LangChain x PaddleOCR:重磅集成!让 AI Agents 真正看懂复杂文档

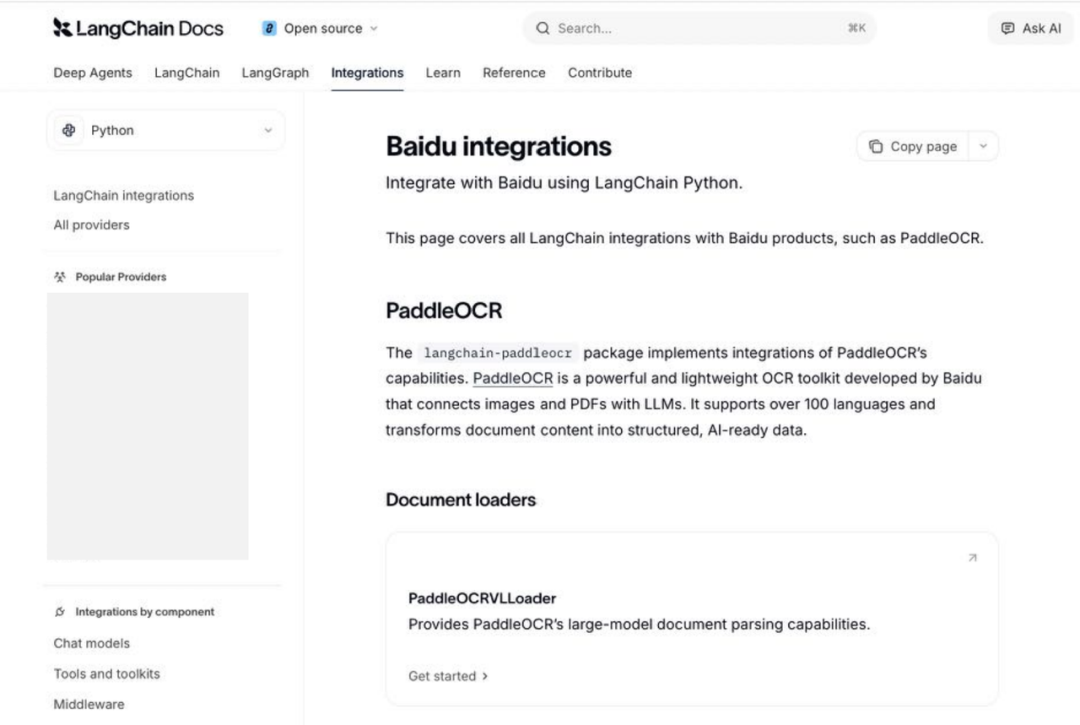
LangChain ——全球最具影响力的开源 LLM 应用工程框架之一,承担着模型、工具、检索与执行机制的“编排层”角色,为 Agent 与各类 AI Workflow 提供统一的工程基础。现在,LangChain 已正式集成 PaddleOCR-VL-1.5。通过全新的 PADDLEOCRVLLoader 组件,PaddleOCR 正为 LangChain 的 AI Agents 补全复杂文档理解这一关键能力层,让系统从“读取文本”进一步迈向“理解文档”。
👉了解 langchain-paddleocr:
https://github.com/PaddlePaddle/PaddleOCR/tree/main/langchain-paddleocr

强强联手
为 LangChain 生态注入结构化文档理解能力
LangChain 通过统一接口与 LCEL 机制,让开发者能够像搭积木一样连接模型、向量数据库和工具,简化 AI 应用从原型到生产的演进过程,而 PaddleOCR-VL-1.5 的接入则为 LangChain 注入关键的文档理解增量能力。开发者已经可以通过 PADDLEOCRVLLoader 将 PaddleOCR-VL-1.5 直接接入 LangChain,该 Loader 支持本地文件与远程 URL 输入,解析后可返回文本内容且保留版面相关信息,并将完整响应写入 metadata,便于进一步衔接检索、问答、Agent 与后处理等下游流程。
-
从“读文本”到“读结构”:PaddleOCR-VL-1.5 能从 PDF 和图像中提取文本与版面信息,并把内容转成 structured, AI-ready data,输出结构化数据。基于此,LangChain 中的 Agents 能够精准识别 PDF 中的列关系、表格数据和层级标题,真正理解文档的排版语义;
-
无缝衔接 LangChain 生态体系:轻松接入 LangChain 工作体系,其识别结果可直接进入 LangSmith 进行调试与可观测性分析;面向当下备受关注的 Deep Agents 场景,也可作为复杂、多步骤任务中的文档输入能力接入,支持规划、子智能体协作与长上下文管理;同时,还可以在 LangGraph 中作为输入源接入复杂多代理工作流;
-
工程化精细保障:PaddleOCR-VL-1.5 提供的
raw_response允许访问底层的文档解析结果(如版面元素的位置、置信度),满足开发者对细粒度控制的需求;
-
适配全球化文档场景:支持 110+ 种语言,能在文档读取阶段处理多语言资料,为后续 LangChain 工作模块建立统一输入基础。

轻松上手
在 LangChain 中调用 PaddleOCR-VL-1.5
下文将介绍如何在 LangChain 中调用 PaddleOCR-VL-1.5。
1. 安装依赖
先安装 LangChain 对应的 PaddleOCR 集成包:
pip install langchain-paddleocr2. 准备 API URL 与 Access Token
调用前,需要先准备两项信息:
-
可用的 PaddleOCR-VL-1.5 API URL;
-
PaddleOCR 官方网站的接口访问凭证
access_token
获取方式如下:
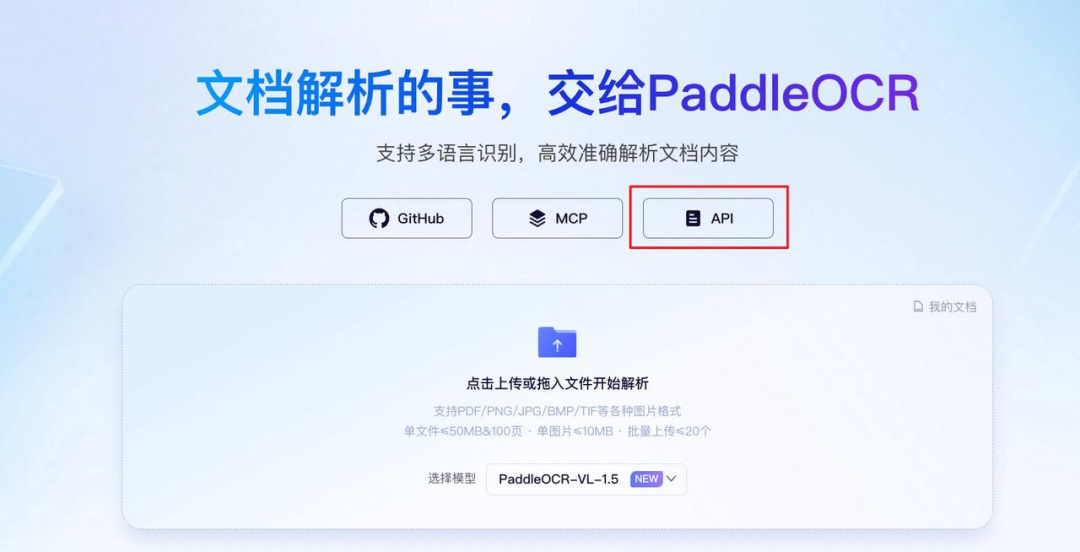
a. 访问 PaddleOCR 官方网站:
https://www.paddleocr.com
b. 点击左上角【API】 ;
c. 选择【PaddleOCR-VL-1.5】;
d. 打开示例代码,复制其中的 【TOKEN】(访问令牌) 和 【API_URL】。
(填写PaddleOCR官方网站访问令牌-用于接口鉴权,支持申请每天免费解析数万文档页数)
Token 可以直接在代码里传入,也可以通过环境变量 PADDLEOCR_ACCESS_TOKEN 配置。推荐做法是先在环境变量中配置 token,后续初始化时就不必在代码中明文写出 token:
export PADDLEOCR_ACCESS_TOKEN="your-access-token"3. 快速验证
完成安装和鉴权后,可以直接初始化 Loader,传入文档路径与 API 地址,进行快速验证:
from langchain_paddleocr import PaddleOCRVLLoaderfrom pydantic import SecretStr
loader = PaddleOCRVLLoader( file_path="path/to/document.pdf", api_url="your-api-endpoint", access_token=SecretStr("your-access-token"))
docs = loader.load()
print(docs[0].page_content[:500])print(docs[0].metadata["source"])如果已经通过环境变量配置了 PADDLEOCR_ACCESS_TOKEN,初始化时可以省略 access_token。
4. 解析远程文档
除了本地文件,PaddleOCRVLLoader 也支持直接处理远程文档的 URL,满足快速验证效果或者处理在线文档资源的场景:
from langchain_paddleocr import PaddleOCRVLLoader
loader = PaddleOCRVLLoader( file_path="https://arxiv.org/pdf/2408.09869", api_url="your-api-endpoint")
docs = loader.load()
for doc in docs[:2]: print(f"Content: {doc.page_content[:200]}...") print(f"Source: {doc.metadata['source']}") print("---")5. 一次处理多份文件
