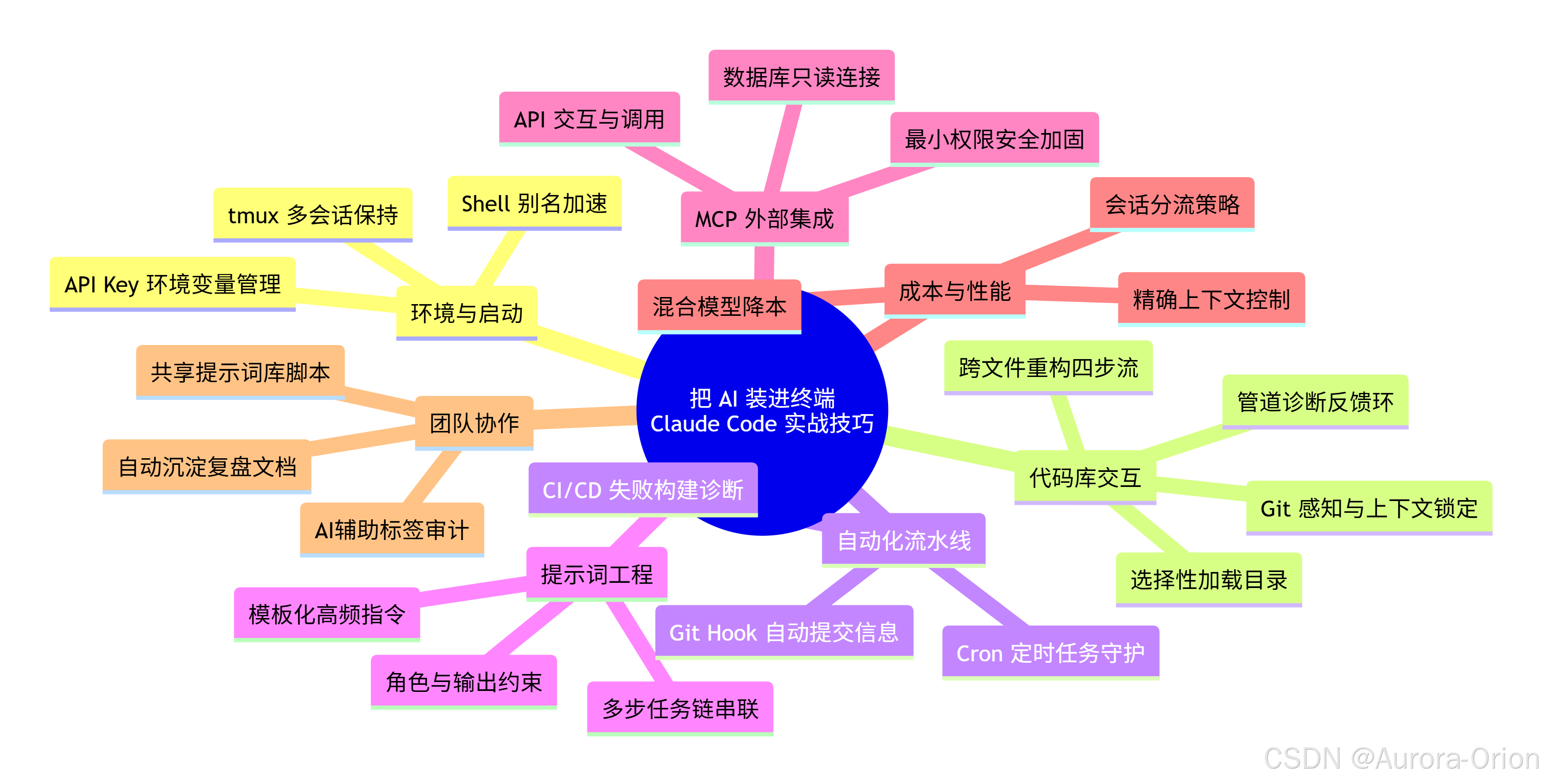
把 AI 装进终端:Claude Code 工程师实战手册
一、环境配置与高效启动
1. 安装与认证的最佳实践
-
使用官方命令
npm install -g @anthropic-ai/claude-code安装,保持全局更新。 -
API Key 管理:不要硬编码在脚本中。将
ANTHROPIC_API_KEY设为环境变量,并建议将其持久化到 shell 配置(.bashrc/.zshrc),同时设置权限chmod 600。 -
多 Key 切换:使用
direnv或项目级.env文件,在不同项目间自动切换 Key,防止开发环境与个人实验混用。
2. Shell 别名加速
在 .bashrc 或 .zshrc 中创建常用别名:
alias cc="claude-code"
alias cca="claude-code --add-dir ." # 将当前目录加入上下文
alias cce="claude-code --explain" # 解释最后一条命令的输出
alias ccf="claude-code --fix" # 尝试修复最后一条命令的错误这些别名能将常见操作压缩到两三个字母,契合终端工作节奏。
3. 多会话管理
-
使用
tmux或screen维持 Claude Code 会话不中断,即使断开 SSH 也可恢复。 -
命名窗口:
tmux new -s claude-backend,方便在多个项目间切换。
二、与代码库交互的核心技巧
1. 智能索引与上下文控制
-
选择性加载目录:不必把整个巨型仓库喂进去,使用
--add-dir仅加载关键模块。例如claude-code --add-dir src/api,减少 token 消耗并提高响应精准度。 -
Git 感知:Claude Code 默认能读取 Git 历史。你可以直接问“上周哪些提交修改了认证模块?简述影响”,无需手动
git log。 -
上下文锁定:在对话中明确“仅基于
src/services下的文件回答”,避免它检索无关代码分支。
2. 跨文件重构的四步命令流
-
梳理结构:“列出所有调用
deprecatedAuth()的文件和具体行号。” -
生成迁移计划:“为新版
authV2()生成一个从旧函数迁移的步骤清单,按风险等级排序。” -
批量修改:“按此计划修改所有文件,保留原有注释和错误处理风格。”
-
验证并提交:“运行
npm test并针对失败的测试直接修复,全部通过后执行git add -A && git commit -m 'refactor: migrate to authV2'。”
3. 诊断与调试的即时反馈环
-
管道输入:将错误输出直接喂给 Claude Code ——
npm test 2>&1 | claude-code "分析失败原因并给出修复代码"。 -
交互式调试:运行程序,将堆栈粘贴进 Claude Code,让它“解释这个 Rust 编译错误并修改代码”。甚至可以要求它“用
dbg!()宏插桩到疑似变量,然后再次运行并分析输出”。 -
日志分析:
tail -f /var/log/app.log | claude-code --stream "实时监控,发现 ERROR 立即总结并建议处理命令"。
三、自动化与流水线嵌入
1. Git Hook 中的 AI 自动化
在 .git/hooks/prepare-commit-msg 中嵌入:
#!/bin/sh
# 自动生成提交信息草稿
claude-code --print "基于当前暂存区的 diff,生成一条简洁的 conventional commit 信息,只输出信息本身" > $1此后每次 git commit 都会预先填入 AI 生成的提交信息。
2. CI/CD 中的智能审查
-
自动化 PR 摘要:在 GitHub Actions 中运行
claude-code --print "为这次 PR 的 diff 写一段面向产品经理的变更总结",将输出贴入 PR 描述。 -
失败构建诊断:CI 脚本里,当
make build失败时,捕获日志并通过claude-code分析,直接在 CI 输出中给出修复建议。
3. 定时任务与看板守护
-
写一个 cron 脚本,每小时运行
claude-code --print "分析 Jira(通过 MCP)中当前迭代的新增 Bug,列出最可能由最近部署引起的 Top 3",将结果发送到 Slack。 -
这需要事先配置好 Jira MCP 服务器,Claude Code 可在非交互模式下直接调用。
四、提示词工程的终端适配
1. 角色设定与输出约束
直接在指令前加上角色和格式要求,例如:
claude-code "你是资深 SRE。仅基于 /var/log 下的日志,用四行以内的文字说明当前系统健康度,最后给出一个 0-100 的评分。"终端版更看重结构的精准性,因为纯文本输出没有 UI 辅助。
2. 多步任务的任务链
-
用
&&或分号串联多个 Claude Code 调用,形成“思考-执行-验证”链条:
claude-code --print "生成一个 SQL 查询以找出重复用户" > query.sql \
&& mysql -u root < query.sql | claude-code "分析结果,如果存在重复则生成清理脚本" > clean.sql \
&& claude-code "审查 clean.sql 的安全性并加注释"每个环节的输出成为下一环的输入。
3. 模板化常用 Prompt
将高频指令保存为文件,如 prompts/code-review.txt:
你是一位严格的代码审查员。审查以下 diff,按三个等级(🔴 必须修改 / 🟡 建议优化 / 🟢 良好实践)输出问题,每个问题附上修改建议和代码示例。
然后通过 claude-code --instructions prompts/code-review.txt 调用,确保一致性。
五、MCP 与外部工具深度集成
1. 构建可执行的工具链
-
数据库直连:配置只读 MCP 服务器连接 PostgreSQL,Claude Code 就能根据模糊描述生成并执行查询,例如“上个月每个国家的订单量趋势”,直接得到数据表。
-
API 交互:通过 MCP 让 Claude Code 调用公司内部服务的 API,实现“帮我生成一个新的测试用户,并返回登录 token”。
