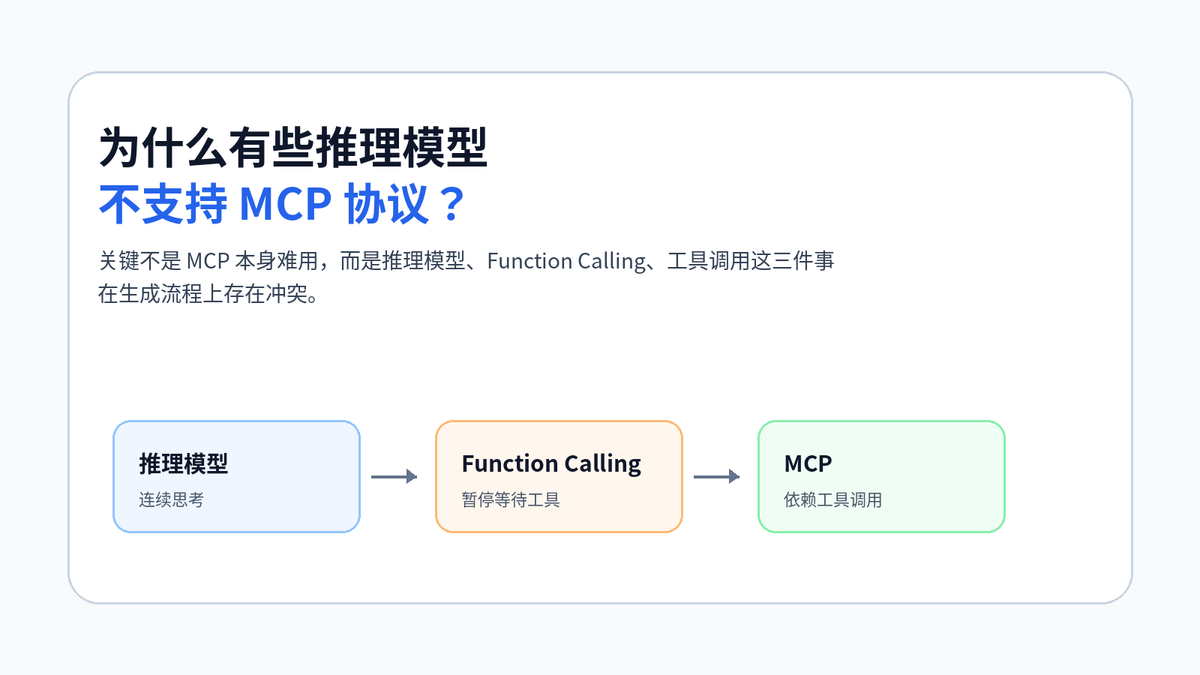
为什么有些推理模型不支持 MCP 协议?
说透推理模型、Function Calling 和 MCP 之间的真实关系
开头:这个问题不是“厂商没适配”这么简单
很多人第一次听到这个问题,会下意识回答:可能是模型太新,SDK 还没接好,等更新就行。这个回答只说对了一小部分。
真正要抓住的是:MCP 要想跑起来,底层通常需要模型具备稳定的工具调用能力;而有些推理模型的生成方式,天然不喜欢在“想题目”的中途被打断。
换句话说,问题不在于 MCP Server 写得好不好,而在于模型是否能稳定完成这件事:看懂工具定义,决定要不要调用工具,输出结构化参数,等工具结果回来之后继续回答。
一句话回答
有些推理模型不支持 MCP,本质上是因为它们不适合被工具调用流程中途打断。
推理模型通常会先生成大量内部推理 token,把问题完整想一遍;而 Function Calling 需要模型在生成过程中暂停,把工具请求交给宿主程序执行,再接着生成。这个“暂停等待外部结果”的动作,和连续推理机制存在冲突。
