大模型MCP 教程:从原理到实战的全攻略
MCP(Model Context Protocol) 由 Anthropic 于 2024 年底开源,其目标是为大模型与外部工具 / 数据源之间建立起一座标准化的桥梁,解决兼容性和互操作性问题。从本质上讲,MCP 就像是 AI 领域的 “USB-C 接口”,它定义了一套统一的通信标准,使得大模型能够通过标准化接口连接任意工具,而无需为每个工具单独开发适配代码。。
一、什么是MCP
1.1 核心概念
MCP(Model Context Protocol) 由 Anthropic 于 2024 年底开源,其目标是为大模型与外部工具 / 数据源之间建立起一座标准化的桥梁,解决兼容性和互操作性问题。从本质上讲,MCP 就像是 AI 领域的 “USB-C 接口”,它定义了一套统一的通信标准,使得大模型能够通过标准化接口连接任意工具,而无需为每个工具单独开发适配代码。
例如,在传统的 AI 开发中,如果要让大模型调用 GitHub 的 API 获取代码仓库信息,以及连接数据库查询数据,可能需要分别为这两个操作编写不同的接口代码,而且不同大模型的接口实现方式可能各不相同。但有了 MCP,无论是 Claude 还是 GPT-4,都可以通过 MCP 的标准化接口(如 JSON-RPC 2.0)来调用 GitHub 和数据库,大大简化了开发流程,提高了效率。
1.2 总体架构
MCP 的核心是客户端-服务器架构,其中主机应用程序可以连接到多个服务器: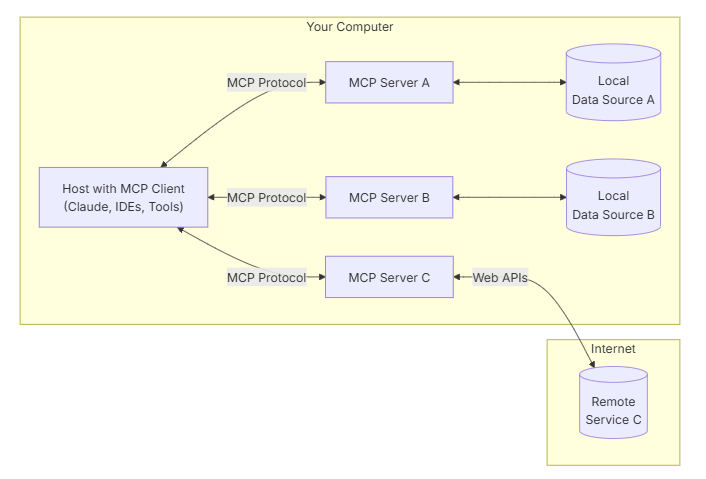
MCP 的技术架构基于经典的客户端 - 服务器模式,主要由三个关键组件构成:MCP Client、MCP Server 和标准协议层。
- MCP Client:运行在大模型所在的环境中,负责与大模型进行交互,并将大模型的请求转发给 MCP Server。它就像是大模型的 “代言人”,理解大模型的需求,并将其转化为与外部交互的指令。例如,当用户向 Claude 提出查询 GitHub 上某个项目最新提交记录的请求时,Claude 所在的运行环境中的 MCP Client 会接收这个请求。
- MCP Server:负责封装外部工具的服务,将其暴露为 MCP 可以理解的接口。每个 MCP Server 专注于特定的功能,比如有的 MCP Server 专门处理文件系统的读写操作,有的则负责与数据库进行交互。以 GitHub 为例,对应的 MCP Server 会实现与 GitHub API 交互的逻辑,接收 MCP Client 传来的请求,执行相应的 API 调用(如获取仓库信息、提交记录等),并将结果返回给 MCP Client。
- 标准协议层:采用 JSON-RPC 2.0 等标准协议,负责规范 MCP Client 和 MCP Server 之间的通信格式和流程。这确保了不同的 MCP 组件之间能够准确无误地进行信息交换。例如,MCP Client 向 MCP Server 发送的请求和 MCP Server 返回的响应都遵循 JSON-RPC 2.0 的格式,这样无论大模型和外部工具如何变化,只要它们都遵循 MCP 的标准协议,就能够实现无缝对接。
1.3 支持的通信协议
| 协议类型 | 应用场景 | 数据格式 | 典型实现案例 |
|---|---|---|---|
| Stdio | 本地工具调用 | JSON-LD | Cursor代码生成插件 |
| HTTP/2 | 远程服务交互 | JSON-RPC 2.0 | Claude企业知识库连接 |
| SSE | 实时数据流处理 | Server-Sent Events | 金融行情数据订阅 |
二、MCP与Function Calling对比
以下是MCP与Function Call的对比表格:
| 对比维度 | MCP | Function Call |
|---|---|---|
| 接口类型 | 开放标准协议(JSON-RPC 2.0) | 大模型专有接口(如GPT-4函数调用) |
| 适配难度 | 标准化协议,开发一次即可复用 | 需为每个模型单独适配函数定义 |
| 多模型支持 | 跨模型兼容(Claude/GPT-4/Llama3) | 仅支持特定模型(如GPT-4) |
| 厂商依赖 | 无,开放生态 | 强依赖模型厂商(如OpenAI) |
| 工具复用性 | 统一工具接口,跨场景调用 | 工具绑定模型,需重复开发 |
| 适用场景 | 复杂工具链集成、企业级应用 | 简单任务快速执行、轻量级调用 |
互补价值说明:
- MCP:提供标准化的“操作系统”级接口,解决跨模型/跨工具的互操作性问题,适合构建复杂AI Agent系统
- Function Call:作为“汇编指令”级优化,在特定模型环境中实现高效任务执行,适合快速验证业务逻辑
- 协同模式:MCP定义接口规范,Function Call提供性能优化,共同构建“协议层+执行层”的AI开发双栈架构
三、实战案例
1、安装依赖
openai>=1.0.0
click>=8.1.0
httpx>=0.24.0
anyio>=4.0.0
starlette>=0.36.0
uvicorn>=0.27.0
python-dotenv>=1.0.0
mcp>=1.4.1,<1.5
2、开发 MCP server
2.1 定义三个函数作为工具
async def fetch_website(
url: str,
) -> list[types.TextContent | types.ImageContent | types.EmbeddedResource]:
headers = {
"User-Agent": "MCP Test Server (github.com/modelcontextprotocol/python-sdk)"
}
async with httpx.AsyncClient(follow_redirects=True, headers=headers) as client:
response = await client.get(url)
response.raise_for_status()
return [types.TextContent(type="text", text=response.text)]
async def fetch_weather(city: str) -> types.TextContent:
"""获取城市天气信息"""
data = {
"name": "北京",
"main": {
"temp": 20,
"humidity": 50
},
"weather": [
{"description": "晴"}
]
}
weather_info = (
f"城市: {data['name']}\n"
f"温度: {data['main']['temp']}°C\n"
f"天气: {data['weather'][0]['description']}\n"
f"湿度: {data['main']['humidity']}%"
)
return types.TextContent(type="text", text=weather_info)
async def calculate(num1: int, num2: int) -> types.TextContent:
return types.TextContent(type="text", text=f"结果: {num1 + num2}")
2.2 定义tools 和 tool调用
@app.call_tool()
async def fetch_tool(
name: str,
arguments: dict
) -> list[types.TextContent | types.ImageContent | types.EmbeddedResource]:
if name == "fetch":
if "url" not in arguments:
raise ValueError("Missing required argument 'url'")
return await fetch_website(arguments["url"])
elif name == "weather":
if "city" not in arguments:
raise ValueError("Missing required argument 'city'")
