「全球首个自回归视频生成大模型」,清华特奖得主团队 Sand AI 携 MAGI-1 颠覆视频生成!模型权重、代码100%开源
就在昨天,的创业公司Sand AI推出的MAGI-1大模型以开源之姿重磅入场,成为视频生成领域的新晋焦点!随着短视频平台崛起与影视制作智能化转型,传统视频生成技术如基于规则的动画系统和早期GAN模型,已难以满足多样化场景需求。而基于Transformer与扩散模型的新一代技术,虽带来革新希望,却仍面临长序列计算复杂度高、生成内容时序混乱等挑战。随着AIGC应用向影视制作、虚拟主播、游戏开发等领域渗
就在昨天,马尔奖、清华特奖得主曹越的创业公司Sand AI推出的MAGI-1大模型以开源之姿重磅入场,成为视频生成领域的新晋焦点!
随着短视频平台崛起与影视制作智能化转型,传统视频生成技术如基于规则的动画系统和早期GAN模型,已难以满足多样化场景需求。而基于Transformer与扩散模型的新一代技术,虽带来革新希望,却仍面临长序列计算复杂度高、生成内容时序混乱等挑战。MAGI-1正是针对这些痛点,通过自回归架构与分块扩散设计,将视频切割为24帧片段逐块生成,配合块因果注意力机制,有效降低计算成本,实现长视频的实时、流畅生成。
随着AIGC应用向影视制作、虚拟主播、游戏开发等领域渗透,对视频生成模型的实时性、可控性和内容质量提出更高要求。这既需要算法创新突破技术瓶颈,也呼唤产学研协同探索更高效的优化路径,推动视频生成大模型从实验室走向大规模产业应用。
为此,我们精心整理了12篇顶刊前沿论文,从不同角度和方法对视频生成大模型进行创新,希望对大家有所帮助!
全部论文+开源代码需要的同学看文末!
【论文1】MAGI-1: Autoregressive Video Generation at Scale
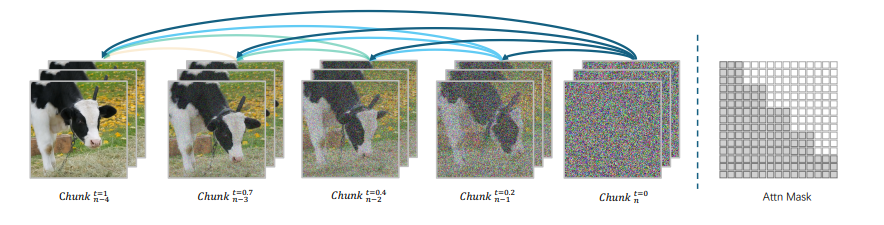
(Left) MAGI-1 performs chunk-wise autoregressive denoising. (Right) A block-causal attention mask enforces temporal causality across chunks, enabling pipelined and parallel generation.