MCP 又是建立在工具调用能力之上的。模型如果不能稳定输出 tool_calls,MCP 的工具发现、工具路由和工具执行链路就没法顺利跑起来。
1. 先看普通模型和推理模型有什么不同
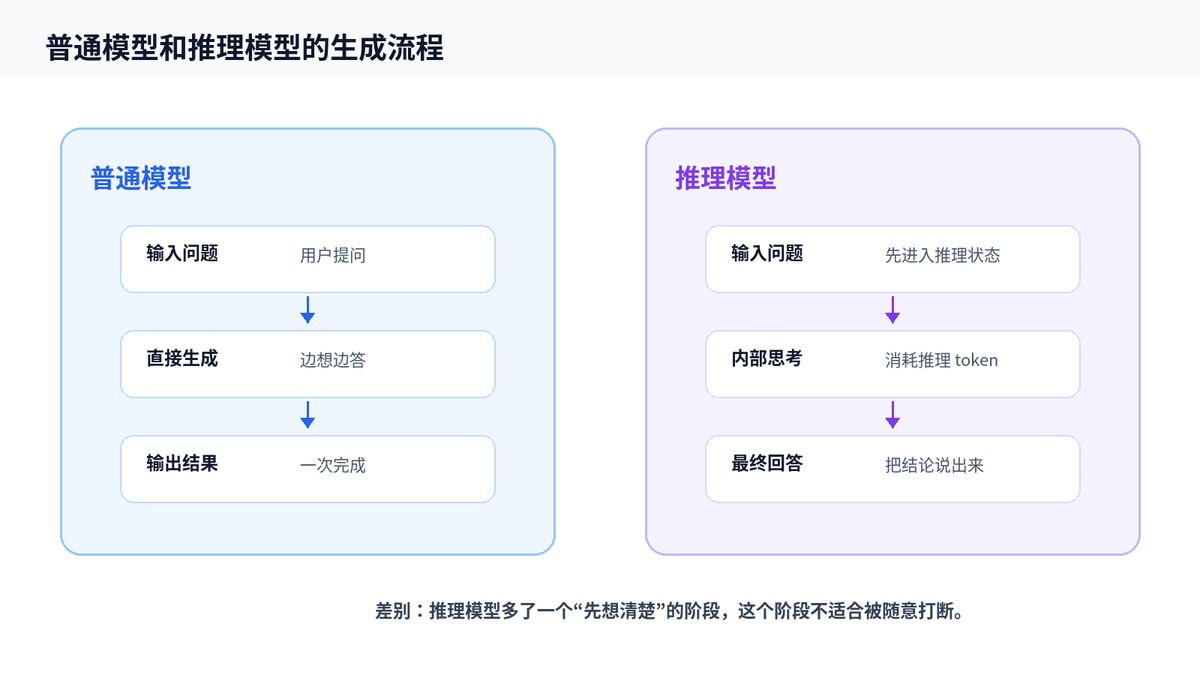
普通模型更像“边想边说”。用户给一个问题,它开始生成 token,一路生成到答案结束。
推理模型更像“先在草稿纸上想一遍,再把答案写给你”。它会消耗一部分内部推理 token,用来分解问题、检查思路、修正错误,再输出最终答案。OpenAI 文档也把推理模型描述为会使用内部 reasoning tokens,然后再产生响应。
这类模型适合数学、代码、复杂规划、多步问题,因为它不是马上说结论,而是先把问题推演一遍。
2. 工具调用的关键动作是“中途暂停”
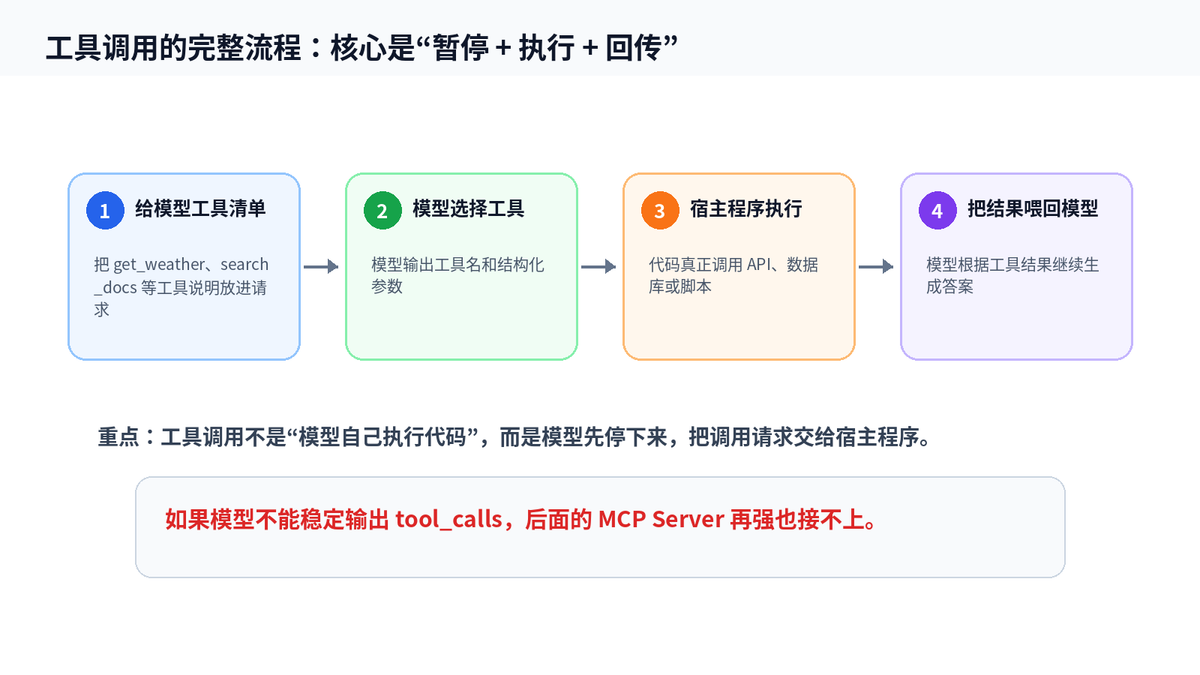
