Seed1.5-VL:20250511字节视觉-语言多模态大模型
我们介绍 Seed1.5-VL,这是一款旨在提升通用多模态理解与推理能力的视觉 - 语言基础模型。Seed1.5-VL 由一个 5.32 亿参数的视觉编码器和一个包含 200 亿活跃参数的混合专家(MoE)语言模型组成。尽管架构相对紧凑,它在广泛的公共视觉语言模型(VLM)基准和内部评估套件中表现出色,在 60 个公共基准中的 38 个上实现了最先进的性能。
技术报告:
摘要:
我们介绍 Seed1.5-VL,这是一款旨在提升通用多模态理解与推理能力的视觉 - 语言基础模型。Seed1.5-VL 由一个 5.32 亿参数的视觉编码器和一个包含 200 亿活跃参数的混合专家(MoE)语言模型组成。
尽管架构相对紧凑,它在广泛的公共视觉语言模型(VLM)基准和内部评估套件中表现出色,在 60 个公共基准中的 38 个上实现了最先进的性能。此外,在 GUI 控制和游戏等以代理为中心的任务中,Seed1.5-VL 优于包括 OpenAI CUA 和 Claude 3.7 在内的领先多模态系统。
除了视觉和视频理解,它还展示了强大的推理能力,尤其在视觉谜题等多模态推理挑战中表现卓越。我们相信这些能力将推动其在各种任务中的广泛应用。本报告主要全面回顾了我们在 Seed1.5-VL 的模型设计、数据构建和各阶段训练中的实践经验,希望能为进一步的研究提供启发。Seed1.5-VL 现已在火山引擎平台开放访问。
模型ID: doubao-1-5-thinking-vision-pro-250428
介绍:
视觉语言模型(VLMs)已成为使通用人工智能能够在开放的虚拟和物理环境中感知、推理和行动的基础范式。
与大型语言模型(LLMs)不同 —— 后者受益于丰富高质量的文本语料库(涵盖广泛的人类知识),VLMs 缺乏同样丰富多样的视觉语言注释,尤其是基于低级感知现象的概念。此外,多模态数据的异构性在训练和推理中引入了额外的复杂性,使数据管道设计、并行训练策略和评估协议变得复杂。
为解决高质量注释的稀缺性问题,我们开发了一套多样化的数据合成管道,针对关键能力进行预训练(包括光学字符识别(OCR)、视觉定位、计数、视频理解和长尾知识),并在训练后阶段针对视觉谜题和游戏进行优化。Seed1.5-VL 在数万亿跨模态标记(包括图像、视频、文本和人机交互数据)上进行预训练,以获取广泛的视觉知识并掌握核心视觉能力。我们还探讨了预训练阶段的规模扩展特性。在训练后阶段,我们结合人类反馈和可验证的奖励信号,进一步增强其通用推理能力。
我们还解决了高效训练非对称架构的大规模多模态模型的挑战,尤其是视觉编码器和语言模型之间的不平衡问题。我们的贡献包括:(1)针对这种非对称性优化的新型混合并行方案;(2)用于平衡 GPU 工作负载的视觉标记重新分配策略。此外,我们实现了定制化的数据加载器,以最小化 3D 并行下的 I/O 瓶颈。这些创新与标准系统级优化(如内核融合、选择性激活检查点和卸载)相结合,共同提高了整体训练吞吐量。
