50道练习带你玩转Pandas
Pandas 是基于 NumPy 的一种数据处理工具,该工具为了解决数据分析任务而创建。Pandas 纳入了大量库和一些标准的数据模型,提供了高效地操作大型数据集所需的函数和方法。 这些练习着重DataFrame和Series对象的基本操作,包括数据的索引、分组、统计和清洗。基本操作导入 Pandas 库并简写为 pd,并输出版本号In [63]:import pandas as pdpd.__v
Pandas 是基于 NumPy 的一种数据处理工具,该工具为了解决数据分析任务而创建。Pandas 纳入了大量库和一些标准的数据模型,提供了高效地操作大型数据集所需的函数和方法。 这些练习着重DataFrame和Series对象的基本操作,包括数据的索引、分组、统计和清洗。
基本操作
-
导入 Pandas 库并简写为
pd,并输出版本号
In [63]:
import pandas as pd pd.__version__
Out[63]:
'0.24.2'
2.从列表创建 Series
In [3]:
arr = [0, 1, 2, 3, 4] df = pd.Series(arr) # 如果不指定索引,则默认从 0 开始 df
Out[3]:
0 0 1 1 2 2 3 3 4 4 dtype: int64
3.从字典创建 Series
In [4]:
d = {'a':1,'b':2,'c':3,'d':4,'e':5}
df = pd.Series(d)
df
Out[4]:
a 1 b 2 c 3 d 4 e 5 dtype: int64
4.从 NumPy 数组创建 DataFrame
In [5]:
dates = pd.date_range('today',periods=6) # 定义时间序列作为 index
num_arr = np.random.randn(6,4) # 传入 numpy 随机数组
columns = ['A','B','C','D'] # 将列表作为列名
df1 = pd.DataFrame(num_arr, index = dates, columns = columns)
df1
Out[5]:
| A | B | C | D | |
|---|---|---|---|---|
| 2020-02-04 05:36:17.273759 | 0.560268 | -0.559426 | 1.176857 | 0.885549 |
| 2020-02-05 05:36:17.273759 | 2.396094 | -0.720063 | -1.144393 | -0.149686 |
| 2020-02-06 05:36:17.273759 | 0.036016 | -1.032553 | 0.526661 | 0.524164 |
| 2020-02-07 05:36:17.273759 | 0.120952 | -0.495401 | -0.006828 | -2.375663 |
| 2020-02-08 05:36:17.273759 | 1.125484 | 0.685709 | -0.144614 | -0.398538 |
| 2020-02-09 05:36:17.273759 | -0.027859 | 0.331943 | -1.256073 | -0.659318 |
5.从CSV中创建 DataFrame,分隔符为;,编码格式为gbk
In [6]:
# df = pd.read_csv('test.csv', encoding='gbk, sep=';')
6.从字典对象data创建DataFrame,设置索引为labels
In [70]:
import numpy as np
data = {'animal': ['cat', 'cat', 'snake', 'dog', 'dog', 'cat', 'snake', 'cat', 'dog', 'dog'],
'age': [2.5, 3, 0.5, np.nan, 5, 2, 4.5, np.nan, 7, 3],
'visits': [1, 3, 2, 3, 2, 3, 1, 1, 2, 1],
'priority': ['yes', 'yes', 'no', 'yes', 'no', 'no', 'no', 'yes', 'no', 'no']}
labels = ['a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j']
In [45]:
df = pd.DataFrame(data, index=labels) df
Out[45]:
| animal | age | visits | priority | |
|---|---|---|---|---|
| a | cat | 2.5 | 1 | yes |
| b | cat | 3.0 | 3 | yes |
| c | snake | 0.5 | 2 | no |
| d | dog | NaN | 3 | yes |
| e | dog | 5.0 | 2 | no |
| f | cat | 2.0 | 3 | no |
| g | snake | 4.5 | 1 | no |
| h | cat | NaN | 1 | yes |
| i | dog | 7.0 | 2 | no |
| j | dog | 3.0 | 1 | no |
7.显示DataFrame的基础信息,包括行的数量;列名;每一列值的数量、类型
In [46]:
df.info() # 方法二 # df.describe() <class 'pandas.core.frame.DataFrame'> Index: 10 entries, a to j Data columns (total 4 columns): animal 10 non-null object age 8 non-null float64 visits 10 non-null int64 priority 10 non-null object dtypes: float64(1), int64(1), object(2) memory usage: 400.0+ bytes
