大模型核心概念梳理
从一张全景图开始
MCP、Agent、Skill、loop、上下文……这些词你大概都单独见过,但凑一起就糊了:Skill 和 MCP 到底差在哪?Agent 和"调一次大模型"有什么不一样?
问题在于,它们听起来平级,其实是一层套一层的。先记住这张图,后面每个概念都能对号入座。
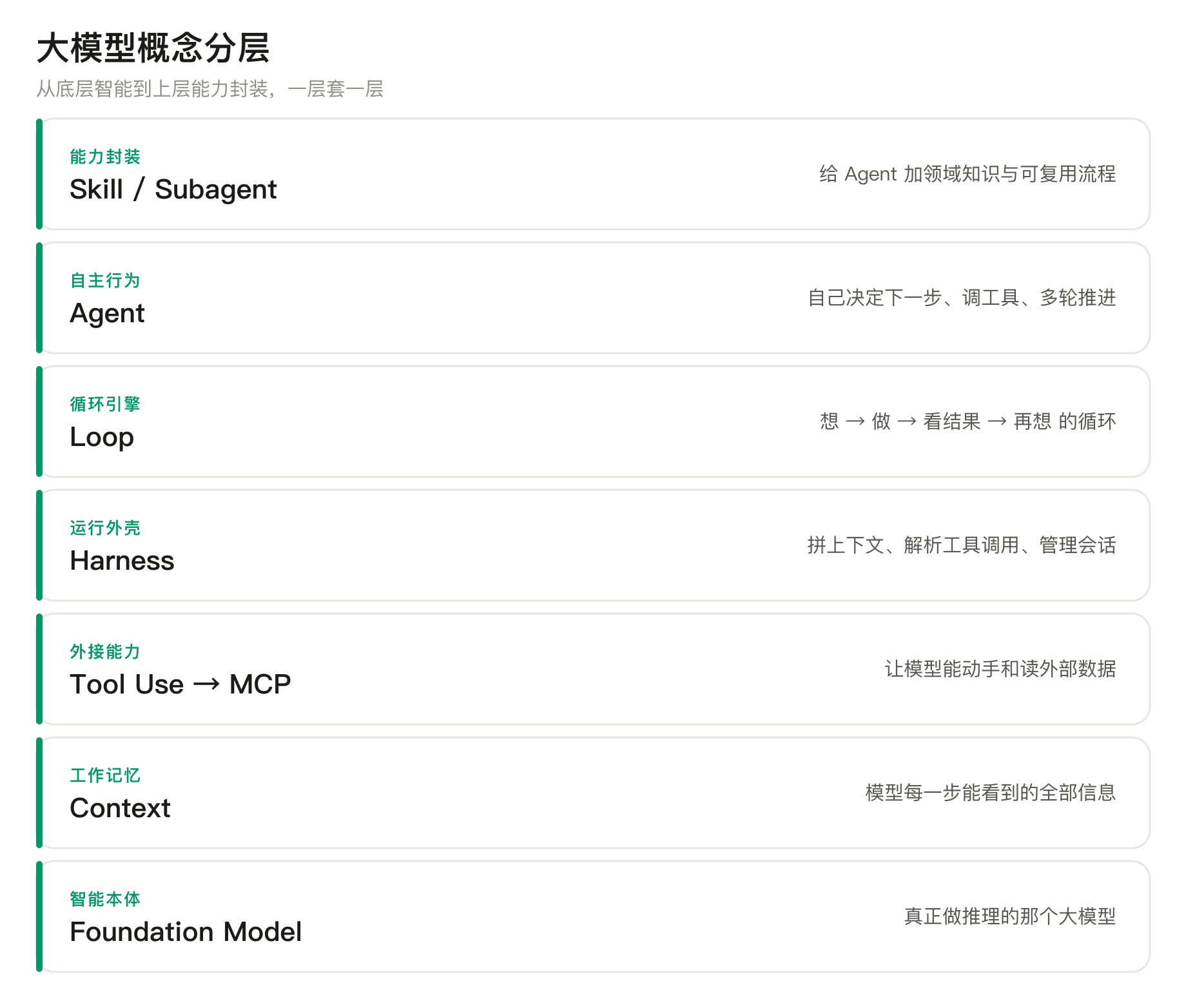
一句话串起来:模型底座提供智能,上下文是它的工作记忆,harness 负责把上下文喂进去、把输出解析出来,loop 让这个过程反复迭代,tool use / MCP 让它能调外部能力,Agent 是跑起来的整套自主体,Skill 则是按需加载的领域专长。
智能的本体:模型底座
它是什么
真正做推理的那个预训练大模型,所有上层能力的发动机——Claude Opus、GPT、Gemini、开源的 Llama / Qwen 都属于这一层。
它本质是个无状态的函数:给一段文本(上下文),吐出下一段文本。可以拿它跟你写的普通函数类比——同样的输入给同样的输出,两次调用之间不留任何痕迹。它不记事、不会自己调工具、不会循环,也"记不得"你上一句问过什么;这些能力全是上层后加的。
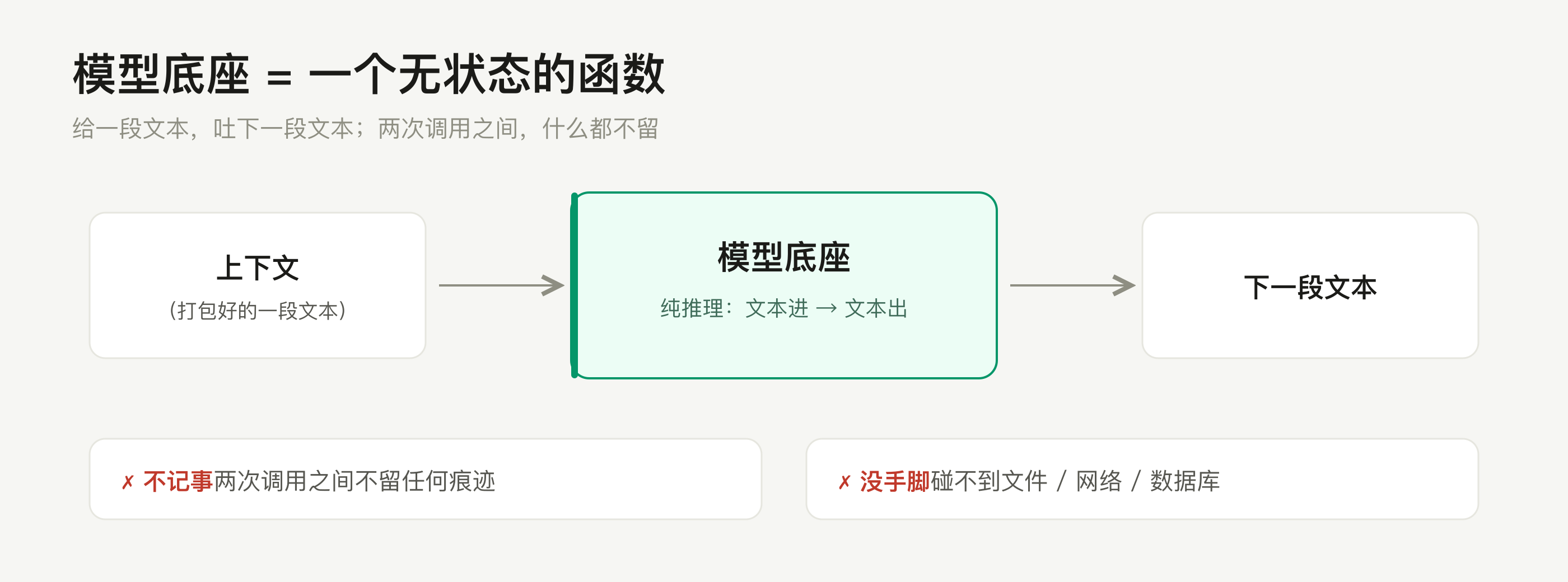
它是可替换的
正因为底座只负责"推理"这一件事,同一套上层框架可以随意换底座:复杂任务上 Opus,简单总结换便宜的 Haiku,成本太敏感甚至换开源的 Qwen 自己部署——上层框架一行代码都不用改,权衡的无非是智能 / 成本 / 延迟。后面所有概念,都是围绕这个无状态函数做的"包装"。
