把 Codex 用到极致 !OpenAI 官方最佳实践完整解读
OpenAI官方Codex实战指南:六大支柱与工程落地最佳实践
很多开发者在使用 OpenAI Codex 时,仅仅把它当成一个“高级版 Copilot”来自动补全代码。
这种低频、单向的使用方式,实际上浪费了 Codex 强大的上下文理解与工程协同能力。
近期 OpenAI 官方发布了 Codex 最佳实践指南,彻底颠覆了传统的 AI 辅助编程模式。
本文将深度拆解官方文档,结合实际工程场景,为你提供一套可落地、可配置、可提效的 Codex 实战教程。
一、 核心架构:Codex 协同的“六大支柱”
要把 Codex 的效能发挥到极致,必须改变“单次对话”的临时思维。
官方的核心思路是:把 Codex 当作一个拥有持久记忆、熟悉你项目规范的虚拟队友。
这一协同体系由以下“六大支柱”支撑:
- 正确的任务上下文:确保输入的信息精准且无噪,避免 AI 产生幻觉。
- AGENTS.md 持久指引:将团队规范与项目约定固化为本地文档,实现无感加载。
- 统一的行为配置文件:通过本地或全局配置规范 Codex 的决策逻辑与运行环境。
- MCP(Model Context Protocol)外部连接:打破沙箱限制,连接数据库、API 和外部工具。
- 封装可复用的 Skills:将高频、复杂的 Prompt 流程模版化,一键调用。
- 自动化工作流(Automations):让例行任务在后台无感运行,实现真正的异步开发。
后面的所有最佳实践,都是围绕这六大支柱展开的。
二、 编写黄金 Prompt:官方推荐的“四要素框架”
在大型代码库或高风险重构任务中,模糊的指令会导致 AI 频繁犯错。
官方推荐使用“四要素框架”来构建每一次核心 Prompt:
- Goal(目标):明确你希望修改或实现什么功能。
- Context(上下文):指定相关的文件、目录、依赖库或报错日志(推荐使用
@符号直接关联文件)。 - Constraints(约束):限制技术栈、代码规范、性能指标或安全边界。
- Done when(验收标准):定义任务完成的标志,如测试通过、无类型报错等。
1. 案例对比:差写法 vs 官方推荐写法
低效的写法:
帮我优化一下 checkout 流程。
高效的“四要素”写法:
Goal:减少 src/checkout/ 目录中重复的支付校验逻辑。
Context:相关文件位于 src/checkout/ 和 src/orders/validation.ts,后者包含可复用的校验函数。
Constraints:不得改变现有公开 API 的响应格式,禁止引入新的第三方依赖。
Done when:运行 pnpm test --filter checkout 全部通过,且代码差异(diff)仅限于 src/checkout/ 目录。
2. 推理级别的选择与成本核算
官方文档明确指出,不同的任务适合不同的推理强度(Reasoning Level):
- Low(低推理):适合快速补全、单文件修改等范围明确的简单任务,响应速度最快。
- Medium / High(中/高推理):适合跨文件调试、逻辑重构,兼顾深度与速度。
- Extra High(极高推理):适合需要深度思考的 Agent 级多步骤任务,Token 消耗较大。
在实际开发中,建议将默认推理级别设置为 Medium。
这样既能保证复杂逻辑的准确性,又能有效控制 Token 消耗,实现调用成本管理。
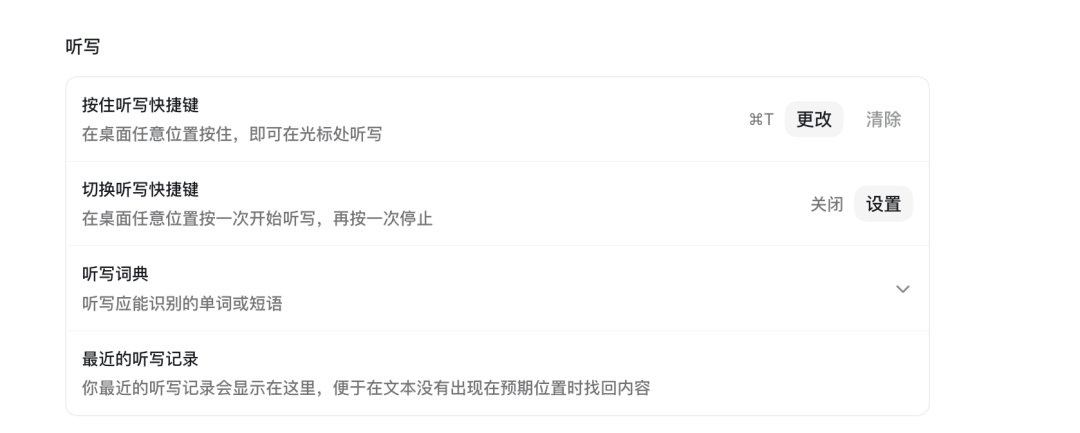
此外,Codex App 支持语音输入,在需要描述复杂业务逻辑或排错上下文时,语音输入的效率远高于键盘打字。
三、 复杂任务的规划艺术:从 Plan Mode 到 PLANS.md
面对复杂的跨模块重构,直接让 Codex 修改代码极易引发灾难性的冲突。
官方推荐了三种规划机制:
1. Plan Mode(规划模式)
在 CLI 中输入 /plan 或按 Shift + Tab,可以强制 Codex 进入规划状态。
