深入浅出极大似然估计
最大似然估计是利用已知的样本的结果,在使用某个模型的基础上,反推最有可能导致这样结果的模型参数值。在理解极大似然估计之前我们首先要了解概率和似然,概率是事件未发生前预测事件发生的概率,当事件发生时这个概率就已经确定,不在改变,而似然是事实已经发生去推测发生的条件,当事件与条件一一对应时似然值大小等于概率值大小,即 L(&|x) = P(x|&)。举例说明:假设一个袋子装有白球与红球
最大似然估计是利用已知的样本的结果,在使用某个模型的基础上,反推最有可能导致这样结果的模型参数值。在理解极大似然估计之前我们首先要了解概率和似然,概率是事件未发生前预测事件发生的概率,当事件发生时这个概率就已经确定,不在改变,而似然是事实已经发生去推测发生的条件,当事件与条件一一对应时似然值大小等于概率值大小,即 L(&|x) = P(x|&)。
举例说明:假设一个袋子装有白球与红球,比例未知,现在抽取10次(每次抽完都放回,保证事件独立性),假设抽到了7次白球和3次红球,在此数据样本条件下,可以采用最大似然估计法求解袋子中白球的比例(最大似然估计是一种“模型已定,参数未知”的方法)。当然,这种数据情况下很明显,白球的比例是70%,但如何通过理论的方法得到这个答案呢?一些复杂的条件下,是很难通过直观的方式获得答案的,这时候理论分析就尤为重要了,这也是学者们为何要提出最大似然估计的原因。我们可以定义从袋子中抽取白球和红球的概率如下:
![]()
其中x1和x2为采样次数,f为映射函数,theta是未知参数,也就是我们要求的值,我们定义似然L为:
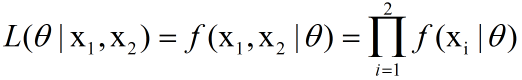
两边取ln,取ln是为了将右边的乘号变为加号,方便求导。
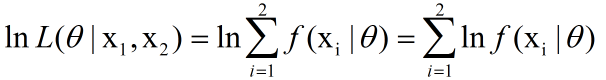
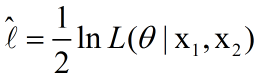
这是平均对数似然,因为是两次取样,所以乘上1/2,

这里讨论的是2次采样的情况,当然也可以拓展到多次采样的情况:
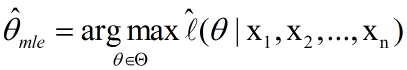
我们定义M为模型(也就是之前公式中的f),表示抽到白球的概率为theta,而抽到红球的概率为(1-theta),因此10次抽取抽到白球7次的概率可以表示为:
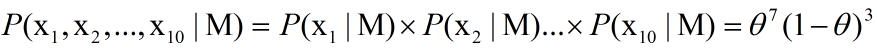
将其描述为平均似然可得:
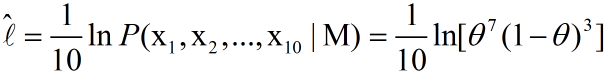
那么最大似然就是找到一个合适的theta,获得最大的平均似然。因此我们可以对平均似然的公式对theta求导,并另导数为0。
![]()
由此可得,当抽取白球的概率为0.7时,最可能产生10次抽取抽到白球7次的事件。
以上就是整个最大似然估计整个过程。

欢迎加入 MCP 技术社区!与志同道合者携手前行,一同解锁 MCP 技术的无限可能!
更多推荐


 1
1 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)