AI记忆系统演进 - 从ChatGPT到OpenClaw的上下文工程路线
想象一下这个场景:你把同一个复杂任务,分别丢给 ChatGPT、Cursor、Claude Code、OpenClaw。表面上看,它们都在“调用大模型”。可真跑起来,你很快会发现差别根本不只在模型能力,而在它到底记住了什么、怎么记、什么时候拿出来用。
我这次专门把四家的官方文档重新对了一遍,越看越觉得,所谓 Agent 竞争,真正卷到后面,卷的不是“窗口多大”,而是“上下文工程做得有多成熟”。
因为模型本身并没有真正意义上的长期记忆,所谓“记住你”,本质上还是外部系统把一些状态重新塞回上下文里。
第一阶段:ChatGPT 先解决“它要更懂你”
如果从产品时间线往前看,ChatGPT 代表的是第一阶段。
它的记忆系统核心不是工程接口,而是用户体验。官方现在公开的几层能力,包括 Custom Instructions、Saved Memories、Reference chat history,以及项目空间里的 Projects。
这些东西合在一起,目的很明确:让 ChatGPT 在后续对话里更像“持续认识你的人”。
这套设计很适合普通用户。你不用管文件放哪,也不用维护规则目录,只要持续使用,它就能慢慢知道你的偏好、习惯、长期目标。
问题也很明显:它更像平台托管的个性化层,而不是工程团队可审计、可版本化、可复用的上下文资产。
ChatGPT 的“记忆”,本质上更接近用户画像系统;它解决的是连续对话体验,而不是复杂工程协作。
第二阶段:Cursor 开始把记忆变成项目能力
到了 Cursor,这件事明显开始变味了。它不再主要关注“你喜欢什么表达方式”,而是开始关心“这个仓库应该怎么工作”。
官方文档现在把长期上下文拆成几类:User Rules、Project Rules、AGENTS.md,再加上按项目范围自动生成的 Memories。
这一步很关键。因为记忆的重心从“我是谁”,变成了“这个代码库是什么”。
AI 需要知道的,不再只是你的口头偏好,而是这个项目用什么架构、哪些目录有什么约束、提交改动时该遵守什么规则、哪些经验教训应该在后续会话里继续生效。
说白了,Cursor 把“记忆”从聊天附属功能,推进成了repo 内的生产资料。
它已经不是单纯想让 AI 更懂用户,而是想让 AI 更懂这个代码仓库的做事方式。
第三阶段:Claude Code 把上下文工程文件化、分层化
Claude Code 再往前走了一步,而且这一步我觉得非常像“工程师写给工程师”的设计。
它把长期信息明确拆成两类:一类是人显式维护的 CLAUDE.md,另一类是 Claude 自己学习后写下的 auto memory。同时,它还支持组织级、用户级、项目级、本地项目级等不同层次的记忆来源。
更重要的是,这套机制是文件系统友好的。
规则可以放进 .claude/rules/,目录树会按层级向上查找,必要时还能用 @路径 导入额外文件,Skills 也是按需加载,而不是一股脑塞进默认上下文里。
这个变化表面看只是“多了几个 markdown 文件”,实际不是。它回答的是几个更底层的问题:哪些信息应该每次都带上,哪些只在某个目录下生效,哪些是团队规范,哪些只是个人习惯,哪些该一直存在,哪些应该按需读取,避免把窗口撑爆。
如果说 Cursor 是把规则系统化,Claude Code 更像是在把“上下文工程”本身做成一套可读、可写、可组合的文件操作系统。
第四阶段:OpenClaw 开始把记忆抬升为 Agent 架构
OpenClaw 再往前走,思路已经不只是 IDE 助手,而是 Agent runtime 了。
它文档里一个特别重要的区分,就是把 context 和 memory 分开定义。
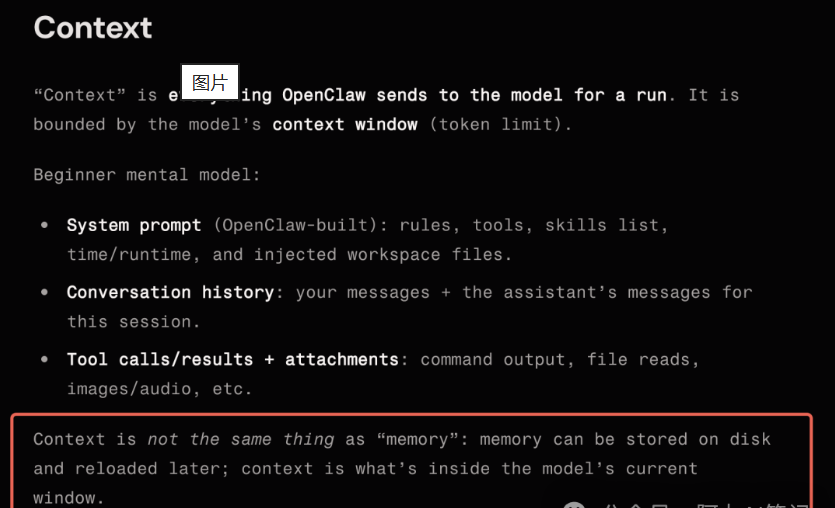
context 是这一轮真正进模型窗口的内容,memory 则是存在磁盘里、之后可以再检索和装配回来的持久状态。
