大语言模型系统:【CMU 11-868】课程学习笔记03——GPU编程基础2(GPU Programming Basics 2)
大语言模型系统:【CMU 11-868】课程学习笔记03——GPU编程基础2(GPU Programming Basics 2)
前言
【CMU 11-868】课程面向研究生开设,聚焦“从算法到工程”的大语言模型系统构建全过程。课程内容包括但不限于:
- GPU 编程与自动微分:掌握 CUDA kernel 调用、并行编程基础,以及深度学习框架设计原理
- 模型训练与分布式系统:学习高效的训练算法、通信优化(ZeRO、FlashAttention)、分布式训练框架(DDP、GPipe、Megatron-LM)。
- 模型压缩与加速:量化(GPTQ)、稀疏化(MoE)、编译技术(JAX、Triton)、以及推理时的服务化设计(vLLM、CacheGen)。
- 前沿技术与系统实践:涵盖检索增强生成(RAG)、多模态 LLM、RLHF 系统,以及端到端的在线维护和监控。
一、基本的GPU CUDA操作(Basic GPU CUDA operations)
1️⃣ CUDA内核(CUDA Kernel)
- 每个核函数都是一个在GPU上运行的函数(程序);
- 程序本身是串行的;
- 可以同时运行多个(10k)线程;
- 使用线程索引计算数据的右侧部分;
2️⃣ 运行CUDA内核(Running GPU kernel)
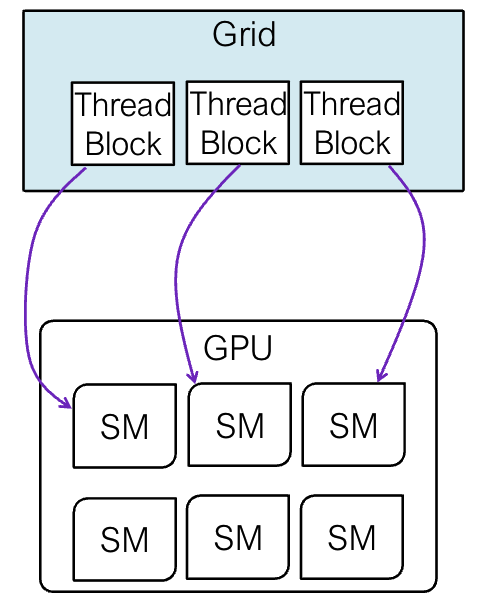
- CPU调用内核网格(CPU invokes kernel grid);
- 网格中的线程块分配给流多处理器(Thread blocks in grid distributed to SMs);
- 并发执行(Execute concurrently)
- 每个SM运行多个线程块(Each SM runs multiple thread blocks);