工作记忆:上下文
模型每一步能看到的全部
模型没有长期记忆,每次推理都是把当前所有相关信息打包成一段文本喂进去——这段文本就是上下文,它的容量上限叫上下文窗口(以 token 计)。里面通常装着:系统提示、工具定义、历史对话、检索到的资料、当前任务、工具返回结果。
你跟它连续聊,感觉它"记得"前面说过的话——其实不是它记得,是 harness 每一轮把需要的历史重新拼进这段文本喂进去,才制造出连续的错觉。
常见误区:上下文 ≠ 模型的记忆力。模型不记事,是 harness 每一轮重新把信息拼进上下文,制造出"它记得"的假象。
它是有限资源,于是有了三件事
窗口越大能塞越多,但更慢更贵,而且"塞太多反而注意力分散"——很多人发现长对话聊到后面模型像变笨了,往往就是上下文塞太满、关键信息被淹没。围绕这个约束,衍生出一整套实践:

上下文工程
决定"哪一步放什么、怎么排、放多少"。比如让它修一个 bug,不是把整个项目几百个文件都塞进去,而是只放当前文件 + 报错 + 相关的几个函数定义——多了是干扰,少了它看不全。它比"提示词工程"更系统:管的是整段上下文的布局,而不只是怎么问那一句话。
RAG(检索增强)
你有一整个 wiki 的资料,不可能全塞进窗口。RAG 是先检索、只把最相关的几段摘进上下文,像开卷考试时翻到相关那一页,而不是把整本书都搬上来。
压缩 / Compaction
对话超出窗口时,把早期内容自动摘要替换:一段聊了俩小时的对话快塞不下了,系统把前一小时总结成几句话替换掉、只留最近的细节,腾出空间继续。
让模型跑起来:Harness 与 Loop