所以 OpenClaw 的记忆系统,不只是几份说明文件。它一方面有像 AGENTS.md、SOUL.md、TOOLS.md 这样的 bootstrap 文件,作为启动时注入的行为框架;另一方面又有 memory/YYYY-MM-DD.md、MEMORY.md 这类持久记录,再配合 memory_search、memory_get 和可插拔的 memory 插件去做召回。
这就意味着,OpenClaw 已经不满足于“让 AI 记住一些事”,而是在认真处理一个更难的问题:当 Agent 连续运行很多轮、跨很多天、调用很多工具之后,状态到底怎么存、怎么压、怎么取、怎么保持可观测。
四套系统看起来不同,其实在回答同一个问题
我想了想,这些差异既来源于产品本身定位的差异,也包含了随着时间演进的技术升级,
它们底层命题其实是一致的:模型没有真正意义上的长期记忆,那系统应该如何用外部状态管理,制造出“它记得住”的体验?
ChatGPT 记的是用户偏好,Cursor 记的是仓库规则,Claude Code 记的是工作树里的层级知识,OpenClaw 记的则是一个 Agent 在真实运行中的状态资产。
换句话说,这条演进线不是简单的产品替代关系,而是记忆对象在不断迁移:
• 在 ChatGPT 时代,记忆服务的是“连续对话”。• 到了 Cursor,记忆服务的是“持续开发”。• 到了 Claude Code,记忆服务的是“上下文治理”。• 到了 OpenClaw,记忆服务的是“长期运行的 Agent 系统”。
真正的分水岭,不是窗口大小,而是状态管理能力
这也是为什么我越来越觉得,只盯着上下文窗口大小,其实很容易看偏。
100万 tokens、200万 tokens 当然重要,但那更像给系统更大的缓存。真正决定一个 Agent 能不能做长期任务的,还是它有没有稳定的状态管理机制:什么该长期保存,什么该临时压缩,什么该在下一轮继续注入,什么应该靠检索召回而不是全量塞进去。
从这个角度看,ChatGPT 到 Cursor 到 Claude Code 到 OpenClaw,不只是产品形态在变,而是在一点点把“记忆”从体验功能,升级成工程基础设施。
前面更像是助手懂不懂你,后面越来越像系统会不会失忆、会不会跑偏、会不会在第 20 轮之后还知道自己要干什么。
说到底,所谓“AI 记忆系统”并不是模型突然会记事了,而是外部系统终于学会了怎么替模型管理状态。
如果这条路线继续往前走,我觉得下一阶段大概率会出现更清晰的分层:
- 指令记忆、事实记忆、过程记忆分开管理;
- 短期上下文和长期记忆自动压缩;
- repo 记忆、个人记忆、团队记忆有明确边界;
最后,记忆本身会像代码一样变成可审计、可版本化、可测试的资产。
这时候你再回头看,就会发现这几家产品真正串起来的,不是“谁更聪明”,而是同一个工程问题的不同阶段答案:当模型天生会忘,系统该怎么帮它记。
学习资源推荐
如果你想更深入地学习大模型,以下是一些非常有价值的学习资源,这些资源将帮助你从不同角度学习大模型,提升你的实践能力。
一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

因篇幅有限,仅展示部分资料,需要点击文章最下方名片即可前往获取
二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示

因篇幅有限,仅展示部分资料,需要点击文章最下方名片即可前往获取
三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。

因篇幅有限,仅展示部分资料,需要点击文章最下方名片即可前往获取
四、AI大模型商业化落地方案

作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。

欢迎加入 MCP 技术社区!与志同道合者携手前行,一同解锁 MCP 技术的无限可能!
更多推荐

 5
5 0
0- 0



 已为社区贡献33条内容
已为社区贡献33条内容

所有评论(0)