- 每个核心运行来自一个线程块的一个线程(Each core runs one thread from one thread block);
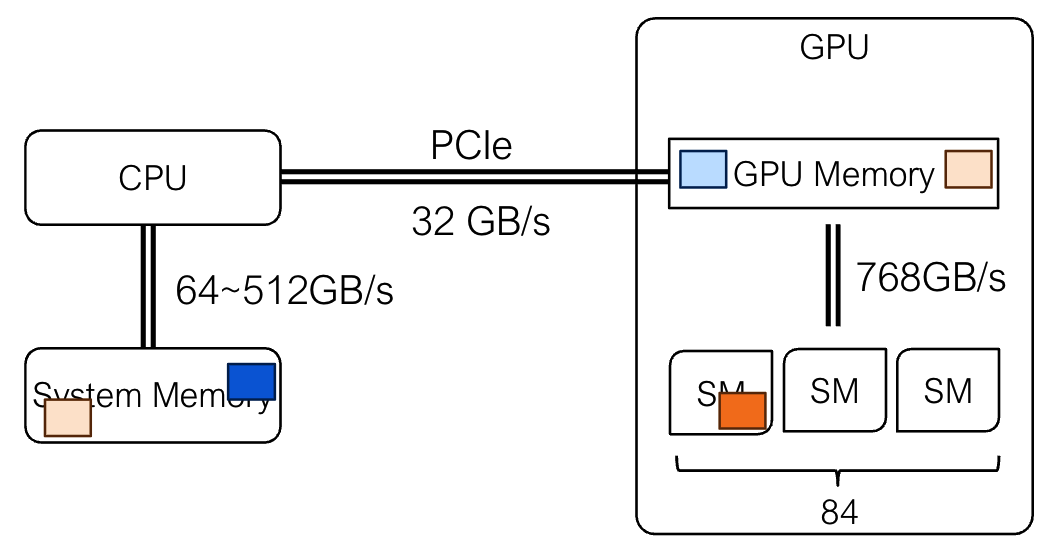
3️⃣ CPU-GPU数据移动(CPU-GPU Data Movement)
4️⃣ CUDA操作(CUDA Operations)
- CPU 分配 GPU 内存:
cudaMalloc;- CPU将数据复制到GPU内存(主机到设备):
cudaMemcpy;- CPU 启动 GPU 核函数;
- CPU从GPU复制结果(设备到主机):
cudaMemcpy;- 释放GPU内存
cudaFree。
1.1 内存管理(memory management)
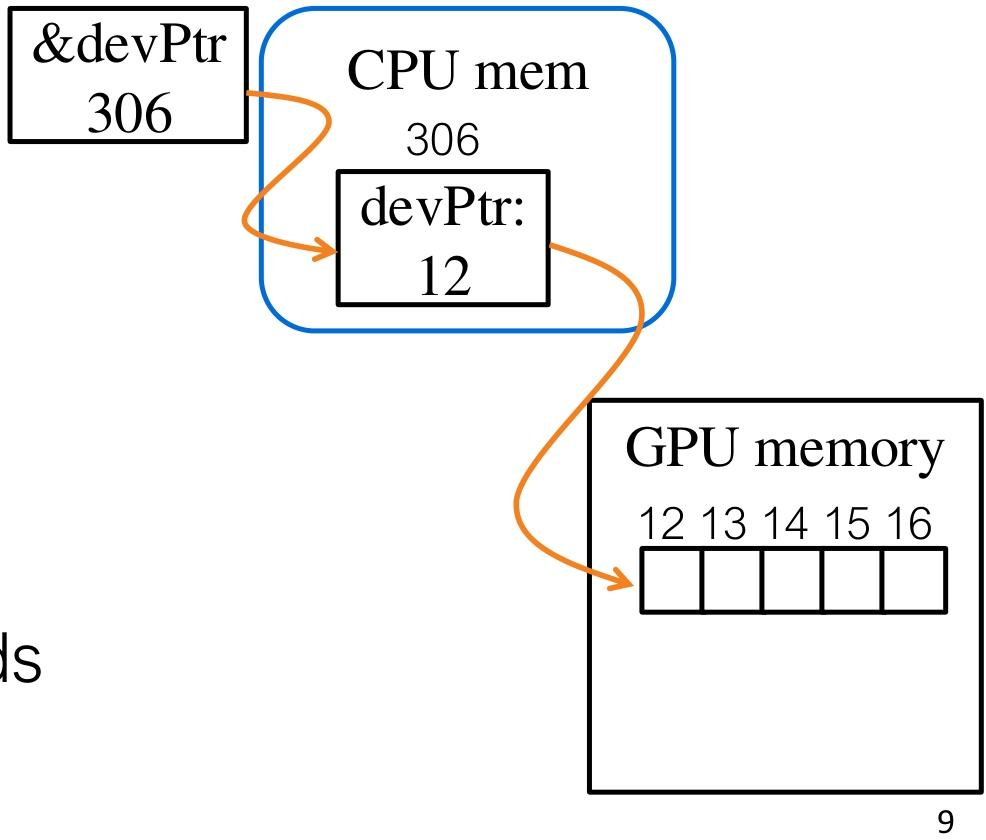
1️⃣ 分配GPU内存(Allocate GPU Memory)
分配的内存可以被所有线程访问(The allocated mem is accessible by all threads)。
cudaError_t cudaMalloc(void** devPtr, size_t size)
参数:
devPtr:指向已分配的设备内存的指针(Pointer to allocated device memory)size:以字节为单位的请求分配大小(Requested allocation size in bytes)
示例如下:
int *dA;
cudaMalloc(&dA, n * sizeof(int));
float *dB;
cudaMalloc(&dB, n * sizeof(float));
2️⃣ 释放GPU内存(Free GPU memory)
需要手动释放内存占用。
cudaError_t cudaFree(void *devPtr);
Parameters:
devPtr: 指向你想要释放的内存的设备指针(A device pointer to the memory you want to free).