工具调用的流程并不神秘。模型不是自己去查数据库,也不是自己执行代码。它只负责输出“我要调用哪个工具、参数是什么”。真正的执行动作,由你的后端程序、Agent 框架或 MCP Client 完成。
OpenAI 的工具调用文档也把这个流程拆成多步:先给模型工具,模型返回工具调用,应用侧执行代码,再把工具结果发回模型,最后模型继续生成答案。
关键就在“模型返回工具调用之后,必须停下来”。比如模型生成到一半,发现需要查天气,于是输出 get_weather(city=“上海”),此时模型不能继续胡编天气,只能等你的程序去查完,再把结果喂回来。
{ "type": "function", "name": "get_weather", "description": "查询城市天气", "parameters": { "type": "object", "properties": { "city": { "type": "string" } }, "required": [ "city" ] } }
上面这段只是告诉模型:你可以调用 get_weather。模型如果判断需要查天气,就会输出类似下面这样的调用请求。
{ "type": "function_call", "name": "get_weather", "arguments": { "city": "上海" } }
3. 冲突点:推理模型想连续思考,工具调用要暂停等待
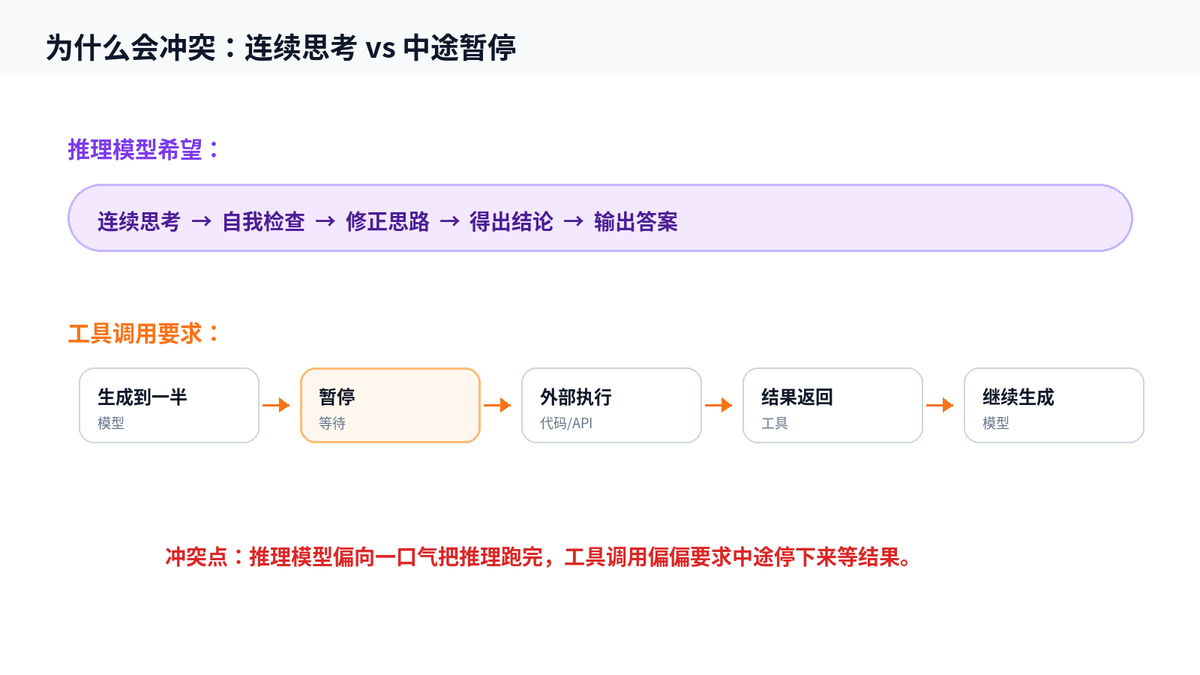
这里就是很多推理模型早期不支持工具调用的核心原因。
推理模型的优势来自连续推理。它在内部不断推演、反驳、修正,形成一条完整的推理链路。工具调用却要求它在某个时间点突然停下来,输出结构化 JSON,然后等外部工具执行。
用一个生活例子理解:你正在写一篇逻辑很复杂的文章,刚把结构想顺,突然有人让你出去办个事,二十分钟后回来,你很可能要重新找状态。推理模型也是类似,它的连续推理状态被打断之后,后续推理就不一定自然衔接。
4. “保存状态再恢复”为什么也不轻松
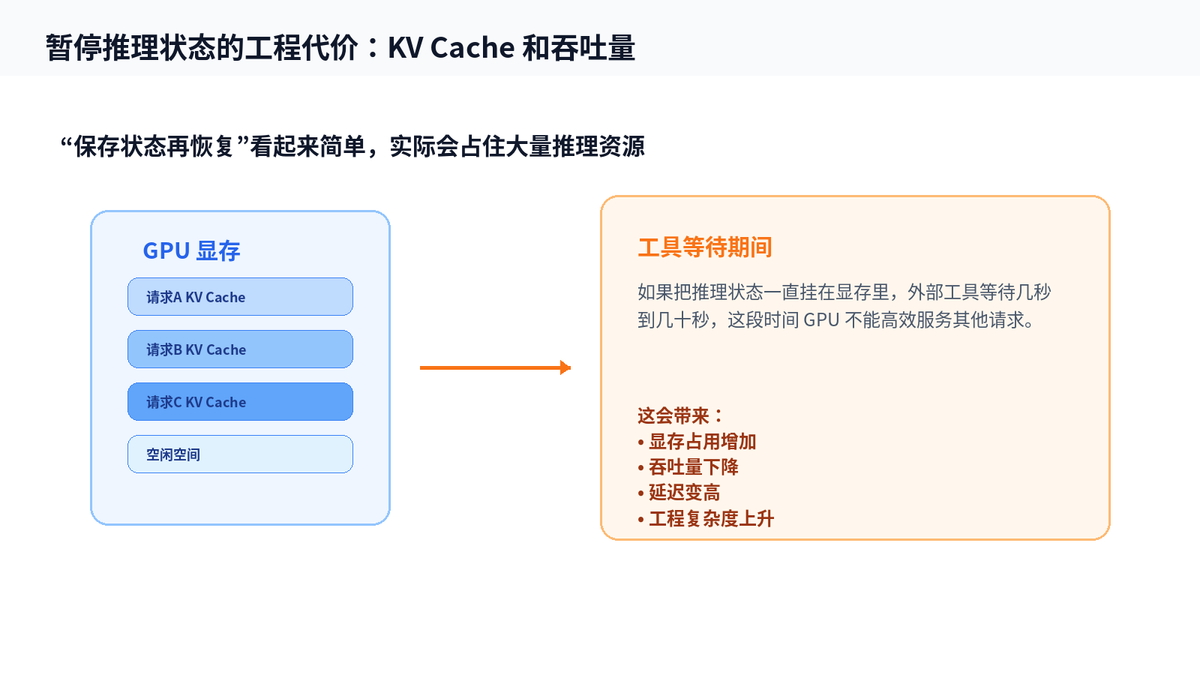
有人可能会问:那把模型状态保存起来,等工具返回再恢复,不就行了吗?
