【AI大模型】终于把 Transformer 中的键值(KV)缓存搞懂了!!
随着这些模型的复杂性和规模持续增长,优化推理速度的需求愈发迫切,尤其是在聊天应用等需要实时响应的场景中。键值(KV)缓存正是提升推理效率的一种巧妙优化策略。接下来,让我们深入探讨其工作原理以及适用场景。
前言
Transformer 架构无疑是现代深度学习领域最具变革性的创新之一。自 2017 年在著名论文 《Attention Is All You Need》 中提出以来,Transformer 已成为大多数语言相关建模的首选方法,包括所有大型语言模型 (LLM),例如 GPT 系列。
随着这些模型的复杂性和规模持续增长,优化推理速度的需求愈发迫切,尤其是在聊天应用等需要实时响应的场景中。键值(KV)缓存正是提升推理效率的一种巧妙优化策略。接下来,让我们深入探讨其工作原理以及适用场景。
Transformer 架构概述
在深入研究 KV 缓存之前,我们需要先了解一下 transformer 中使用的注意力机制。
了解它的工作原理是发现和理解 KV 缓存如何优化 transformer 推理的必要条件。
自注意力机制
自注意力机制允许模型在生成下一个标记时 “注意” 输入序列的特定部分。
例如,在生成句子 “She poured the coffee into the cup(她将咖啡倒入杯子)”时,模型可能会更加注意单词 “poured” 和 “coffee”,以预测下一个单词是“into”,因为这些单词为接下来可能出现的内容提供了上下文。
从数学上讲,自注意力的目标是将每个输入(嵌入的标记)转换为所谓的上下文向量,该向量结合了给定文本中所有输入的信息。
考虑文本“She poured coffee”。注意力将计算三个上下文向量,每个输入标记一个(我们假设标记是单词)。
为了计算上下文向量,自注意力机制计算三种中间向量:查询、键和值。
下图逐步展示了如何计算第二个单词 “poured” 的上下文向量。
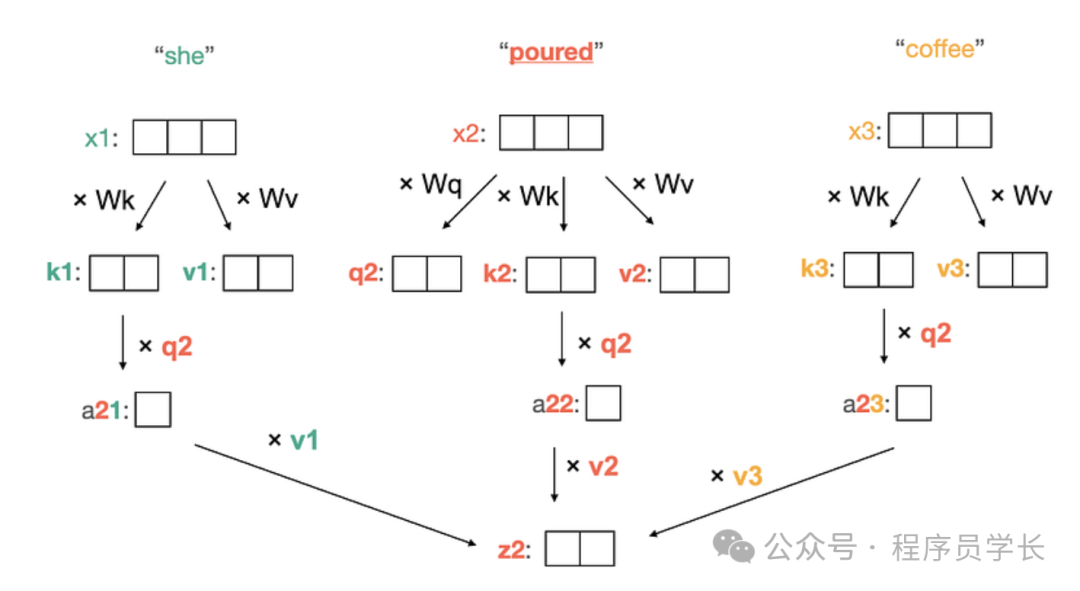
我们将三个标记化输入分别表示为x1、x2 和 x3。
图中将它们描绘为具有三个元素的向量,但实际上,它们的长度将有数百或数千个元素。
作为第一步,自注意力将每个输入分别与两个权重矩阵 和 相乘。现在正在计算上下文向量的输入(在我们的例子中是x2 )还与第三个权重矩阵 相乘。所有三个 W 矩阵都是你通常的神经网络权重,在学习过程中随机初始化和优化。此步骤的输出是每个输入的键(k)和值(v)向量,以及正在处理的输入的额外查询(q)向量。
