
一文彻底搞懂大模型 - LLaMA-Factory
一文彻底搞懂大模型 - LLaMA-Factory
LLaMA-Factory
如何高效地微调和部署大型语言模型(LLM)?LLaMA-Factory作为一个开源的微调框架,应运而生,为开发者提供了一个简便、高效的工具,以便在现有的预训练模型基础上,快速适应特定任务需求,提升模型表现。LLaMA-Factory作为一个功能强大且高效的大模型微调框架,通过其用户友好的界面和丰富的功能特性,为开发者提供了极大的便利。

LLaMA-Factory
一、LLaMA-Factory
什么是LLaMA-Factory?LLaMA-Factory,全称Large Language Model Factory,即大型语言模型工厂。它支持多种预训练模型和微调算法,提供了一套完整的工具和接口,使得用户能够轻松地对_预训练的模型进行定制化的训练和调整_,以适应特定的应用场景,如_智能客服、语音识别、机器翻译_等。

LLaMA-Factory
-
支持的模型:LLaMA-Factory支持多种大型语言模型,包括但不限于LLaMA、BLOOM、Mistral、Baichuan、Qwen、ChatGLM等。
-
集成方法:包括(增量)预训练、指令监督微调、奖励模型训练、PPO训练、DPO训练和ORPO训练等多种方法。
-
运算精度与优化算法:提供32比特全参数微调、16比特冻结微调、16比特LoRA微调和基于AQLM/AWQ/GPTQ/LLM.int8的2/4/8比特QLoRA微调等多种精度选择,以及GaLore、DoRA、LongLoRA、LLaMA Pro、LoRA+、LoftQ和Agent微调等先进算法。
LLaMA-Factory
LLaMA-Factory提供了简洁明了的操作界面和丰富的文档支持,使得用户能够轻松上手并快速实现模型的微调与优化。 用户可以根据自己的需求选择不同的模型、算法和精度进行微调,以获得最佳的训练效果。
LLaMA-Factory
二、模型微调(Fine-Tuning)
如何使用 LLaMA-Factory进行模型微调? 使用LLaMA-Factory进行模型微调是一个涵盖从 选择模型、数据加载、参数配置到训练、评估优化直至部署应用 的全面且高效的流程。
1. 选择模型:根据应用场景和需求选择合适的预训练模型。
-
设置语言:进入WebUI后,可以切换到中文(zh)。
-
配置模型:选择LLaMA3-8B-Chat模型。
-
配置微调方法:微调方法则保持默认值lora,使用LoRA轻量化微调方法能极大程度地节约显存。

2. 加载数据:将准备好的数据集加载到LLaMA-Factory中。
- LLaMA-Factory项目内置了丰富的数据集,放在了
data目录下。同时也可以自己准备自定义数据集,将数据处理为框架特定的格式,放到指定的data目录下。