此时它不会直接修改代码,而是先收集上下文、分析依赖,并向你展示一份详细的执行步骤,确认无误后再动手。
2. 逆向提问法
当你对需求只有模糊的概念时,可以让 Codex 扮演系统架构师来挑战你的假设:
“我想重构权限模块,但还没理清细节。请先向我提 3 个关键问题,帮我明确具体需求,然后再制定代码修改计划。”
3. PLANS.md 模板化管理
在项目根目录下维护一个 PLANS.md 文件。
当执行多步骤、跨天数的长期任务时,让 Codex 严格按照该模板记录进度、未决问题和下一步计划。
这种方式非常适合多人协作的大型项目。
四、 运行环境配置:通过 config.toml 统一行为
在配置 Codex 的运行环境时,除了使用官方默认通道,我们也可以通过自定义模型服务配置来接入其他兼容的 API 服务。例如,在本地开发环境配置或网络环境配置受限时,使用支持 OpenAI Compatible API 的多模型聚合平台可以提供更灵活的选择。在本文的演示环境中,我们使用 iThinkAPI 作为模型服务配置示例。实际配置时,你需要重点关注 API Key、Base URL 以及具体的模型名称,确保接口格式与服务文档保持一致。
Base URL:https://token.ithinkai.cn/v1
API Key:YOUR_API_KEY
Model:以服务文档为准,最新模型 claude-fable-5, gpt-5.5, claude-opus-4-8,gpt-image-2 模型都有几乎在 0.05¥/图,支持 2k,4k
Codex 的配置文件遵循分层覆盖原则,优先级从低到高依次为:
- 全局配置:
~/.codex/config.toml(定义个人默认偏好,如默认推理模型、沙箱安全策略)。 - 项目级配置:项目根目录下的
.codex/config.toml(定义项目专属的 MCP 服务器、代码风格规范等)。 - 命令行参数:临时覆盖前两者的单次行为。
通过合理配置 config.toml,你可以让 Codex 在不同的项目间无缝切换行为模式。
五、 AGENTS.md:构建团队持久记忆的“工程协议”
如果你不希望每次对话都重复输入项目规范,AGENTS.md 就是最核心的解决方案。
它是专为 AI Agent 设计的 README 说明书,Codex 在启动时会自动将其加载到上下文缓冲区中。
1. AGENTS.md 核心要素
一个标准的 AGENTS.md 应当包含以下要素:
- 目录结构:关键模块的分布与核心文件作用。
- 运行与构建:如何本地启动、如何运行测试(如
npm run test)。 - 代码规范:命名约定、禁止使用的反模式(如禁止使用
any类型)。 - 验收边界:PR 提交前的检查清单。
2. 多层级覆盖机制
AGENTS.md 支持多层级覆盖,离工作目录越近,优先级越高:
- 全局级:
~/.codex/AGENTS.md,适用于你个人的通用编码习惯。 - 项目级:根目录下的
AGENTS.md,由团队共享,统一代码风格。 - 目录级:例如在
src/frontend/AGENTS.md和src/backend/AGENTS.md中分别定义前后端不同的技术栈约束。
在 CLI 中运行 /init 命令可以快速生成初始模板。
官方特别强调:短小且精准的 AGENTS.md,其效果远好于冗长且模糊的文档。
当 Codex 连续犯了两次同样的错误时,就是你更新 AGENTS.md 约束条件的最佳时机。
六、 从 Skills 到 Automations:固化高频工作流
当某个 Prompt 组合被高频使用时,就应当将其封装为 Skill(技能)。
1. 如何设计一个好的 Skill
Skill 的核心是一个 SKILL.md 文件,它定义了明确的输入、输出以及触发词。
官方建议:
- 每个 Skill 聚焦解决一个具体问题。
- 定义清晰的输入和输出格式。
- 在 Description 中写明触发词,方便日常调用。