3️⃣ 数据移动(Data Movement)
从设备复制数据:CPU到GPU,GPU到CPU。
cudaError_t cudaMemcpy(void* dst, const void* src, size_t count, cudaMemcpyKind kind)
参数:
dst:目标内存地址(Destination memory address)src:源内存地址(Source memory address)count:要复制的字节大小(Size in bytes to copy)kind:传输类型(Type of transfer),cudaMemcpyHostToDevice 或 cudaMemcpyDeviceToHost
示例如下:
cudaMemcpy(dGPU, hCpu, n * sizeof(int), cudaMemcpyHostToDevice);
1.2 创建线程(creating threads)
1️⃣ 主机/设备函数的声明(Declaration of Host/Device function)
主机和设备代码位于同一个.cu文件中,主机/设备函数的声明指明代码将在何处运行。
| 关键字(Keyword) | 调用位置(Call On) | 执行位置(Execute On) |
|---|---|---|
| __global__ | host (cpu) | device (gpu) |
| __device__ | device (gpu) | device (gpu) |
| __host__ | host | host |
2️⃣ 定义要在GPU上执行的函数(Defining Functions to be executed on GPU)
定义内核函数__global__。
// 向量加法内核(Example 1: Vector Addition Kernel)
__global__ void VecAddKernel(int* A, int* B, int* C, int n) {
// 计算线程全局索引(Calculate global thread index)
int i = blockDim.x * blockIdx.x + threadIdx.x;
if (i < n) { // 避免索引越界(Avoid index out of bounds)
C[i] = A[i] + B[i];
}
}
int main() {
VecAddKernel<<<1, N>>>(A, B, C, N);
}
3️⃣ 运行时调用内核(Calling Kernel at Runtime)
主机程序在运行时为内核指定网格-块-线程配置。Dg 和 Db 要么是 dim3 类型,要么是 int 类型。
Dg: 网格大小(线程块数量)(size of grid (num. of blocks)),Dg.x * Dg.y * Dg.z是块的数量。Db:块大小(size of block),Db.x * Db.y * Db.z是每个块的线程数(<=1024)。
dim3 Dg(4, 2, 1);
dim3 Db(8, 8, 1);
kernelFuncName<<<Dg, Db>>>(args)
4️⃣ 设备运行时变量(Device Runtime Variables)
- 主机在GPU设备上启动内核;
- 每个内核线程都需要知道自己正在运行的是哪个线程;
- 编译器会生成内置变量,这些变量包含x、y、z字段;

5️⃣ 从CPU调用CUDA内核(Calling CUDA Kernel from CPU)
// n: the size of the vector
int n = 1024;
int threads_per_block = 256;
int num_blocks = (n + threads_per_block - 1) / threads_per_block;
VecAddKernel<<<num_blocks, threads_per_block>>>(dA, dB, dC, n);
二、GPU上的矩阵/张量计算(Matrix/Tensor Computation on GPU)
1️⃣ 使用CUDA进行矩阵乘法(Matrix Multiplication with CUDA)
示例参考:
__global__ void MatAddKernel(float* A, float* B, float* C, int N) {
int i = blockIdx.x * blockDim.x + threadIdx.x;
int j = blockIdx.y * blockDim.y + threadIdx.y;
C[i * N + j] = A[i * N + j] + B[i * N + j];
}
int main() {
int N = 32;
dim3 threads_per_block(N, N);
int num_blocks = 1;
MatAddKernel<<<num_blocks, threads_per_block>>>(dA, dB, dC, N);
}
__global__ void fullKernel(float* din, float* dout) {
int block_id = blockIdx.x + blockIdx.y * gridDim.x + blockIdx.z * gridDim.x * gridDim.y; int block_offset = block_id * blockDim.x * blockDim.y * blockDim.z;
int thread_offset = threadIdx.x + threadIdx.y * blockDim.x
int tid = block_offset + thread_offset; + threadIdx.z * blockDim.x * blockDim.y;
dout[tid] = func(din[tid]);
}
int main() {
dim3 threads_per_block(2, 4, 8);
dim3 blocks_per_grid(2, 3, 4);
fullKernel<<<blocks_per_grid, threads_per_block>>>(some_input, some_output);
}
2️⃣ 向量加法(Vector Addition)
void VecAddCUDA(int* Acpu, int* Bcpu, int* Ccpu, int n) {
int *dA, *dB, *dC;
cudaMalloc(&dA, n * sizeof(int));
cudaMalloc(&dB, n * sizeof(int));
cudaMalloc(&dC, n * sizeof(int));
cudaMemcpy(dA, Acpu, n * sizeof(int), cudaMemcpyHostToDevice);
cudaMemcpy(dB, Bcpu, n * sizeof(int), cudaMemcpyHostToDevice);
int threads_per_block = 256;
VecAddKernel<<<num_blocks, threads_per_block>>>(dA, dB, dC, n);
int num_blocks = (n + threads_per_block - 1) / threads_per_block;
cudaMemcpy(Ccpu, dC, n * sizeof(int), cudaMemcpyDeviceToHost);
cudaFree(dA);
cudaFree(dB);
cudaFree(dC);
}
3️⃣ 矩阵加法(Matrix Addition)
void MatAddCUDA(int* Acpu, int* Bcpu, int* Ccpu, int n) {
int *dA, *dB, *dC;
cudaMalloc(&dA, n * n * sizeof(int));
cudaMalloc(&dB, n * n * sizeof(int));
cudaMalloc(&dC, n * n * sizeof(int));
cudaMemcpy(dA, Acpu, n * n * sizeof(int), cudaMemcpyHostToDevice);
cudaMemcpy(dB, Bcpu, n * n * sizeof(int), cudaMemcpyHostToDevice);
int THREADS = 32;
int BLOCKS = (n + THREADS - 1) / THREADS;
dim3 threads(THREADS, THREADS); // should be <= 1024
dim3 blocks(BLOCKS, BLOCKS);
MatAddKernel<<<blocks, threads>>>(dA, dB, dC, n);
cudaFree(dA);
cudaMemcpy(Ccpu, dC, n * n * sizeof(int), cudaMemcpyDeviceToHost);
cudaFree(dB);
cudaFree(dC);
}

欢迎加入 MCP 技术社区!与志同道合者携手前行,一同解锁 MCP 技术的无限可能!
更多推荐
 5
5 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)