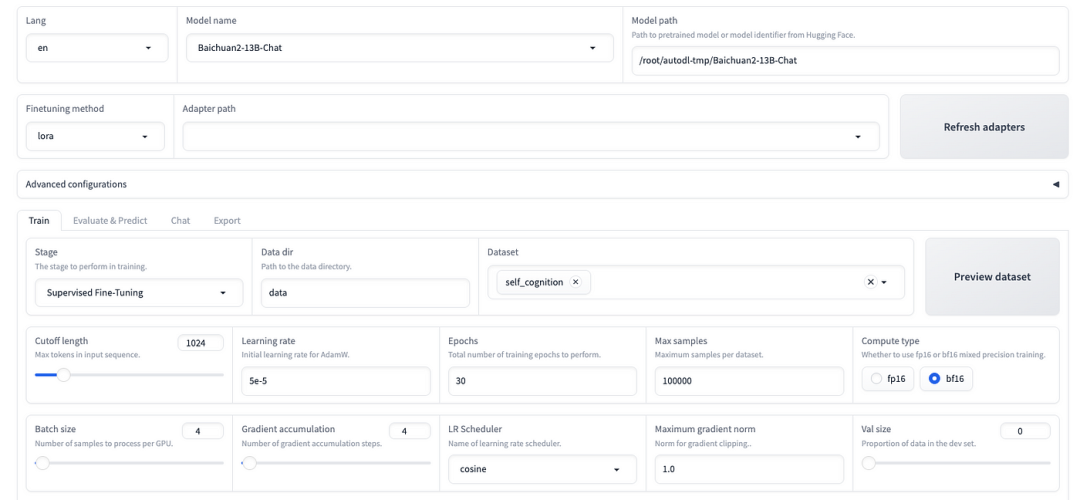
3. 配置参数:根据实际情况调整学习率、批次大小等训练参数。
-
学习率+梯度累积:设置学习率为1e-4,梯度累积为2,有利于模型拟合。
-
计算类型:如果是NVIDIA V100显卡,计算类型保持为fp16;如果使用了AMD A10系列显卡,可以更改计算类型为bf16。
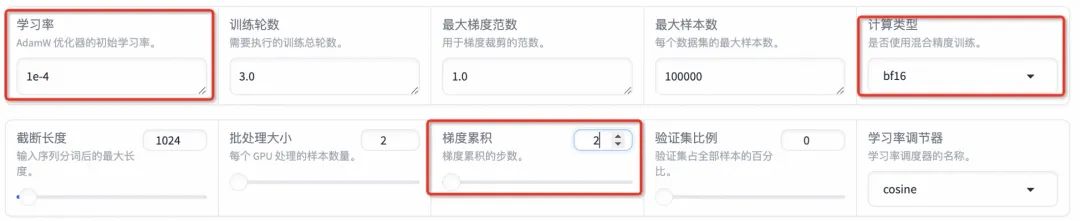
- LoRA参数设置:设置LoRA+学习率比例为16,LoRA+被证明是比LoRA学习效果更好的算法。在LoRA作用模块中填写all,即将LoRA层挂载到模型的所有线性层上,提高拟合效果。
4. 开始训练:启动训练过程,并监控模型的训练进度和性能表现。
-
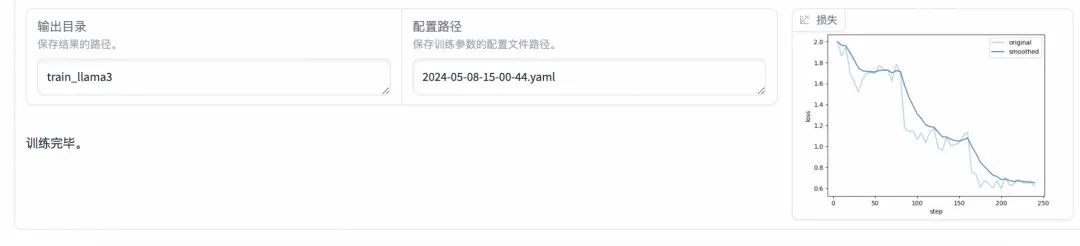
输出目录:将输出目录修改为train_llama3,训练后的LoRA权重将会保存在此目录中。
-
预览命令:点击「预览命令」可展示所有已配置的参数,如果想通过代码运行微调,可以复制这段命令,在命令行运行。
-
开始:点击「开始」启动模型微调。
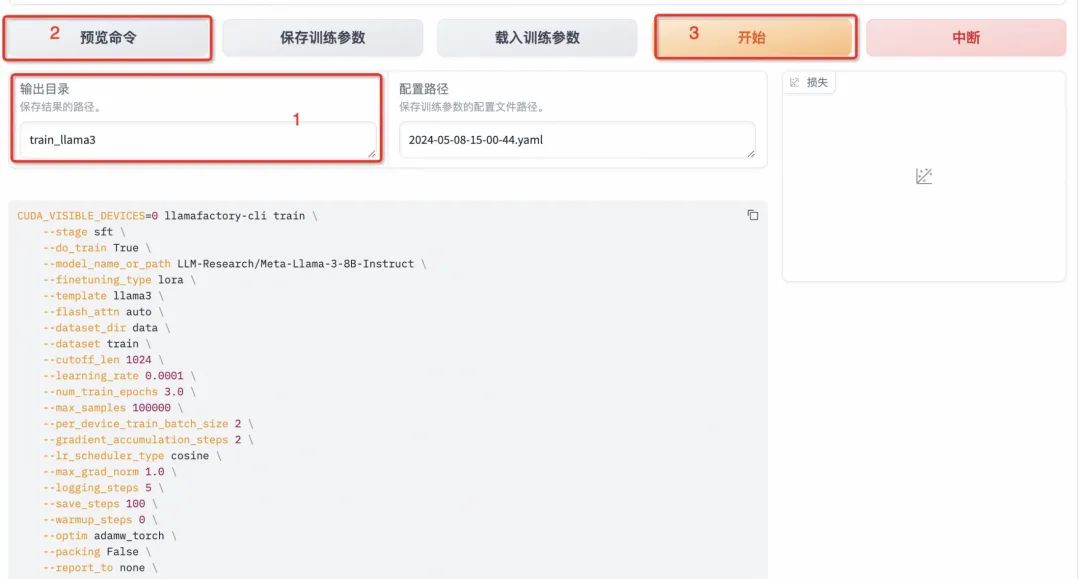
- 训练完毕:启动微调后需要等待一段时间,待模型下载完毕后可在界面观察到训练进度和损失曲线。模型微调大约需要20分钟,显示“训练完毕”代表微调成功。
5. 评估与优化:使用LLaMA-Factory提供的评估工具对模型性能进行评估,并根据评估结果进行针对性的优化。
-
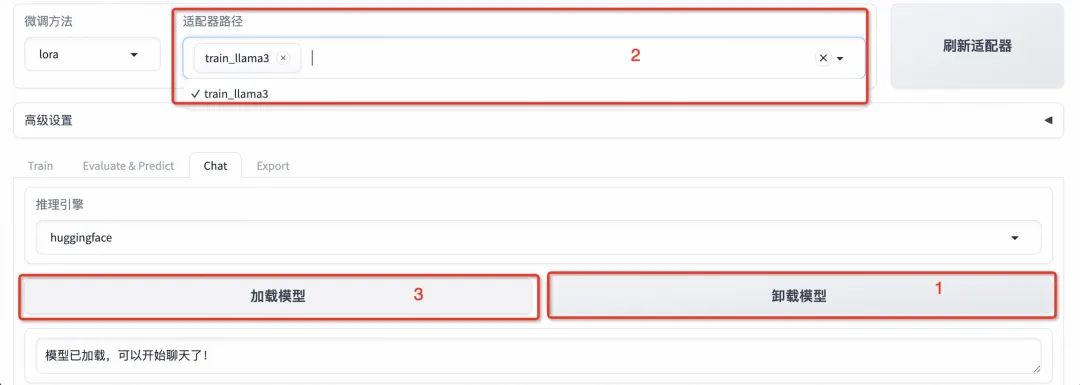
刷新适配器:微调完成后,点击页面顶部的「刷新适配器」
-
适配器路径:点击适配器路径,即可弹出刚刚训练完成的LoRA权重,点击选择下拉列表中的train_llama3选项,在模型启动时即可加载微调结果。

