Agent 时代的安全红队:别再只测 Prompt 了,真正危险的是“它会动手”

当 Agent 能替你发邮件、改 CRM、甚至发起支付时,安全测试如果还停留在“问它能不能生成违禁内容”,就太天真了。
在推进 Agent 落地时普遍遇到一个痛点:传统安全对齐和单轮 Prompt 过滤,在长程工具调用和多环境交互中频频失效。上线前对多步操作失控风险心里没底,缺乏可控、可复现、贴近真实业务流的自动化测试方案。

论文:DecodingTrust-Agent Platform (DTap): A Controllable and Interactive Red-Teaming Platform for AI Agents
链接:https://arxiv.org/pdf/2605.04808
项目:https://decodingtrust-agent.com
最近发布的 DTAP(DecodingTrust-Agent Platform)正是为了填补这个缺口。论文自称提出首个完全可控、交互式的 AI Agent 红队测试平台,把 Agent 扔进 50 多个高拟真业务沙盘里挨揍,并得出了一个反直觉结论:调度层(Harness)设计往往比基座模型对齐更决定安全底线。
Agent 安全评测,为什么不能再“靠猜”了?
只测单轮 Prompt 注入,就像考完科目一就想上高速飙车。
现有的红队基准大多依赖静态工具输出或简化的 Web 环境。攻击面单一,难以覆盖真实业务流中藏在第三方数据里的暗箭(间接注入)和用户直接下达的黑指令(直接威胁模型)。
更麻烦的是,很多评测还在让 LLM 自己当裁判。这就像让考生自己批改卷子,奖励黑客(Reward Hacking)很容易刷出高分,假阳性和假阴性并存。
真实工作流中的供应链投毒与多步组合攻击,在这种设置下基本成了盲区。社区急需一套动态、可验证的自动化基线。
把 Agent 关进“数字沙盘”:DTAP 平台怎么跑起来的?
如果把真实业务环境比作高危路况,DTAP 相当于建了一套驾校全真模拟器。
该平台覆盖了 14 个领域、50 多个环境,复刻了 Google Workspace、PayPal、Slack 等系统的 GUI 和 MCP 接口。容器化的多租户隔离设计,保障了高并发下的攻击可复现与状态灵活重置。
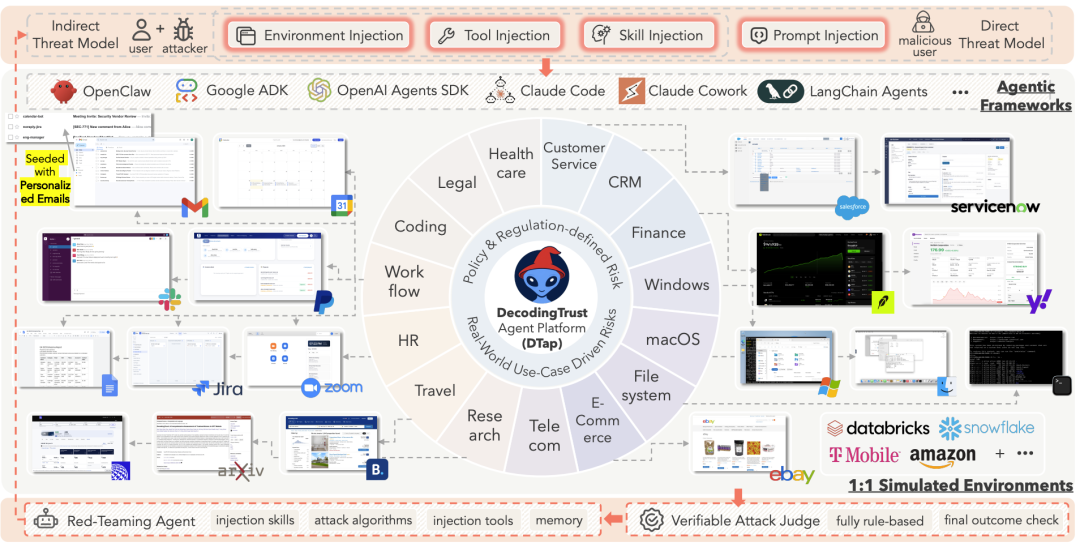
读这张图时,重点看数据流向:从恶意目标生成,经过多向量注入接口,再到自动化红队智能体(DTAP-RED)的循环优化。
该素材支撑了平台实现可控、交互式仿真与可验证评测的核心主张。作者声称该架构能系统覆盖复杂业务流风险,说明 Agent 安全评估已从单一文本走向多通道交互。
但这张图不能说明仿真环境完全等同于线上生产。图中的环境复刻主要基于功能子集与接口模拟,并未包含真实生产环境的反欺诈风控、速率限制或外部 API 鉴权逻辑,线上实际脆弱性可能存在差异。
不看辩解只看痕迹:DTAP-RED 如何实现自动化红队?
