AI Agent Context Window 不是记忆:上下文窗口、Memory 和 Token 的区别
AI Agent Context Window 不是记忆:上下文窗口、Memory 和 Token 的区别
摘要:这篇文章讲清楚 AI Agent 里的 Context Window、Memory、Token、RAG 上下文之间的关系。重点不是概念翻译,而是工程里怎么避免“窗口很大但模型还是忘”的问题。
上一篇我们讲了 Token 是怎么算的。
那模型一次能处理多少 Token,靠什么限制?
答案是:Context Window。
很多人第一次听到 128K、1M 上下文窗口,会下意识觉得:
窗口这么大,模型是不是就什么都记得住了?
不一定。
Context Window 只是模型这一次能看到的内容范围。
它不是记忆。
先说结论
Context Window 可以理解成:
一次模型调用里,输入和输出能占用的 Token 空间。
它不是数据库,也不是长期记忆系统。
一般直接调用模型 API 时,模型看到的只有这次传进去的上下文。
如果你没有把上一次对话带进去,模型就不会凭空记得。
所以一句话就够了:
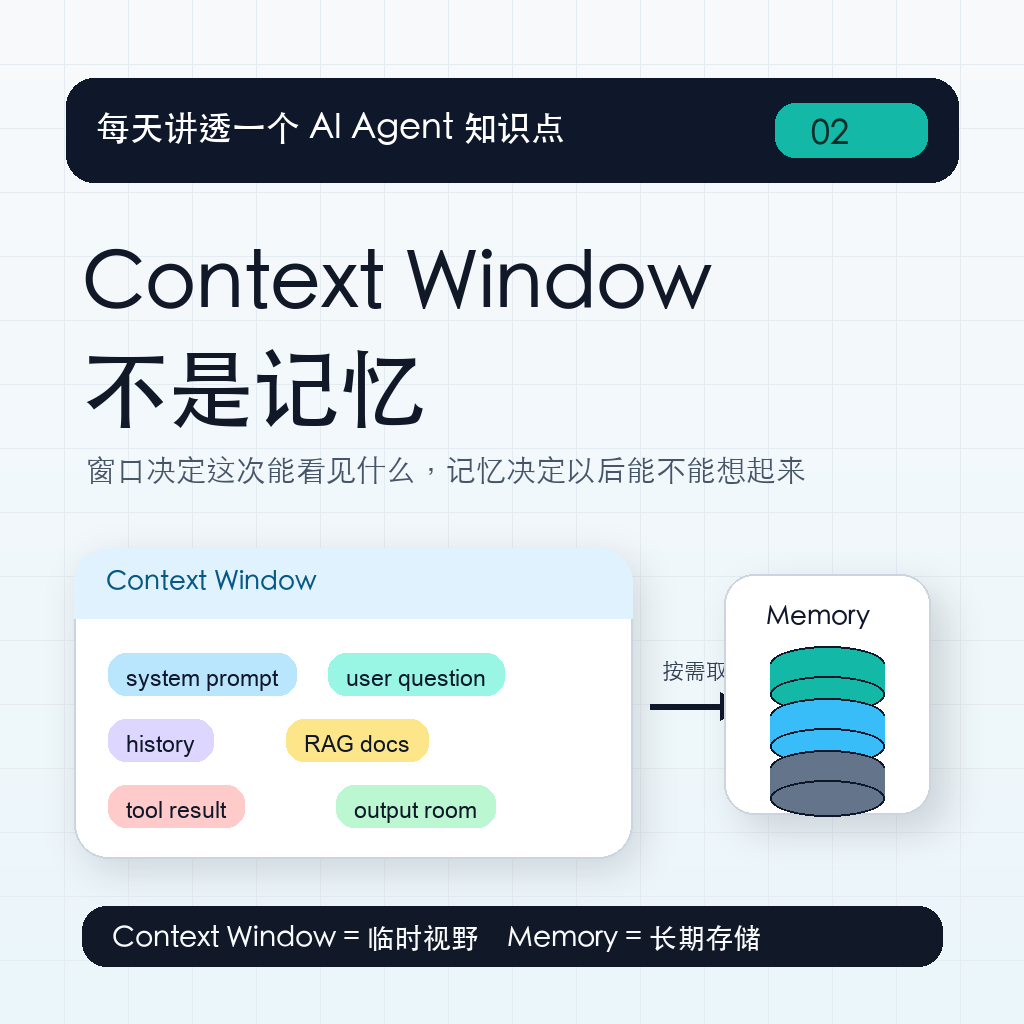
Context Window 是这次能看见什么,Memory 是以后还能不能想起来。
Context Window 里有什么?
一次完整调用里,Context Window 通常会放这些东西:
- system prompt;
- 用户问题;
- 最近几轮对话历史;
- RAG 检索出来的文档片段;
- Tool Calling 的工具定义和工具返回结果;
- 给模型输出预留的空间。
看起来只是一句用户问题,实际传给模型的可能是一整包内容。
比如做一个 Java 日志分析助手,用户只问:
帮我看一下这个异常是什么原因?
但后端可能一起塞进去:
系统提示词
最近几轮对话
异常堆栈
相关代码片段
排障手册
工具调用结果
这些都会占 Token。窗口再大,也不是让你无脑往里塞东西。
为什么窗口很大,Agent 还是会忘?
