Agent Harness 架构真相:Prompt Cache 如何决定 Skill、MCP 与 SubAgent 设计
很多人第一次看 Claude Code、Codex CLI 或类似 Coding Agent 的实现,注意力会落在 Skill、MCP、SubAgent 这些新名词上。它们看起来像一组彼此独立的能力:Skill 像插件,MCP 像外部工具协议,SubAgent 像多智能体协作。
真正把代码和请求链路翻开之后,结论会朴素很多:这些机制大多不是模型侧的新能力,而是 Agent Harness 在 system、tools、messages 三个输入面上做的工程编排。难点不在于“能不能塞进去”,而在于什么时候塞、塞到哪里、怎样不把 Prompt Cache 打碎。
Prompt Cache 这件事很容易被低估。Agent 每轮请求都可能带上系统提示词、工具定义、历史消息、文件片段、运行时提醒和工具结果。如果前缀稳定,缓存命中能明显降低延迟和成本;如果动态内容插得太靠前,从变化位置之后的内容就会失去缓存价值。Claude Code 很多看似绕的设计,本质上是在守这条边界。
Harness 的输入面:三块上下文决定了所有扩展点
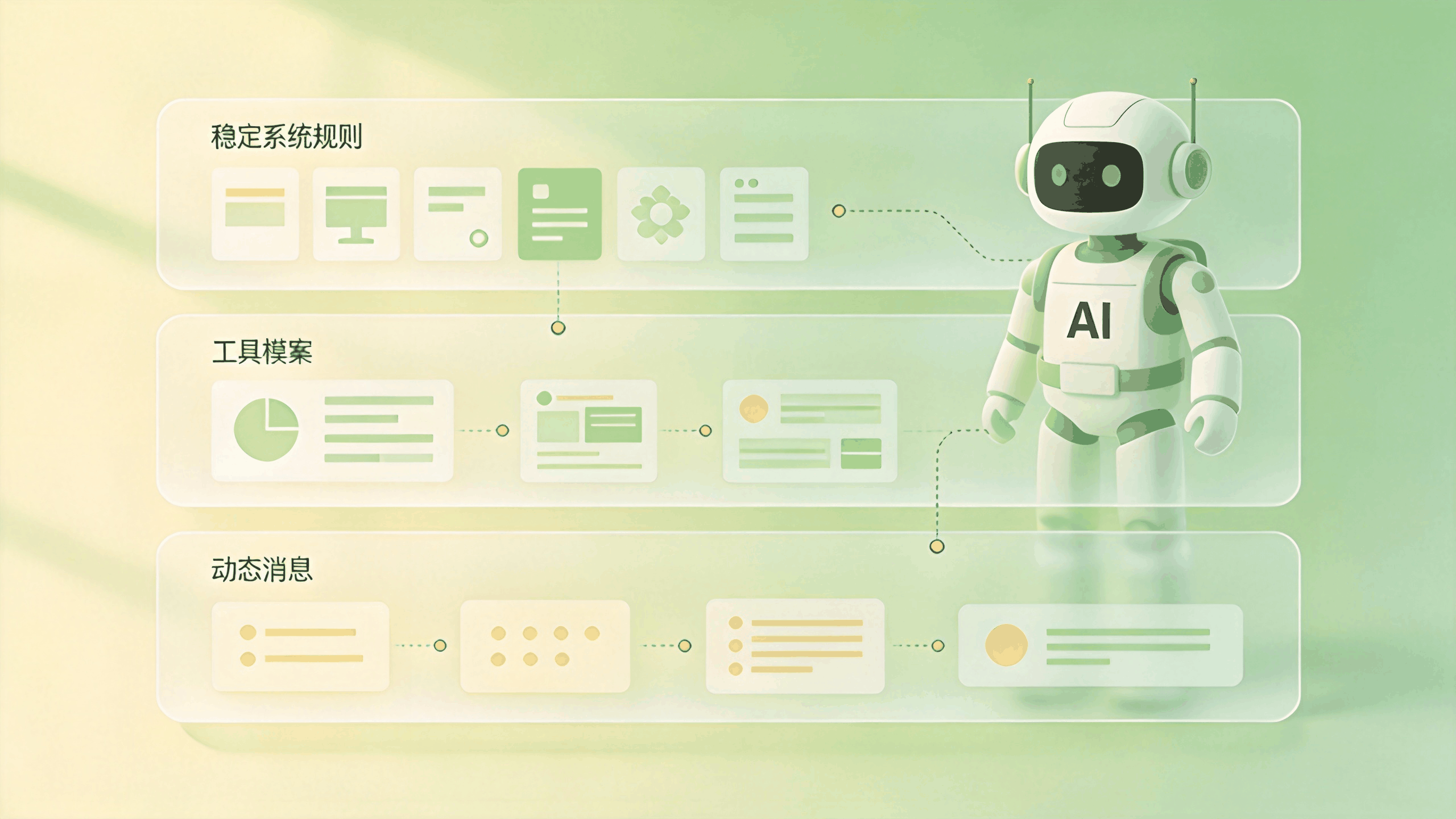
图:Agent Harness 把稳定规则、工具能力与动态消息分层管理
一次 LLM 调用通常不神秘。无论是 Anthropic Messages API,还是 OpenAI Chat Completions 风格的接口,核心输入都绕不开三类内容:
{
"model": "claude-opus-4.7",
"system": "You are a helpful coding assistant.",
"messages": [
{ "role": "user", "content": "..." }
],
"tools": [
{
"name": "read_file",
"description": "...",
"input_schema": {}
}
]
}
这三个字段对应 Harness 的三条主线。