理论上听起来合理,工程上却很重。模型推理时会产生大量中间状态,常见说法是 KV Cache。这个缓存会占用 GPU 显存。工具调用如果要等几秒甚至几十秒,显存就要一直被这个请求占着,其他请求进不来,吞吐量会下降。
更麻烦的是一致性。工具结果回来之后,模型之前的内部推理可能已经基于“还不知道工具结果”的前提展开了。现在突然插入新事实,模型需要把新结果和旧思路重新对齐,这不是简单拼接一段文本就能完全解决的。
5. 训练目标上也有拉扯

推理模型训练时,往往会更强调“完整推理、答案正确、复杂问题做对”。它学到的行为是:遇到难题,先深入思考,不要急着输出。
Function Calling 训练想让模型学会另一件事:该停的时候要停,该查的时候要查,还要输出严格的结构化参数。
这两种能力并不是完全矛盾,但训练信号确实不同。一个鼓励模型持续推理,一个鼓励模型在合适时机切换到工具调用。融合得不好,就可能出现三类问题:
模型想了一半突然吐出格式错误的 JSON;
模型过度推理,明明该查工具却不查;
工具结果回来后,后续回答和前面推理脱节。
6. 为什么不支持 Function Calling,就很难支持 MCP
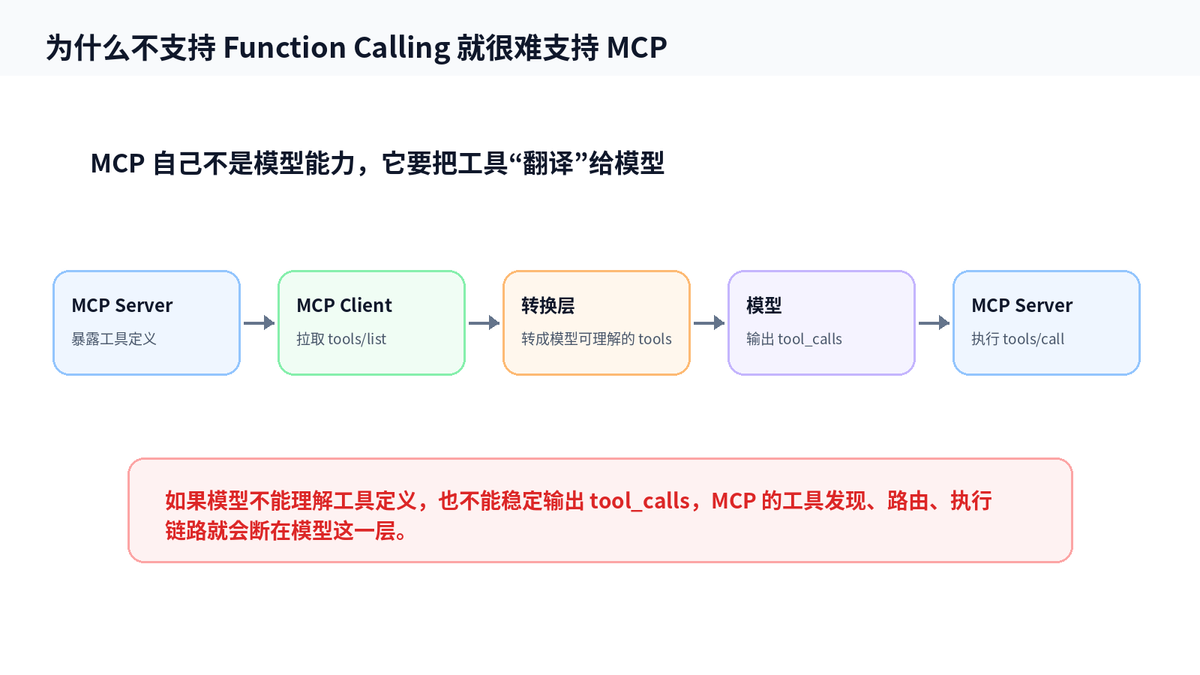
MCP 可以理解为一套“工具接入标准”。它能让 AI 应用用统一方式连接外部工具、数据源和工作流。MCP 官方文档也把它类比成 AI 应用连接外部系统的 USB-C。