return [await fetch_weather(arguments["city"])]
elif name == "calculate":
if "num1" not in arguments or "num2" not in arguments:
raise ValueError("Missing required arguments 'num1' or 'num2'")
return [await calculate(arguments["num1"], arguments["num2"])]
else:
raise ValueError(f"Unknown tool: {name}")
@app.list_tools()
async def list_tools() -> list[types.Tool]:
return [
types.Tool(
name="fetch",
description="@app.call_tool()
async def fetch_tool(
name: str,
arguments: dict
) -> list[types.TextContent | types.ImageContent | types.EmbeddedResource]:
if name == "fetch":
if "url" not in arguments:
raise ValueError("Missing required argument 'url'")
return await fetch_website(arguments["url"])
elif name == "weather":
if "city" not in arguments:
raise ValueError("Missing required argument 'city'")
return [await fetch_weather(arguments["city"])]
elif name == "calculate":
if "num1" not in arguments or "num2" not in arguments:
raise ValueError("Missing required arguments 'num1' or 'num2'")
return [await calculate(arguments["num1"], arguments["num2"])]
else:
raise ValueError(f"Unknown tool: {name}")
@app.list_tools()
async def list_tools() -> list[types.Tool]:
return [
types.Tool(
name="fetch",
description="Fetches a website and returns its content",
inputSchema={
"type": "object",
"required": ["url"],
"properties": {
"url": {
"type": "string",
"description": "URL to fetch",
}
},
},
),
types.Tool(
name="weather",
description="获取指定城市的天气信息",
inputSchema={
"type": "object",
"required": ["city"],
"properties": {
"city": {
"type": "string",
"description": "城市名称(例如:Beijing,CN)",
}
},
},
),
types.Tool(
name="calculate",
description="计算两个数的和",
inputSchema={
"type": "object",
"required": ["num1", "num2"],
"properties": {
"num1": {"type": "number", "description": "第一个数"},
"num2": {"type": "number", "description": "第二个数"}
}
},
),
]
",
inputSchema={
"type": "object",
"required": ["url"],
"properties": {
"url": {
"type": "string",
"description": "URL to fetch",
}
},
},
),
types.Tool(
name="weather",
description="获取指定城市的天气信息",
inputSchema={
"type": "object",
"required": ["city"],
"properties": {
"city": {
"type": "string",
"description": "城市名称(例如:Beijing,CN)",
}
},
},
),
types.Tool(
name="calculate",
description="计算两个数的和",
inputSchema={
"type": "object",
"required": ["num1", "num2"],
"properties": {
"num1": {"type": "number", "description": "第一个数"},
"num2": {"type": "number", "description": "第二个数"}
}
},
),
]
2.3 完整的mcp server 实现
import sys
print("Python path:", sys.path) # 打印 Python 路径
print("Current executable:", sys.executable) # 打印当前 Python 解释器路径
import anyio
import click
import httpx
import os
from typing import Optional
import mcp.types as types
from mcp.server.lowlevel import Server
from starlette.middleware.cors import CORSMiddleware
import logging
async def fetch_website(
url: str,
) -> list[types.TextContent | types.ImageContent | types.EmbeddedResource]:
headers = {
"User-Agent": "MCP Test Server (github.com/modelcontextprotocol/python-sdk)"
}
async with httpx.AsyncClient(follow_redirects=True, headers=headers) as client:
response = await client.get(url)
response.raise_for_status()
return [types.TextContent(type="text", text=response.text)]
async def fetch_weather(city: str) -> types.TextContent:
"""获取城市天气信息"""
data = {
"name": "北京",
"main": {
"temp": 20,
"humidity": 50
},
"weather": [
{"description": "晴"}
]
}
weather_info = (
f"城市: {data['name']}\n"
f"温度: {data['main']['temp']}°C\n"
f"天气: {data['weather'][0]['description']}\n"
f"湿度: {data['main']['humidity']}%"
)
return types.TextContent(type="text", text=weather_info)