| 输入面 | 适合放什么 | 不适合放什么 |
|---|---|---|
system |
稳定身份、全局规则、安全边界 | 高频变化的项目状态、动态 skill 列表 |
tools |
相对稳定的工具名、参数 schema、权限边界 | 大段文档、可变 agent 列表、临时状态 |
messages |
用户输入、历史对话、工具结果、运行时注入 | 需要长期稳定缓存的大块静态规则 |
Agent Harness 的大部分能力都可以落回这张表。Skill 是把一段 prompt 延后放进上下文;SubAgent 是通过一个工具调用开出一套新的上下文;MCP 是把外部能力包装成工具 schema;attachment 是把运行时生成的信息变成额外 message。概念变多了,底层入口没有变。
Agent Loop:模型只决定下一步,Harness 负责把世界接回来
Agent 不是一次请求给出完整答案,而是在“模型决策”和“工具执行”之间来回切换。模型输出 tool_use,Harness 调用真实工具,再把 tool_result 写回 messages,下一轮继续请求模型。

图:Agent Loop 在模型决策与工具执行之间循环
真实系统会在这条循环外再加很多护栏,比如最大轮次、token 上限、工具超时、权限过滤、错误重试、上下文压缩。但这些护栏不改变主结构:LLM 负责判断下一步,Harness 负责执行下一步。
Skill 和 SubAgent 的差别,也可以放进这条循环里看。Skill 不会自己执行代码,它只是改变下一轮模型能看到的指令。SubAgent 则更重:一次外层工具调用会启动另一个独立的 Agent Loop,外层只拿最终结果。
Prompt Cache 是架构约束,不是性能小优化
如果把所有内容一股脑塞进 system 或工具描述,功能也许能跑,但缓存会很快变差。原因是 Prompt Cache 依赖前缀稳定。越靠前的 token 越应该稳定,越动态的内容越应该靠后。
可以把一次请求粗略拆成这样:
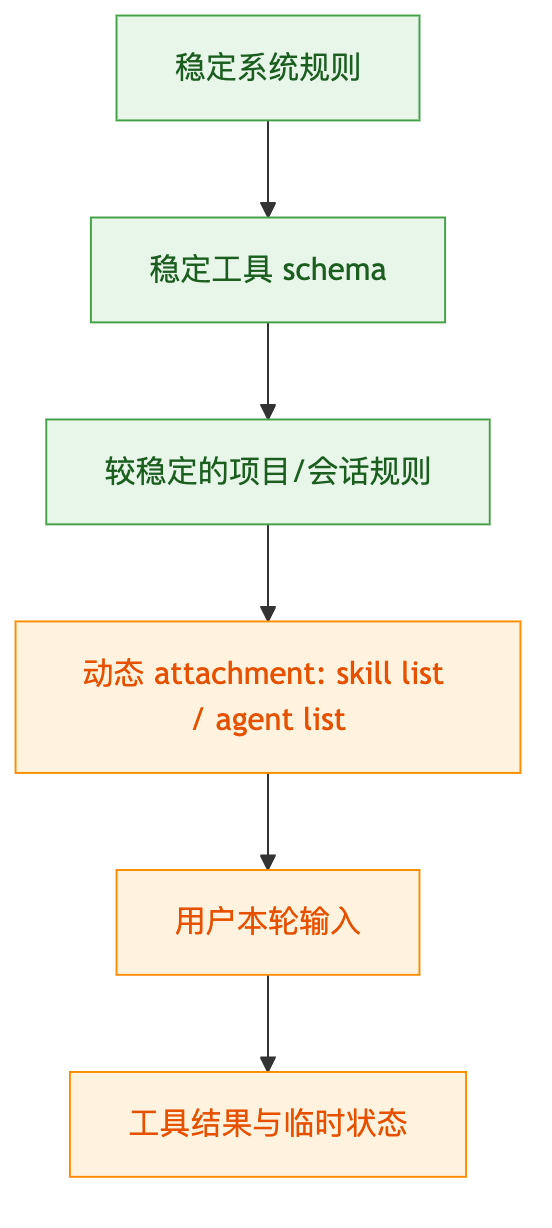