模型底座只是文本进文本出,自己什么都不会主动做。把它变得"能用、能反复干活"的,是这两层。
Harness:包在模型外的运行壳
Harness 负责把活儿组织起来:组装每一轮上下文、调模型 API、解析输出里的工具调用并执行、管理会话与压缩。
举个具体的:你让它"查下明天的日历",模型本身只会输出一句"我要调用查日历工具"——真正起身去执行、把查到的结果塞回上下文的,是 harness。
Claude Code、Cursor、Codex 本质上就是围绕同一个模型做的不同 harness——底座一样,harness 不同,体验天差地别。你平时写的那段"调用模型 + 执行工具"的循环代码,就是你自己的 harness。
边界:harness 是名词性的"壳 / 框架";agent 是这套壳跑起来、被赋予目标后表现出的"自主行为体"。
Loop:反复推进的引擎(当下最火)
单次问答没有循环。真实任务需要多步、且每步依赖上一步结果,loop 就是这个反复推进的引擎。
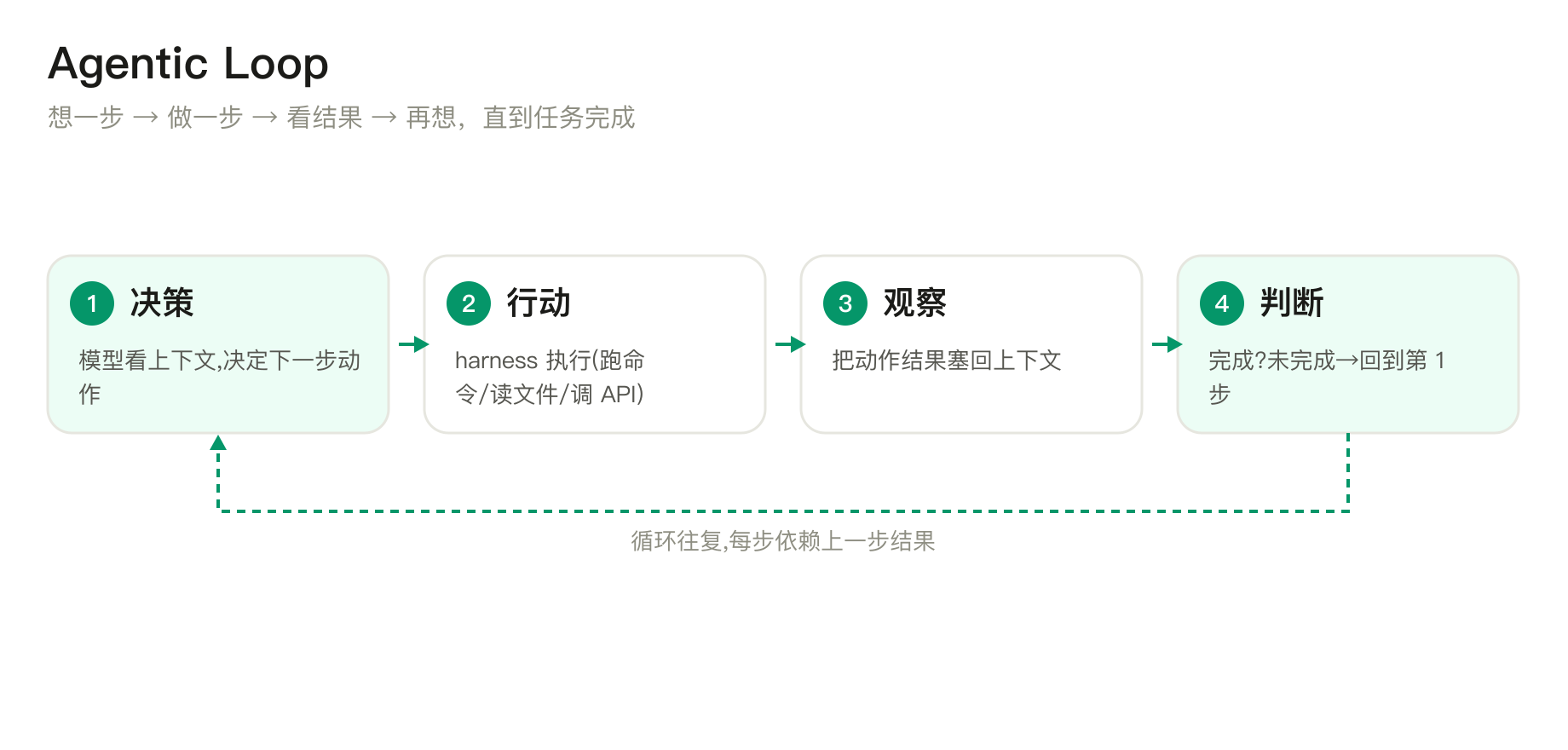
拿"修一个 bug"举例,它会这样转圈:读报错 → 猜哪个文件出问题 → 改 → 跑测试 → 还是红的 → 再改……一圈一圈,直到测试变绿。什么时候停不是代码写死的,是模型自己判断"搞定了"、不再要求调工具为止——同一个 bug,可能转 3 圈,也可能转 20 圈,边走边定。
为什么现在特别火
模型的推理与工具调用能力到位后,"会循环"比"单次更聪明"更能解决真实问题——这正是从"聊天机器人"到"会干活的 agent"的关键跃迁。它也带火了一批词:agentic loop、长程任务、自我纠错、ReAct、反思。
