使用国内大模型API进行GraphRAG 2.1.0本地部署教程
之前运行graphrag踩过各种坑,这是笔者第一次写文章,主要是想分享一下,避免后来人像我一样一步一踩。大家有什么问题欢迎在评论区留言。
2025新版GraphRAG 2.1.0本地部署教程,使用国内大模型API
前言
最近在部署GraphRAG,踩了不少坑,参考了不少同行的文件,这里简单分享一下,并附部署全过程流程,帮助大家避免踩坑。
提示:以下是本篇文章正文内容,下面案例可供参考
一、准备工作
1.虚拟环境
这个不用过多赘述,conda创建,或者直接在pycham中默认创建一个。笔者使用的python环境为3.12.8。
2.获得代码
这里笔者是直接去GitHub上面下载压缩包,粘到项目中,对于初学者而言我个人觉得反而更方便一些。
3.安装依赖
安装poetry(如果没有),再使用poetry安装依赖
pip install poetry
poetry install
4.数据准备
这里随便整一篇即可,我随便找的放到了创建的文件夹graphrag_index下的input中。
二、关键步骤
1.初始化项目
执行初始化命令(注意不同版本命令有出入):
graphrag init --root ./tets/graphrag_index #根据自己路径改
运行完上述项目后会得到一个.env文件和一个settings.yaml文件,其他不用管。
2.修改配置
我这里使用的是阿里云百炼的api,对于初学者而言比较省事,有些中转的国外GPT的密匙反而更容易报错,也可以采用ollama,可以参考这位的:https://blog.csdn.net/m0_54356251/article/details/146074188
①修改.env文件,换成自己的api密匙。这里要注意,apikey外面那两个“<>”大概率是要去掉的,不去掉后面运行索引,验证会失败。
②修改settings.yaml文件,如下(标注的地方都要改):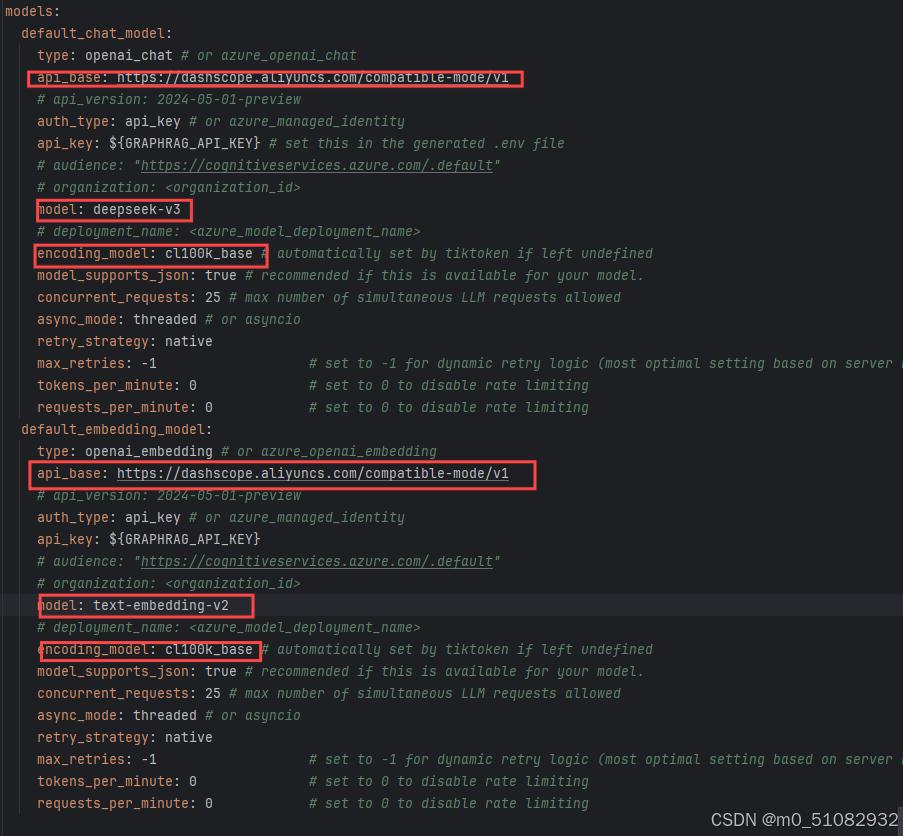 使用阿里的向量模型还有个问题,我这里使用的text-embedding-v2,原本使用v3到最后会报错,笔者猜测因为最大行数的限制。另外切片也需要修改一下,改小一点不要使用默认:
使用阿里的向量模型还有个问题,我这里使用的text-embedding-v2,原本使用v3到最后会报错,笔者猜测因为最大行数的限制。另外切片也需要修改一下,改小一点不要使用默认: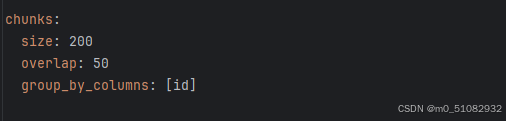
修改后如下整体如下所示:
### This config file contains required core defaults that must be set, along with a handful of common optional settings.
### For a full list of available settings, see https://microsoft.github.io/graphrag/config/yaml/
### LLM settings ###
## There are a number of settings to tune the threading and token limits for LLM calls - check the docs.
models:
default_chat_model:
type: openai_chat # or azure_openai_chat
api_base: https://dashscope.aliyuncs.com/compatible-mode/v1
# api_version: 2024-05-01-preview
auth_type: api_key # or azure_managed_identity
api_key: ${GRAPHRAG_API_KEY} # set this in the generated .env file
# audience: "https://cognitiveservices.azure.com/.default"
# organization: <organization_id>
model: deepseek-v3
# deployment_name: <azure_model_deployment_name>
encoding_model: cl100k_base # automatically set by tiktoken if left undefined
model_supports_json: true # recommended if this is available for your model.