图:稳定上下文靠前,动态信息靠后
这解释了 Claude Code 里一些不直觉的选择:动态列表不一定塞进 system,而是作为额外 message 注入;工具 schema 尽量保持稳定;某些工具定义可以 defer-loading,先暴露搜索入口,命中后再加载完整定义。
这不是洁癖。一个可扩展 Agent 会不断遇到新文件、新 skill、新 MCP server、新 agent 配置和用户临时指令。只要其中一类内容频繁变化,放错位置就会拖累后面的缓存命中。
Skill:不要把它想成插件,先把它看成延迟加载的提示词
Skill 的核心价值不是“多一个工具”,而是把某类任务的做法沉淀成一个可按需加载的 prompt。它通常有 SKILL.md,也可能带参考资料、示例和脚本。
my-skill/
├── SKILL.md
├── reference.md
├── examples/
└── scripts/
SKILL.md 本身不具备执行能力。它会告诉 Agent:遇到这类任务时应该怎么读文件、怎么调用 bash、怎么编辑代码、怎么验收。真正干活的仍然是 Harness 已经提供的工具。
更合理的 Skill 系统一般分两步:
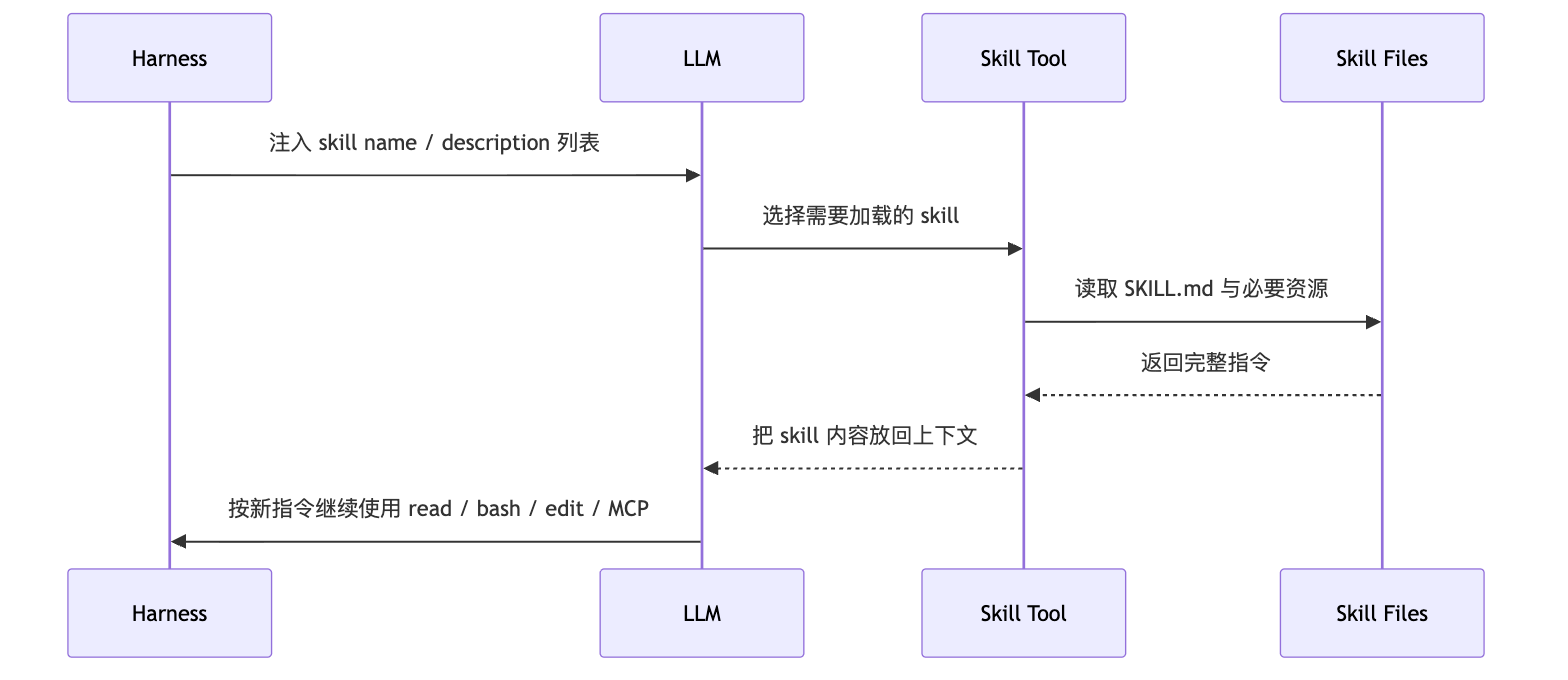
图:Skill 从短描述到完整指令的按需加载
这样做有两个好处。第一,初始上下文只放很短的 name/description,不会把所有 skill 内容都塞进去。第二,skill 可以渐进加载,真正命中后再读 body,缓存压力小很多。
Slash Command 是另一个入口,但不是 Skill 的本质。Command 更像用户主动点名:“把这段 prompt 展开后送进 Agent Loop”。Skill 更重要的部分,是 Harness 能让模型先感知有哪些能力,再决定是否加载完整说明。
Command 和 Skill 的关系可以这么看:
| 机制 | 入口 | 放进上下文的内容 | 典型用途 |
|---|---|---|---|
| Slash Command | 用户显式输入 /xxx |