它带来的新工程问题
循环什么时候停?跑偏了怎么办?token 预算怎么控?要不要人来把关?这些是 loop 时代才需要认真回答的。
边界:loop 是机制(反复迭代),agent 是跑这个机制的主体。没有 loop 的"agent",其实只是单次问答。
让模型动手:Tool Use 与 MCP
Tool Use:让模型发起调用
你在上下文里告诉模型"有哪些工具、各要什么参数"。模型需要时不直接执行,而是输出一个结构化的"我要调用工具 X、参数 Y";harness 接到后真正去执行,把结果塞回上下文——这正是 loop 的一环。
打个比方:模型像在餐厅点菜,它只负责喊一句"来份番茄炒蛋",自己并不进厨房——接了单真正去炒的是 harness。tool use 就是让模型从"只会说"变成"能查能改能算"的那道关。
那"打开文件"这种底层操作,到底谁在做
一个常见疑问:模型说要"读取某个文件",可它本身碰不到操作系统,这行 open() 到底是谁执行的?答案是 harness 这一层,不是模型。完整跟一遍"读取 /tmp/a.txt":
- 模型只吐出一段结构化文本:
{tool: read_file, path: /tmp/a.txt}——它没打开任何文件,连进程都不是它的,纯粹是"说了句要调用"。 - harness(一个真实跑在你机器上、有 OS 权限的程序)接住、解析,去调用对应工具的实现代码——那段代码里就是大白话的
os.ReadFile("/tmp/a.txt"),这一行才真正触发操作系统的系统调用。 - 读到的内容塞回上下文,模型下一轮才"看见"文件内容。