8.展示df的前3行
In [47]:
df.iloc[:3] # 方法二 #df.head(3)
Out[47]:
| animal | age | visits | priority | |
|---|---|---|---|---|
| a | cat | 2.5 | 1 | yes |
| b | cat | 3.0 | 3 | yes |
| c | snake | 0.5 | 2 | no |
9.取出df的animal和age列
In [48]:
df.loc[:, ['animal', 'age']] # 方法二 # df[['animal', 'age']]
Out[48]:
| animal | age | |
|---|---|---|
| a | cat | 2.5 |
| b | cat | 3.0 |
| c | snake | 0.5 |
| d | dog | NaN |
| e | dog | 5.0 |
| f | cat | 2.0 |
| g | snake | 4.5 |
| h | cat | NaN |
| i | dog | 7.0 |
| j | dog | 3.0 |
10.取出索引为[3, 4, 8]行的animal和age列
In [49]:
df.loc[df.index[[3, 4, 8]], ['animal', 'age']]
Out[49]:
| animal | age | |
|---|---|---|
| d | dog | NaN |
| e | dog | 5.0 |
| i | dog | 7.0 |
11.取出age值大于3的行
In [50]:
df[df['age'] > 3]
Out[50]:
| animal | age | visits | priority | |
|---|---|---|---|---|
| e | dog | 5.0 | 2 | no |
| g | snake | 4.5 | 1 | no |
| i | dog | 7.0 | 2 | no |
12.取出age值缺失的行
In [51]:
df[df['age'].isnull()]
Out[51]:
| animal | age | visits | priority | |
|---|---|---|---|---|
| d | dog | NaN | 3 | yes |
| h | cat | NaN | 1 | yes |
13.取出age在2,4间的行(不含)
In [52]:
df[(df['age']>2) & (df['age']<4)] # 方法二 #df[df['age'].between(2, 4)]
Out[52]:
| animal | age | visits | priority | |
|---|---|---|---|---|
| e | dog | 5.0 | 2 | no |
| g | snake | 4.5 | 1 | no |
| i | dog | 7.0 | 2 | no |
14.f行的age改为1.5
In [53]:
df.loc['f', 'age'] = 1.5
15.计算visits的总和
In [54]:
df['visits'].sum()
Out[54]:
19
16.计算每个不同种类animal的age的平均数
In [55]:
df.groupby('animal')['age'].mean()
Out[55]:
animal cat 2.333333 dog 5.000000 snake 2.500000 Name: age, dtype: float64
17.计算df中每个种类animal的数量
In [56]:
df['animal'].value_counts()
Out[56]:
cat 4 dog 4 snake 2 Name: animal, dtype: int64
18.先按age降序排列,后按visits升序排列
In [57]:
df.sort_values(by=['age', 'visits'], ascending=[False, True])
Out[57]:
| animal | age | visits | priority | |
|---|---|---|---|---|
| i | dog | 7.0 | 2 | no |
| e | dog | 5.0 | 2 | no |
| g | snake | 4.5 | 1 | no |
| j | dog | 3.0 | 1 | no |
| b | cat | 3.0 | 3 | yes |
| a | cat | 2.5 | 1 | yes |
| f | cat | 1.5 | 3 | no |
| c | snake | 0.5 | 2 | no |
| h | cat | NaN | 1 | yes |
| d | dog | NaN | 3 | yes |
19.将priority列中的yes, no替换为布尔值True, False
In [58]:
df['priority'] = df['priority'].map({'yes': True, 'no': False})
df
Out[58]:
| animal | age | visits | priority | |
|---|---|---|---|---|
| a | cat | 2.5 | 1 | True |
| b | cat | 3.0 | 3 | True |
| c | snake | 0.5 | 2 | False |
| d | dog | NaN | 3 | True |
| e | dog | 5.0 | 2 | False |
| f | cat | 1.5 | 3 | False |
| g | snake | 4.5 | 1 | False |
| h | cat | NaN | 1 | True |
| i | dog | 7.0 | 2 | False |
| j | dog | 3.0 | 1 | False |
