IvorySQL HTAP 实时湖仓接入引擎
本文章整理于 HOW 2026 中陶郑(IvorySQL 核心贡献者)演讲内容。
一、数据架构的演进历程
1.1 传统数据架构的局限
业务数据从产生到被分析使用,中间需要经过多个系统的流转。当前行业主要存在两种架构模式:
- 线性架构:业务数据产生后进入事务数据库,经过 ETL 数据迁徙进入数据湖,再经处理进入数据仓库,最终由 AI 调用数据仓库接口进行分析。这一链路冗长,数据处理环节众多。
- 变形架构:数据同时写入事务数据库和分析型数据库(即数据库与数据仓库并存),但本质上仍是多个数据库系统,AI 查询仍需跨系统访问。
这两类架构共同面临的困境是:数据处理流程复杂导致分钟级甚至小时级的延迟,且多次查询间原始数据可能已经发生变化,造成数据割裂。与此同时,多套系统的运维成本也居高不下。
1.2 架构演进的三代路径
- 第一代(2000年代——数据仓库) :随着数据量增长,企业开始按业务需求设计数据结构并存入数据仓库。但后期业务扩展时,新增数据分析需求往往面临数据仓库改造的高昂成本。
- 第二代(2010年代——数据湖) :为降低成本,企业开始将全量增量数据保存至廉价的数据湖中,仅在需要时提取至数据仓库。这虽降低了存储成本,却使分析链路更加复杂,维护难度加大。
- 第三代(2020年前后——湖仓一体) :融合数据仓库与数据湖的优势,但本质上仍是两个系统的组合。
1.3 HTAP 原生化:下一代架构
当前最新趋势是从“湖仓一体”向“HTAP 原生化”演进——让事务数据与分析数据存储在同一数据库中,彻底消除数据迁徙与 ETL 环节。
两代架构的核心差异:
| 维度 | 湖仓一体 | HTAP 原生化 |
|---|---|---|
| 存储底座 | 对象存储 | 统一高性能存储引擎 |
| 数据新鲜度 | 分钟级/小时级 | 秒级/毫秒级 |
| 核心能力 | 数据湖增加数仓功能 | 数据库具备数仓体量 |
这意味着多个数据库整合为一个,AI 可通过单一 API 调用,无需跨库查询,运维成本显著降低,数据实时性大幅提升。
这一演进逻辑在知识管理领域同样成立:传统的“笔记(事务)+ 大脑思考(分析)”分离模式,正向着“AI 统一管理所有笔记、查询与自动更新”的方向演进——这正是人类大脑“记忆与思考同一器官”的工作方式。
二、AI 时代传统架构的三大痛点
AI Agent 的普及对数据基础设施提出了全新要求,传统架构在三个维度上面临根本性挑战:
- 痛点一:查询模式不可预测
传统架构按预定查询脚本和数据模型设计,但 Agent 生成的查询是随机的——用户用自然语言描述需求,Agent 可能生成点查也可能生成聚合分析。传统架构无法同时高效应对这两种查询模式。 - 痛点二:数据新鲜度敏感
ETL 延迟意味着 Agent 查询事务数据和分析数据时,数据可能已经发生变化。在风控、推荐、金融等对实时性要求极高的场景中,这一延迟不可接受。 - 痛点三:跨系统延迟叠加
AI 任务的执行本质上是线性的。当单次任务需要同时涉及点查和聚合分析时,跨两套系统的延迟相互叠加,数据准确性与响应速度双双受损。
三、HTAP 原生架构:行业动向与 IvorySQL 的定位
3.1 行业风向标:Databricks 的两笔关键并购
过去一年中,数据库领域龙头企业 Databricks 完成了两笔具有标志性意义的收购:
- 2025年5月——收购 Neon:Neon 是无服务器 PostgreSQL 服务提供商。这一收购意味着 OLAP 巨头主动进入 OLTP 领域,事务与分析的边界开始被打破。
- 2025年10月——收购 Mooncake Labs:Mooncake Labs 的核心项目是 pg_mooncake——在 PostgreSQL 内嵌入 DuckDB 列存引擎,使同一份数据同时支持事务查询与分析查询,彻底无需 ETL。
这两笔收购释放了明确信号:HTAP 原生化方向已有顶级资本认可,且有商业化产品在实质推进。IvorySQL 的方案正是基于 pg_mooncake 构建。
3.2 pg_mooncake 留下的两个空白
- 空白一:开源生态的维护缺口
pg_mooncake 被收购后,更新频率明显放缓(自2025年10月起至今未再更新)。后续迭代必然优先服务于 Databricks 自身的商业产品路线图。开源社区需要一个独立维护的实现,迭代方向由社区共同决定,不被单一公司绑定。 - 空白二:Oracle 迁移场景的能力缺口
pg_mooncake 基于 PostgreSQL 生态构建,从未考虑过 Oracle 兼容场景。然而,中国大量企业的核心数据仍运行在 Oracle 上,迁移过程中同样面临 HTAP 需求——目前这一领域尚无现成答案。
3.3 IvorySQL 的定位与填补
IvorySQL 是一个开源的 PostgreSQL 分支,由社区独立维护,完整兼容 PostgreSQL 生态,同时支持 Oracle 语法、数据类型和函数行为。
基于这一基础,IvorySQL 的 HTAP 引擎做到:
- 填补空白一:社区独立维护的 pg_mooncake 持续演进版本,迭代方向不受商业公司绑定
- 填补空白二:全面支持 Oracle 迁移场景的 HTAP 能力,覆盖 Oracle 数据类型、语法及函数兼容
- 实时湖仓接入引擎:在上述基础上,同一份数据同时支持事务与分析两条路径,实时可查
四、技术路径与架构原理
4.1 行存与列存:理解 HTAP 的技术基础
PostgreSQL 是行存数据库,数据按整行连续存储(如同一张 Excel 表中一行完整记录)。行存适合事务型操作,写入速度快,事务支持完善,但在大数据量分析查询时性能会遇到瓶颈。
列存则按列独立排列(如所有金额值集中存储),查询时可直接提取目标列,无需整行扫描。列存在大数据量聚合分析场景下性能优势显著。
HTAP 的核心思路是:在同一数据库中同时拥有行存与列存两种存储形态,根据查询特征自动选择最优执行路径。
4.2 整体架构
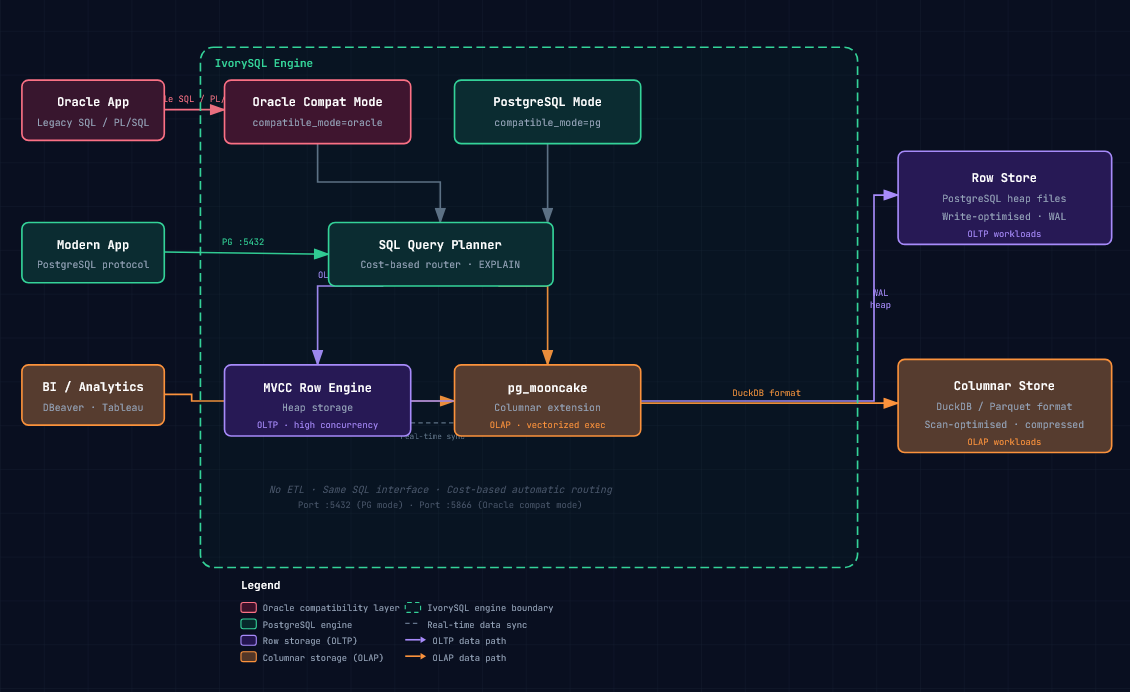
IvorySQL HTAP 引擎基于 pg_mooncake 构建,核心机制如下:
智能路由:通过 Hooks 方式嵌入 PostgreSQL 内核(不侵入内核代码),Planner(计划器)自动识别查询特征,判断走行存(点查/事务)还是列存(聚合/分析)效率更高,自动路由至最优执行路径。
双存储引擎:
- 行存:PG Heap 文件,服务于 OLTP 事务场景
- 列存:DuckDB 引擎 + Parquet 列存格式,服务于 OLAP 分析场景
内存共享与自动同步:在内存中,同一份数据既可通过 PG 行存访问,也可转化为列存供 DuckDB 查询。持久化层面,数据通过 Parquet 等列存格式保存,行存与列存之间自动实时同步,应用层完全无感知。
4.3 为什么不需要 ETL
传统方案中,数据库 → ETL → 数仓,延迟达分钟级甚至小时级,AI Agent 拿到的是过时数据。