async def calculate(num1: int, num2: int) -> types.TextContent:
return types.TextContent(type="text", text=f"结果: {num1 + num2}")
@click.command()
@click.option("--port", default=8000, help="Port to listen on for SSE")
@click.option(
"--transport",
type=click.Choice(["stdio", "sse"]),
default="stdio",
help="Transport type",
)
def main(port: int, transport: str) -> int:
app = Server("mcp-website-fetcher")
@app.call_tool()
async def fetch_tool(
name: str,
arguments: dict
) -> list[types.TextContent | types.ImageContent | types.EmbeddedResource]:
if name == "fetch":
if "url" not in arguments:
raise ValueError("Missing required argument 'url'")
return await fetch_website(arguments["url"])
elif name == "weather":
if "city" not in arguments:
raise ValueError("Missing required argument 'city'")
return [await fetch_weather(arguments["city"])]
elif name == "calculate":
if "num1" not in arguments or "num2" not in arguments:
raise ValueError("Missing required arguments 'num1' or 'num2'")
return [await calculate(arguments["num1"], arguments["num2"])]
else:
raise ValueError(f"Unknown tool: {name}")
@app.list_tools()
async def list_tools() -> list[types.Tool]:
return [
types.Tool(
name="fetch",
description="获取网页内容",
inputSchema={
"type": "object",
"required": ["url"],
"properties": {
"url": {
"type": "string",
"description": "URL to fetch",
}
},
},
),
types.Tool(
name="weather",
description="获取指定城市的天气信息",
inputSchema={
"type": "object",
"required": ["city"],
"properties": {
"city": {
"type": "string",
"description": "城市名称(例如:Beijing,CN)",
}
},
},
),
types.Tool(
name="calculate",
description="计算两个数的和",
inputSchema={
"type": "object",
"required": ["num1", "num2"],
"properties": {
"num1": {"type": "number", "description": "第一个数"},
"num2": {"type": "number", "description": "第二个数"}
}
},
),
]
if transport == "sse":
from mcp.server.sse import SseServerTransport
from starlette.applications import Starlette
from starlette.routing import Mount, Route
sse = SseServerTransport("/messages/")
async def handle_sse(request):
async with sse.connect_sse(
request.scope, request.receive, request._send
) as streams:
await app.run(
streams[0], streams[1], app.create_initialization_options()
)
starlette_app = Starlette(
debug=True,
routes=[
Route("/sse", endpoint=handle_sse),
Mount("/messages/", app=sse.handle_post_message),
],
)
# 添加 CORS 中间件
starlette_app.add_middleware(
CORSMiddleware,
allow_origins=["*"],
allow_credentials=True,
allow_methods=["*"],
allow_headers=["*"],
)
import uvicorn
logging.info(f"Starting SSE server on port {port}")
uvicorn.run(starlette_app, host="0.0.0.0", port=port)
else:
from mcp.server.stdio import stdio_server
async def arun():
async with stdio_server() as streams:
await app.run(
streams[0], streams[1], app.create_initialization_options()
)
anyio.run(arun)
return 0
if __name__ == "__main__":
sys.exit(main())
- sys:用于获取 Python 解释器的相关信息,像 Python 模块搜索路径 sys.path 以及当前 Python 解释器的路径 sys.executable。
- anyio:提供异步 I/O 功能,可用于编写异步代码。
- click:用于创建命令行接口。
- httpx:异步 HTTP 客户端,用于发送 HTTP 请求。
- mcp.types 和 mcp.server.lowlevel:属于自定义模块,分别用于定义类型和实现服务器的底层逻辑。
- CORSMiddleware:来自 starlette 库,用于处理跨域资源共享(CORS)问题。
- logging:用于记录日志。
- @click.command() 和 @click.option():借助 click 库创建命令行接口,支持 --port 和 --transport 两个选项, 使其支持sse 和 stdio两种通信协议
- 若为 sse,则启动一个基于 Starlette 的 SSE 服务器,并且添加 CORS 中间件。
- 若为 stdio,则启动一个标准输入输出服务器。
2.4 启动MCP server
以stdio方式启动:
python .\mcp_test_server.py --transport=stdio
以sse方式启动:
python .\mcp_test_server.py --transport=sse --port=8000
Current executable: D:\.venv\Scripts\python.exe
?[32mINFO?[0m: Started server process [?[36m19956?[0m]
?[32mINFO?[0m: Waiting for application startup.