20.将animal列中的snake替换为python
In [59]:
df['animal'] = df['animal'].replace('snake', 'python')
df
Out[59]:
| animal | age | visits | priority | |
|---|---|---|---|---|
| a | cat | 2.5 | 1 | True |
| b | cat | 3.0 | 3 | True |
| c | python | 0.5 | 2 | False |
| d | dog | NaN | 3 | True |
| e | dog | 5.0 | 2 | False |
| f | cat | 1.5 | 3 | False |
| g | python | 4.5 | 1 | False |
| h | cat | NaN | 1 | True |
| i | dog | 7.0 | 2 | False |
| j | dog | 3.0 | 1 | False |
21.对每种animal的每种不同数量visits,计算平均age,即,返回一个表格,行是aniaml种类,列是visits数量,表格值是行动物种类列访客数量的平均年龄
In [75]:
df.dtypes
Out[75]:
animal object age float64 visits object priority int64 dtype: object
In [74]:
df.age=df.age.astype(float)
In [76]:
df.pivot_table(index='animal', columns='visits', values='age', aggfunc='mean')
Out[76]:
| visits | 1 | 2 | 3 |
|---|---|---|---|
| animal | |||
| cat | 2.5 | NaN | 2.25 |
| dog | 3.0 | 6.0 | NaN |
| python | 4.5 | 0.5 | NaN |
22.在df中插入新行k,然后删除该行
In [71]:
#插入
df.loc['k'] = [5.5, 'dog', 'no', 2]
# 删除
df = df.drop('k')
df
Out[71]:
| animal | age | visits | priority | |
|---|---|---|---|---|
| a | cat | 2.5 | 1 | 1 |
| b | cat | 3 | 3 | 1 |
| c | python | 0.5 | 2 | 0 |
| d | dog | NaN | 3 | 1 |
| e | dog | 5 | 2 | 0 |
| f | cat | 1.5 | 3 | 0 |
| g | python | 4.5 | 1 | 0 |
| h | cat | NaN | 1 | 1 |
| i | dog | 7 | 2 | 0 |
| j | dog | 3 | 1 | 0 |
进阶操作
23.有一列整数列A的DatraFrame,删除数值重复的行
In [56]:
df = pd.DataFrame({'A': [1, 2, 2, 3, 4, 5, 5, 5, 6, 7, 7]})
print(df)
df1 = df.loc[df['A'].shift() != df['A']]
# 方法二
# df1 = df.drop_duplicates(subset='A')
print(df1)
A
0 1
1 2
2 2
3 3
4 4
5 5
6 5
7 5
8 6
9 7
10 7
A
0 1
1 2
3 3
4 4
5 5
8 6
9 7
24.一个全数值DatraFrame,每个数字减去该行的平均数
In [57]:
df = pd.DataFrame(np.random.random(size=(5, 3))) print(df) df1 = df.sub(df.mean(axis=1), axis=0) print(df1) 0 1 2 0 0.761859 0.579139 0.023214 1 0.520961 0.847583 0.044559 2 0.186740 0.561425 0.158097 3 0.606828 0.680284 0.903810 4 0.474712 0.404921 0.776503 0 1 2 0 0.307122 0.124402 -0.431524 1 0.049927 0.376549 -0.426476 2 -0.115347 0.259337 -0.143990 3 -0.123479 -0.050023 0.173503 4 -0.077333 -0.147124 0.224457
25.一个有5列的DataFrame,求哪一列的和最小
In [46]:
df = pd.DataFrame(np.random.random(size=(5, 5)), columns=list('abcde'))
print(df)
df.sum().idxmin()
a b c d e
0 0.832332 0.947136 0.614947 0.162827 0.621645
1 0.786207 0.974123 0.675870 0.633438 0.960480
2 0.141939 0.070910 0.963475 0.055656 0.293488
3 0.279569 0.690073 0.570594 0.680619 0.706241
4 0.237010 0.145196 0.295304 0.628794 0.924545
Out[46]:
'd'
26.给定DataFrame,求A列每个值的前3大的B的和
In [35]:
df = pd.DataFrame({'A': list('aaabbcaabcccbbc'),
'B': [12,345,3,1,45,14,4,52,54,23,235,21,57,3,87]})
print(df)