所以"打开文件"的能力不在模型里,也不是凭空包装出来的——就是一段普通代码 + 操作系统,模型只是发起请求的那一方。这段实现代码具体住哪,看工具类型:内置工具(Read / Bash 等)直接打包在 harness 自己里;MCP 工具住在独立的 MCP server 进程里;自定义工具就是你写的那个函数。(要不要真执行、要不要先弹权限确认、要不要丢沙箱里跑,这些"把关"也都在 harness 这层。)
MCP:标准化的接入层
tool use 解决了"模型能调工具",但每个应用接每个工具都要重写一套适配——5 个应用 × 10 个工具就是 50 套互不通用的胶水,典型的 N×M 重复劳动。MCP 把它标准化。
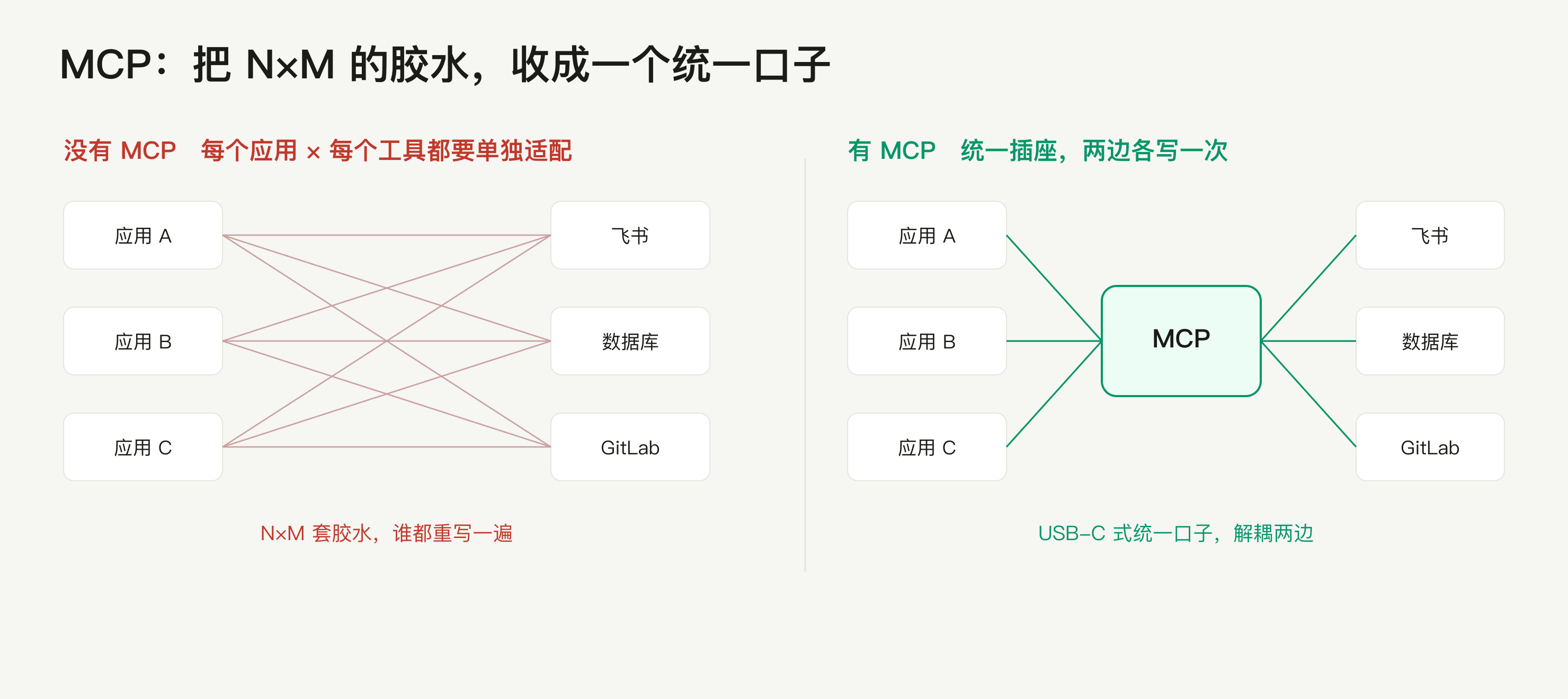
解决的痛点
MCP Server 把某个系统(飞书、GitLab、数据库、浏览器)的能力包成标准工具,写一次;MCP Client(Claude Code 等)统一发现并调用。你给 Claude Code 配的那些工具,多半就是 MCP server。
一个类比
MCP 之于"AI 接工具",约等于 USB-C 之于设备接外设、LSP 之于编辑器接语言——以前每个设备一种插头,立一个统一口子后,两边彻底解耦。
边界:MCP 不是新的模型能力,而是 tool use 的标准化分发层。
跑起来的主体:Agent
判定标准:会不会自主多步
把"模型底座 + 上下文 + loop + 工具"组装起来、能自己决定多步行动去完成目标的系统,才叫 agent。