展开后的 command prompt | 快速触发固定流程 |
| Skill Meta | Harness 自动注入 | name、description |
让模型知道可选能力 |
| Skill Tool | 模型按需调用 | 完整 SKILL.md 与资源 |
复杂任务的过程约束 |
Claude Code 将 Skill 注册进 CommandRegistry,是一个产品和工程上的复用选择。用户可以像调用命令一样主动触发 Skill;模型也可以在看到 skill 列表后,按需把完整指令加载进来。
Attachment:把动态清单放到消息层,而不是污染稳定前缀
Skill 列表、SubAgent 列表、运行时提醒,这些内容有一个共同点:它们有用,但变化频率高。项目里新增一个 Skill、插件更新一个 Agent、会话中临时挂载一个能力,都会改变这部分内容。
把它们写死在 system 里会很省事,但会破坏稳定前缀。更稳的做法是把这类内容变成 attachment,作为额外 user message 注入,常见形式是包一层类似 <system-reminder> 的标签,让模型知道它是系统级提醒,但又不把它放进最前面的静态 system prompt。
<system-reminder>
Available skills:
- code-review: inspect diffs and report risks
- explain-code: explain implementation and call chain
</system-reminder>
这层设计解决的是“动态信息如何被模型感知”的问题。它不负责执行,也不保证模型一定调用,只是把运行时状态以较低缓存代价送进上下文。
可以把它理解成 Harness 的上下文公告栏:不稳定的信息贴在公告栏上,稳定规则留在前缀里。
SubAgent:一次工具调用,换来一条隔离的执行链

欢迎加入 MCP 技术社区!与志同道合者携手前行,一同解锁 MCP 技术的无限可能!
更多推荐


 0
0 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)