-
评估模型:选择「Evaluate&Predict」栏,在数据集下拉列表中选择「eval」(验证集)评估模型。
-
输出目录:更改输出目录为
eval_llama3,模型评估结果将会保存在该目录中。 -
开始评估:最后点击开始按钮启动模型评估。

-
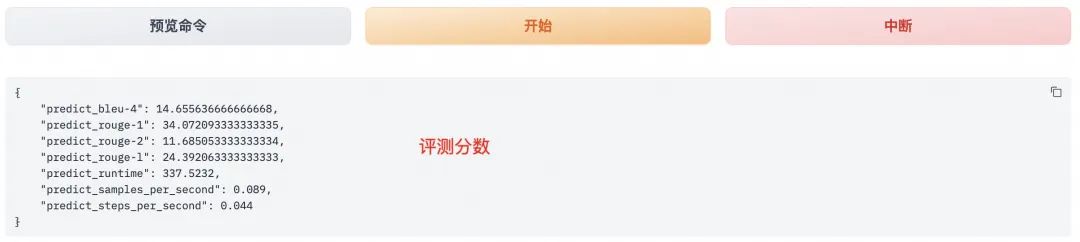
评估分数:模型评估大约需要5分钟左右,评估完成后会在界面上显示验证集的分数。
-
ROUGE分数:其中ROUGE分数衡量了模型输出答案(predict)和验证集中标准答案(label)的相似度,ROUGE分数越高代表模型学习得更好。
6. 部署应用:将训练好的模型部署到实际应用场景中,实现其功能和价值。
- 加载模型:选择「Chat」栏,确保适配器路径是
train_llama3,点击「加载模型」即可在Web UI中和微调模型进行对话。

- 卸载模型:点击「卸载模型」,点击“×”号取消适配器路径,再次点击「加载模型」,即可与微调前的原始模型聊天。
零基础入门AI大模型
由于新岗位的生产效率,要优于被取代岗位的生产效率,所以实际上整个社会的生产效率是提升的。
但是具体到个人,只能说是:
“最先掌握AI的人,将会比较晚掌握AI的人有竞争优势”。
这句话,放在计算机、互联网、移动互联网的开局时期,都是一样的道理。
我在一线互联网企业工作十余年里,指导过不少同行后辈。帮助很多人得到了学习和成长。
我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在人工智能学习中的很多困惑,所以在工作繁忙的情况下还是坚持各种整理和分享。但苦于知识传播途径有限,很多互联网行业朋友无法获得正确的资料得到学习提升,故此将并将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
😝有需要的小伙伴,可以点击下方链接免费领取🆓
一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。


四、AI大模型商业化落地方案

学习计划:
- 阶段1:1-2个月,建立AI大模型的基础知识体系。
- 阶段2:2-3个月,专注于API应用开发能力的提升。
- 阶段3:3-4个月,深入实践AI大模型的应用架构和私有化部署。
- 阶段4:4-5个月,专注于高级模型的应用和部署。
资料领取
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码或者点击下方链接免费领取【保证100%免费】


欢迎加入 MCP 技术社区!与志同道合者携手前行,一同解锁 MCP 技术的无限可能!
更多推荐

 17
17 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)