一文详解:8种常见的大模型微调方法,看这篇就够了!
P-Tuning v2是P-Tuning的进一步改进版,在P-Tuning中,连续提示被插入到输入序列的嵌入层中,除了语言模型的输入层,其他层的提示嵌入都来自于上一层。这种方法的优势在于不需要调整模型的所有权重,而是通过在输入中添加前缀来调整模型的行为,从而节省大量的计算资源,同时使得单一模型能够适应多种不同的任务。与传统的微调范式不同,前缀调整提出了一种新的策略,即在预训练的语言模型(LM)输入
1、LoRA
LoRA(Low-RankAdaptation)是一种旨在微调大型预训练语言模型(如GPT-3或BERT)的技术。
其核心理念在于,在模型的决定性层次中引入小型、低秩的矩阵来实现模型行为的微调,而无需对整个模型结构进行大幅度修改。
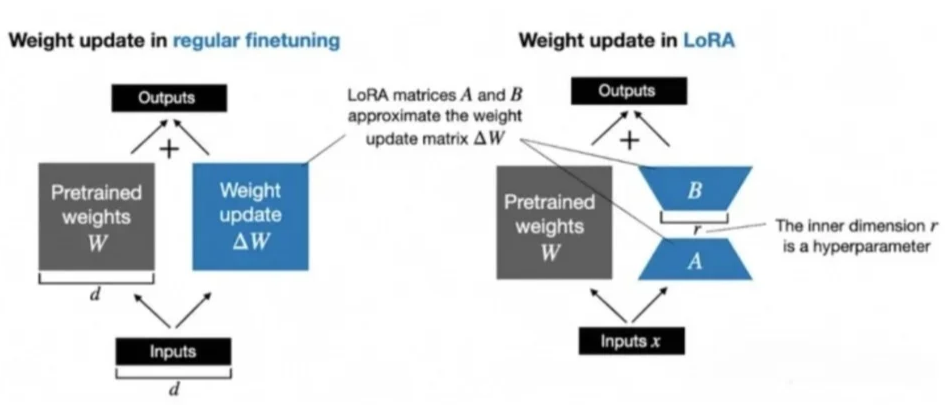
这种方法的优势在于,在不显著增加额外计算负担的前提下,能够有效地微调模型,同时保留模型原有的性能水准。
LORA的操作流程如下:
1)确定微调目标权重矩阵: 首先在大型模型(例如GPT)中识别出需要微调的权重矩阵,这些矩阵一般位于模型的多头自注意力和前馈神经网络部分。
2)引入两个低秩矩阵: 然后,引入两个维度较小的低秩矩阵A和B。假设原始权重矩阵的尺寸为dd,则A和B的尺寸可能为dr和r*d,其中r远小于d。
3)计算低秩更新: 通过这两个低秩矩阵的乘积AB来生成一个新矩阵,其秩(即r)远小于原始权重矩阵的秩。这个乘积实际上是对原始权重矩阵的一种低秩近似调整。
4)结合原始权重: 最终,新生成的低秩矩阵AB被叠加到原始权重矩阵上。因此,原始权重经过了微调,但大部分权重维持不变。
这个过程可以用数学表达式描述为: 新权重=原始权重+AB。
学习AI大模型是一项系统工程,需要时间和持续的努力。但随着技术的发展和在线资源的丰富,零基础的小白也有很好的机会逐步学习和掌握。【点击蓝字获取】