1.研究方法
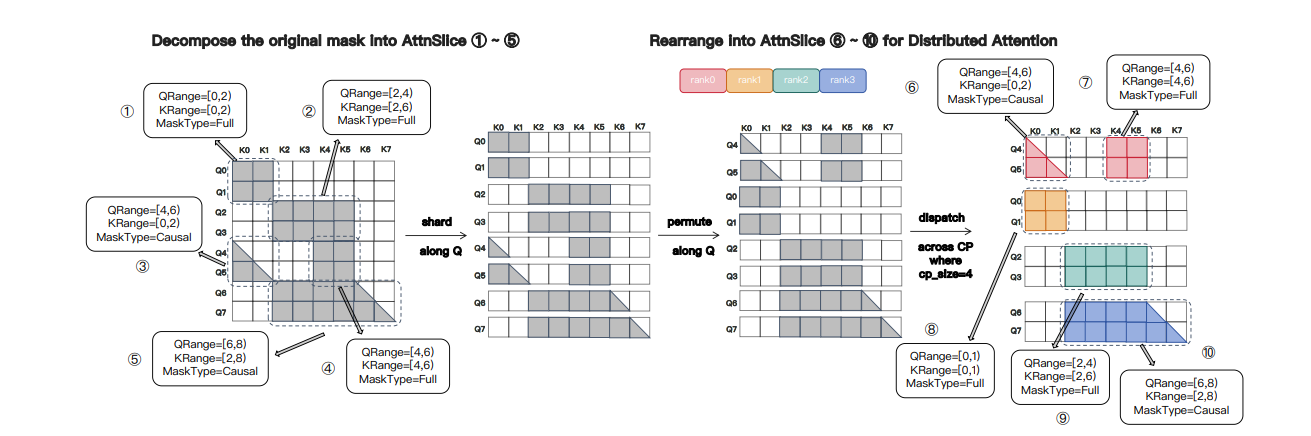
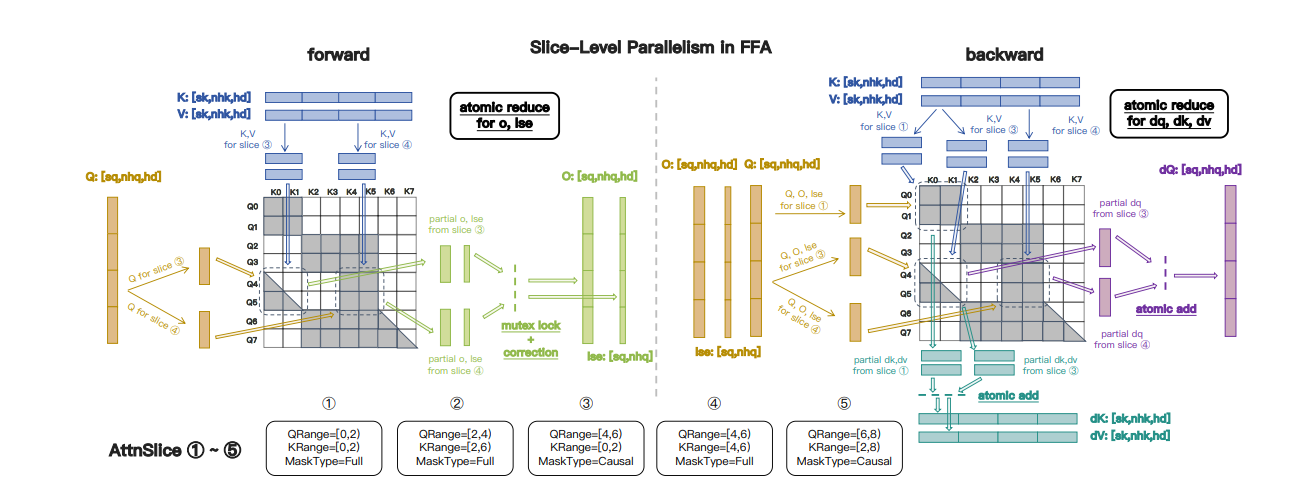
Magi-1 整体架构基于 Diffusion Transformer,采用 Flow-Matching 作为训练目标。训练分为多阶段,第一阶段固定分辨率,第二阶段引入可变分辨率和图像 - 视频联合训练。采用自回归去噪方式预测固定长度(24 帧)的视频片段,前一片段去噪到一定程度后生成下一片段 ,通过分片段自回归设计配合多项改进,包括在注意力机制等方面的创新来生成视频。
2.论文创新点
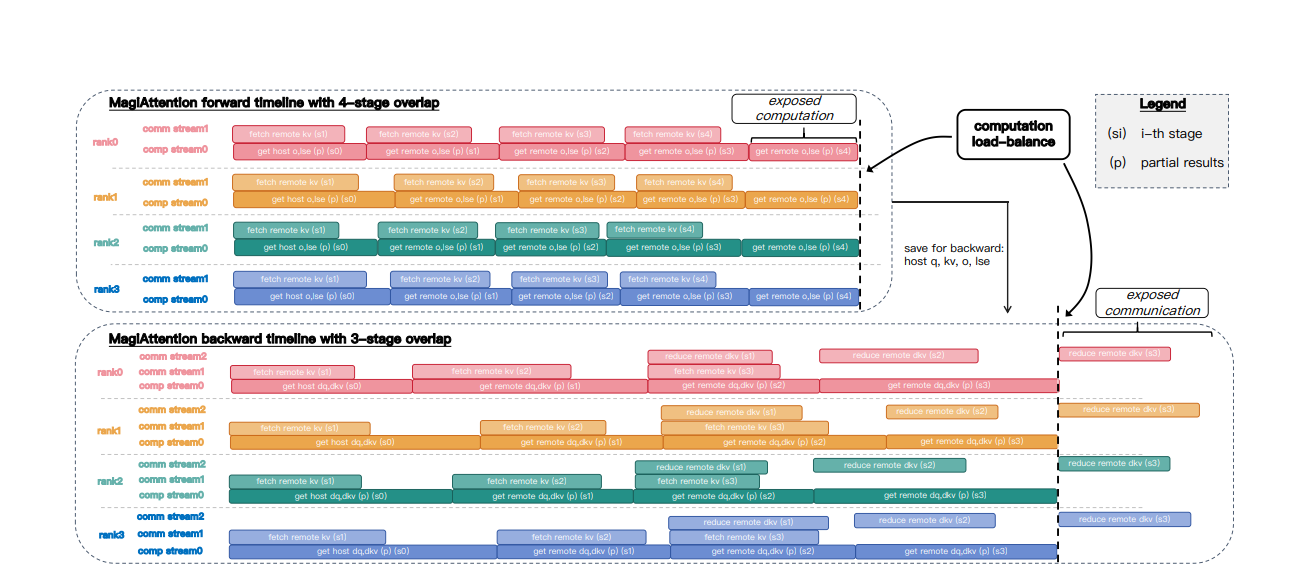
Schematic of MagiAttention’s multi-stage overlap scheduling
-
自回归架构创新:将视频分割为24帧的“块”,逐块生成,支持实时流式生成与长视频无缝衔接,允许用户通过分块提示词精确控制场景过渡。
-
扩散模型优化创新:在Diffusion Transformer基础上,进行块因果注意力、并行注意力块、QK标准化与分组查询、三明治归一化等多项创新,提升训练效率与模型性能。
-
蒸馏算法创新:开发多步长自洽蒸馏技术,使模型可在RTX 4090显卡上运行,量化版本性能损失小且速度提升 。
论文链接:https://static.magi.world/static/files/MAGI_1.pdf
【论文2】ByTheWay: Boost Your Text-to-Video Generation Model to Higher Quality in a Training-free Way

Unlock the potential of pretrained text-to-video (T2V) generation models in a training-free approach.
1.研究方法