如果需要将多份 PDF、图片或混合来源文档同时输入 LangChain,可以直接传入列表,PaddleOCRVLLoader 会根据文件后缀自动识别类型,适合批量解析资料包、混合文档集或多模态知识源,支持的图片格式包括 .jpg、.jpeg、.png、.bmp、.tiff、.tif、.webp,文档格式支持 .pdf。
from langchain_paddleocr import PaddleOCRVLLoader
files = [ "document.pdf", "image.jpg", "https://example.com/report.pdf"]
loader = PaddleOCRVLLoader( file_path=files, api_url="your-api-endpoint")
docs = loader.load()print(f"Loaded {len(docs)} documents")6. 面向复杂文档的进阶配置
若需处理版式复杂的真实业务文档,可以进一步启用 Loader 的高级配置项进行微调,详细可调参数可见下文中的 LangChain 官方文档。以下列出部分重要参数:
-
use_doc_orientation_classify:是否启用文档方向分类; -
use_doc_unwarping:是否启用版面图像矫正; -
use_layout_detection:是否启用版面检测; -
use_chart_recognition:是否启用图表识别; -
use_seal_recognition:是否启用印章识别; -
use_ocr_for_image_block:是否对图像块进行 OCR; -
restructure_pages:是否重构多页结果; -
merge_tables:是否合并跨页表格; -
relevel_titles:是否重建多级标题; -
prettify_markdown:是否美化输出的 Markdown 文本; -
visualize:是否在输出中包含可视化结果; -
timeout:请求超时时间;
配置方式如下所示:
from langchain_paddleocr import PaddleOCRVLLoader
loader = PaddleOCRVLLoader( file_path=["document1.pdf", "document2.jpg"], api_url="your-api-endpoint", file_type=None, use_doc_orientation_classify=True, use_doc_unwarping=True, use_layout_detection=True, use_chart_recognition=True, use_seal_recognition=True, merge_tables=True, restructure_pages=True, relevel_titles=True, prettify_markdown=True, timeout=300)
docs = loader.load()7. 读取结构化结果与原始响应