为了全面了解 VLM 能力的现状并为模型改进提供研究方向,我们在广泛的公共和内部基准上对 Seed1.5-VL 进行了评估,涵盖视觉推理、定位、计数、视频理解和计算机应用等多项任务。具体而言,我们在 60 个公共基准上报告了结果,其中 Seed1.5-VL 在 38 个基准上实现了最先进的性能,包括 34 个视觉语言基准中的 21 个、19 个视频基准中的 14 个,以及 7 个 GUI 代理任务中的 3 个。除了基准性能外,我们还将 Seed1.5-VL 部署在内部聊天机器人系统中,以监控其在动态交互式环境中的实际应用和分布外(OOD)性能。
尽管功能强大,Seed1.5-VL 仍保持紧凑高效的架构,包括 5.32 亿参数的视觉编码器和 200 亿活跃参数的语言模型。这种精简设计降低了推理成本和计算需求,使其非常适合交互式应用。Seed1.5-VL 的高效性通过 API 服务扩大了用户覆盖范围,并为豆包聊天机器人提供了更流畅的用户体验。Seed1.5-VL 即将在火山引擎 API 平台 1 上开放访问。
结构:
包含3部分:视觉编码器,MLP适配器,LLM;
视觉编码器原生支持动态图像分辨率,并采用 2D RoPE [126] 进行位置编码,能够灵活适应任意尺寸的图像。为了提高计算效率,该架构对相邻的 2×2 特征补丁应用平均池化;
随后,两层 MLP 对这些池化后的特征进行处理,然后输入到 LLM 中。
无编码器架构 [1,23,127] 未被考虑,因为视觉编码器提供了高效的图像压缩能力,能够用更少的标记实现高分辨率图像表示。整体架构如图 1 所示。
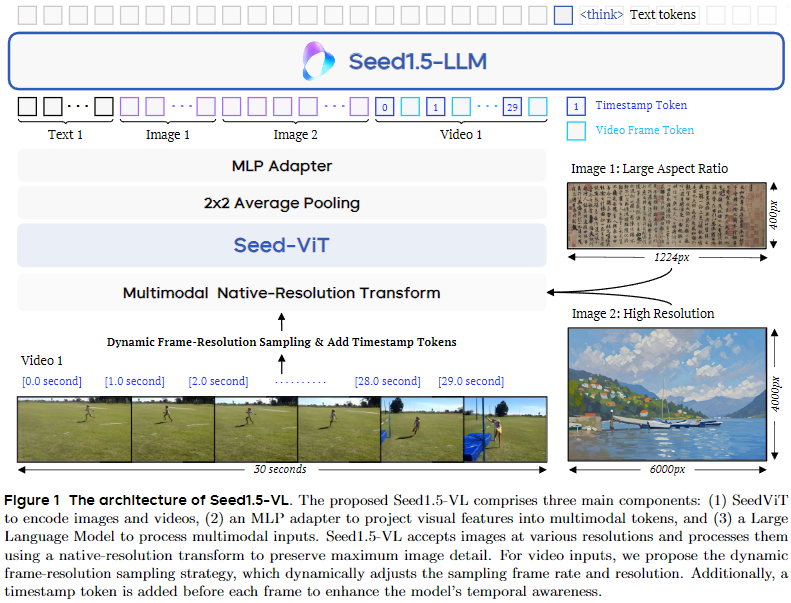
视觉编码器:
结构:

我们的视觉编码器旨在适应不同尺寸的输入图像。首先,输入图像会经过双线性插值预处理步骤,将分辨率调整为最接近 28×28 像素的倍数。【这是实现动态分辨率的关键吧】随后,每张图像被分割为一系列不重叠的 14×14 像素补丁序列。根据 NaViT [20] 提出的方法,我们将多个输入图像的补丁序列连接成一个统一序列。这些原始补丁序列通过线性补丁嵌入层投影到嵌入空间的标记中,然后输入到 Transformer 块中。为确保批次序列中属于同一图像的标记不会关注其他图像的标记,我们在 Transformer 块的自注意力计算过程中使用适当的注意力掩码。最后,对输出的补丁嵌入应用 2×2 平均池化操作,再将其传递到上述的 MLP 适配器和语言模型(LLM)。
ViT 预训练流程分为三个阶段:(i) 带 2D RoPE 的掩码图像建模(MIM)[145],(ii) 原生分辨率对比学习,(iii) 全模态预训练。以下将详细介绍每个阶段。
编辑
分享
将“The architecture of Seed1.5-VL consists of three components: a vision encoder, an MLP adapter, and a large language model (LLM).”翻译成中文。
“动态图像分辨率”英文是什么?
“MLP”的全称是什么?
Seed1.5-VL 包含一个 5.32 亿参数的视觉编码器,以及一个激活参数规模达 200 亿的混合专家(MoE)大语言模型。
模型由以下三个核心组件组成:
1)SeedViT:用于对图像和视频进行编码;
2)MLP 适配器:将视觉特征投射为多模态 token ;
3)大语言模型:用于处理多模态输入并执行推理。