在第二步中,将每个输入的键向量乘以正在处理的输入的查询向量(我们的q2)。然后对输出进行归一化以产生注意权重。在我们的示例中, 是输入“She” 和 “poured” 之间的注意权重。
最后,每个注意力权重都乘以其对应的值向量。然后将输出相加以产生上下文向量 z。在我们的示例中,上下文向量 z2 对应于输入x2,即“poured”。上下文向量是自注意力模块的输出。
import torch
class SelfAttention_v2(torch.nn.Module):
def __init__(self, d_in, d_out, qkv_bias=False):
super().__init__()
self.W_query = torch.nn.Linear(d_in, d_out, bias=qkv_bias)
self.W_key = torch.nn.Linear(d_in, d_out, bias=qkv_bias)
self.W_value = torch.nn.Linear(d_in, d_out, bias=qkv_bias)
def forward(self, x):
keys = self.W_key(x)
queries = self.W_query(x)
values = self.W_value(x)
attn_scores = queries @ keys.T
attn_weights = torch.softmax(
attn_scores / keys.shape[-1]**0.5, dim=-1
)
context_vec = attn_weights @ values
return context_vec
高级自注意力模块
上面描述的自注意力机制是最简单的原始形式。
当今最大的 LLM 通常使用略微修改的变体,这些变体通常在三个方面与我们的基本风格不同。
-
注意力是有因果关系的。
-
Dropout 用于注意力权重。
-
使用多头注意力机制。
因果注意力意味着模型在预测下一个单词时应该只考虑序列中的前一个标记,防止它“向前看”未来的单词。回到我们的例子 “She poured coffee”,当模型被赋予单词 “She” 并现在试图预测下一个单词(“poured”)时,它不应该计算或访问 “coffee” 和任何其他单词之间的注意力权重,因为 “coffee” 这个词还没有出现在文本中。因果注意力通常是通过用零掩盖注意力权重矩阵的“向前看”部分来实现的。