主要有三个原因。
1. 你的代码可能没带历史
模型本身不替你的应用保存对话状态。
第 1 次调用里,用户说:
我的项目用的是 Spring Boot 3.2
第 2 次调用里,如果你只传:
帮我写个配置类
那模型不知道你用的是 Spring Boot 3.2。
不是它“忘了”,是你这次没有告诉它。
很多聊天系统所谓的“记住上下文”,本质上是应用层把历史消息重新带进这次请求。
2. 放进去了,也不代表一定用得好
长上下文还有一个经典问题:Lost in the Middle。
简单说就是:
关键信息放在很长上下文的中间时,模型更容易忽略它。
开头和结尾的信息通常更容易被用到,中间的信息更容易被淹没。
所以,不要以为支持 128K、1M,就等于模型能稳定消化全部内容。
标称窗口大小,不等于有效利用能力。
3. 历史太多会变成噪音
假设你做一个代码助手,用户连续问了 20 个不同问题。
第 21 个问题时,如果把前面 20 轮全带上,模型可能反而更迷糊:
第 8 轮提过 NullPointerException
第 12 轮提过 Bean 注入失败
第 17 轮提过 Maven 依赖冲突
现在这个问题到底要关联哪一轮?
上下文不是越多越好。
相关的上下文才有用。
Context Window 和 Memory 的区别
这两个词很容易混。
可以这样区分:
| 概念 | 可以怎么理解 | 特点 |
|---|---|---|
| Context Window | 本次调用的临时视野 | 调用时构建,受 Token 限制 |
| Memory | 应用层维护的长期记忆 | 通常存在数据库、向量库或缓存里,需要时取回来 |
一个简单类比:
Context Window = 你现在摊开的几页资料
Memory = 你书架上的资料库
你不能同时把整座书架都摊在桌上。
你只能根据当前问题,挑几页最相关的放到模型面前。
工程里也是这样:
用户新问题
-> 从 Memory 里找相关历史
-> 从知识库里找相关文档
-> 组装本次 Context Window
-> 调用模型
-> 把有价值的新信息写回 Memory
Memory 里可以有很多内容,但本次 Context Window 只应该放当前有用的内容。
工程上怎么处理?
落到工程里,先抓这几件事。
1. 不要无限带历史
不要每次都把所有聊天记录塞进去。
更常见的做法是:
- 最近几轮原文保留;
- 更早的内容压成摘要;
- 关键事实单独存起来;
- 当前问题相关的历史再检索回来。
比如:
最近 3 轮对话
+ 早期对话摘要
+ 和当前问题相关的历史片段
这通常比“全量历史”稳定。
2. RAG 不要 topK 乱开
RAG 检索不是越多越好。
topK = 20 看起来资料更全,但也可能把真正有用的信息挤到中间,甚至引入噪音。
一般可以先从 3 到 5 开始,再看效果调整。
再配合:
- rerank;
- 截断;
- 摘要;
- 去重。
目标不是“塞更多”,而是“塞得更准”。
3. 重要信息放显眼位置
如果有关键约束,不要藏在一大段上下文中间。
比如:
必须用 JSON 返回
不要编造不存在的接口
只能基于给定文档回答
这类约束可以放在 system prompt,或者在用户问题附近再强调一次。
这是在对抗 Lost in the Middle。
4. 给输出留空间
上下文窗口不是只给输入用。
模型生成的回答也要占 Token。
如果一个模型支持 128K,你把输入塞到接近上限,输出空间就会被挤掉。
所以要给输入设置上限,也要给输出设置上限。
Context Window: 128K
输入控制在: 100K 以内
剩下空间留给输出和安全余量
5. 记录 Token 分布
只记录 total tokens 不够。
最好能知道 Token 花在了哪里:
system prompt: 800
history: 3000
RAG docs: 5000
user question: 200
output: 900
发现 RAG 太大,就优化检索。
发现历史太大,就做摘要和截断。
没有这些数据,就只能凭感觉调。
一个小例子
假设你做了一个日志分析助手。
最开始你可能会这样写:
String prompt = "分析这个日志:\n" + fullLog;
如果 fullLog 有 2 万 Token,模型每次都要读完整日志。
慢、贵,还容易被无关日志干扰。
更好的做法是先过滤:
List<String> errorLines = filterErrorLines(fullLog);
String relevantLog = String.join("\n", errorLines);
String prompt = "分析这些错误日志:\n" + relevantLog;
如果还太长,再截断或摘要。
很多时候,输入少一点,回答反而更准。因为噪音少了。
最后总结
Context Window 不是记忆。
它只是模型这一次能看到的临时空间。
记住三句话:
- 窗口大,不等于模型能稳定用好所有内容;
- Memory 通常是应用层的外部存储,需要时再取回来;
- 上下文工程的目标不是塞满窗口,而是把有用的信息放对位置。
我是 Dilee,11 年 Java 老兵,专注 AI 落地应用。
后续会继续更新 Spring AI、RAG、Memory、Tool Calling、MCP 等实战内容。

欢迎加入 MCP 技术社区!与志同道合者携手前行,一同解锁 MCP 技术的无限可能!
更多推荐

 7
7 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)