?[32mINFO?[0m: Application startup complete.
?[32mINFO?[0m: Uvicorn running on ?[1mhttp://0.0.0.0:8000?[0m (Press CTRL+C to quit)
3、开发MCP client
3.1 实现mcp client
实现了一个基于 Azure OpenAI 的聊天会话程序,支持与多个服务器进行交互,执行服务器提供的工具,并处理 LLM 的响应。程序通过配置文件加载服务器配置,使用环境变量管理 API 密钥,支持标准输入输出和 Server-Sent Events 两种通信模式,并带有重试机制和资源清理功能。
mcp_test_client.py代码如下:
import asyncio
import json
import logging
import os
import shutil
from contextlib import AsyncExitStack
from typing import Any
import os
import sys
import httpx
from dotenv import load_dotenv
from mcp import ClientSession, StdioServerParameters
from mcp.client.stdio import stdio_client
from mcp.client.sse import sse_client
from openai import AsyncAzureOpenAI
# Configure logging
logging.basicConfig(
level=logging.INFO, format="%(asctime)s - %(levelname)s - %(message)s"
)
python_executable = sys.executable
# 获取虚拟环境的 site-packages 路径
venv_site_packages = os.path.join(os.path.dirname(os.path.dirname(python_executable)), 'Lib', 'site-packages')
class Configuration:
def __init__(self) -> None:
self.load_env()
self.api_key = os.getenv("AZURE_OPENAI_KEY")
@staticmethod
def load_env() -> None:
load_dotenv(dotenv_path='.env.dev')
@staticmethod
def load_config(file_path: str) -> dict[str, Any]:
with open(file_path, "r") as f:
return json.load(f)
@property
def llm_api_key(self) -> str:
if not self.api_key:
raise ValueError("LLM_API_KEY not found in environment variables")
return self.api_key
class Server:
def __init__(self, name: str, config: dict[str, Any]) -> None:
self.name: str = name
self.config: dict[str, Any] = config
self.stdio_context: Any | None = None
self.session: ClientSession | None = None
self._cleanup_lock: asyncio.Lock = asyncio.Lock()
self.exit_stack: AsyncExitStack = AsyncExitStack()
async def initialize(self) -> None:
command = self.config.get("command")
if command is None:
raise ValueError("The command must be a valid string and cannot be None.")