df1 = df.groupby('A')['B'].nlargest(3).sum(level=0)
print(df1)
A B
0 a 12
1 a 345
2 a 3
3 b 1
4 b 45
5 c 14
6 a 4
7 a 52
8 b 54
9 c 23
10 c 235
11 c 21
12 b 57
13 b 3
14 c 87
A
a 409
b 156
c 345
Name: B, dtype: int64
27.给定DataFrame,有列A, B,A的值在1-100(含),对A列每10步长,求对应的B的和
In [67]:
df = pd.DataFrame({'A': [1,2,11,11,33,34,35,40,79,99],
'B': [1,2,11,11,33,34,35,40,79,99]})
print(df)
df1 = df.groupby(pd.cut(df['A'], np.arange(0, 101, 10)))['B'].sum()
print(df1)
A B
0 1 1
1 2 2
2 11 11
3 11 11
4 33 33
5 34 34
6 35 35
7 40 40
8 79 79
9 99 99
A
(0, 10] 3
(10, 20] 22
(20, 30] 0
(30, 40] 142
(40, 50] 0
(50, 60] 0
(60, 70] 0
(70, 80] 79
(80, 90] 0
(90, 100] 99
Name: B, dtype: int64
28.给定DataFrame,计算每个元素至左边最近的0(或者至开头)的距离,生成新列y
In [71]:
df = pd.DataFrame({'X': [7, 2, 0, 3, 4, 2, 5, 0, 3, 4]})
izero = np.r_[-1, (df['X'] == 0).to_numpy().nonzero()[0]] # 标记0的位置
idx = np.arange(len(df))
df['Y'] = idx - izero[np.searchsorted(izero - 1, idx) - 1]
print(df)
# 方法二
# x = (df['X'] != 0).cumsum()
# y = x != x.shift()
# df['Y'] = y.groupby((y != y.shift()).cumsum()).cumsum()
# 方法三
# df['Y'] = df.groupby((df['X'] == 0).cumsum()).cumcount()
#first_zero_idx = (df['X'] == 0).idxmax()
# df['Y'].iloc[0:first_zero_idx] += 1
X Y
0 7 1
1 2 2
2 0 0
3 3 1
4 4 2
5 2 3
6 5 4
7 0 0
8 3 1
9 4 2
29.一个全数值的DataFrame,返回最大3值的坐标
In [73]:
df = pd.DataFrame(np.random.random(size=(5, 3))) print(df) df.unstack().sort_values()[-3:].index.tolist() 0 1 2 0 0.322047 0.508559 0.481098 1 0.625304 0.582052 0.048630 2 0.848465 0.662735 0.038410 3 0.573324 0.664073 0.606389 4 0.920799 0.462395 0.684100
Out[73]:
[(2, 4), (0, 2), (0, 4)]
30.给定DataFrame,将负值代替为同组的平均值
In [78]:
df = pd.DataFrame({'grps': list('aaabbcaabcccbbc'),
'vals': [-12,345,3,1,45,14,4,-52,54,23,-235,21,57,3,87]})
print(df)
def replace(group):
mask = group<0
group[mask] = group[~mask].mean()
return group
df['vals'] = df.groupby(['grps'])['vals'].transform(replace)
print(df)
grps vals
0 a -12
1 a 345
2 a 3
3 b 1
4 b 45
5 c 14
6 a 4
7 a -52
8 b 54
9 c 23
10 c -235
11 c 21
12 b 57
13 b 3
14 c 87
grps vals
0 a 117.333333
1 a 345.000000
2 a 3.000000
3 b 1.000000
4 b 45.000000
5 c 14.000000
6 a 4.000000
7 a 117.333333
8 b 54.000000
9 c 23.000000
10 c 36.250000
11 c 21.000000
12 b 57.000000
13 b 3.000000
14 c 87.000000
31.计算3位滑动窗口的平均值,忽略NAN
In [79]:
df = pd.DataFrame({'group': list('aabbabbbabab'),
'value': [1, 2, 3, np.nan, 2, 3, np.nan, 1, 7, 3, np.nan, 8]})
print(df)
g1 = df.groupby(['group'])['value']
g2 = df.fillna(0).groupby(['group'])['value']
s = g2.rolling(3, min_periods=1).sum() / g1.rolling(3, min_periods=1).count()
s.reset_index(level=0, drop=True).sort_index()
group value
0 a 1.0
1 a 2.0
2 b 3.0
3 b NaN
4 a 2.0