【2025最新】AI大模型全套学习籽料(可白嫖):LLM面试题+AI大模型学习路线+大模型PDF书籍+640套AI大模型报告等等,从入门到进阶再到精通,超全面存下吧!
以一个具体实例来说,假设我们手头有一个大型语言模型,它通常用于执行广泛的自然语言处理任务。现在,我们打算将其微调,使其在处理医疗健康相关的文本上更为擅长。
采用LoRA方法,我们无需直接修改模型现有的大量权重。相反只需在模型的关键部位引入低秩矩阵,并通过这些矩阵的乘积来进行有效的权重调整。
这样一来,模型就能更好地适应医疗健康领域的专业语言和术语,同时也避免了大规模权重调整和重新训练的必要。
2、QLORA
OLoRA(Quantized Low-RankAdaptation)是一种结合了LORA(Low-RankAdaptation)方法与深度量化技术的高效模型微调手段。
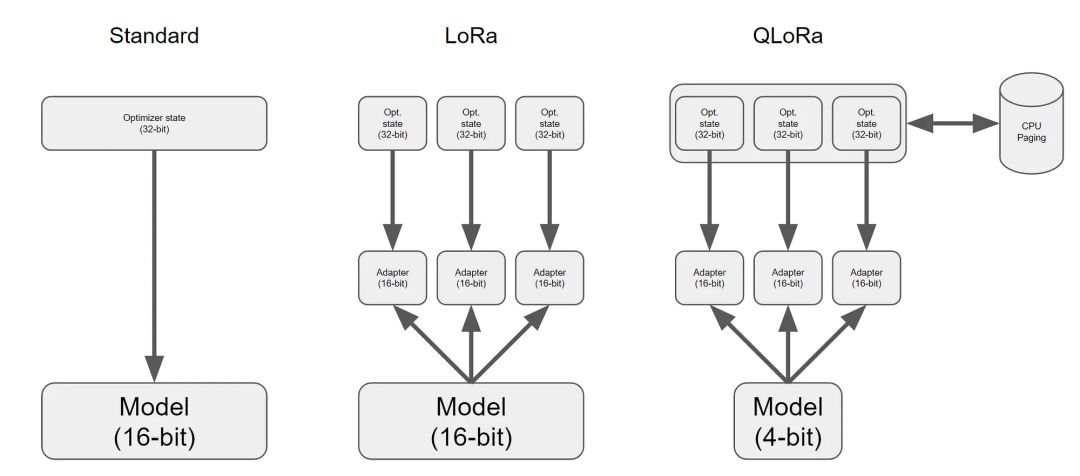
QLORA的核心在于:
**1)量化技术:**QLORA通过双阶段数值编码方案实现参数高效压缩,其核心包含存储环节的4-bit NormalFloat标准化浮点格式与计算环节的16-bit BrainFloat运算架构。
这种混合精度处理机制在保证神经网络计算稳定性的前提下,将模型参数存储密度提升300%,通过动态反量化策略维持了原始模型97%以上的表征能力。
相较于传统量化方法,该方案在显著降低存储资源占用的同时,构建了精度损失与硬件效能的最优平衡模型。
**2)量化操作:**在4-bit精度量化中,权重参数通过4比特二进制编码表征,其核心流程是通过特征值筛选与区间映射实现数据压缩。
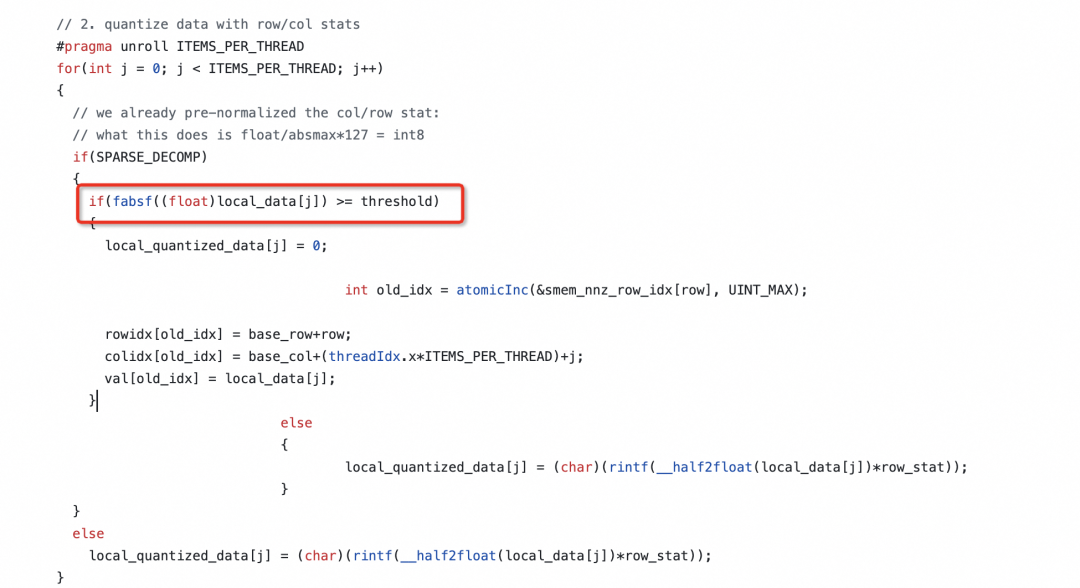
首先基于张量分布特性划定动态范围边界(如[-0.8,0.8]),将该连续空间均等划分为16个离散子域,每个子域对应唯一的4-bit编码值。
