Harness -- 上下文压缩
常见压缩策略
参考Agent Scope 框架
1. 对话摘要压缩 (CompactionMiddleware)
按消息条数或估算 token 触发,把对话前缀用一次 LLM 调用压成结构化摘要,保留尾部 N 条最近消息原文,然后把 [summary] + [recent tail] 写回 AgentState.contextMutable()。
2. 大工具结果卸载 (ToolResultEvictionMiddleware)
跟摘要压缩独立。当某条工具结果文本超过阈值(默认 80K 字符 ≈ 20K tokens),把全文写到工作区某个目录,上下文里只保留首尾各约 2K 字符 + 一个 read_file 路径提示符。agent 想看全文就自己 read_file。
默认排除 read_file / write_file / edit_file / grep_files / glob_files / list_files / memory_* / session_search——这些工具要么自带分页、要么返回值很小。Shell execute 默认不排除,因为命令输出可能非常大。
3. 上下文溢出兜底
如果模型直接返回 context_length_exceeded / maximum context / token limit 等错误,HarnessAgent.recoverFromOverflow() 会强制走一次 triggerMessages=1 的极端压缩,然后自动重试一次。前提是构造 agent 时配了 .compaction(...),否则错误原样抛回上层。
这条兜底链路无需额外配置:只要 compaction 开了,溢出恢复就自动开。
Claude Code -- 压缩
在Claude Code 的这种AI Coding的Agent中,“上下文窗口”是制约 Agent 长程任务执行能力的核心瓶颈。随着对话轮数的增加,海量的工具调用输出、代码片段和历史交互会迅速耗尽 token 配额,导致模型“失忆”或响应延迟。为了解决这一痛点,Claude Code提供了一套先进的上下文管理思路,就是这个三层渐进式压缩体系
- Layer 1: MicroCompact(微压缩) — 无 LLM 调用,纯规则驱动,极致轻量。
- Layer 2: Session Memory Compact(会话记忆压缩) — 基于已有会话记忆进行替换,零额外推理成本。
- Layer 3: Full LLM Compact(完全压缩) — 调用 LLM 生成结构化摘要,精度最高但成本也最高。
MicroCompact(微压缩)—— 规则驱动的“第一道防线”
在很多人的认知里,压缩上下文似乎必须依赖大模型的总结摘要能力,但这往往带来了不必要的延迟和成本。实际上,对于大量结构化的工具输出,规则驱动的微压缩才是 ROI 最高的选择。
Claude Code提供了这种设计的细节。系统定义了一个可压缩工具白名单,仅针对如 Bash、Read、Grep、Glob 等产生大量标准输出的工具进行压缩处理;而对于 Edit、Write 等涉及核心状态变更的操作,其输出则被完整保留,以确保后续决策的准确性。这种“抓大放小”的策略,既控制了体积,又守住了安全底线。
微压缩主要包含两条执行路径:
- 1.基于时间的路径:直接对超过一定时间阈值的旧消息工具输出进行截断。
- 2.基于缓存的路径:智能识别 KV Cache 的边界,仅在边界之外执行压缩,最大化利用缓存命中率。
Session Memory Compact(会话记忆压缩)—— 复用已有的“智慧”
当微压缩不足以缓解上下文压力时,Claude Code进入第二层压缩:会话记忆压缩。这一层的核心理念是“不要重复造轮子”。
在之前的交互中,Claude Code 可能已经生成过高质量的会话记忆(Session Memory)。这一层的策略就是直接利用这些现有的摘要来替换冗长的原始历史消息,而无需再次调用 LLM 进行新的总结。
- 触发时机:只有当上下文 Token 数 ≥ 10,000 且文本消息条数 ≥ 5 条时才触发,避免频繁操作干扰短期记忆。
- 压缩上限:单次最大压缩 40,000 token,防止一次性丢失过多细节。
- 执行逻辑:将符合条件的旧消息替换为会话记忆摘要,同时严格保留最近几轮的消息不动,确保模型对当前任务的“近因效应”感知不被破坏。
Full LLM Compact(完全 LLM 压缩)—— 高精度的“终极手段”
如果前两层依然无法将上下文控制在安全范围内,或者任务场景极其复杂,Claude Code需要动用“重型武器”:调用 LLM 进行全量压缩。
- 为了保证摘要的质量并防止模型“偷懒”或产生幻觉,这里引入了两个关键的 Prompt Engineering 技巧:隐式思维链(Implicit CoT)优化:Claude Code在 Prompt 中明确要求模型在输出最终摘要前,先在 标签内进行全面的逻辑推演和分析,然后再在summary>标签中输出结果。在实际返回给系统的过程中, 块会被程序剥离,只保留纯净的摘要。这种做法极大地提升了摘要的逻辑连贯性和信息密度。
- 反工具调用保护:这是一个非常容易被忽视但至关重要的细节。Claude Code在 Prompt 头部加入了强约束指令(NO_TOOLS_PREAMBLE),严厉禁止模型在压缩过程中调用任何工具(如 Read、Bash 等)。明确告知模型:“工具调用将被拒绝,且会浪费你唯一的一次机会,导致任务失败”。这有效防止了模型在压缩阶段产生不可控的副作用。
自动压缩触发机制 —— 智能的“流量调节阀”
当超过上下文窗口的80%首先尝试会话记忆压缩,如果不满足使用完全 LLM 压缩
OpenClow -- 压缩
一:上下文压缩
分块设计,旧消息被自适应分为多个块,对每个块进行总结,然后对这些总结在进行总结
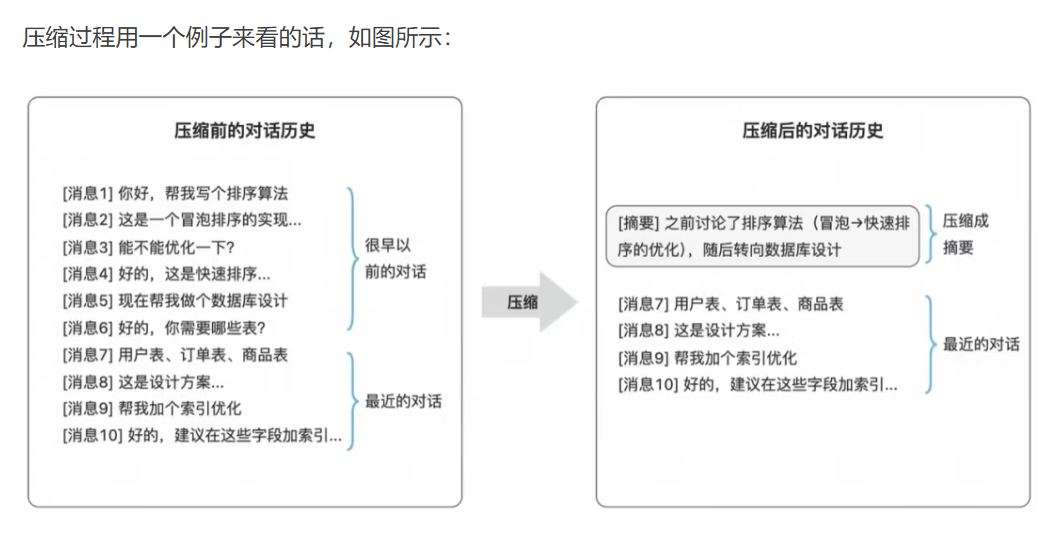
触发时机:
- 手动触发
- 超过上下文阈值自动触发
注意:为防止重要信息在压缩丢失
OpenClaw在生成Summary的时候,会被特别要求保留当前活跃的任务、重要的决策和结论、待办事项(TODO)、做过的承诺、所有不透明标识符(如UUID、哈希值等,必须原文保留,不能自己瞎改)。而且,在将要压缩的内容送入Summary模型之前,会先调用stripToolResultDetails()移除工具输出中的一些details的字段。这是因为工具的结果中可能包含一些冗长的内容,不适合直接送入Summary模型。
二:精细化裁剪
除了对话历史的压缩,工具调用的返回结果往往是占用上下文的“大户”。
- 头尾保留,中间省略:基于经验法则,Exception、Error、Traceback等这些报错的关键信息通常位于开头和结尾,而正常的如JSON这样的数据结构的核心定义也在头部。因此,系统在检测到超长输出时,会智能地保留首尾部分,将中间内容替换为 ... 或简略标记。
- 止损策略:虽然这种裁剪可能在极端情况下损失部分细节,但在上下文受限的硬约束下,这是避免整体理解偏差的必要妥协。系统通常会控制裁剪比例(不超过 50%),以最大程度保留核心语义。