同样是"写一份调研报告":对一颗光秃秃的模型来说,就是吐一段文字;对一个 agent 来说,是搜资料 → 读文档 → 起草 → 自查 → 保存一整套自己走完的多步流程。关键词就两个:自主和多步。"自己读了报错、决定改哪个文件、再跑测试"的是 agent;问一句答一句的,不是。
衍生形态
- Subagent:主 agent 派生去做子任务,跑完把结论带回(适合并行、隔离上下文)。比如让 3 个 subagent 同时查 3 个模块,各查各的,最后汇总。
- Multi-agent:多个 agent 分工协作,典型的如"一个写、一个审"。
- Managed Agent:把 loop 和工具执行环境托管到服务端,你只管创建和调用。
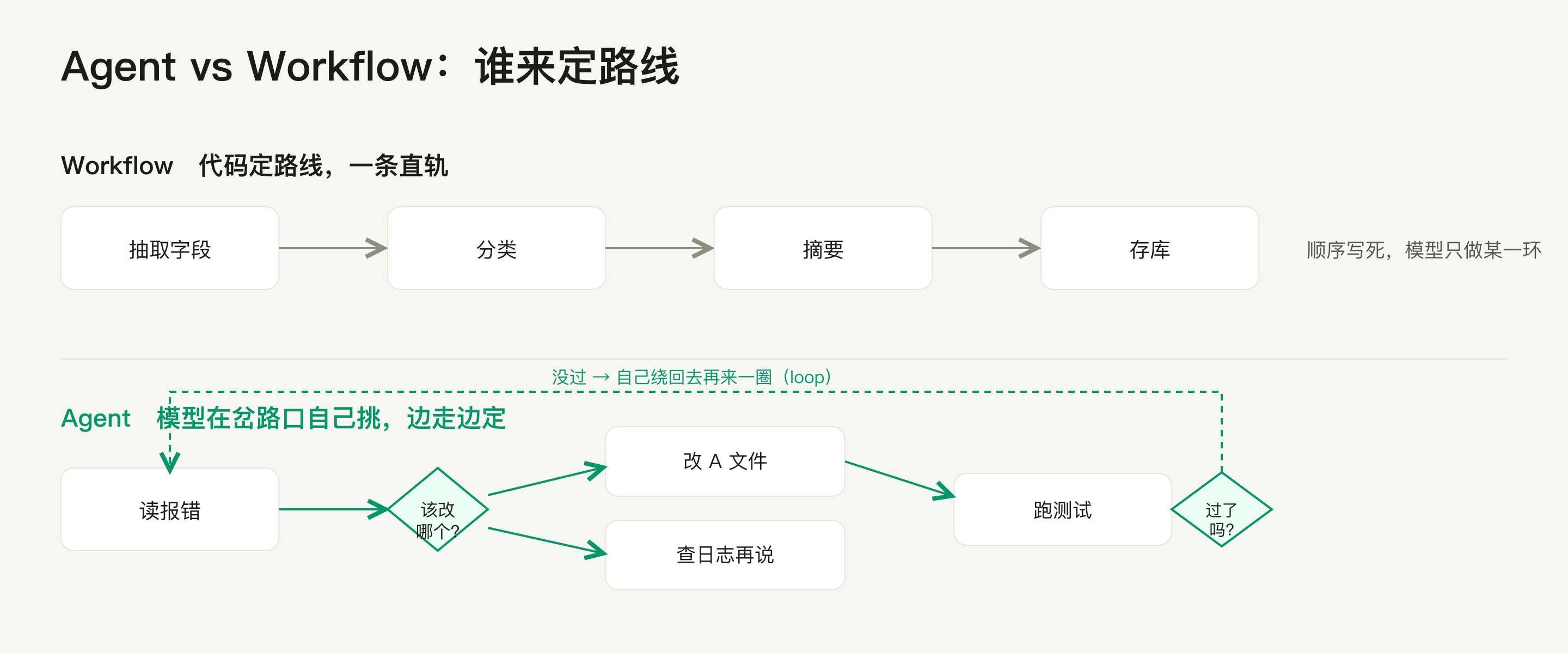
边界:Agent vs Workflow
别把"任何调一次大模型的功能"都叫 agent。像"抽取字段 → 分类 → 摘要 → 存库"这种你用代码把顺序写死的,是 workflow——模型只是流水线上被叫去做某一环。agent 是模型自己决定流程。一句话分辨:路线是代码定的(一条直轨),还是模型在岔路口自己挑的(边走边定)。
注入专长:Skill
它是什么
一份可按需加载的领域专长包:把某类任务的知识、规范、步骤、脚本打包(通常是带 SKILL.md 的目录)。Agent 判断当前任务匹配时,把这份说明加载进上下文,于是"临时变成"该领域专家。
举个我们自己的例子:团队里"留存口径到底怎么算""技术方案得按哪个固定框架写""操作飞书文档用哪几条命令"——这类私有约定,与其每次在 prompt 里重新交代一遍,不如沉淀成一个 skill,用到才加载。