最终通过最近邻匹配原则,将原始FP32精度数值投影至最邻近的离散量化点上,完成32位浮点数值到4位定点表示的精度转换。
**3)微调阶段:**在参数优化过程中,OLORA采用4-bit精度加载模型参数,通过动态反量化至bf16格式进行梯度计算,这种混合精度策略有效节省了83%的显存占用。
实际测试表明,该方法使得原本需要80GB显存的LLaMA-33B大模型,仅需单张RTX 4090显卡即可完成全参数微调。
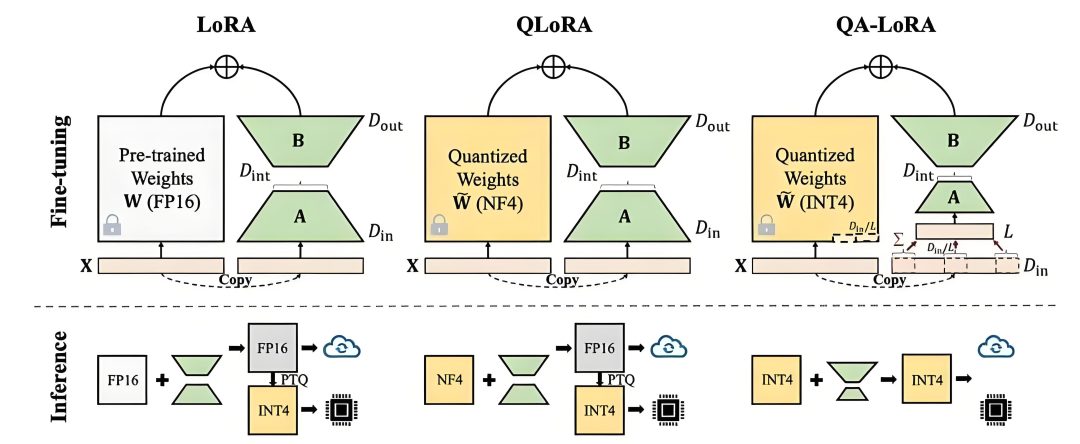
整个过程严格保持原始模型架构,仅在数值计算时实施临时精度转换。
量化过程的挑战在于设计合适的映射和量化策略,以最小化精度损失对性能的影响。
在大型模型中,这种方法可以显著减少内存和计算需求,使得在资源有限的环境下部署和训练成为可能。
3、适配器调整(Adapter Tuning)
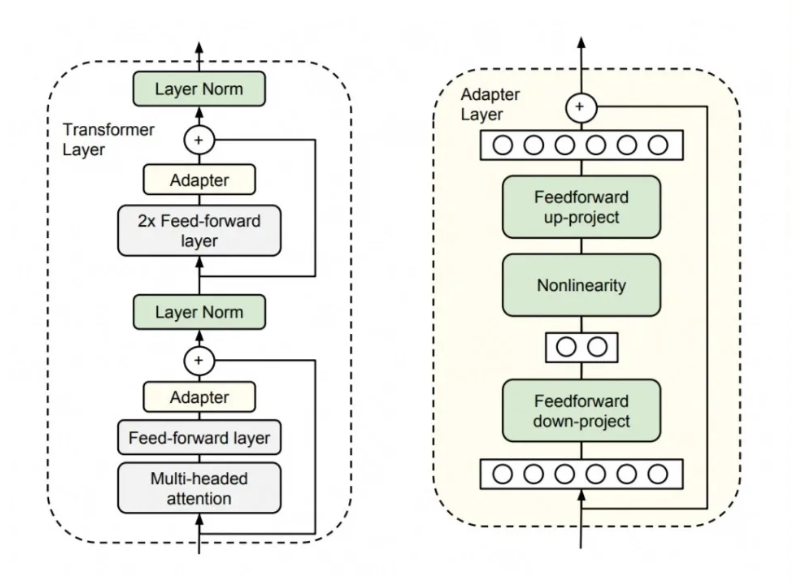
与LoRA技术类似,适配器调整的目标是在保留预训练模型原始参数不变的前提下,使模型能够适应新的任务。
适配器调整的方法是在模型的每个层或选定层之间插入小型神经网络模块,称为“适配器”。这些适配器是可训练的,而原始模型的参数则保持不变。
适配器调整的关键步骤包括:
1)以预训练模型为基础: 初始阶段,我们拥有一个已经经过预训练的大型模型,如BERT或GPT,该模型已经学习了丰富的语言特征和模式。
2)插入适配器: 在预训练模型的每个层或指定层中我们插入适配器。适配器是小型的神经网络,一般包含少量层次,并且参数规模相对较小。
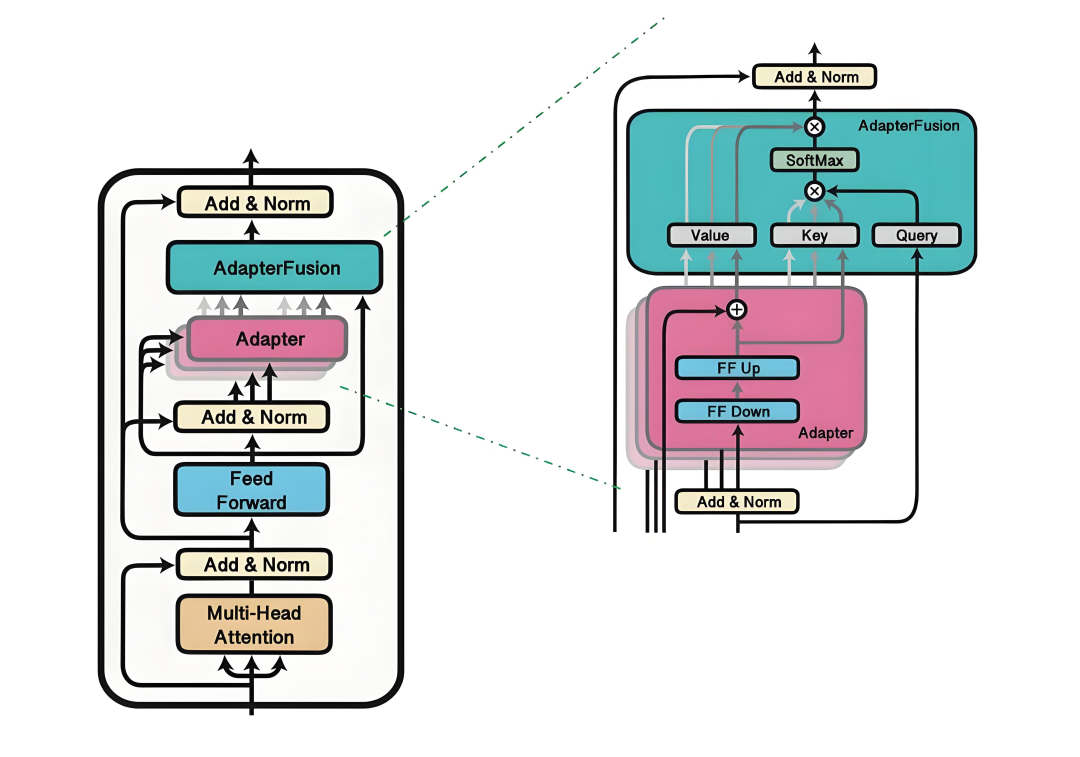
3)维持预训练参数不变: 在微调过程中,原有的预训练模型参数保持不变。我们不直接调整这些参数,而是专注于适配器的参数训练。