接下来,为了减少训练过程中的过度拟合,通常会对注意力权重应用 dropout。这意味着在每次前向传递中,其中一些权重会被随机设置为零。
最后,基本注意力可以称为单头注意力,这意味着只有一组 、 和 矩阵。增加模型容量的一个简单方法是切换到多头注意力。这归结为拥有多组 W 矩阵,从而拥有多个查询、键和值矩阵,以及每个输入的多个上下文向量。
此外,一些 Transformer 对注意力模块进行了额外的修改,以提高速度或准确性。
三种流行的 Transformer 是:
-
分组查询注意力
不再逐个查看每个输入标记,而是对标记进行分组,让模型可以同时关注相关的单词组,从而加快处理速度。
-
分页注意力
注意力被分解为“页面”或标记块,因此模型一次处理一页,从而使得非常长的序列的处理速度更快。
-
滑动窗口注意力
该模型仅关注每个标记周围固定“窗口”内的附近标记,因此它专注于局部上下文,而无需查看整个序列。
所有这些实现自注意力的先进方法都不会改变其基本前提和它所依赖的基本机制:总是需要将键乘以查询,然后再乘以值。事实证明,在推理时,这些乘法显示出严重的低效率。让我们看看为什么会这样。
什么是键值缓存
当我们通过传递 “She” 来提示模型开始生成时,它将生成一个单词,例如“poured”(为了避免干扰,我们继续假设一个 token 是一个单词)。然后,我们可以将 “She poured” 传递给模型,它会生成 “coffee”。接下来,我们传递 “She poured coffee” 并从模型中获取序列结束 token,表明它认为生成已完成。
这意味着我们已经运行了三次前向传递,每次将查询乘以键以获得注意力分数(稍后与值的乘法也是如此)。
在第一次正向传递中,只有一个输入标记(“She”),因此只有一个键向量和一个查询向量。我们将它们相乘以获得 q1k1 注意力得分。
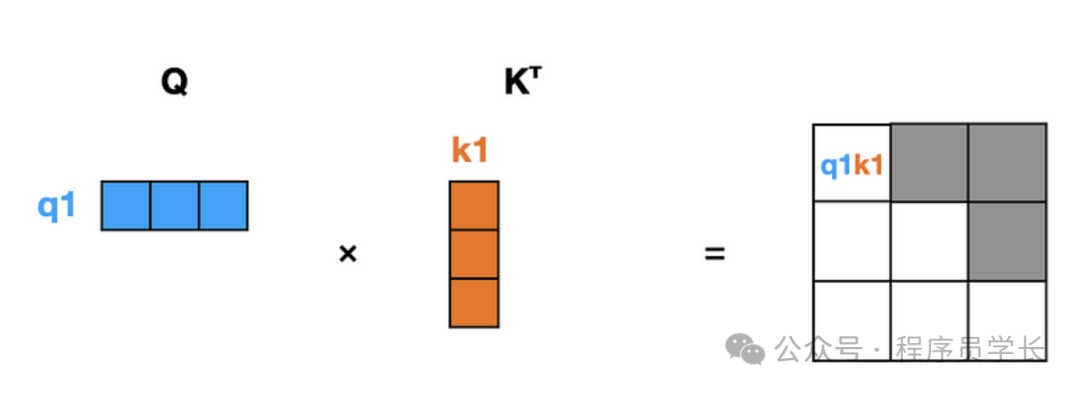
接下来,我们将 “She poured” 传递给模型。
现在它看到两个输入标记,因此我们的注意力模块内部的计算如下所示。
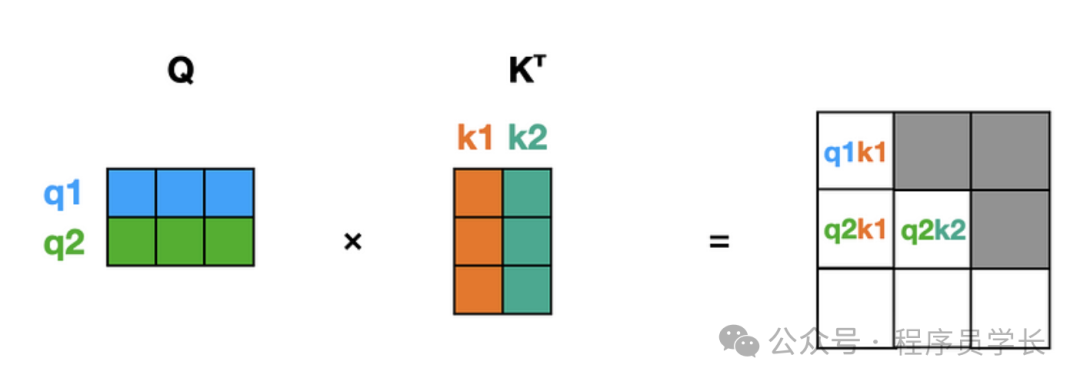
我们进行了乘法运算来计算三个项,但 q1k1 是不必要的计算,我们之前已经计算过了!