-
基础设施即代码:连接 AWS CLI 或 Terraform,让 Claude Code 可查询现有资源状态,并生成安全的变更计划,你确认后再执行。
2. MCP 安全性加固
-
永远在 MCP 配置中声明最小权限,只给 Claude Code 所需的只读或限定写入权限。
-
使用 Claude Code 的
--mcp-config指定项目级配置,不要修改全局默认连接。 -
在自定义指令中明确规定:“任何涉及删除、修改生产数据的命令必须请求人类确认。”
六、成本控制与性能优化
1. Token 消耗的精细管理
-
精确添加上下文:用
--add-dir和--add-file按需引入,而非一次性索引整个仓库。重度仓库可使用.claudeignore文件排除node_modules、dist等。 -
会话分流:简单的问题用
--print单次问答(无状态),需要多轮推理时再进入交互会话。无状态调用成本更低。 -
监控用量:定期检查 Anthropic Console 中的 API 用量报表,或使用
claude-code --status查看当前会话的 token 消耗。
2. 混合模型策略
-
在交互会话中,可以根据任务复杂度切换模型:先让 Claude Code 用 Sonnet 快速生成方案,再要求“用更严密的逻辑(模拟 Opus 深度)重新评估该方案” 。注意 Claude Code 支持通过参数指定模型版本。
-
对于简单的代码生成、注释补全,使用
--model claude-sonnet降低开销。
七、团队协作与知识沉淀
1. 共享提示词库与脚本
-
在团队仓库中维护
prompts/和scripts/目录,将 Claude Code 的高效调用方式固化为脚本。新成员只需./scripts/ai-code-review.sh即可获得统一质量的审查意见。 -
使用 Claude Code 的
--instructions参数加载共享指令,确保团队输出风格一致。
2. 审计与日志
-
所有通过 Claude Code 修改的文件都在 Git 历史中可见。强制提交信息中包含
[AI-assisted]标签,便于后续审查。 -
将 Claude Code 的完整对话日志导出(可配合
script命令记录终端会话),用于团队复盘和知识提取。
3. 从对话到文档
-
在解决完一个复杂问题后,要求 Claude Code “将刚才的调试过程和解决方案生成为 Markdown 文档,保存到
docs/postmortem/”,形成自动化的知识库沉淀。
总结:Claude 终端版的精髓在于将 AI 推理与操作系统能力无摩擦地结合。通过精确的上下文控制、管道串联、MCP 集成和自动化脚本,你可以把它从一个问答工具升维成能独立完成开发、运维、分析任务的 AI 代理。核心心法是:永远为它提供清晰、有限的作战地图,给它手脚(Shell),也给它边界(权限和安全策略)。

欢迎加入 MCP 技术社区!与志同道合者携手前行,一同解锁 MCP 技术的无限可能!
更多推荐

 7
7 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)