和相邻概念的边界
- vs Tool / MCP:MCP 给的是"能做某动作"的能力;skill 给的是"该怎么做这件事"的知识与流程,skill 里常会去调 tool / MCP。一个解决"能不能做",一个解决"做得好不好"。
- vs 系统提示:skill 是按需、模块化加载的,不像 system prompt 常驻——挂十几个 skill 也只占个标题,用到才把正文读进上下文,省地方、也便于复用组合。
- vs Subagent:skill 是"加载一段专长知识",subagent 是"派一个独立 agent 去干",两者常配合。
把它们串起来:一次 AI 编码任务
概念单看是孤立的,放进一个真实任务里就活了。以"让 Claude Code 修一个 bug"为例,把前面的词放一遍电影:
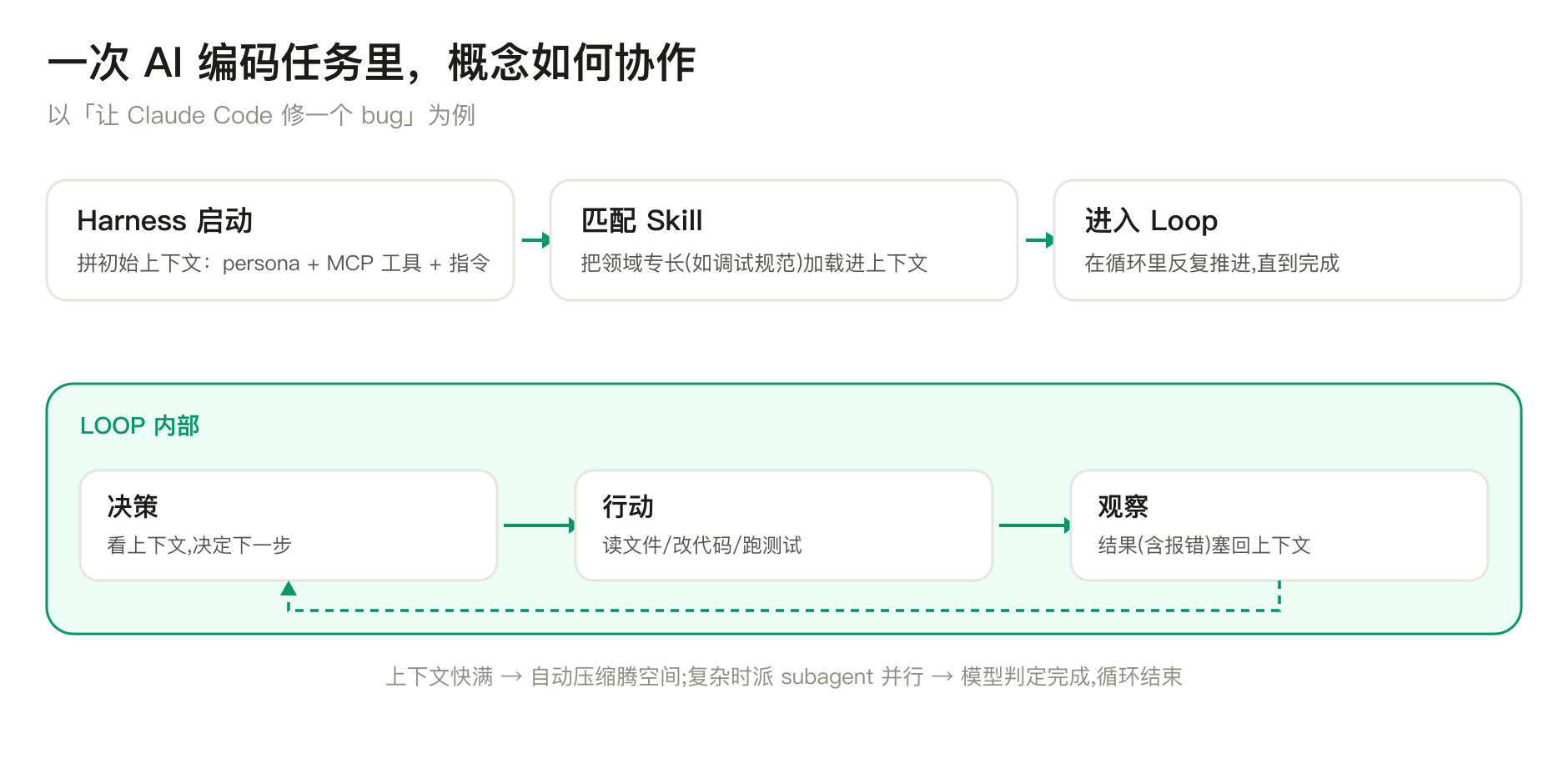
Harness 启动,拼好初始上下文(persona + MCP 工具 + 指令);任务匹配到某个 Skill,其流程被加载进来;接着进入 Loop:模型底座决定"读哪个文件"→ 发起 tool use → harness 执行(可能经 MCP)→ 结果塞回上下文 → 再决定下一步……上下文快满就触发压缩。这个"有目标、自主多步推进"的整体,就是一个 Agent 在工作;复杂时它还会派 subagent 并行。直到模型在 loop 里判定"测试通过",循环结束。
速查与避坑
一句话速查表
| 概念 | 一句话 | 解决什么 |
|---|---|---|