HTAP 原生方案中,数据始终只有一份,存储在 PostgreSQL 中。行存和列存是同一份数据的两种访问路径——ETL 消失了,延迟也消失了,AI Agent 拿到的是最新数据。
4.4 写入路径与查询路由
- 应用层 SQL:标准 SQL 语句发出,无需任何改造,应用完全不感知底层路由决策
- PostgreSQL 查询层:Parser(解析器)→ Planner(规划器)→ Executor(执行器),pg_mooncake 以 Hook 方式嵌入,不侵入 PG 内核
- 自动路由:Planner 识别查询特征,自动决定行存(点查/事务)或列存(聚合/分析)
- 双存储引擎执行:行存走 PG Heap(OLTP),列存走 DuckDB + Parquet(OLAP)
- 自动同步:两种存储之间自动同步,数据始终只有一份
五、应用场景
场景一:Oracle 数仓迁移
迁移前痛点:企业将 Oracle 数仓迁移到开源数据库后,原有的分析链路需全部重建——OLAP 系统重新搭建、ETL 脚本重新编写、业务停摆等待,成本倍增。
迁移到 IvorySQL 后:Oracle 类型、语法、数据类型、函数行为全面兼容,迁移脚本无需修改。HTAP 能力随迁移一并到位,分析链路不需要重建,迁移完成即可用,无需额外部署任何组件。
场景二:AI Agent 混合查询
当前困境:Agent 完成一个任务需要同时查询事务数据和分析数据——先查 MySQL 拿最新订单,再查分析数据库做趋势分析。两个系统、两次延迟,且数据新鲜度不一致。
统一到 IvorySQL 后:点查走行存,聚合走列存,一个连接搞定所有查询。数据实时一致,Agent 响应速度与决策质量同步提升。
场景三:实时风控
当前困境:交易发生后,数据经过 ETL 进入风控分析系统,最快也是分钟级延迟。对于高风险交易,风控判断往往在交易完成后才到达,形同虚设。
接入 IvorySQL 后:交易写入 IvorySQL 的同时,列存即可查询。风控规则实时触发,从分钟级降到秒级以内。对风控、推荐、金融等延迟敏感场景,效果尤为显著。
六、开源发布计划
- 发布时间:计划伴随 IvorySQL 6.0 版本正式发布
- 开源内容:代码完全开源,包含三个核心模块——ivy_mooncake、ivy_duckdb、ivy_moonlink
- 获取方式:可通过 IvorySQL 官网获取相关资源与文档
注:现在已经发布了预览版 1.0 beta1
七、总结
IvorySQL HTAP 实时湖仓接入引擎,是 IvorySQL 社区在数据库架构演进方向上的重要布局。项目紧跟 Databricks 等行业巨头验证的技术方向,基于 pg_mooncake 构建,同时填补了开源独立维护与 Oracle 迁移场景两大空白。通过行存与列存的融合、智能路由与自动同步机制,实现了事务与分析在同一数据库中的实时统一,为 AI Agent 时代的数据查询、实时风控、Oracle 迁移等场景提供了切实可行的解决方案。
随着 6.0 版本的开源发布,IvorySQL 社区将为企业用户提供一套真正开放、可独立演进、兼容 Oracle 生态的 HTAP 基础设施。

欢迎加入 MCP 技术社区!与志同道合者携手前行,一同解锁 MCP 技术的无限可能!
更多推荐
 3
3 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)