4)训练适配器: 适配器的参数会根据特定任务的数据进行训练使适配器能够学习如何根据任务调整模型的行为。
5)针对任务的调整: 通过这种方式,模型能够对每个特定任务进行微调,同时不影响模型其他部分的通用性能。
适配器有助于模型更好地理解和处理与特定任务相关的特殊模式和数据。
6)高效与灵活: 由于只有部分参数被调整,适配器调整方法相比于全模型微调更为高效,并且允许模型迅速适应新任务。
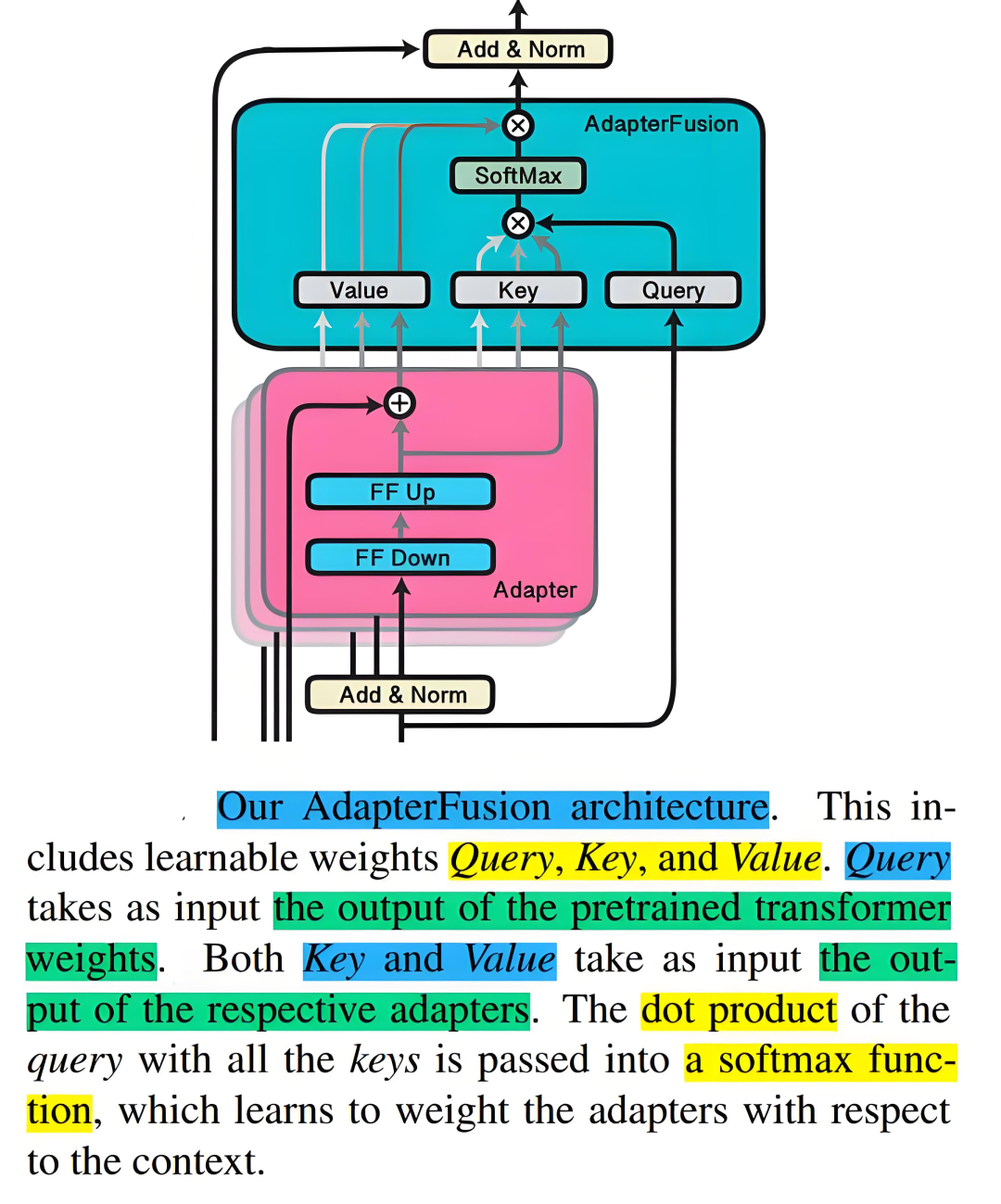
例如,如果我们有一个大型文本生成模型,它通常用于执行广泛的文本生成任务。
若要将其微调以生成专业的金融报告,我们可以在模型的关键层中加入适配器。
在微调过程中,仅有适配器的参数会根据金融领域的数据进行更新,使得模型更好地适应金融报告的写作风格和术语,同时避免对整个模型架构进行大幅度调整。
LORA与适配器调整的主要区别在于
1)LORA: 在模型的权重矩阵中引入低秩矩阵来实现微调。这些低秩矩阵作为原有权重矩阵的修改项,在实际计算时对原有权重矩阵进行调整。
2)适配器调整: 通过在模型各层中添加小型神经网络模块,即“适配器”,来实现微调。
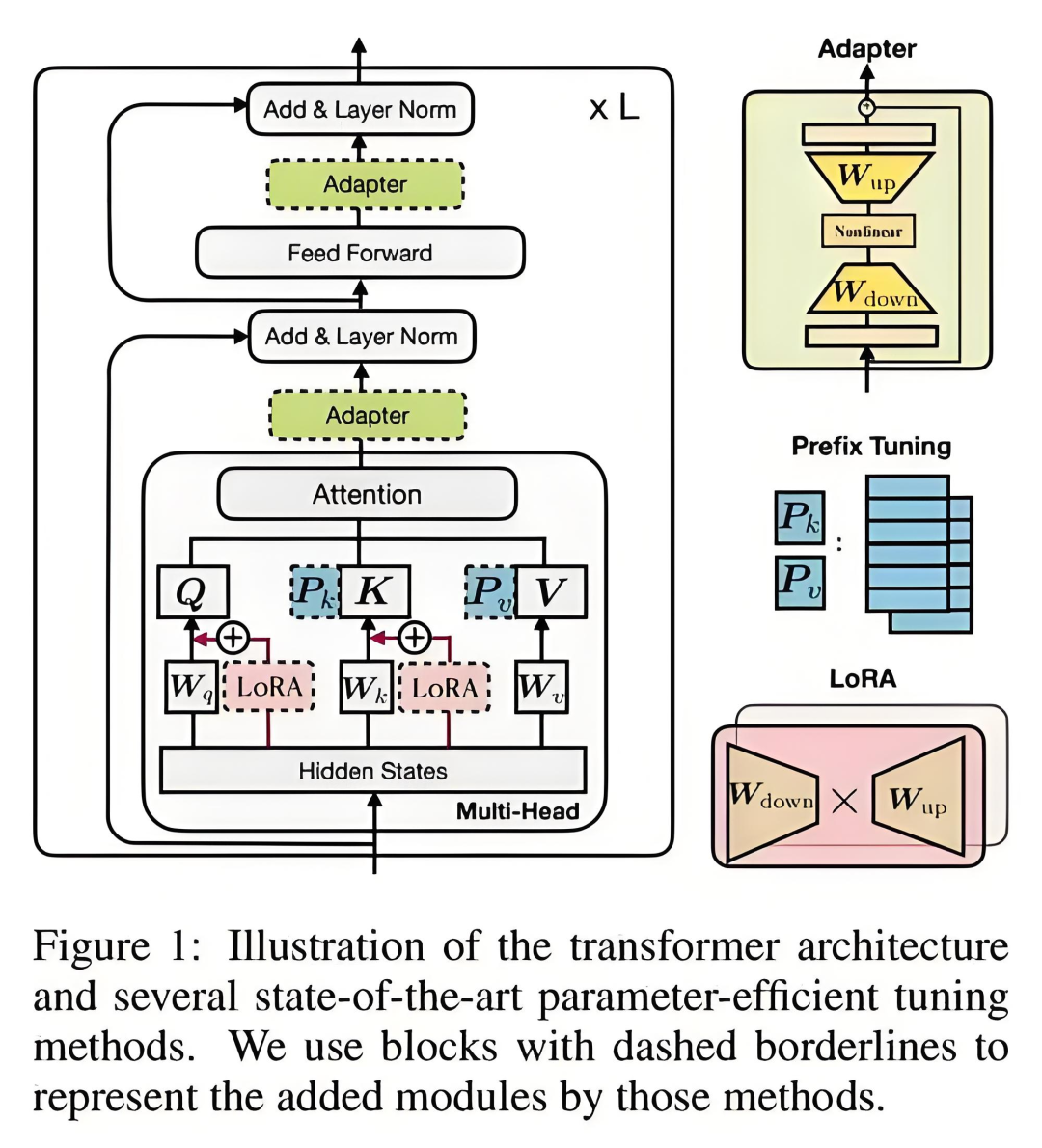
适配器独立于模型的主体结构,仅适配器的参数在微调过程中更新,而模型的其他预训练参数保持不变。
4、前缀调整(Prefix Tuning)
与传统的微调范式不同,前缀调整提出了一种新的策略,即在预训练的语言模型(LM)输入序列前添加可训练、任务特定的前缀,从而实现针对不同任务的微调。
这意味着我们可以为不同任务保存不同的前缀,而不是为每个任务保存一整套微调后的模型权重,从而节省了大量的存储空间和微调成本。
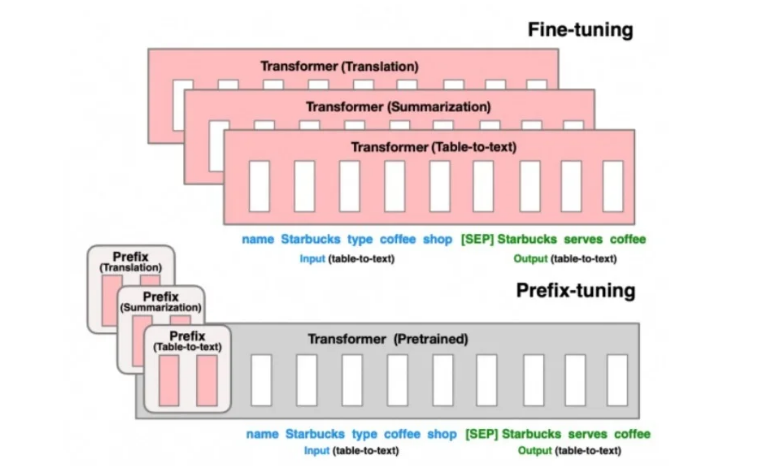