| 模型底座 | 真正推理的大模型本体 | 提供原始智能(无状态文本函数) |
| 上下文 | 模型每步能看到的全部信息 | 模型的"工作记忆" |
| Harness | 包在模型外的运行框架 | 拼上下文、解析工具调用、管会话 |
| Loop | 想→做→看→再想的反复迭代 | 让模型完成多步长程任务 |
| Tool Use | 模型发起调用外部函数 | 让模型能"动手"而不只说 |
| MCP | 工具/数据接入的标准协议 | 统一口子,消除 N×M 胶水 |
| Agent | 自主多步完成目标的系统 | 从"会聊"变成"会干活" |
| Skill | 按需加载的领域专长包 | 给通用 agent 注入私有知识/流程 |
容易踩的认知误区
- "上下文 = 记忆":模型不记事,是 harness 每轮重新拼出来的。
- "调一次大模型 = agent":没有自主多步 loop 的是 workflow,路线是你代码写死的。
- "MCP 是新模型能力":它只是 tool use 的标准化分发协议。
- "Skill 是代码插件":核心是喂给模型的知识与流程,本质是组织好的上下文。
- "harness 和 agent 是一回事":harness 是壳,agent 是壳跑起来后有目标的自主体。
推销一下自己的 skill,本文内容由 doc-generate-skill 自动生成。有兴趣的朋友可以使用

欢迎加入 MCP 技术社区!与志同道合者携手前行,一同解锁 MCP 技术的无限可能!
更多推荐
 2
2 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)