# 检查是否是 stdio 模式
is_stdio = any(arg == "stdio" for arg in self.config.get("args", []))
if is_stdio:
# 处理 stdio 连接
server_params = StdioServerParameters(
command=command,
args=self.config["args"],
env={"PYTHONPATH": venv_site_packages, **os.environ, **self.config.get("env", {})}
)
try:
logging.info(f"Initializing stdio connection for server {self.name}")
stdio_transport = await self.exit_stack.enter_async_context(
stdio_client(server_params)
)
read, write = stdio_transport
session = await self.exit_stack.enter_async_context(
ClientSession(read, write)
)
await session.initialize()
self.session = session
logging.info(f"Successfully initialized stdio connection for server {self.name}")
except Exception as e:
logging.error(f"Error initializing stdio server {self.name}: {e}")
await self.cleanup()
raise
return
# 如果不是 stdio 模式,则尝试 SSE 连接
if "--transport" in self.config.get("args", []) and "sse" in self.config.get("args", []):
try:
port = 8000 # 默认端口
# 从参数中获取端口
if "--port" in self.config["args"]:
port_index = self.config["args"].index("--port") + 1
if port_index < len(self.config["args"]):
port = int(self.config["args"][port_index])
# 修改 SSE 端点路径
base_url = f"http://localhost:{port}/sse"
logging.info(f"Connecting to SSE endpoint: {base_url}")
# 添加重试逻辑
max_retries = 3
retry_delay = 2.0
for attempt in range(max_retries):
try:
sse_transport = await self.exit_stack.enter_async_context(
sse_client(base_url)
)
read, write = sse_transport
session = await self.exit_stack.enter_async_context(
ClientSession(read, write)
)
await session.initialize()
self.session = session
logging.info("Successfully connected to SSE server")
return
except Exception as e:
if attempt < max_retries - 1:
logging.warning(f"Connection attempt {attempt + 1} failed: {e}")
await asyncio.sleep(retry_delay)
else:
raise
except Exception as e:
logging.error(f"Error initializing SSE server {self.name}: {e}")
await self.cleanup()
raise
async def list_tools(self) -> list[Any]:
if not self.session:
raise RuntimeError(f"Server {self.name} not initialized")
tools_response = await self.session.list_tools()
tools = []
for item in tools_response:
if isinstance(item, tuple) and item[0] == "tools":
for tool in item[1]:
tools.append(Tool(tool.name, tool.description, tool.inputSchema))
return tools
async def execute_tool(
self,
tool_name: str,
arguments: dict[str, Any],
retries: int = 2,
delay: float = 1.0,
) -> Any:
if not self.session:
raise RuntimeError(f"Server {self.name} not initialized")
attempt = 0
while attempt < retries:
try:
logging.info(f"Executing {tool_name}...")
result = await self.session.call_tool(tool_name, arguments)
return result
except Exception as e:
attempt += 1
logging.warning(
f"Error executing tool: {e}. Attempt {attempt} of {retries}."
)
if attempt < retries:
logging.info(f"Retrying in {delay} seconds...")
await asyncio.sleep(delay)
else:
logging.error("Max retries reached. Failing.")
raise
async def cleanup(self) -> None:
async with self._cleanup_lock:
try:
await self.exit_stack.aclose()
self.session = None
self.stdio_context = None
except Exception as e:
logging.error(f"Error during cleanup of server {self.name}: {e}")
class Tool:
def __init__(
self, name: str, description: str, input_schema: dict[str, Any]
) -> None:
self.name: str = name
self.description: str = description
self.input_schema: dict[str, Any] = input_schema
def format_for_llm(self) -> str:
args_desc = []
if "properties" in self.input_schema:
for param_name, param_info in self.input_schema["properties"].items():
arg_desc = (
f"- {param_name}: {param_info.get('description', 'No description')}"
)
if param_name in self.input_schema.get("required", []):
arg_desc += " (required)"
args_desc.append(arg_desc)
return f"""
Tool: {self.name}
Description: {self.description}
Arguments:
{chr(10).join(args_desc)}
"""
class LLMClient:
def __init__(self, api_key: str) -> None:
self.api_key: str = api_key
self.client = AsyncAzureOpenAI(
api_key=os.environ.get("AZURE_OPENAI_KEY"),
api_version=os.environ.get("AZURE_OPENAI_VERSION"),
azure_endpoint=os.environ.get("AZURE_OPENAI_BASE")
)
async def get_response(self, messages: list[dict[str, str]]) -> str:
formatted_messages = [
{"role": message["role"], "content": message["content"]}
for message in messages
]
response = await self.client.chat.completions.create(
model=os.environ.get("AZURE_OPENAI_MODEL"),
messages=formatted_messages,
temperature=0,
max_tokens=10000,
stream=False,
)
return response.choices[0].message.content
class ChatSession:
def __init__(self, servers: list[Server], llm_client: LLMClient) -> None:
self.servers: list[Server] = servers
self.llm_client: LLMClient = llm_client
async def cleanup_servers(self) -> None:
cleanup_tasks = []
for server in self.servers:
cleanup_tasks.append(asyncio.create_task(server.cleanup()))