前缀实际上是一种连续可微的虚拟标记(Soft Prompt/与离散的Token相比,它们更易于优化并Continuous Prompt),且效果更佳。
这种方法的优势在于不需要调整模型的所有权重,而是通过在输入中添加前缀来调整模型的行为,从而节省大量的计算资源,同时使得单一模型能够适应多种不同的任务。
前缀可以是固定的(即手动设计的静态提示)或可训练的(即模型在训练过程中学习的动态提示)。
5、提示调整(Prompt Tuning)
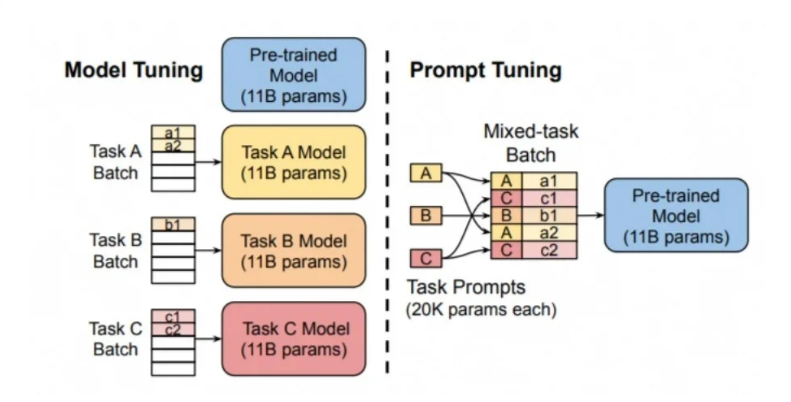
Prompt Tuning 是2021年谷歌在论文《The Power of Scale forParameter-Efficient Prompt Tuning》中提出的微调方法
提示调整是一种在预训练语言模型输入中引入可学习嵌入向量作为提示的微调方法。
这些可训练的提示向量在训练过程中更新,以指导模型输出更适合特定任务的响应。
提示调整与前缀调整都涉及在输入数据中添加可学习的向量,这些向量是在输入层添加的,但两者的策略和目的不同:
1)提示调整: 旨在模仿自然语言中的提示形式,将可学习向量(通常称为提示标记)设计为模型针对特定任务生成特定类型输出的引导。
这些向量通常被视为任务指导信息的一部分,倾向于使用较少的向量来模仿传统的自然语言提示。

2)前缀调整: 可学习前缀更多地用于提供输入数据的直接上下文信息,作为模型内部表示的一部分,可以影响整个模型的行为。
以下是两者的训练示例,以说明它们的不同:
1)提示调整示例:
输入序列: [Prompt1][Prompt2]“这部电影令人振奋。
问题: 评价这部电影的情感倾向。
答案: 模型需要预测情感倾向(例如“积极”)
提示: 没有明确的外部提示,[Prompt1lPrompt2]作为引导模型的内部提示,这里的问题是隐含的,即判断文本中表达的情感倾向。
2)前缀调整示例:
输入序列: [Prefix1][Prefix2][Prefix3]“lwant to watch amovie.
问题: 根据前缀生成后续的自然语言文本。
答案: 模型生成的文本,如“that is exciting and fun.
提示: 前缀本身提供上下文信息,没有单独的外部提示。
6**、P-Tuning**
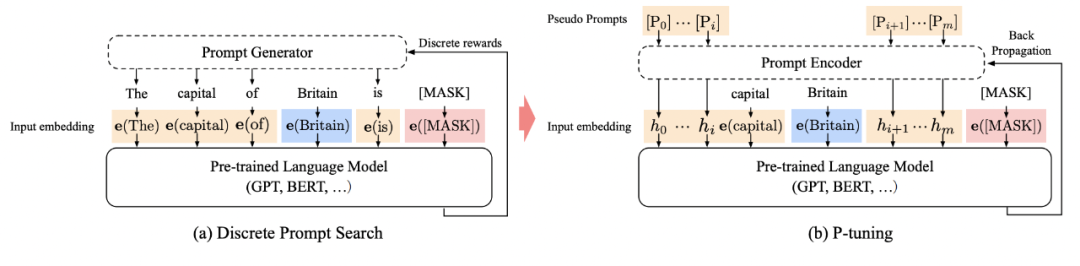
P-Tuning 方法的提出主要是为了解决这样一个问题:大模型的Prompt 构造方式严重影响下游任务的效果。
P-Tuning(基于提示的微调)和提示调整都是为了调整大型预训练语言模型(如GPT系列)以适应特定任务而设计的技术。
两者都利用预训练的语言模型执行特定的下游任务,如文本分类、情感分析等,并使用某种形式的“提示”或“指导”来引导模型输出,以更好地适应特定任务。
提示调整与P-Tuning的主要区别在于
1)提示调整: 使用静态的、可训练的虚拟标记嵌入,在初始化后保持固定,除非在训练过程中更新。
这种方法相对简单,因为它只涉及调整一组固定的嵌入参数,在处理多种任务时表现良好,但可能在处理特别复杂或需要细粒度控制的任务时受限。
2)P-Tuning: 使用一个可训练的LSTM模型(称为提示编码器prompt encoder)来动态生成虚拟标记嵌入。
允许根据输入数据的不同生成不同的嵌入,提供更高的灵活性和适应性,适合需要精细控制和理解复杂上下文的任务。
这种方法相对复杂,因为它涉及一个额外的LSTM模型来生成虚拟标记嵌入。
P-Tuning中使用LSTM(长短期记忆网络)作为生成虚拟标记嵌入的工具,利用了LSTM的以下优势:
1)更好的适应性和灵活性: LSTM可以捕捉输入数据中的时间序列特征,更好地理解和适应复杂的、顺序依赖的任务,如文本生成或序列标注。
2)改进的上下文理解: LSTM因其循环结构,擅长处理和理解长期依赖关系和复杂的上下文信息。
