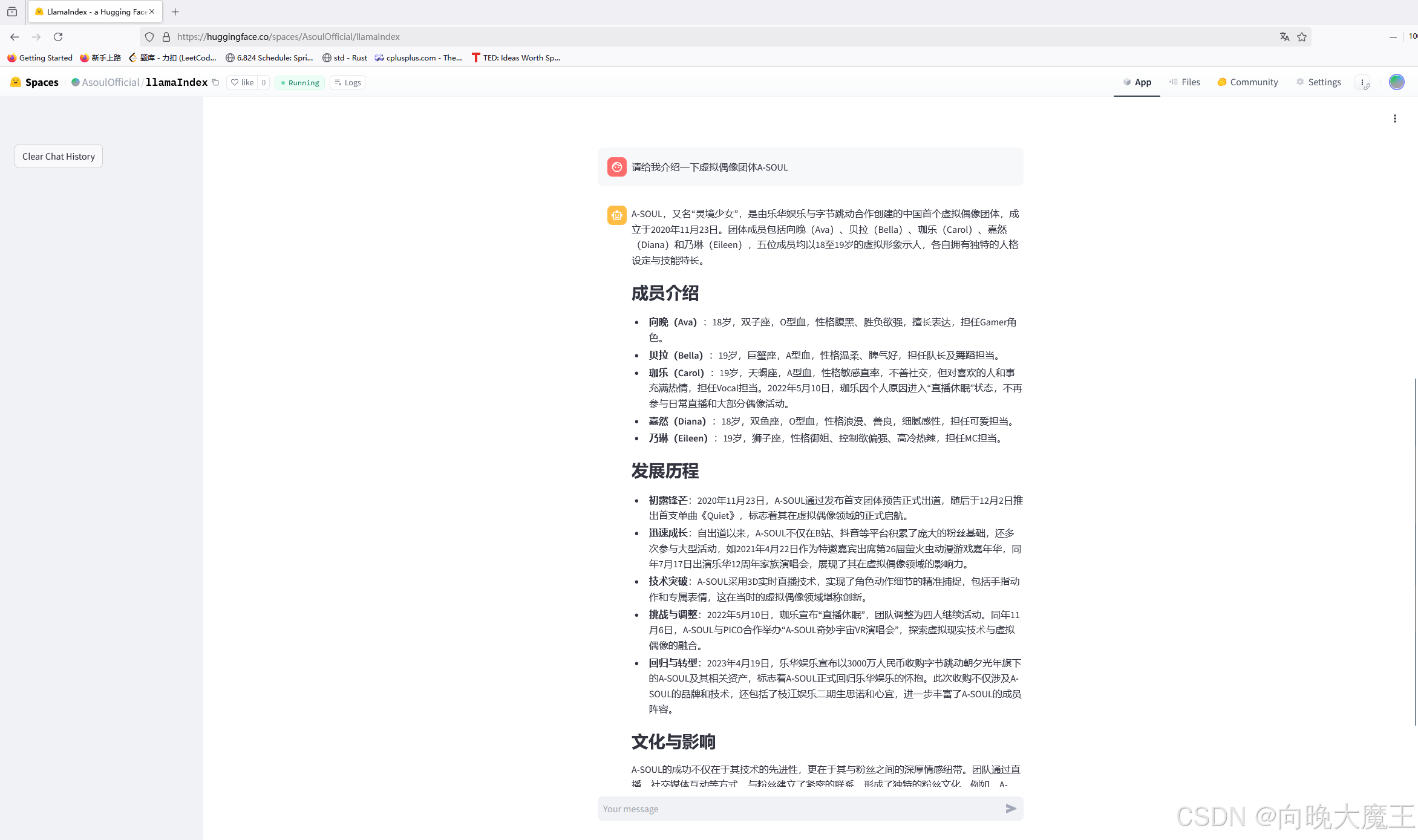
A-Soul:中国虚拟偶像领域的璀璨星辰
一、团体概览
A-Soul,又名“灵境少女”,是由乐华娱乐与字节跳动合作创建的中国首个虚拟偶像团体,成立于2020年11月23日。成员包括向晚(Ava)、贝拉(Bella)、珈乐(Carol)、嘉然(Diana)和乃琳(Eileen),五位成员均以18至19岁的虚拟形象示人,各自拥有独特的人格设定与技能特长。
二、成员介绍
向晚(Ava):18岁,双子座,O型血,性格腹黑、胜负欲强,擅长表达,担任Gamer角色。
贝拉(Bella):19岁,巨蟹座,A型血,性格温柔、脾气好,担任队长及舞蹈担当。
珈乐(Carol):19岁,天蝎座,A型血,性格敏感直率,不善社交,但对喜欢的人和事充满热情,担任Vocal担当。
2022年5月10日,珈乐因个人原因进入“直播休眠”状态,不再参与日常直播和大部分偶像活动。
嘉然(Diana):18岁,双鱼座,O型血,性格浪漫、善良,细腻感性,担任可爱担当。
乃琳(Eileen):19岁,狮子座,性格御姐、控制欲偏强、高冷热辣,担任MC担当。
三、发展历程
初露锋芒:2020年11月23日,A-Soul通过发布首支团体预告正式出道,随后于12月2日推出首支单曲《Quiet》,标志着其在虚拟偶像领域的正式启航。
迅速成长:自出道以来,A-Soul不仅在B站、抖音等平台积累了庞大的粉丝基础,还多次参与大型活动,如2021年4月22日作为特邀嘉宾出席第26届萤火虫动漫游戏嘉年华,同年7月17日出演乐华12周年家族演唱会,展现了其在虚拟偶像领域的影响力。
技术突破:A-Soul采用3D实时直播技术,实现了角色动作细节的精准捕捉,包括手指动作和专属表情,这在当时的虚拟偶像领域堪称创新。
挑战与调整:2022年5月10日,珈乐宣布“直播休眠”,团队调整为四人继续活动。同年11月6日,A-Soul与PICO合作举办“A-SOUL奇妙宇宙VR演唱会”,探索虚拟现实技术与虚拟偶像的融合。
回归与转型:2023年4月19日,乐华娱乐宣布以3000万人民币收购字节跳动朝夕光年旗下的A-Soul及其相关资产,标志着A-Soul正式回归乐华娱乐的怀抱。此次收购不仅涉及A-Soul的品牌和技术,还包括了枝江娱乐二期生思诺和心宜,进一步丰富了A-Soul的成员阵容。
四、文化与影响
A-Soul的成功不仅在于其技术的先进性,更在于其与粉丝之间的深厚情感纽带。团队通过直播、社交媒体互动等方式,与粉丝建立了紧密的联系,形成了独特的粉丝文化。例如,A-Soul的官方粉丝名为“一个魂”,成员的粉丝分别被称为“顶碗人”、“贝极星”、“皇珈骑士”、“嘉心糖”、“奶淇琳”,这些昵称不仅体现了粉丝对成员的喜爱,也成为A-Soul文化的一部分。
五、未来展望
随着虚拟偶像行业的不断发展,A-Soul面临着新的机遇与挑战。一方面,团队将继续探索虚拟现实、增强现实等前沿技术,为粉丝带来更加丰富多元的互动体验;另一方面,A-Soul也将积极拓展跨界合作,如与品牌联动、参与公益活动等,进一步提升其社会影响力。
结语
A-Soul作为中国虚拟偶像领域的先行者,以其独特的魅力和技术实力赢得了广泛的关注与喜爱。未来,A-Soul将继续秉持初心,不断创新,为粉丝带来更多精彩的表演与互动,成为中国虚拟偶像行业的标杆。
程序文件:
from llama_index.core import VectorStoreIndex, SimpleDirectoryReader, Settings