if cleanup_tasks:
try:
await asyncio.gather(*cleanup_tasks, return_exceptions=True)
except Exception as e:
logging.warning(f"Warning during final cleanup: {e}")
async def process_llm_response(self, llm_response: str) -> str:
import json
try:
tool_call = json.loads(llm_response)
if "tool" in tool_call and "arguments" in tool_call:
logging.info(f"Executing tool: {tool_call['tool']}")
logging.info(f"With arguments: {tool_call['arguments']}")
for server in self.servers:
tools = await server.list_tools()
if any(tool.name == tool_call["tool"] for tool in tools):
try:
result = await server.execute_tool(
tool_call["tool"], tool_call["arguments"]
)
if isinstance(result, dict) and "progress" in result:
progress = result["progress"]
total = result["total"]
percentage = (progress / total) * 100
logging.info(
f"Progress: {progress}/{total} "
f"({percentage:.1f}%)"
)
return f"Tool execution result: {result}"
except Exception as e:
error_msg = f"Error executing tool: {str(e)}"
logging.error(error_msg)
return error_msg
return f"No server found with tool: {tool_call['tool']}"
return llm_response
except json.JSONDecodeError:
return llm_response
async def start(self) -> None:
try:
for server in self.servers:
try:
await server.initialize()
except Exception as e:
logging.error(f"Failed to initialize server: {e}")
await self.cleanup_servers()
return
all_tools = []
for server in self.servers:
tools = await server.list_tools()
all_tools.extend(tools)
tools_description = "\n".join([tool.format_for_llm() for tool in all_tools])
system_message = (
"You are a helpful assistant with access to these tools:\n\n"
f"{tools_description}\n"
"Choose the appropriate tool based on the user's question. "
"If no tool is needed, reply directly.\n\n"
"IMPORTANT: When you need to use a tool, you must ONLY respond with "
"the exact JSON object format below, nothing else:\n"
"{\n"
' "tool": "tool-name",\n'
' "arguments": {\n'
' "argument-name": "value"\n'
" }\n"
"}\n\n"
"After receiving a tool's response:\n"
"1. Transform the raw data into a natural, conversational response\n"
"2. Keep responses concise but informative\n"
"3. Focus on the most relevant information\n"
"4. Use appropriate context from the user's question\n"
"5. Avoid simply repeating the raw data\n\n"
"Please use only the tools that are explicitly defined above."
)
messages = [{"role": "system", "content": system_message}]
while True:
try:
user_input = input("请输入你的问题: ").strip().lower()
if user_input in ["quit", "exit"]:
logging.info("\nExiting...")
break
messages.append({"role": "user", "content": user_input})
llm_response = await self.llm_client.get_response(messages)
logging.info("\nAssistant: %s", llm_response)
result = await self.process_llm_response(llm_response)
if result != llm_response:
messages.append({"role": "assistant", "content": llm_response})
messages.append({"role": "system", "content": result})
final_response = await self.llm_client.get_response(messages)
logging.info("\nFinal response: %s", final_response)
messages.append(
{"role": "assistant", "content": final_response}
)
else:
messages.append({"role": "assistant", "content": llm_response})
except KeyboardInterrupt:
logging.info("\nExiting...")
break
finally:
await self.cleanup_servers()
async def main() -> None:
config = Configuration()
server_config = config.load_config("servers_config.json")
servers = [
Server(name, srv_config)
for name, srv_config in server_config["mcpServers"].items()
]
llm_client = LLMClient(config.llm_api_key)
chat_session = ChatSession(servers, llm_client)
await chat_session.start()
if __name__ == "__main__":
asyncio.run(main())
- Server 类
init 方法:初始化服务器对象,包括服务器名称、配置、会话等。
initialize 方法:根据配置初始化服务器连接,支持标准输入输出(stdio)和 Server-Sent Events(SSE)两种模式,并带有重试机制。
list_tools 方法:列出服务器可用的工具。
execute_tool 方法:执行指定的工具,并带有重试机制。
cleanup 方法:清理服务器资源,确保资源正确释放。 - Tool 类
init 方法:初始化工具对象,包括工具名称、描述和输入模式。
format_for_llm 方法:将工具信息格式化为适合 LLM 处理的字符串。 - ChatSession 类
init 方法:初始化聊天会话,包括服务器列表和 LLM 客户端。
cleanup_servers 方法:清理所有服务器资源。
process_llm_response 方法:处理 LLM 响应,如果响应中包含工具调用,则执行相应的工具并返回结果。
start 方法:启动聊天会话,与用户进行交互,向 LLM 发送消息并处理响应。
3.2 测试stdio方式
修改servers_config.json 为:
{
"mcpServers": {
"weather": {
"command": "python",
"args": ["mcp_test_server.py", "--transport", "stdio"]
}
}
}
stdio 方式启动:
python mcp_test_client.py
python.exe d:/mcp_test_client.py
2025-03-27 15:43:28,281 - INFO - Initializing stdio connection for server weather
2025-03-27 15:43:28,891 - INFO - Successfully initialized stdio connection for server weather
运行结果: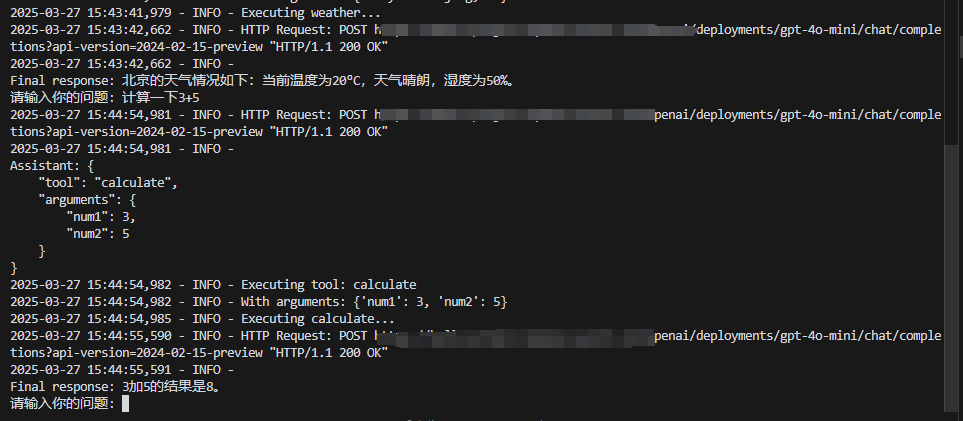
3.3 测试sse方式
以 sse方式启动 MCP server
python .\mcp_test_server.py --transport=sse --port=8000
?[32mINFO?[0m: Started server process [?[36m6588?[0m]
?[32mINFO?[0m: Waiting for application startup.