3)参数共享和泛化能力: 在P-Tuning中,LSTM模型的参数可以在多个任务之间共享,这提高了模型的泛化能力,并减少了针对每个单独任务的训练需求。
而在提示调整中,每个任务通常都有其独立的虚拟标记嵌入,这可能限制了跨任务泛化的能力。
这些特性使得LSTM特别适合处理复杂任务和需要细粒度控制的应用场景。
然而,这些优势也伴随着更高的计算复杂度和资源需求因此在实际应用中需要根据具体需求和资源限制来权衡使用LSTM的决策。
7、P-Tuning v2
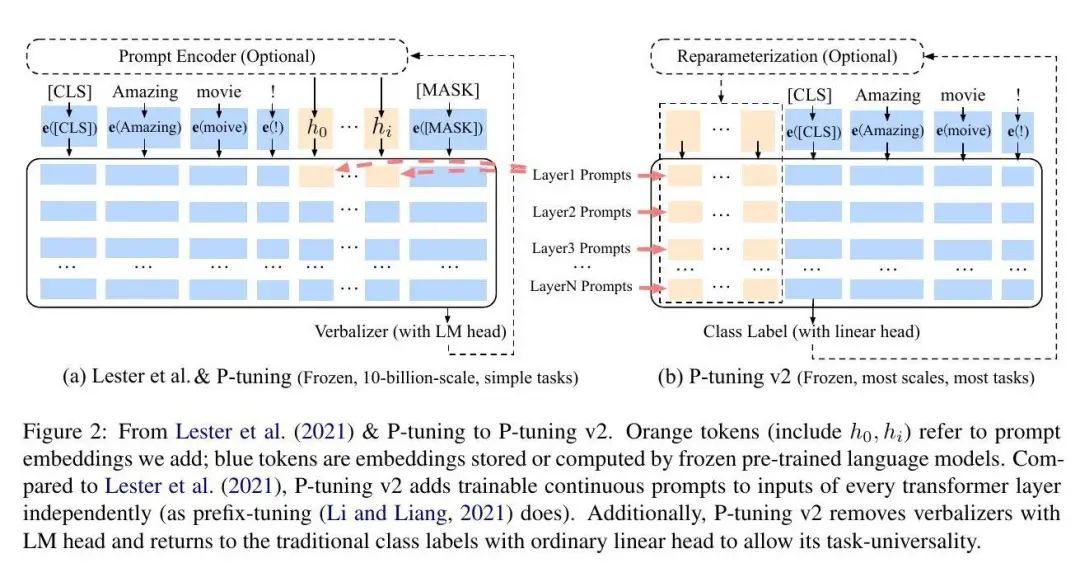
P-Tuning v2是P-Tuning的进一步改进版,在P-Tuning中,连续提示被插入到输入序列的嵌入层中,除了语言模型的输入层,其他层的提示嵌入都来自于上一层。
这种设计存在两个问题: 第一,它限制了优化参数的数量。由于模型的输入文本长度是固定的,通常为512,因此提示的长度不能过长。
第二,当模型层数很深时,微调时模型的稳定性难以保证; 模型层数越深,第一层输入的提示对后面层的影响难以预测,这会影响模型的稳定性。
P-Tuning v2的改进在于,不仅在第一层插入连续提示,而是在多层都插入连续提示,且层与层之间的连续提示是相互独立的。
这样,在模型微调时,可训练的参数量增加了,P-Tuning v2在应对复杂的自然语言理解(NLU)任务和小型模型方面,相比原始P-Tuning具有更出色的效能。
除了以上PEFT,当前还存在PILL(PluggableInstructionLanguage Learning)、SSF(Scaling & Shifting YourFeatures)等其他类型的微调方法。
SSF核心思想是对模型的特征(即模型层的输出)进行缩放(Scaling)和位移(Shifting)。简单来说,就是通过调整特征的比例和偏移量来优化模型的性能。