但是 MCP 并不能绕过模型本身的工具调用能力。实际链路大致是:MCP Client 从 MCP Server 拉取工具定义,再把这些工具整理成模型能理解的工具描述,模型输出 tool_calls,Client 再把调用请求路由回 Server 执行。
如果模型本身不能稳定理解工具定义、不能稳定输出工具调用参数,那么 MCP 后面的标准化、复用、路由都用不上。
{ "jsonrpc": "2.0", "id": 1, "method": "tools/list", "params": { } }
MCP Client 可以像上面这样向 Server 要工具清单。但拿到工具清单之后,仍然要交给模型判断“该不该用、用哪个、参数是什么”。这一步如果模型不支持 Function Calling,链路就断了。
7. 后来怎么解决:不是硬打断,而是重新安排节奏
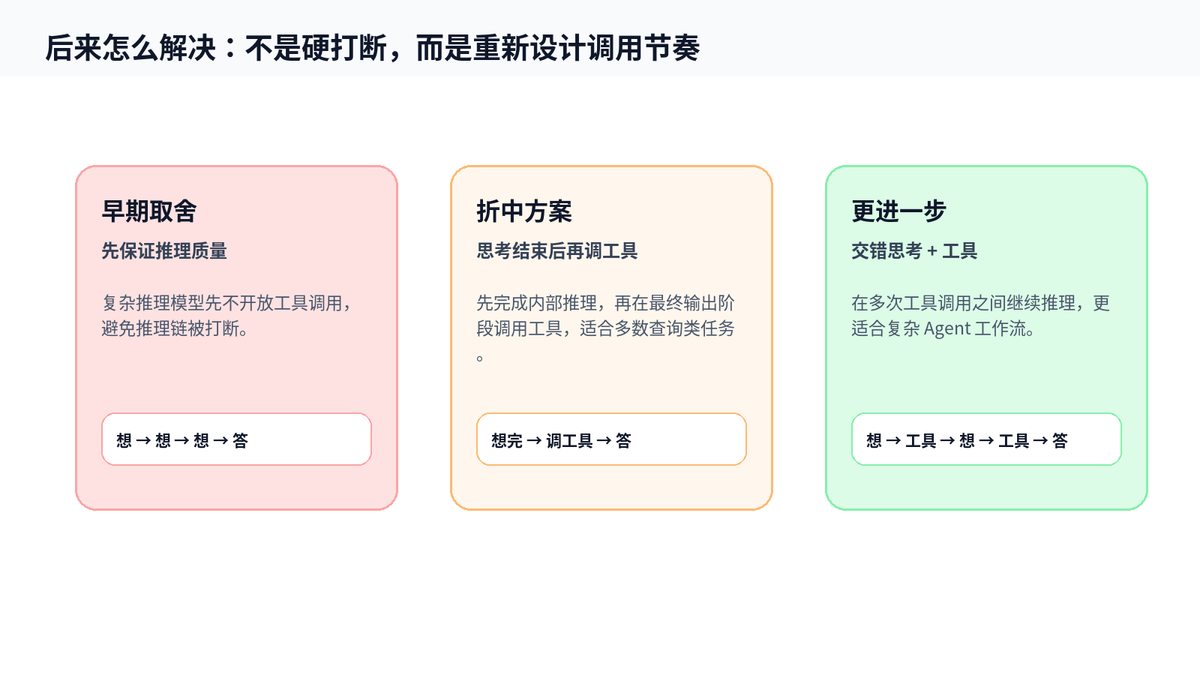
这个问题并不是无解。后来的做法主要有两类。
第一类是“先思考,再调用”。也就是让推理模型先把主要推理做完,到需要形成最终答案或补充事实时,再触发工具调用。这样能保住推理质量,但它的局限是:工具结果没有参与最早的深度推理。
第二类是“交错思考和工具调用”。Anthropic 在 Claude 4 里提到 Extended Thinking with tool use,可以让模型在思考和工具使用之间交替;AWS Bedrock 文档也说明,Claude 4 支持 interleaved thinking,让模型在工具调用结果回来后继续思考,再决定下一步。