?[32mINFO?[0m: Application startup complete.
?[32mINFO?[0m: Uvicorn running on ?[1mhttp://0.0.0.0:8000?[0m (Press CTRL+C to quit)
修改servers_config.json 为:
{
"mcpServers": {
"weather": {
"command": "python",
"args": ["mcp_test_server.py", "--transport", "sse", "--port", "8000"]
}
}
}
sse 方式启动:
python mcp_test_client.py
2025-03-27 16:02:06,302 - INFO - Connecting to SSE endpoint: http://localhost:8000/sse
2025-03-27 16:02:06,305 - INFO - Connecting to SSE endpoint: http://localhost:8000/sse
2025-03-27 16:02:06,723 - INFO - HTTP Request: GET http://localhost:8000/sse "HTTP/1.1 200 OK"
2025-03-27 16:02:06,725 - INFO - Received endpoint URL: http://localhost:8000/messages/?session_id=7542736ddcbf48ec985e9b38b500a975
2025-03-27 16:02:06,726 - INFO - Starting post writer with endpoint URL: http://localhost:8000/messages/?session_id=7542736ddcbf48ec9
85e9b38b500a975
2025-03-27 16:02:06,982 - INFO - HTTP Request: POST http://localhost:8000/messages/?session_id=7542736ddcbf48ec985e9b38b500a975 "HTTP
/1.1 202 Accepted"
2025-03-27 16:02:06,983 - INFO - Successfully connected to SSE server
2025-03-27 16:02:06,986 - INFO - HTTP Request: POST http://localhost:8000/messages/?session_id=7542736ddcbf48ec985e9b38b500a975 "HTTP
/1.1 202 Accepted"
2025-03-27 16:02:06,988 - INFO - HTTP Request: POST http://localhost:8000/messages/?session_id=7542736ddcbf48ec985e9b38b500a975 "HTTP
/1.1 202 Accepted"
测试结果: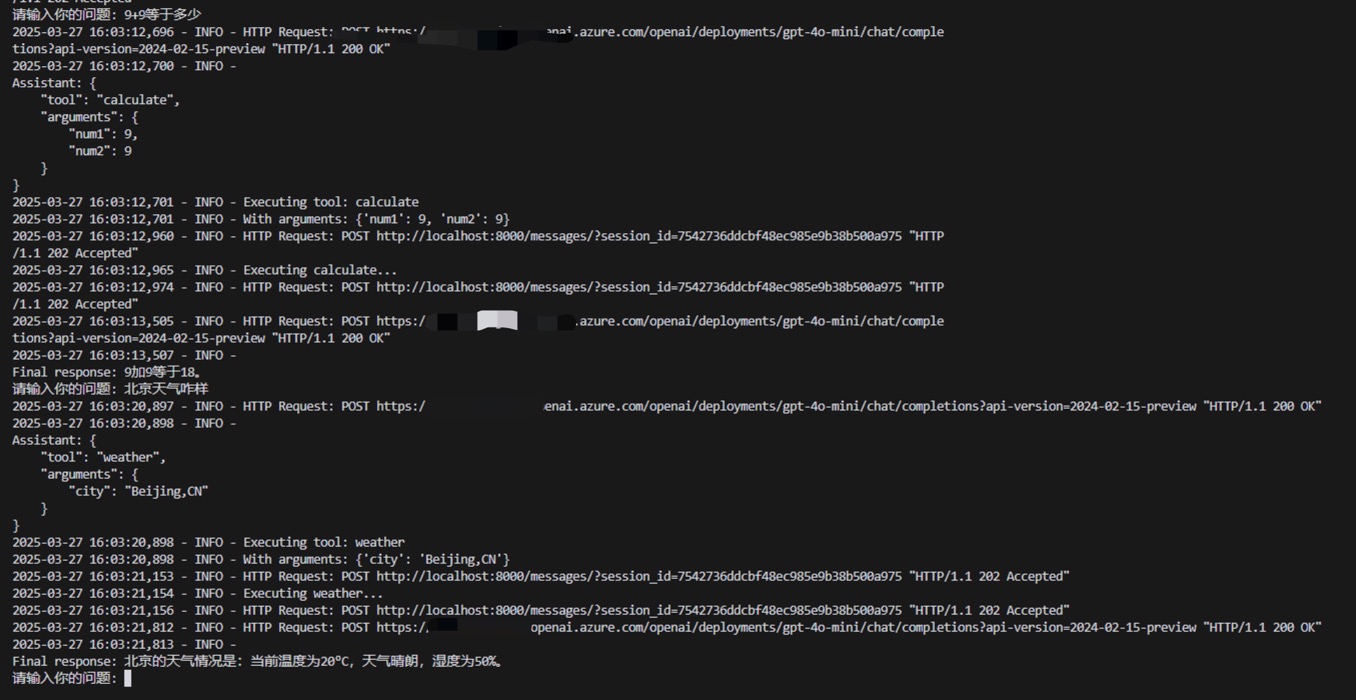
四、应用场景与行业价值
4.1 典型应用场景