concurrent_requests: 25 # max number of simultaneous LLM requests allowed
async_mode: threaded # or asyncio
retry_strategy: native
max_retries: -1 # set to -1 for dynamic retry logic (most optimal setting based on server response)
tokens_per_minute: 0 # set to 0 to disable rate limiting
requests_per_minute: 0 # set to 0 to disable rate limiting
default_embedding_model:
type: openai_embedding # or azure_openai_embedding
api_base: https://dashscope.aliyuncs.com/compatible-mode/v1
# api_version: 2024-05-01-preview
auth_type: api_key # or azure_managed_identity
api_key: ${GRAPHRAG_API_KEY}
# audience: "https://cognitiveservices.azure.com/.default"
# organization: <organization_id>
model: text-embedding-v2
# deployment_name: <azure_model_deployment_name>
encoding_model: cl100k_base # automatically set by tiktoken if left undefined
model_supports_json: true # recommended if this is available for your model.
concurrent_requests: 25 # max number of simultaneous LLM requests allowed
async_mode: threaded # or asyncio
retry_strategy: native
max_retries: -1 # set to -1 for dynamic retry logic (most optimal setting based on server response)
tokens_per_minute: 0 # set to 0 to disable rate limiting
requests_per_minute: 0 # set to 0 to disable rate limiting
### Input settings ###
input:
type: file # or blob
file_type: text # [csv, text, json]
base_dir: "input"
chunks:
size: 200
overlap: 50
group_by_columns: [id]
### Output/storage settings ###
## If blob storage is specified in the following four sections,
## connection_string and container_name must be provided
output:
type: file # [file, blob, cosmosdb]
base_dir: "output"
cache:
type: file # [file, blob, cosmosdb]
base_dir: "cache"
reporting:
type: file # [file, blob, cosmosdb]
base_dir: "logs"
vector_store:
default_vector_store:
type: lancedb
db_uri: output\lancedb
container_name: default
overwrite: True
### Workflow settings ###
embed_text:
model_id: default_embedding_model
vector_store_id: default_vector_store
extract_graph:
model_id: default_chat_model
prompt: "prompts/extract_graph.txt"
entity_types: [organization,person,geo,event]
max_gleanings: 1
summarize_descriptions:
model_id: default_chat_model
prompt: "prompts/summarize_descriptions.txt"
max_length: 500
extract_graph_nlp:
text_analyzer:
extractor_type: regex_english # [regex_english, syntactic_parser, cfg]
cluster_graph:
max_cluster_size: 10
extract_claims:
enabled: false
model_id: default_chat_model
prompt: "prompts/extract_claims.txt"
description: "Any claims or facts that could be relevant to information discovery."
max_gleanings: 1
community_reports:
model_id: default_chat_model
graph_prompt: "prompts/community_report_graph.txt"
text_prompt: "prompts/community_report_text.txt"
max_length: 2000
max_input_length: 8000
embed_graph:
enabled: false # if true, will generate node2vec embeddings for nodes
umap:
enabled: false # if true, will generate UMAP embeddings for nodes (embed_graph must also be enabled)
snapshots:
graphml: false
embeddings: false
### Query settings ###
## The prompt locations are required here, but each search method has a number of optional knobs that can be tuned.
## See the config docs: https://microsoft.github.io/graphrag/config/yaml/#query
local_search:
chat_model_id: default_chat_model
embedding_model_id: default_embedding_model
prompt: "prompts/local_search_system_prompt.txt"
global_search:
chat_model_id: default_chat_model
map_prompt: "prompts/global_search_map_system_prompt.txt"
reduce_prompt: "prompts/global_search_reduce_system_prompt.txt"
knowledge_prompt: "prompts/global_search_knowledge_system_prompt.txt"
drift_search:
chat_model_id: default_chat_model
embedding_model_id: default_embedding_model
prompt: "prompts/drift_search_system_prompt.txt"
reduce_prompt: "prompts/drift_search_reduce_prompt.txt"
basic_search:
chat_model_id: default_chat_model
embedding_model_id: default_embedding_model
prompt: "prompts/basic_search_system_prompt.txt"
3.进行索引
建立索引,运行如下命令:
graphrag index --root ./tets/graphrag_index
4.查询
可以先进行graphrag query --help查看一下查询有哪些类型,再选择。这里推荐看另外一篇同行的文章 https://blog.csdn.net/m0_54356251/article/details/146074188我这里进行了全局查询如下:
graphrag query --root ./tets/graphrag_index --method global --query "这篇文章讲了什么"
总结
之前运行graphrag踩过各种坑,这是笔者第一次写文章,主要是想分享一下,避免后来人像我一样一步一踩。大家有什么问题欢迎在评论区留言。

欢迎加入 MCP 技术社区!与志同道合者携手前行,一同解锁 MCP 技术的无限可能!
更多推荐


 17
17 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)