OpenAI 现在的推理模型文档也提到,新的推理模型支持在工具调用之间进行思考,并建议在函数调用场景中把相关 reasoning items 一起传回,以便模型继续推理。
8. 落地时怎么判断一个模型能不能接 MCP
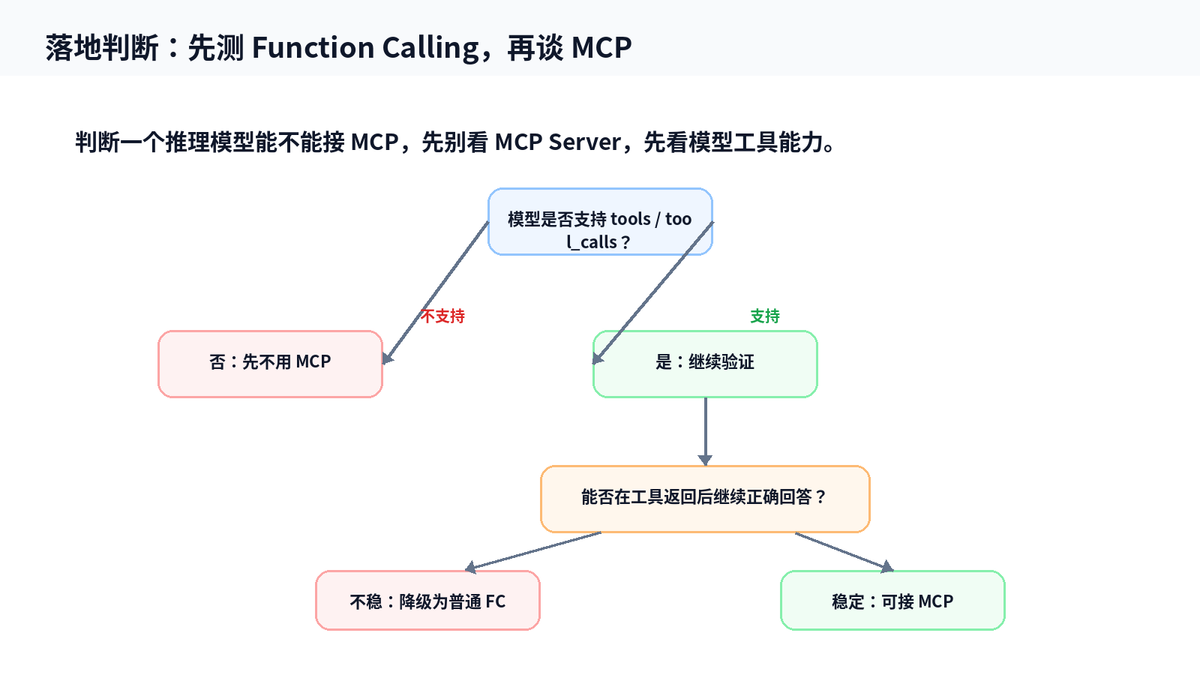
不要只看模型名字里有没有“推理”两个字,也不要只看 MCP Server 能不能启动。真正要测的是模型端的工具能力。
第一步:模型能否读取工具 schema,并选择正确工具;
第二步:模型能否输出合法 JSON 参数;
第三步:工具返回后,模型能否继续正确回答;
第四步:连续多次工具调用时,模型是否会丢上下文;
第五步:遇到工具失败、超时、参数缺失时,模型是否能降级处理。
9. 场景选型:不要为了 MCP 而 MCP
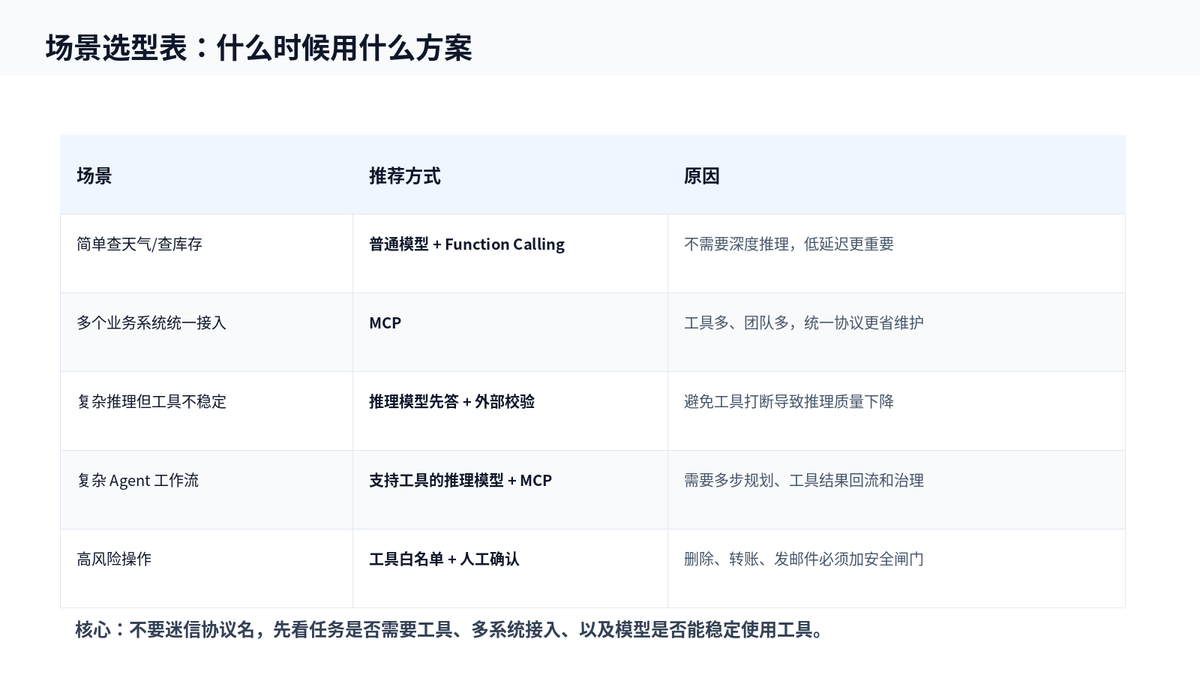
如果只是一个简单业务工具,比如查询订单、查天气、查库存,用 Function Calling 就够了,没必要上 MCP。
如果工具越来越多,多个项目都要接同一批能力,比如数据库、Git、文件系统、搜索、内部业务接口,这时候 MCP 的价值就出来了:统一暴露工具,统一发现工具,统一维护。