这个 q1k1 元素与上一次前向传递中的相同,因为:
-
q1 的计算方式是将输入(“she”)的嵌入乘以 Wq 矩阵
-
k1 的计算方式是将输入(“she”)的嵌入乘以 Wk 矩阵
-
嵌入和权重矩阵在推理时都是恒定的
注意注意力得分矩阵中灰色的条目被零掩盖以实现因果注意力。
最后,这是我们第三次前向传递中注意力模块内部的计算。
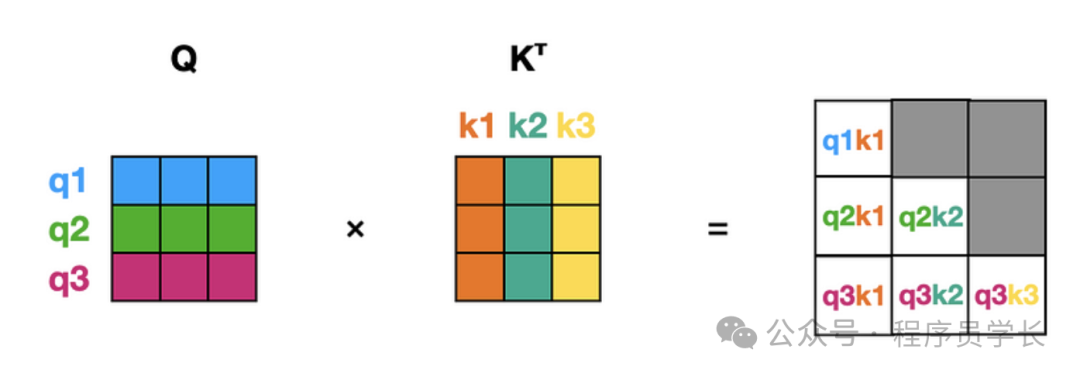
我们花费了计算力气来计算六个值,其中一半我们已经知道,不需要重新计算!
你可能已经对键值缓存的含义有所了解。在推理时,当我们计算键 ( K ) 和值 ( V ) 矩阵时,我们会将其元素存储在缓存中。缓存是一种辅助存储器,可以从中进行高速检索。在生成后续标记时,我们仅计算新标记的键和值。
例如,第三次前向传递在缓存的情况下看起来如下:
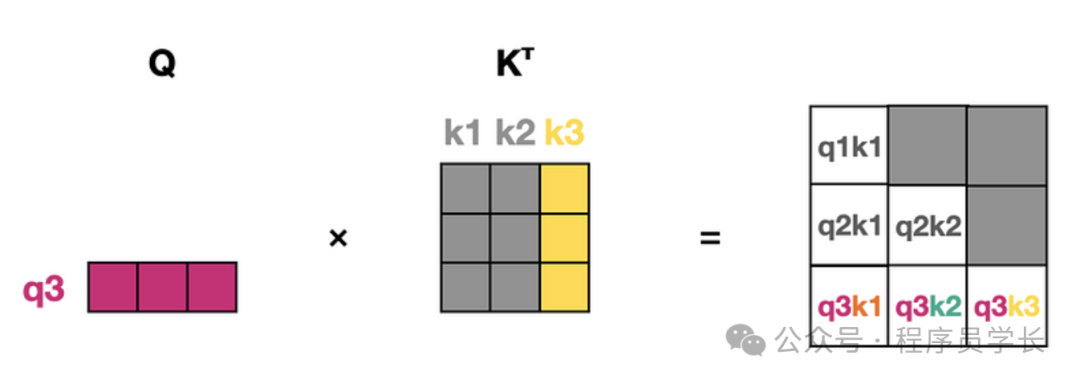
在处理第三个 token 时,我们不需要重新计算前一个 token 的注意力分数。我们可以从缓存中检索前两个 token 的键和值,从而节省计算时间。
评估键值缓存的影响
键值缓存可能会对推理时间产生重大影响。影响的大小取决于模型架构。可缓存的计算越多,减少推理时间的潜力就越大。
我们将首先定义一个计时器上下文管理器来计算生成时间。
import time
class Timer:
def __enter__(self):
self._start = time.time()
return self
def __exit__(self, exc_type, exc_value, traceback):
self._end = time.time()
self.duration = self._end - self._start
def get_duration(self) -> float:
return self.duration
接下来,我们从 Hugging Face Hub 加载模型,设置标记器并定义提示。
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
model_name = "EleutherAI/gpt-neo-1.3B"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model.to(device)
input_text = "Why is a pour-over the only acceptable way to drink coffee?"