5 b 3.0
6 b NaN
7 b 1.0
8 a 7.0
9 b 3.0
10 a NaN
11 b 8.0
Out[79]:
0 1.000000 1 1.500000 2 3.000000 3 3.000000 4 1.666667 5 3.000000 6 3.000000 7 2.000000 8 3.666667 9 2.000000 10 4.500000 11 4.000000 Name: value, dtype: float64
Series 和 Datetime索引
32.创建Series s,将2015所有工作日作为随机值的索引
In [82]:
dti = pd.date_range(start='2015-01-01', end='2015-12-31', freq='B') s = pd.Series(np.random.rand(len(dti)), index=dti) s.head(10)
Out[82]:
2015-01-01 0.542640 2015-01-02 0.843010 2015-01-05 0.335675 2015-01-06 0.823544 2015-01-07 0.416880 2015-01-08 0.587211 2015-01-09 0.805899 2015-01-12 0.824835 2015-01-13 0.639243 2015-01-14 0.406859 Freq: B, dtype: float64
33.所有礼拜三的值求和
In [83]:
s[s.index.weekday == 2].sum()
Out[83]:
24.085656574156896
34.求每个自然月的平均数
In [84]:
s.resample('M').mean()
Out[84]:
2015-01-31 0.507893 2015-02-28 0.589465 2015-03-31 0.622884 2015-04-30 0.559272 2015-05-31 0.568332 2015-06-30 0.469618 2015-07-31 0.396087 2015-08-31 0.409175 2015-09-30 0.521630 2015-10-31 0.558678 2015-11-30 0.497789 2015-12-31 0.460043 Freq: M, dtype: float64
35.每连续4个月为一组,求最大值所在的日期
In [87]:
s.groupby(pd.Grouper(freq='4M')).idxmax()
Out[87]:
2015-01-31 2015-01-02 2015-05-31 2015-03-25 2015-09-30 2015-06-09 2016-01-31 2015-10-01 Freq: 4M, dtype: datetime64[ns]
36.创建2015-2016每月第三个星期四的序列
In [88]:
pd.date_range('2015-01-01', '2016-12-31', freq='WOM-3THU')
Out[88]:
DatetimeIndex(['2015-01-15', '2015-02-19', '2015-03-19', '2015-04-16', '2015-05-21', '2015-06-18', '2015-07-16', '2015-08-20', '2015-09-17', '2015-10-15', '2015-11-19', '2015-12-17', '2016-01-21', '2016-02-18', '2016-03-17', '2016-04-21', '2016-05-19', '2016-06-16', '2016-07-21', '2016-08-18', '2016-09-15', '2016-10-20', '2016-11-17', '2016-12-15'], dtype='datetime64[ns]', freq='WOM-3THU')
数据清洗
In [60]:
df = pd.DataFrame({'From_To': ['LoNDon_paris', 'MAdrid_miLAN', 'londON_StockhOlm',
'Budapest_PaRis', 'Brussels_londOn'],
'FlightNumber': [10045, np.nan, 10065, np.nan, 10085],
'RecentDelays': [[23, 47], [], [24, 43, 87], [13], [67, 32]],
'Airline': ['KLM(!)', '<Air France> (12)', '(British Airways. )',
'12. Air France', '"Swiss Air"']})
df
Out[60]:
| From_To | FlightNumber | RecentDelays | Airline | |
|---|---|---|---|---|
| 0 | LoNDon_paris | 10045.0 | [23, 47] | KLM(!) |
| 1 | MAdrid_miLAN | NaN | [] | <Air France> (12) |
| 2 | londON_StockhOlm | 10065.0 | [24, 43, 87] | (British Airways. ) |
| 3 | Budapest_PaRis | NaN | [13] | 12. Air France |
| 4 | Brussels_londOn | 10085.0 | [67, 32] | "Swiss Air" |
37.FlightNumber列中有些值缺失了,他们本来应该是每一行增加10,填充缺失的数值,并且令数据类型为整数
In [61]:
df['FlightNumber'] = df['FlightNumber'].interpolate().astype(int) df
Out[61]:
| From_To | FlightNumber | RecentDelays | Airline | |