对于推理模型,要额外关注工具调用能力是否稳定。复杂任务可以用支持工具的推理模型;如果模型工具能力不稳定,可以先让普通模型承担工具路由,让推理模型负责复杂分析。
10. 生产环境还要补上安全边界

只要模型能调工具,就必须考虑安全问题。因为工具不是聊天,它可能真的查数据、写文件、发消息、删资源、触发付款。
生产环境里,至少要有工具白名单、参数校验、权限控制、用户确认、超时重试、审计日志。尤其是 MCP 场景,工具是动态发现的,更不能把所有 Server 暴露的工具都直接交给模型。
11. 面试可以这样回答
有些推理模型不支持 MCP,核心不是 MCP 协议本身难,而是它底层依赖模型的工具调用能力。
工具调用要求模型在生成过程中输出 tool_calls,然后暂停等待外部工具执行,再把工具结果接回来继续生成。而推理模型的优势来自连续推理,它会先消耗内部推理 token,把问题完整想一遍。早期或某些特定推理模型不适合在这个过程中被打断,所以 Function Calling 支持不好,MCP 自然也跑不稳。
后来的解决办法,是重新安排推理和工具调用的节奏:要么先完成主要思考,再调用工具;要么支持交错思考,让模型在工具结果返回后继续推理。能否支持 MCP,最终要看模型是否能稳定理解工具定义、输出结构化调用参数,并在工具返回后继续正确回答。

欢迎加入 MCP 技术社区!与志同道合者携手前行,一同解锁 MCP 技术的无限可能!
更多推荐


 1
1 0
0- 0



 已为社区贡献49条内容
已为社区贡献49条内容

所有评论(0)