- 智能问答:在企业客户服务场景中,当客户询问关于产品的特定信息,如产品规格、库存情况等,Claude 可以通过 MCP 实时查询企业数据库。假设客户询问某型号电子产品的最新价格和库存数量,Claude 通过 MCP 与企业的数据库 MCP Server 建立连接,发送查询请求。MCP Server 接收到请求后,在数据库中执行相应的 SQL 查询语句,获取最新的价格和库存数据,并将结果返回给 Claude。Claude 根据这些数据生成准确的回答,快速响应客户的问题,大大提高了客户服务的效率和准确性。
- 编程辅助:在软件开发过程中,当开发者使用 Cursor 进行代码编写时,如果需要将代码提交到 GitHub 仓库或者生成代码文档,Cursor 可以调用 Git MCP Server。例如,开发者在完成一段代码编写后,向 Cursor 发出提交代码到 GitHub 的指令,Cursor 通过 MCP 与 Git MCP Server 通信,Git MCP Server 根据指令执行 git commit 和 git push 等操作,将代码自动提交到指定的 GitHub 仓库。在生成文档方面,Cursor 可以利用 MCP Server 获取代码的相关信息,如函数定义、参数说明等,然后根据这些信息自动生成代码文档,减轻了开发者手动编写文档的负担,提高了开发效率。
- 办公自动化:在日常办公中,员工经常需要处理各种繁琐的任务,如安排会议、分发报告等。借助 MCP,AI 助手可以轻松实现这些任务的自动化。例如,当员工向 AI 助手发出 “安排明天下午 3 点的部门会议,并邀请所有部门成员参加” 的指令时,AI 助手通过 MCP 与 Slack 的 MCP Server 进行交互,在 Slack 中创建会议邀请,并向所有部门成员发送通知。在分发报告时,员工可以告诉 AI 助手 “将最新的销售报告分发给销售团队成员,并在 Notion 中创建一个副本”,AI 助手通过 MCP 操作 Slack 将报告发送给销售团队成员,同时与 Notion 的 MCP Server 通信,在 Notion 中创建报告的副本,实现了办公流程的自动化,提升了工作效率。
4.2 行业影响
- 企业级应用:在企业级应用中,数据隐私和安全至关重要。MCP 通过本地 MCP Server 处理敏感信息,为企业提供了强大的数据隐私保护能力。以金融企业为例,客户的交易数据、账户信息等都属于高度敏感信息。金融企业可以部署本地的 MCP Server,将数据库、交易系统等关键数据源与 MCP Server 进行集成。当大模型需要查询客户交易记录等敏感信息时,通过 MCP 与本地 MCP Server 进行交互,所有的数据处理都在企业内部的安全环境中进行,避免了敏感数据被传输到外部服务器,有效降低了数据泄露的风险,确保了企业数据的安全性和合规性。
- 开发者效率:MCP 的出现极大地提高了开发者的工作效率。通过标准化的接口,开发者无需为每个大模型和外部工具单独开发适配代码,减少了大量重复开发工作。同时,MCP 推动了 AI Agent 的快速构建,促进了开源生态的发展,如 Manus 等开源项目。在一个需要使用多个大模型和多种外部工具的复杂 AI 项目中,开发者可以基于 MCP 快速集成不同的工具和模型,节省了大量的开发时间。以 Manus 为例,它利用 MCP 构建了一个多智能体协作的开源生态,开发者可以在这个生态中方便地使用各种预构建的 MCP Server 和智能体组件,快速搭建出满足自己需求的 AI 应用,加速了 AI 项目的开发进程,推动了 AI 技术在各个领域的应用和创新。

欢迎加入 MCP 技术社区!与志同道合者携手前行,一同解锁 MCP 技术的无限可能!
更多推荐

 32
32 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)