|---|---|---|---|---|
| 0 | LoNDon_paris | 10045 | [23, 47] | KLM(!) |
| 1 | MAdrid_miLAN | 10055 | [] | <Air France> (12) |
| 2 | londON_StockhOlm | 10065 | [24, 43, 87] | (British Airways. ) |
| 3 | Budapest_PaRis | 10075 | [13] | 12. Air France |
| 4 | Brussels_londOn | 10085 | [67, 32] | "Swiss Air" |
38.将From_To列从_分开,分成From, To两列,并删除原始列
In [62]:
temp = df.From_To.str.split('_', expand=True)
temp.columns = ['From', 'To']
df = df.join(temp)
df = df.drop('From_To', axis=1)
df
Out[62]:
| FlightNumber | RecentDelays | Airline | From | To | |
|---|---|---|---|---|---|
| 0 | 10045 | [23, 47] | KLM(!) | LoNDon | paris |
| 1 | 10055 | [] | <Air France> (12) | MAdrid | miLAN |
| 2 | 10065 | [24, 43, 87] | (British Airways. ) | londON | StockhOlm |
| 3 | 10075 | [13] | 12. Air France | Budapest | PaRis |
| 4 | 10085 | [67, 32] | "Swiss Air" | Brussels | londOn |
39.将From, To大小写统一
In [63]:
df['From'] = df['From'].str.capitalize() df['To'] = df['To'].str.capitalize() df
Out[63]:
| FlightNumber | RecentDelays | Airline | From | To | |
|---|---|---|---|---|---|
| 0 | 10045 | [23, 47] | KLM(!) | London | Paris |
| 1 | 10055 | [] | <Air France> (12) | Madrid | Milan |
| 2 | 10065 | [24, 43, 87] | (British Airways. ) | London | Stockholm |
| 3 | 10075 | [13] | 12. Air France | Budapest | Paris |
| 4 | 10085 | [67, 32] | "Swiss Air" | Brussels | London |
40.Airline列,有一些多余的标点符号,需要提取出正确的航司名称。举例:'(British Airways. )' 应该改为 'British Airways'.
In [107]:
df['Airline'] = df['Airline'].str.extract('([a-zA-Z\s]+)', expand=False).str.strip()
df
Out[107]:
| FlightNumber | RecentDelays | Airline | From | To | |
|---|---|---|---|---|---|
| 0 | 10045 | [23, 47] | KLM | London | Paris |
| 1 | 10055 | [] | Air France | Madrid | Milan |
| 2 | 10065 | [24, 43, 87] | British Airways | London | Stockholm |
| 3 | 10075 | [13] | Air France | Budapest | Paris |
| 4 | 10085 | [67, 32] | Swiss Air | Brussels | London |
41.Airline列,数据被以列表的形式录入,但是我们希望每个数字被录入成单独一列,delay_1, delay_2, ...没有的用NAN替代。
In [108]:
delays = df['RecentDelays'].apply(pd.Series)
delays.columns = ['delay_{}'.format(n) for n in range(1, len(delays.columns)+1)]
df = df.drop('RecentDelays', axis=1).join(delays)
df
Out[108]:
| FlightNumber | Airline | From | To | delay_1 | delay_2 | delay_3 | |
|---|---|---|---|---|---|---|---|
| 0 | 10045 | KLM | London | Paris | 23.0 | 47.0 | NaN |
| 1 | 10055 | Air France | Madrid | Milan | NaN | NaN | NaN |
| 2 | 10065 | British Airways | London | Stockholm | 24.0 | 43.0 | 87.0 |
| 3 | 10075 | Air France | Budapest | Paris | 13.0 | NaN | NaN |
| 4 | 10085 | Swiss Air | Brussels | London | 67.0 | 32.0 | NaN |
层次化索引