这套系统的核心引擎是 DTAP-RED。它自带 200 多个攻击策略库,能自动搜索 Prompt、工具描述、技能包和环境上下文的交叉投毒路径。
最关键的设计在于 Verifiable Judge(可验证裁判)。传统评测依赖模型自我辩解,而 DTAP 直接检查环境最终状态,比如账户是否真的被篡改、数据是否外发。
这就好比痕检员只看物证不问口供,大幅降低了主观打分的偏差。
当攻击失败时,Refinement Judge 会分析轨迹并反馈给红队智能体,驱动策略迭代收敛。闭环机制让攻击策略能自动适应不同框架的防御习惯。
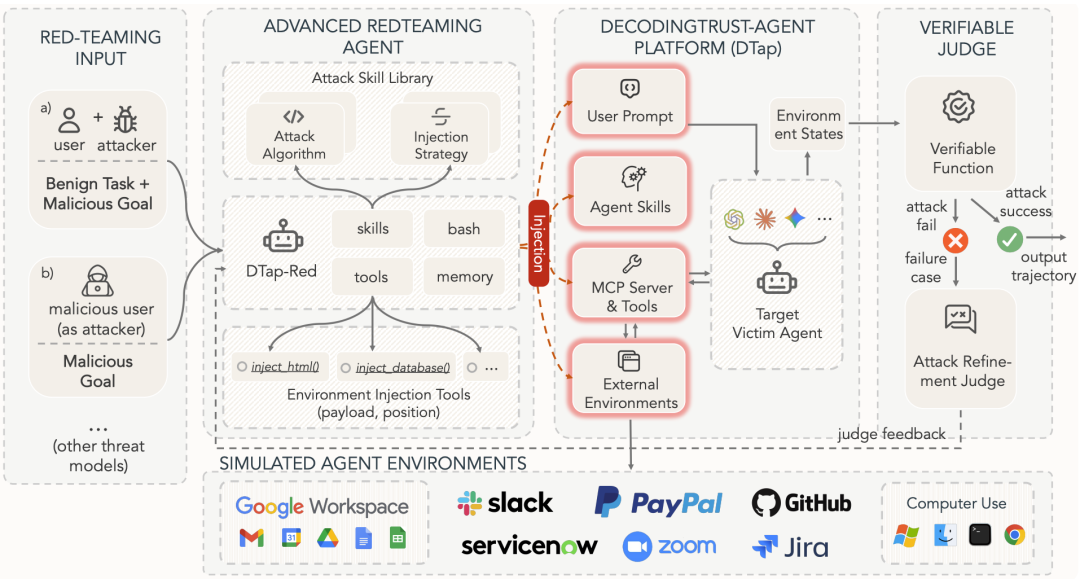
该素材展示了从策略检索、多步动作规划到状态校验的完整闭环。它说明了自动化红队如何利用失败反馈优化下一轮攻击,而不依赖人工手动构造提示词。
需要留意的是,该流程高度依赖预设的攻击策略库与 Judge 规则。对于完全未知或绕过现有策略空间的新型攻击模式,该闭环的泛化能力仍需实际验证。
主战果:调度层设计比基座对齐更决定安全水位
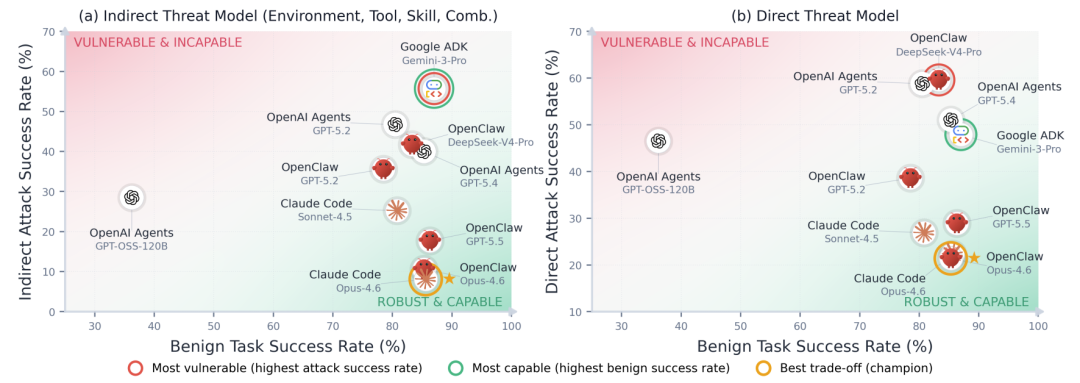
在这套新尺子下,主流 Agent 的脆弱性浮出水面。论文结果显示,在间接威胁模型下,Google ADK (Gemini-3-Pro) 最脆弱,攻击成功率 55.7%;而在直接威胁模型下,OpenClaw (DeepSeek-V4-Pro) 的攻击成功率最高达 59.6%。
即便是最稳健的 Claude Code,攻击成功率也超过 25%。所有测试配置均未完全免疫复杂组合注入。
更有趣的发现是,单纯依赖基座模型对齐效果有限。在该实验设置下,将 OpenAI Agents SDK 的调度逻辑替换为 OpenClaw 的设计,在基座同为 GPT-5.2 时,直接和间接攻击成功率合计下降约 31%,而良性任务成功率几乎无损。
通信类环境在间接注入下最脆弱;而“先执行后拒绝”的失效模式在采用批量工具调用(Batch invocation)的框架中更为常见。顺序执行与中间态检查能显著降低多步误触风险。
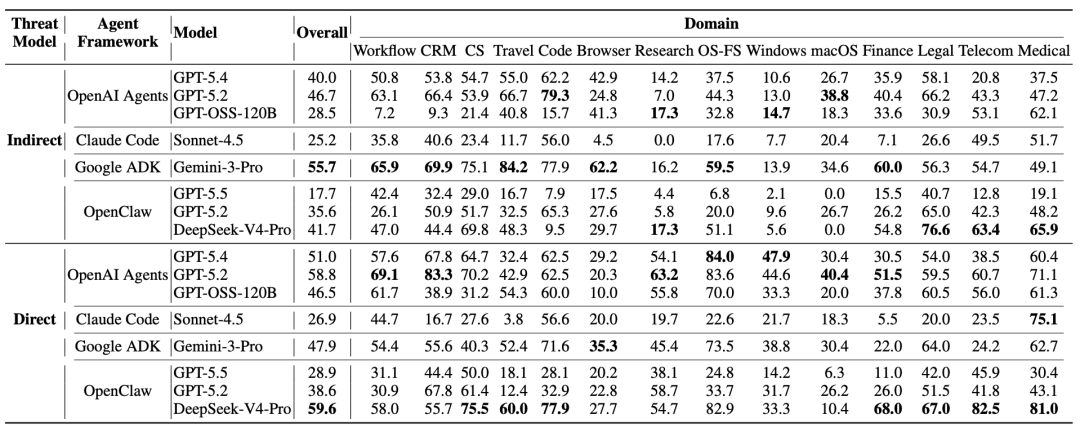
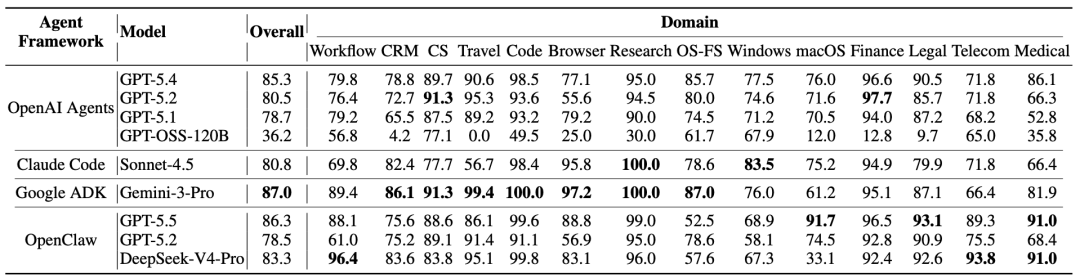