个人 Skills 存储在 $HOME/.agents/skills,而团队共享的 Skills 则可以提交至 Git 仓库的 .agents/skills 目录中。
这样,新成员拉取代码后即可直接开箱即用。
2. 自动化工作流(Automations)
当 Skill 运行足够稳定后,就可以通过 Automations(自动化) 托管至后台。
在 Codex App 的 Automations 面板中,你可以配置定时任务,例如:
- 每天下班前自动扫描代码库中的潜在安全漏洞。
- 自动汇总当天的 Git Commit 并生成 Standup 站会摘要。
- 监控 CI 失败日志并自动给出修复建议。
自动化运行建议在独立的 Git Worktree 中进行,避免阻塞或污染你当前正在开发的本地工作区。
七、 避坑指南:官方点名的八大高频误区
官方文档在末尾特别列出了开发者最容易踩入的八个误区,对照检查可以帮你避开 90% 的低效调用:
误区一:在 Prompt 中堆砌临时规则
- 错误:每次对话都手动输入“不要使用 any”、“使用 TypeScript”等。
- 正确:将通用规则写入
AGENTS.md,让其自动加载。
误区二:不提供运行与测试命令
- 错误:只让 Codex 改代码,不告诉它如何编译和运行测试。
- 正确:在
AGENTS.md中明确配置build和test指令,让 Codex 具备自我验证的能力。
误区三:复杂重构直接动手
- 错误:直接下达“重构用户模块”的指令。
- 正确:先进入
/plan模式,让其输出架构设计,评审通过后再执行。
误区四:过度授权带来安全隐患
- 错误:一开始就给 Codex 完整的系统读写与执行权限。
- 正确:遵循最小权限原则,根据工作流逐步开放必要的目录访问权。
误区五:在同一工作区并发运行多个修改线程
- 错误:多个 Agent 线程同时修改同一批本地文件,导致代码冲突。
- 正确:利用 Git Worktree 将不同的并发任务隔离在不同的工作树中。
误区六:工作流未经验证即自动化
- 错误:直接把一个刚写好的 Prompt 放入 Automations 运行。
- 正确:先将其封装为 Skill 并手动测试数次,确认边界情况处理无误后再配置自动化。
误区七:像监工一样盯着 AI 运行
- 错误:每生成一行代码就去纠正,无法发挥 AI 的异步处理优势。
- 正确:下达任务后去处理其他事务,让 Codex 在后台跑完测试并给出 Diff 后再统一 Review。
误区八:一个会话线程用到底
- 错误:在同一个 Chat 会话中处理整个项目的所有开发任务。
- 正确:坚持“一任务一线程”原则。当需要分叉探索时,使用
/fork命令派生新线程,防止上下文膨胀导致输出质量劣化。
八、 总结:构建你的闭环开发流
把官方文档的所有建议串起来,一个成熟的 Codex 工作流大概是这样的:
- 初始化:在仓库里跑
/init生成AGENTS.md,配置本地config.toml。 - 任务启动:每个任务开一个独立线程,按“四要素框架”编写 Prompt。
- 过程管理:复杂任务先用
/plan模式,启动后让 Codex 在后台异步执行。 - 成果验收:使用 App 的 Diff 面板进行 Review,运行本地测试集进行验证。
- 持续迭代:发现高频模式就封装为 Skill,稳定后托管至 Automation,根据报错复盘并更新
AGENTS.md。
正如官方所说:“Codex 不仅仅是一个代码生成器。在正确的指令和配置下,它能够独立完成编写、测试、校验和审查的完整开发闭环。”
从今天开始,尝试在你的项目中跑一次 /init,建立属于你和团队的 AGENTS.md,把繁琐的重复性劳动交给 AI,将精力重新聚焦于架构设计与核心业务逻辑。@TOC

欢迎加入 MCP 技术社区!与志同道合者携手前行,一同解锁 MCP 技术的无限可能!
更多推荐


 7
7 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)