在 LangChain 中,load() 返回的是文档对象。最常用的字段是:
-
page_content:可直接用于下游问答、切分或检索的文本内容; -
metadata["source"]:文档来源; -
metadata["paddleocr_vl_raw_response"]:完整解析响应,可用于调试和二次开发.
该部分 metadata 适合完成后续版面级后处理、结构调试、表格抽取或者页面分析任务,示例如下:
docs = loader.load()
first_doc = docs[0]raw_response = first_doc.metadata["paddleocr_vl_raw_response"]
print(first_doc.page_content[:300])print(first_doc.metadata["source"])print(raw_response.keys())print(len(raw_response["result"]["layoutParsingResults"]))👉 详情请参考 LangChain官方文档:
https://docs.langchain.com/oss/python/integrations/document_loaders/paddleocr_vl

最佳实践
升级 LLM 应用生产力
LangChain 生态为开发者提供了构建可控、可扩展智能体系统的统一工程框架,而 PaddleOCR-VL-1.5 的接入,则进一步补齐了面向 Agent 场景的文档理解入口,使复杂文档能够以更高质量、更结构化的方式进入应用链路。此次集成提升了 LLM 应用在信息摄取阶段的解析能力,也使文档中的文本、版面与结构语义能够被后续检索、推理与执行模块更充分地继承和利用。随着智能体系统逐步具备跨语言与复杂版式文档处理能力,文档型 AI 应用也将加速迈向更高水平的工程可用性与业务落地能力。
例如,基于 langchain-paddleocr 可以快速搭建一套面向证件与票据场景的智能处理工作流:先对证件、发票等文档完成版面解析与结构化转换,再结合 LangChain 与 LLM 进行关键信息抽取和结果校验,形成从 OCR 解析、结构化提取到业务系统接入的完整链路。对于标准化程度较高的证照与票据,该方案能够高效完成高频字段提取;面对格式更复杂、字段更灵活的长尾文档,也具备较好的扩展能力,适用于金融 KYC、企业报销、政务审批等典型场景。
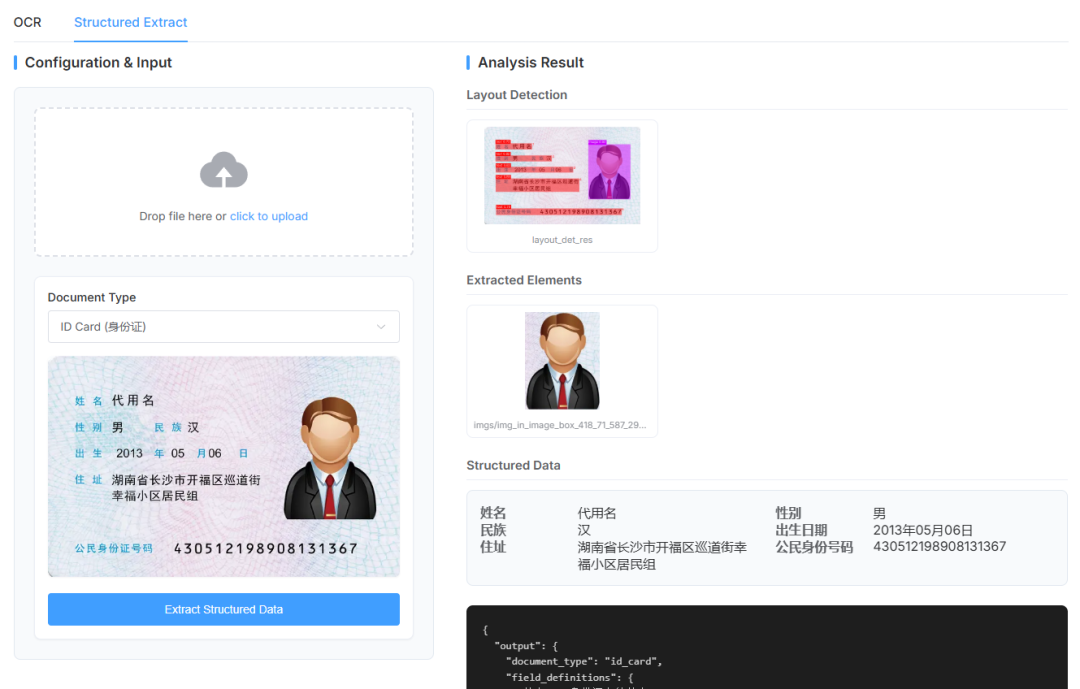
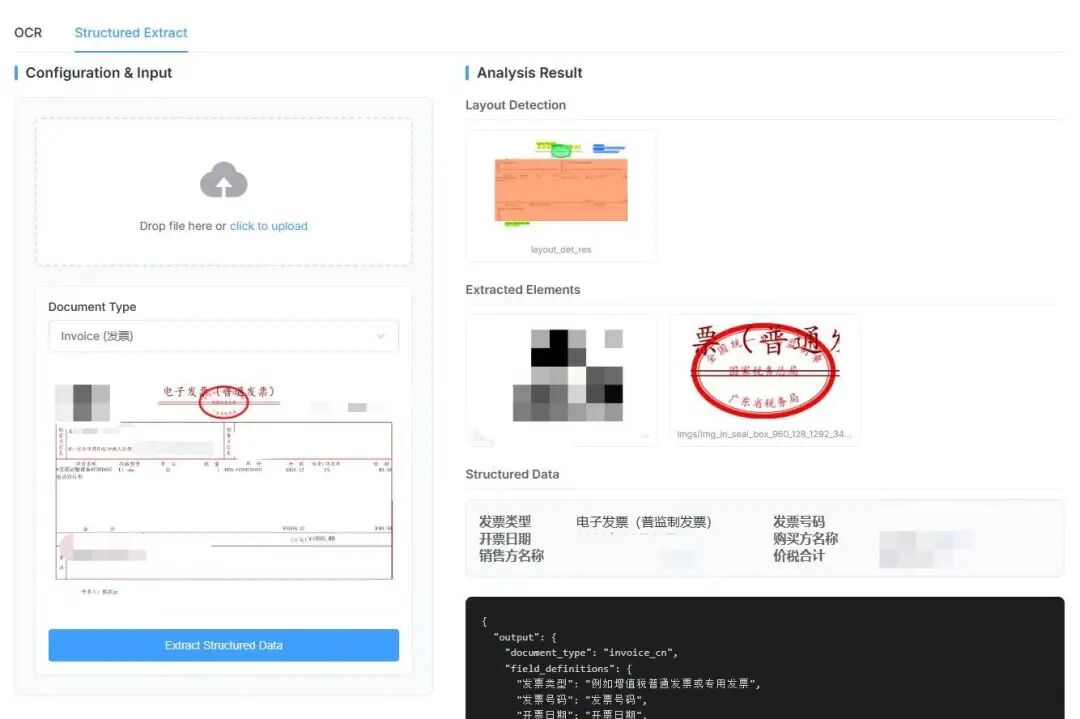
👉案例地址:
https://aistudio.baidu.com/projectdetail/10054897?sUid=168825&shared=1&ts=1773137773480
关于 LangChain