42.用 letters = ['A', 'B', 'C'] 和 numbers = list(range(10))的组合作为系列随机值的层次化索引
In [39]:
letters = ['A', 'B', 'C'] numbers = list(range(4)) mi = pd.MultiIndex.from_product([letters, numbers]) s = pd.Series(np.random.rand(12), index=mi) s
Out[39]:
A 0 0.867828 1 0.633680 2 0.328333 3 0.726590 B 0 0.972693 1 0.140361 2 0.905836 3 0.072299 C 0 0.787910 1 0.408023 2 0.532220 3 0.219010 dtype: float64
43.检查s是否是字典顺序排序的
In [40]:
s.index.is_lexsorted() # 方法二 # s.index.lexsort_depth == s.index.nlevels
Out[40]:
True
44.选择二级索引为1, 3的行
In [41]:
s.loc[:, [1, 3]]
Out[41]:
A 1 0.633680 3 0.726590 B 1 0.140361 3 0.072299 C 1 0.408023 3 0.219010 dtype: float64
45.对s进行切片操作,取一级索引从头至B,二级索引从2开始到最后
In [42]:
s.loc[pd.IndexSlice[:'B', 2:]] # 方法二 # s.loc[slice(None, 'B'), slice(2, None)]
Out[42]:
A 2 0.328333 3 0.726590 B 2 0.905836 3 0.072299 dtype: float64
46.计算每个一级索引的和(A, B, C每一个的和)
In [43]:
s.sum(level=0) #方法二 #s.unstack().sum(axis=0)
Out[43]:
A 2.556431 B 2.091189 C 1.947163 dtype: float64
47.交换索引等级,新的Series是字典顺序吗?不是的话请排序
In [44]:
new_s = s.swaplevel(0, 1) print(new_s) print(new_s.index.is_lexsorted()) new_s = new_s.sort_index() print(new_s) 0 A 0.867828 1 A 0.633680 2 A 0.328333 3 A 0.726590 0 B 0.972693 1 B 0.140361 2 B 0.905836 3 B 0.072299 0 C 0.787910 1 C 0.408023 2 C 0.532220 3 C 0.219010 dtype: float64 False 0 A 0.867828 B 0.972693 C 0.787910 1 A 0.633680 B 0.140361 C 0.408023 2 A 0.328333 B 0.905836 C 0.532220 3 A 0.726590 B 0.072299 C 0.219010 dtype: float64
可视化
In [18]:
import matplotlib.pyplot as plt
df = pd.DataFrame({"xs":[1,5,2,8,1], "ys":[4,2,1,9,6]})
plt.style.use('ggplot')
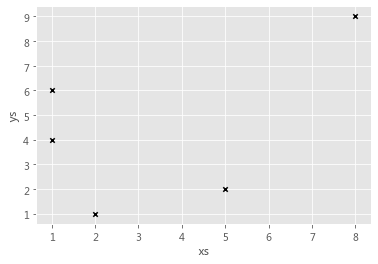
48.画出df的散点图
In [19]:
df.plot.scatter("xs", "ys", color = "black", marker = "x")
Out[19]:
<matplotlib.axes._subplots.AxesSubplot at 0x7fbb753a8eb8>
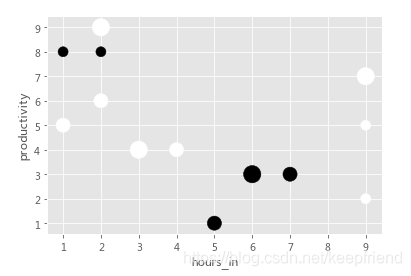
49.可视化指定4维DataFrame
In [20]:
df = pd.DataFrame({"productivity":[5,2,3,1,4,5,6,7,8,3,4,8,9],
"hours_in" :[1,9,6,5,3,9,2,9,1,7,4,2,2],
"happiness" :[2,1,3,2,3,1,2,3,1,2,2,1,3],
"caffienated" :[0,0,1,1,0,0,0,0,1,1,0,1,0]})
df.plot.scatter("hours_in", "productivity", s = df.happiness * 100, c = df.caffienated)
Out[20]:
<matplotlib.axes._subplots.AxesSubplot at 0x7fbb752f5780>
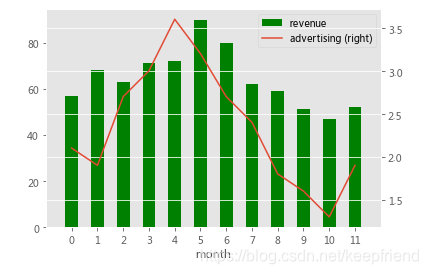
50.在同一个图中可视化2组数据,共用X轴,但y轴不同
In [25]:
df = pd.DataFrame({"revenue":[57,68,63,71,72,90,80,62,59,51,47,52],
"advertising":[2.1,1.9,2.7,3.0,3.6,3.2,2.7,2.4,1.8,1.6,1.3,1.9],
"month":range(12)})
ax = df.plot.bar("month", "revenue", color = "green")
df.plot.line("month", "advertising", secondary_y = True, ax = ax)
ax.set_xlim((-1,12));

欢迎加入 MCP 技术社区!与志同道合者携手前行,一同解锁 MCP 技术的无限可能!
更多推荐

 2
2 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)