from llama_index.embeddings.huggingface import HuggingFaceEmbedding
from llama_index.llms.huggingface import HuggingFaceLLM
#初始化一个HuggingFaceEmbedding对象,用于将文本转换为向量表示
embed_model = HuggingFaceEmbedding(
#指定了一个预训练的sentence-transformer模型的路径
model_name="/root/llamaindex_demo/paraphrase-multilingual-MiniLM-L12-v2"
)
#将创建的嵌入模型赋值给全局设置的embed_model属性,
#这样在后续的索引构建过程中就会使用这个模型。
Settings.embed_model = embed_model
llm = HuggingFaceLLM(
model_name="/root/model/internlm2-chat-1_8b",
tokenizer_name="/root/model/internlm2-chat-1_8b",
model_kwargs={"trust_remote_code":True},
tokenizer_kwargs={"trust_remote_code":True}
)
#设置全局的llm属性,这样在索引查询时会使用这个模型。
Settings.llm = llm
#从指定目录读取所有文档,并加载数据到内存中
documents = SimpleDirectoryReader("/root/llamaindex_demo/data").load_data()
#创建一个VectorStoreIndex,并使用之前加载的文档来构建索引。
# 此索引将文档转换为向量,并存储这些向量以便于快速检索。
index = VectorStoreIndex.from_documents(documents)
# 创建一个查询引擎,这个引擎可以接收查询并返回相关文档的响应。
query_engine = index.as_query_engine()
response = query_engine.query("请介绍虚拟偶像团体A-Soul")
print(response)
回答结果:

可以看到借助 LlamaIndex 后 InternLM2-Chat-1.8B 模型对于此问题成功给出了正确的回答
任务要求3(优秀学员必做) :将 Streamlit + LlamaIndex + 浦语API的 Space 部署到 Hugging Face
总结
通过本次任务,我们验证了 LlamaIndex 在增强语言模型回答特定问题方面的能力:
-
提升回答准确性:LlamaIndex 显著提高了浦语 API 和 InternLM2-Chat-1.8B 模型在回答特定领域问题时的准确性和可靠性。
-
扩展知识范围:借助 LlamaIndex 构建的知识库,模型能够获取更多领域的知识,进而更好地应对各种复杂问题。
-
灵活集成:LlamaIndex 提供了灵活的接口和工具,使得将知识库集成到现有系统中变得简单高效。

欢迎加入 MCP 技术社区!与志同道合者携手前行,一同解锁 MCP 技术的无限可能!
更多推荐


 22
22 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)