LangChain 是全球主流的开源智能体工程平台之一,聚焦于标准化模型接口与灵活的代理抽象层,使开发者能够跨越不同模型供应商进行切换,并将模型、工具、检索器、向量存储等可互操作组件高效连接起来,支持 AI 应用的快速原型开发。在 Deep Agents 方向,LangChain 官方也明确将其作为更适合构建复杂、多步骤智能体任务的“开箱即用”入口,提供任务规划、长上下文压缩、虚拟文件系统、子智能体协作等现代智能体能力;在此基础上,开发者还可以结合 LangGraph 完成更底层、可定制的有状态编排,并借助 LangSmith 实现评估、调试与可观测性分析,从而更顺畅地完成从快速原型到生产环境的演进。截至2026年3月,LangChain 在 GitHub 上已获得超 129k 星标,月下载量超2亿次。
👉了解 LangChain:
https://docs.langchain.com/
关于 PaddleOCR-VL-1.5
PaddleOCR-VL-1.5 是百度飞桨面向文档解析的轻量级视觉语言模型,在仅 0.9B 的参数规模下,它在权威评测 OmniDocBench v1.5 中取得 94.5% 的高解析精度。A100 场景中,PaddleOCR-VL-1.5 的推理速度可快达 1.43 页/秒。PaddleOCR-VL-1.5 引入对多边形(异形框)的元素定位能力,使其在倾斜、弯折、翻拍与复杂光照下仍能稳定贴合文本/表格/图表等元素的真实边界。同时,模型新增文本行级定位/识别与印章识别,并针对长文档引入跨页结构建模(跨页表格自动衔接、跨页标题连续识别),缓解分页造成的语义断层。在特殊场景中,PaddleOCR-VL-1.5 的解析能力得到重点优化,包括生僻字、古籍体、多语种表格、下划线/复选框等弱结构信号,并补全藏语、孟加拉语等语言覆盖,使解析输出更稳定地满足下游输入要求,为企业提供针对常见的“难样本”的进阶处理能力。截至2026年3月,PaddleOCR 在 GitHub 上已获得超 72k 星标。
👉了解 PaddleOCR-VL-1.5:
https://github.com/PaddlePaddle/PaddleOCR
*特别致谢 LangChain 官方社区大使 张海立(沧海九粟)、本期最佳实践案例贡献者 JackieTse 。
加入我们
诚挚邀请全球相关开源项目、开发者工具链团队及各类行业伙伴,与文心大模型、飞桨共建开源生态,共同推进文档解析、知识智能与企业级AI技术的普及与落地。
与文心大模型(ERNIE)、飞桨(PaddlePaddle)开展相关开源生态合作,伙伴可获得:
-
与文心大模型、飞桨的深度技术对接与集成支持;
-
覆盖模型、框架、推理、文档解析、数据治理等全栈生态资源;
-
面向行业的联合解决方案打造与联合发布机会;
-
内容生态、市场活动、行业推广等多渠道赋能。
让我们一起,以开源与技术的力量,构建下一代智能化知识生态。

扫码加入官方技术交流群



关注【飞桨PaddlePaddle】公众号
获取更多技术内容~

欢迎加入 MCP 技术社区!与志同道合者携手前行,一同解锁 MCP 技术的无限可能!
更多推荐
 0
0 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)