Q1:在压缩摘要时,关键信息被压缩掉了怎么处理?
第一步:预先防止关键信息被压缩
- 在系统提示词加上强制约束(如下)
你是一个专业的对话历史压缩专家。你的任务是将冗长的对话历史浓缩为一段精炼的摘要(Summary),以便后续模型能够无缝接续当前任务。
在执行压缩时,你必须严格遵守以下约束:
1. 核心信息保留:
- 当前活跃的任务:准确记录用户当前正在执行的核心任务及进度。
- 重要决策与结论:保留对话中达成的关键共识、架构决策或最终结论。
- 待办事项(TODO):完整提取并列出所有尚未完成的待办事项。
- 做出的承诺:保留模型或用户做出的明确承诺(如“稍后提供代码”、“下一步将执行...”)。
2. 标识符绝对保真:
- 所有不透明标识符(如 UUID、哈希值、Token、API Key 等)必须【逐字原文保留】。
- 严禁对这类标识符进行任何修改、缩写、推测或重新生成。
3. 内容边界限制:
- 仅基于提供的对话历史进行总结,不要引入外部知识。
- 保持摘要的客观性,不要遗漏关键的上下文转折。- 压缩前进行记忆摘要
摘要发生前是否先把对话前缀里的事实抽取到长期记忆(Memory)中第二步:信息被压缩掉了 要进行恢复(用 agent 自己查历史会话)
注册三个查询工具会自动注册,agent 自己就能调:
session_list agentId="..."—— 列出某个 agent 的历史会话。session_history agentId="..." sessionId="..." lastN=20—— 看某次会话最近 N 条消息。session_search query="..." agentId="..."—— 在历史会话里关键词搜索。
这些工具读的是永不压缩的对话日志(<workspace>/agents/<agentId>/sessions/<sessionId>.log.jsonl),所以即使上下文已经被压缩成摘要,agent 也能查到原始消息。

欢迎加入 MCP 技术社区!与志同道合者携手前行,一同解锁 MCP 技术的无限可能!
更多推荐

 1
1 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)