CVPR 2018 VITAL:《VITAL: VIsual Tracking via Adversarial Learning》论文笔记
理解出错之处望不吝指正。 本文模型叫做VITAL。作者提到,当前使用DNN的trackers的性能受限于两方面:(1).每一帧中的positive sample在空间上高度重叠,模型不能和好的捕获较好的appearance variations;(2).positive sample和negative sample的数量及其不平衡。为了处理这两个问题,作者提出了使用对抗学习的VITAL模..
·
理解出错之处望不吝指正。
本文模型叫做VITAL。作者提到,当前使用DNN的trackers的性能受限于两方面:(1).每一帧中的positive sample在空间上高度重叠,模型不能和好的捕获较好的appearance variations;(2).positive sample和negative sample的数量及其不平衡。为了处理这两个问题,作者提出了使用对抗学习的VITAL模型。
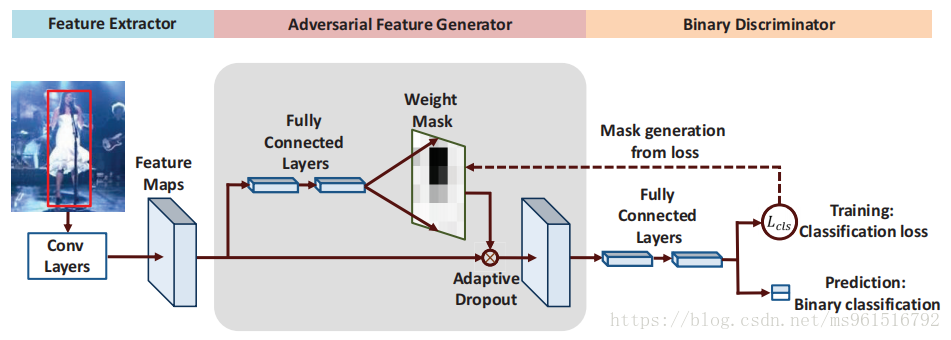
针对问题(1),作者采用GAN来生成mask,这些mask作用在特征图上,表示目标的一种外观变化。在对抗学习的作用下,可以学习出在整个时序中哪一种mask保留了目标物体的最鲁棒性特征。最终,我们可以使用学到的mask对判别力强的特征进行削弱,防止模型对该样本过拟合;
针对问题(2),作者提出了使用高阶敏感损失来挖掘困难负样本,降低简单负样本的影响。这不仅提高了准确率,而且还加快了模型的收敛速度。
正常的损失函数应该是下式这样:
![]()
作者将其改为:
![]()

欢迎加入 MCP 技术社区!与志同道合者携手前行,一同解锁 MCP 技术的无限可能!
更多推荐


 1
1 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)