这种方法可以在改善模型对特定任务的响应时,不需要调整或重新训练模型中的所有参数,从而在节省计算资源的同时保持或提升模型性能。
这对于处理大规模模型特别有效,因为它减少了训练和调整所需的资源和时间。
8、LORA+MoE
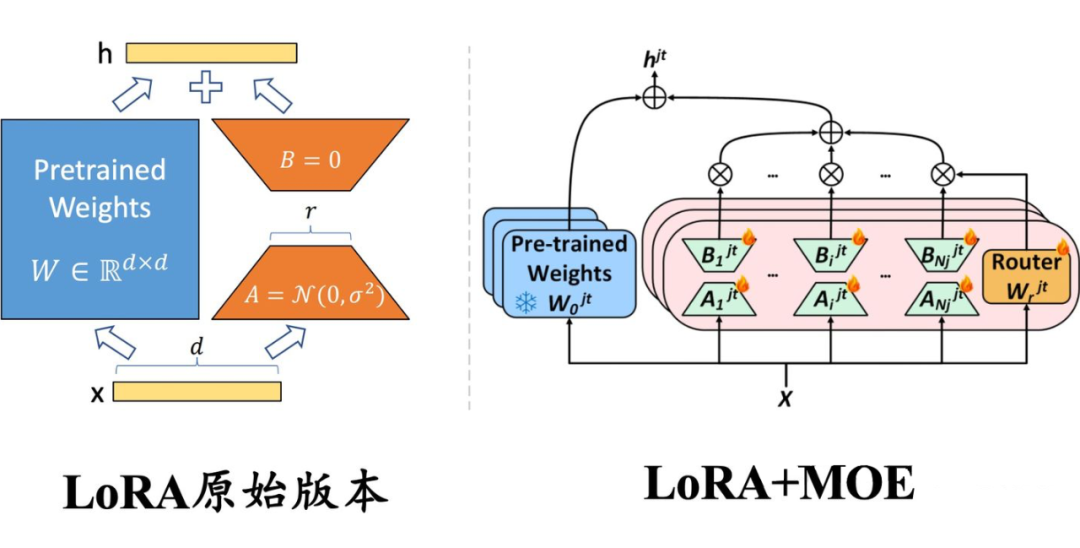
由于大模型全量微调时的显存占用过大,LORA、Adapter、IA3这些参数高效微调方法便成为了资源有限的机构和研究者微调大模型的标配。
PEFT方法的总体思路是冻结住大模型的主干参数,引入一小部分可训练的参数作为适配模块进行训练,以节省模型微调时的显存和参数存储开销。
传统上,LORA这类适配模块的参数和主干参数一样是稠密的,每个样本上的推理过程都需要用到所有的参数。
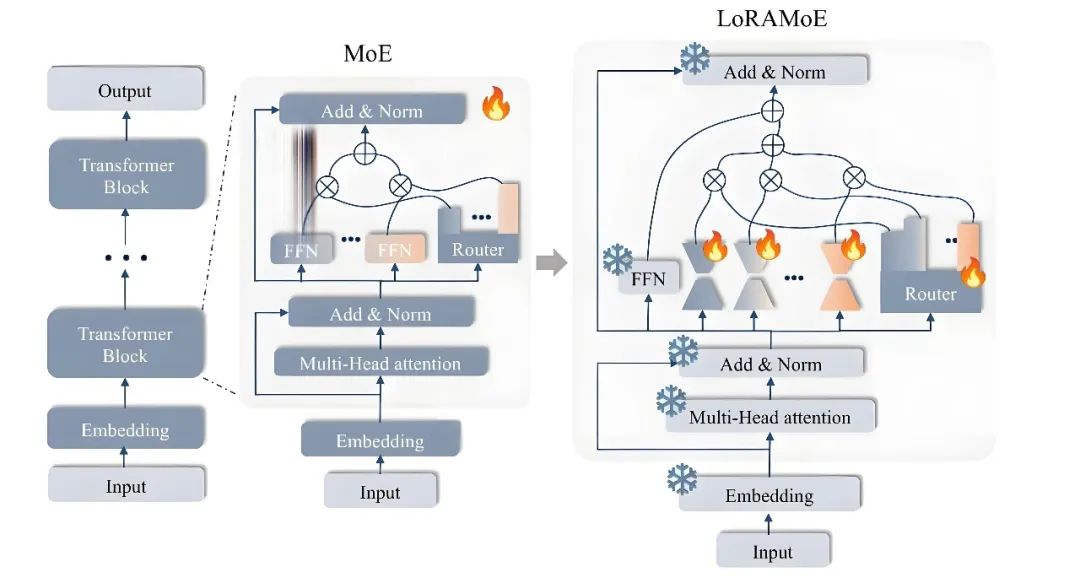
近来,大模型研究者们为了克服稠密模型的参数效率瓶颈,开始关注以Mistral、DeepseekMoE为代表的混合专家(MixureofExperts,简称MOE)模型框架。
在该框架下,模型的某个模块(如Transformer的某个FFN层)会存在多组形状相同的权重(称为专家),另外有一个路由模块(Router)接受原始输入、输出各专家的激活权重。
学习AI大模型是一项系统工程,需要时间和持续的努力。但随着技术的发展和在线资源的丰富,零基础的小白也有很好的机会逐步学习和掌握。【点击蓝字获取】
【2025最新】AI大模型全套学习籽料(可白嫖):LLM面试题+AI大模型学习路线+大模型PDF书籍+640套AI大模型报告等等,从入门到进阶再到精通,超全面存下吧!

欢迎加入 MCP 技术社区!与志同道合者携手前行,一同解锁 MCP 技术的无限可能!
更多推荐


 14
14 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)