最后,我们可以定义运行模型推理的函数。
def generate(use_cache):
input_ids = tokenizer.encode(
input_text,
return_tensors="pt").to(device)
output_ids = model.generate(
input_ids,
max_new_tokens=100,
use_cache=use_cache,
)
注意 use_cache 用于控制是否使用 KV 缓存。
通过此设置,我们可以测量有无 KV 缓存的平均生成时间。
import numpy as np
for use_cache in (False, True):
gen_times = []
for _ in range(1):
with Timer() as t:
generate(use_cache=use_cache)
print(t.get_duration())
gen_times += [t.get_duration()]
print(
f"Average inference time with use_cache={use_cache}: ",
f"{np.round(np.mean(gen_times), 2)} seconds",
)
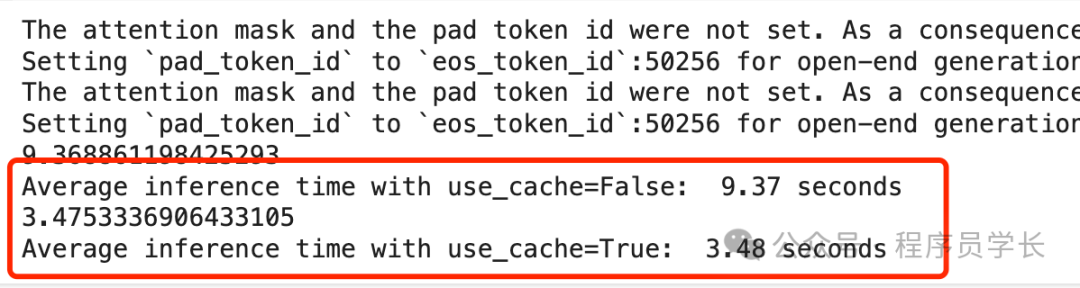
可以看到,缓存带来的加速几乎增加了三倍。
最后的最后
感谢你们的阅读和喜欢,作为一位在一线互联网行业奋斗多年的老兵,我深知在这个瞬息万变的技术领域中,持续学习和进步的重要性。
为了帮助更多热爱技术、渴望成长的朋友,我特别整理了一份涵盖大模型领域的宝贵资料集。
这些资料不仅是我多年积累的心血结晶,也是我在行业一线实战经验的总结。
这些学习资料不仅深入浅出,而且非常实用,让大家系统而高效地掌握AI大模型的各个知识点。如果你愿意花时间沉下心来学习,相信它们一定能为你提供实质性的帮助。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
大模型知识脑图
为了成为更好的 AI大模型 开发者,这里为大家提供了总的路线图。它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。
经典书籍阅读
阅读AI大模型经典书籍可以帮助读者提高技术水平,开拓视野,掌握核心技术,提高解决问题的能力,同时也可以借鉴他人的经验。对于想要深入学习AI大模型开发的读者来说,阅读经典书籍是非常有必要的。

实战案例
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

面试资料
我们学习AI大模型必然是想找到高薪的工作,下面这些面试题都是总结当前最新、最热、最高频的面试题,并且每道题都有详细的答案,面试前刷完这套面试题资料,小小offer,不在话下

640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

欢迎加入 MCP 技术社区!与志同道合者携手前行,一同解锁 MCP 技术的无限可能!
更多推荐


 7
7 0
0- 0



 已为社区贡献45条内容
已为社区贡献45条内容

所有评论(0)