Seed1.5-VL 支持多种分辨率的图像输入,并通过原生分辨率变换(native-resolution transform)确保最大限度保留图像细节。在视频处理方面,我们提出了一种动态帧分辨率采样策略(dynamic frame-resolution sampling strategy),能够根据需要动态调整采样帧率和分辨率。此外,为了增强模型的时间信息感知能力,在每帧图像之前引入了时间戳标记(timestamp token)。
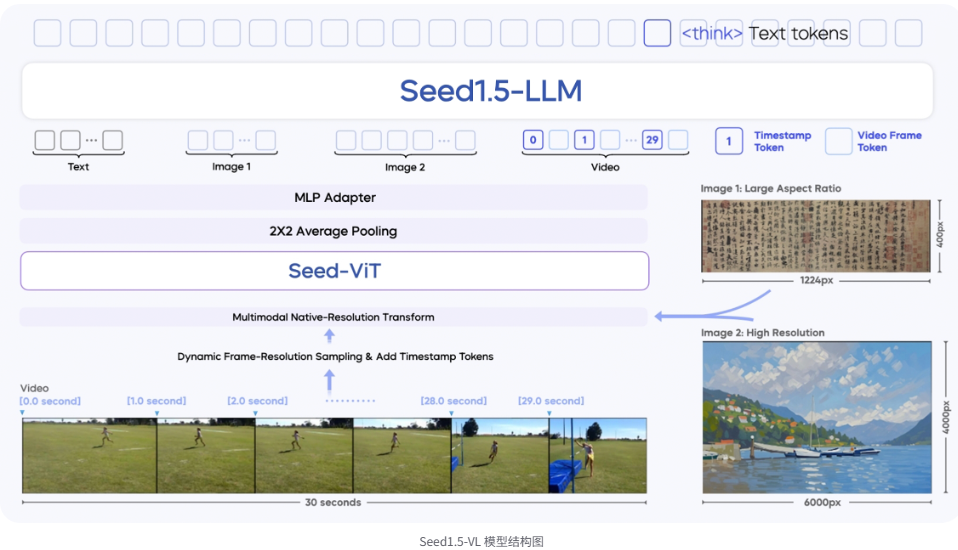
其中,右图分别为大长宽比图片和高分辨率图片。
预训练:
Seed1.5-VL 的预训练语料库包含 3 万亿个多样化且高质量的源标记(source tokens)。这些数据根据模型目标能力的需求进行了分类。
后训练:
Seed1.5-VL 的后训练过程采用了结合拒绝采样(rejection sampling)和在线强化学习(online reinforcement learning)的迭代更新方法。我们构建了一条完整的数据 pipeline,用于收集和筛选复杂提示,以增强后训练阶段的数据质量。
强化学习实现的一个关键特点是,监督信号通过奖励模型(reward models)和规则验证器(rule verifiers)仅作用于模型生成的最终输出结果。我们特意避免对模型的详细链式思维推理(chain-of-thought reasoning)过程进行监督。这一区别在插图的右侧部分得到了重点说明。
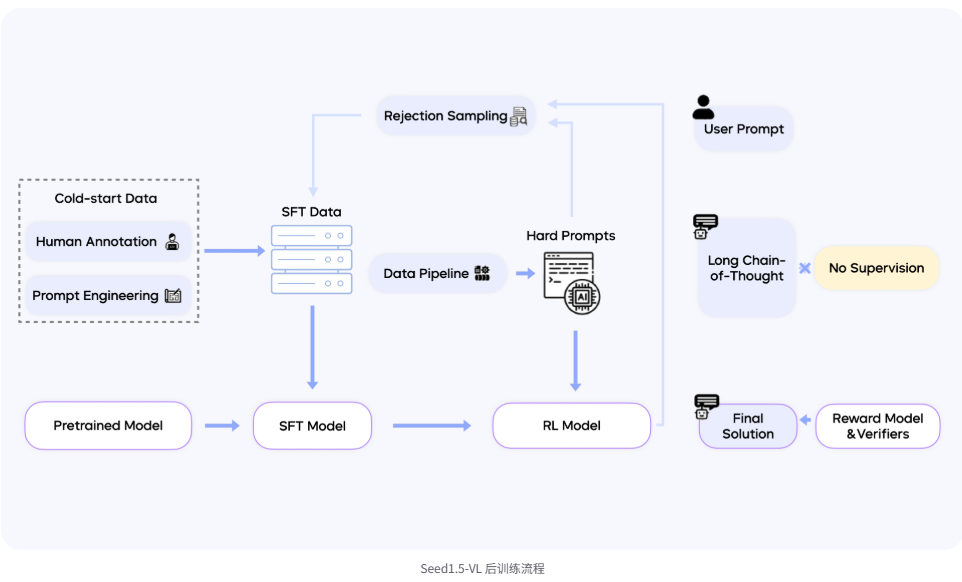
- Hard Prompts:聚焦 “长链思考(Long Chain-of-Thought)”“多模态深度推理” 等高难度场景,逼迫模型分解复杂任务、逐步推导(比如 “分析古画→关联历史背景→对比视频中相似场景→输出文化演变结论”)。
5. 无监督长链思考(Long Chain-of-Thought + No Supervision)
模型在无显式监督下,自主触发 “多步骤推理(Chain-of-Thought)”:
- 面对 “分析古画历史背景 + 视频场景演变” 这类复杂任务,模型会分解为「识别古画元素→检索历史知识→分析视频时序变化→综合推导结论」等多步,无监督激活内在推理能力。
- 这一步是对 “有监督训练” 的补充,让模型在开放域任务中也能自主解决问题(类似人类 “举一反三” 的能力)。
基准测试
Seed1.5-VL 在 60 项公开基准测试中取得了 38 项的最新最优性能(state-of-the-art performance),其中包括 19 项视频基准测试中的 14 项,以及 7 项 GUI 代理任务中的 3 项
局限性
尽管 Seed1.5-VL 展现了出色能力,但仍存在一些局限性,尤其是在细粒度视觉感知、三维空间推理以及复杂组合搜索任务方面。解决这些挑战是我们持续研究的核心部分,研究方向包括统一现有模型能力与图像生成,以及引入更健全的工具使用机制。

欢迎加入 MCP 技术社区!与志同道合者携手前行,一同解锁 MCP 技术的无限可能!
更多推荐


 15
15 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)