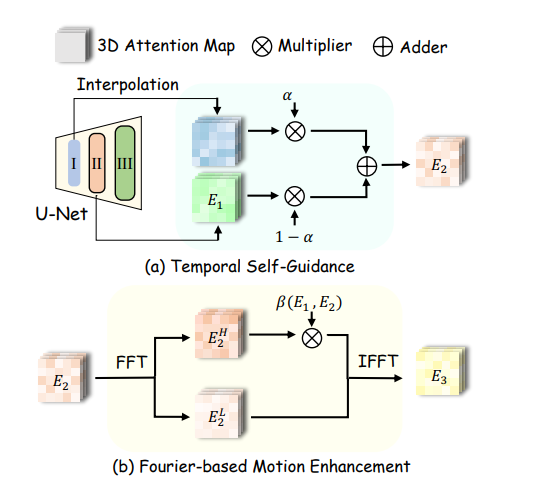
ByTheWay Operations
该论文提出的ByTheWay 方法由两部分构成。Temporal Self-Guidance 通过将前一个上采样块的时间注意力图融入后续块,减少不同解码器块时间注意力图的差异,以此提升生成视频的结构合理性和时间一致性;Fourier-based Motion Enhancement 利用快速傅里叶变换(FFT)分解时间注意力图,对高频分量进行缩放,增加其能量,进而增强视频运动幅度和丰富度。
2.论文创新点
![Quantitative results of ByTheWay on VBench [70]](https://i-blog.csdnimg.cn/direct/7ba314ec09334ccda8edba3c5d7d09a8.png)
Quantitative results of ByTheWay on VBench [70]

Ablation on ByTheWay parameters
-
非训练式优化:无需额外训练、添加参数、扩充内存或增加采样时间,就能提升文本到视频生成的质量,在推理阶段以极小成本优化视频生成效果。
-
深入分析注意力模块:发现视频生成中时间注意力图的两个关键关联,即不同块时间注意力图差异与视频结构、时间不一致性的关系,以及时间注意力图能量与视频运动幅度的关系,为方法设计提供理论依据。
-
强适用性与扩展性:能以即插即用的方式无缝集成到多种主流文本到视频生成模型(如AnimateDiff、VideoCrafter2)中,且在图像到视频任务中也展现出潜力,适用范围广。
论文链接:https://arxiv.org/pdf/2410.06241
关注下方《AI前沿速递》🚀🚀🚀
回复“C260”获取全部方案+开源代码
码字不易,欢迎大家点赞评论收藏

欢迎加入 MCP 技术社区!与志同道合者携手前行,一同解锁 MCP 技术的无限可能!
更多推荐


 9
9 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)