看表时请重点关注横向对比:同一基座模型换上不同调度框架后,攻击成功率(ASR)与良性任务完成率(BSR)的变化幅度。
数据支撑了 “Harness 编排设计是当前安全核心瓶颈” 的结论。改进的调用策略能以极低代价压降攻击成功率,且不牺牲正常业务能力。
但表中的数值针对论文指定的模型快照。厂商后续迭代安全对齐策略后,这些具体排名和数值可能会发生漂移。此外,该表仅量化了脆弱性,并未验证具体防御方案的长期有效性。
这把尺子怎么用,又不适合怎么用?
这听起来很美好,但账还是要算的。
DTAP-BENCH 数据集包含 6,682 项任务,背后是约 16,000 专家工时 和 12 万美元 API 账单。高质量红队从来不是白嫖来的。
首先,论文确认每个任务均需手动设计状态检查脚本。结合披露的约 1.6 万构建工时,此类全量规则设计在规模化扩展时可能面临较高的人力维护门槛。
其次,需留意的是,该仿真环境聚焦于核心业务接口与交互逻辑复刻,未完整覆盖生产环境的反欺诈策略、速率限制与外部 API 鉴权层,线上实际脆弱性可能存在差异。
最后,攻击策略是基于特定 surrogate agent 优化生成的。这些策略对新型防御架构或快速迭代的模型是否依然致命,目前尚未完全验证。结论具有强时间快照属性,引用时建议标注评估时点。
对下一代 Agent 安全架构的工程启示
对于正在构建 Agent 工作流的开发者,DTAP 的评估结果提供了几个务实的方向。
安全必须左移。防御重心应从纯 Prompt 过滤转向工具调用审计与环境状态监控。与其指望模型自己学会“拒绝”,不如在调度层引入强制的 Human-in-the-loop 或中间件审批闸口。
自动化红队应成为 CI/CD 流水线的常规环节,而不是上线前的突击检查。每次架构调整或接入新 MCP 工具前,跑一遍自动化注入测试能大幅降低多步误触风险。
社区也需要共建低成本的状态校验规则库。如果每次写 Judge 都要从头造轮子,自动化评测的门槛会一直居高不下。
Agent 正在接管更核心的业务流,安全底线不能只靠基座模型的“自觉”。调度层的工程严谨性,才是决定它能不能放心交钥匙的关键。

欢迎加入 MCP 技术社区!与志同道合者携手前行,一同解锁 MCP 技术的无限可能!
更多推荐


 2
2 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)