AI分页革命!MCP+Agent+大模型实现百万字电子书秒级解析,让大模型榨干每一本电子书
摘要:本文介绍了一个通过MCP+Agent+大模型协同处理大体积电子书的技术方案。系统支持PDF、Word、EPUB等多种格式,核心功能包括:1)按页面/章节拆分电子书;2)OCR图像识别;3)多格式内容解析;4)大模型自动总结与翻译;5)HTML输出美化。实现过程分为MCP服务端开发(含文件解析、OCR引擎等模块)、Agent流程编排(负责任务调度)和大模型内容处理三个层次。测试案例显示,该系统
大模型的附件上传,一般不会超过100M,如果想利用大模型的强项、对于一本体积大的电子书进行快速的阅读和总结,以了解其主要内容,则需要一些特殊处理。
本次MCP实现的主要功能包括:
1、对电子书按页面进行拆分和读取
2、支持主流的pdf、word、epub、chm、txt、mobi等格式
3、支持图像识别,用以电子书中的图片内容处理
4、对分块之后的电子书进行阅读总结并输出,当然大模型默认支持翻译
5、最终整合为一个整体阅读总结,并以html格式美化输出
老规矩,先看最终效果。
以“Foundation_of_LLMs.pdf”为例,全书分为6个章节,最终的效果如下:
当然总结的内容比较简单,主要是为了验证功能,如果希望得到更好的总结结果,需要调优Agent的Prompt。
转换为HTML之后的展示效果截图

原书目录索引截图
MCP+Agent+大模型的核心是,要分清楚各自的职能,哪些MCP实现、哪些Agent实现、哪些大模型实现。
MCP的原理,以及如何从零开发一个MCP Server和Client的教程详见上一篇文章,以下只介绍本次实现
以下是详细的实现过程
一、需求拆解和程序设计
1、大模型能干什么:对内容进行翻译、总结和输出
2、需要MCP干什么:根据不同格式、按页码读取文件内容,并输出
3、需要Agent干什么:串整个流程,根据需要调用不同的MCP tools或者大模型,完成不同任务,比如调用mcp完成文件拆分、调用大模型完成内容翻译和总结、调用mcp完成内容存储等。
4、功能要求:
1)能对电子书进行按块阅读,比如按章节进行拆分、按页面进行拆分等
2)支持主流的各种电子书格式
3)要将最终结果进行汇总并美化输出
5、工程设计:
1)新建mcp-server-readbooks的mcp server完成mcp的功能
2)新建mcp-client完成mcp-server的测试
3)在host中新建mcp和agent完成整体任务
4)在大模型聊天时调用mcp和agent,then have fun!
二、MCP的实现
1、工程目录如下:
mcp-server-readbooks/├── src/│ ├── core/│ │ ├── __init__.py│ │ ├── ebook_parser.py # 主解析逻辑│ │ ├── ocr_engine.py # OCR处理│ │ └── cache_manager.py # 缓存管理│ ├── utils/│ │ ├── __init__.py│ │ └── file_convert.py # 文件格式转换│ └── readbooks——server.py # 服务入口├── tests/│ ├── test_parser.py # 单元测试│ └── test_server.py # 集成测试├── .env # 环境配置├── requirements.txt # 依赖管理├── config.yaml # 运行配置└── README.md # 文档说明
2、依赖的python包
fastmcp>=2.0.0pymupdf>=1.24.0python-docx>=0.8.11pychm>=0.8.6mobi>=0.3.0pytesseract>=0.3.10docx2pdf>=0.1.8python-dotenv>=1.0.0uv>=1.0.0Pillow>=10.0.0
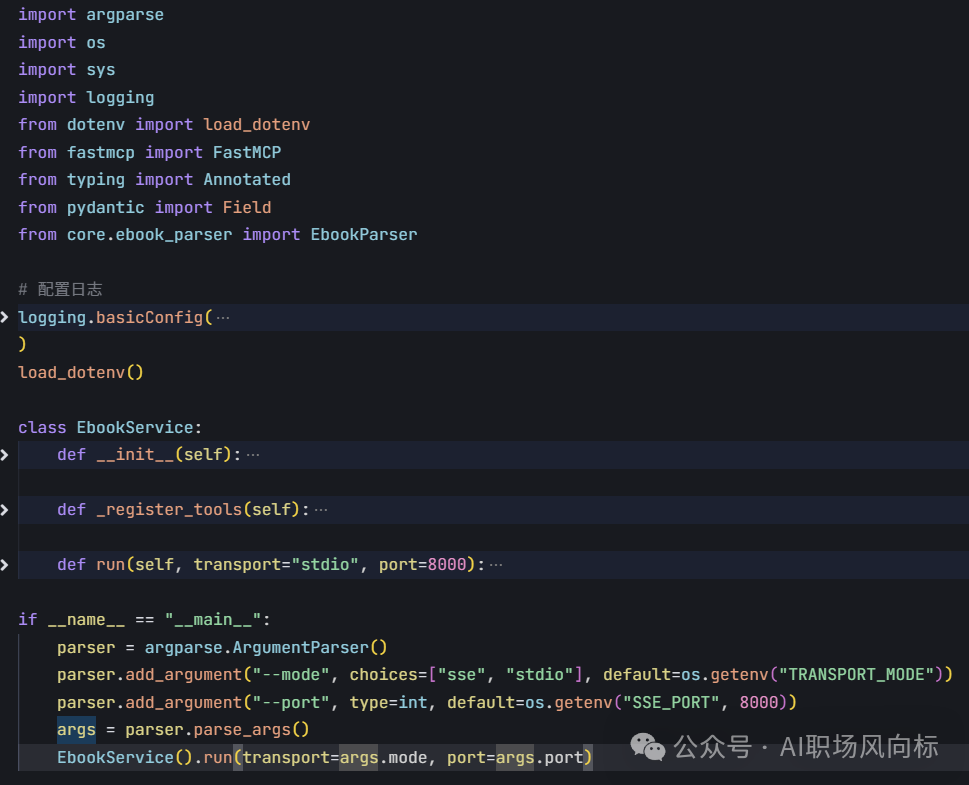
3、readbooks_server.py是mcp server的核心代码
使用FastMCP.tools()注解完成工具代码的生成
同时支持sse和stdio模式(推荐,因为电子书都在本地)
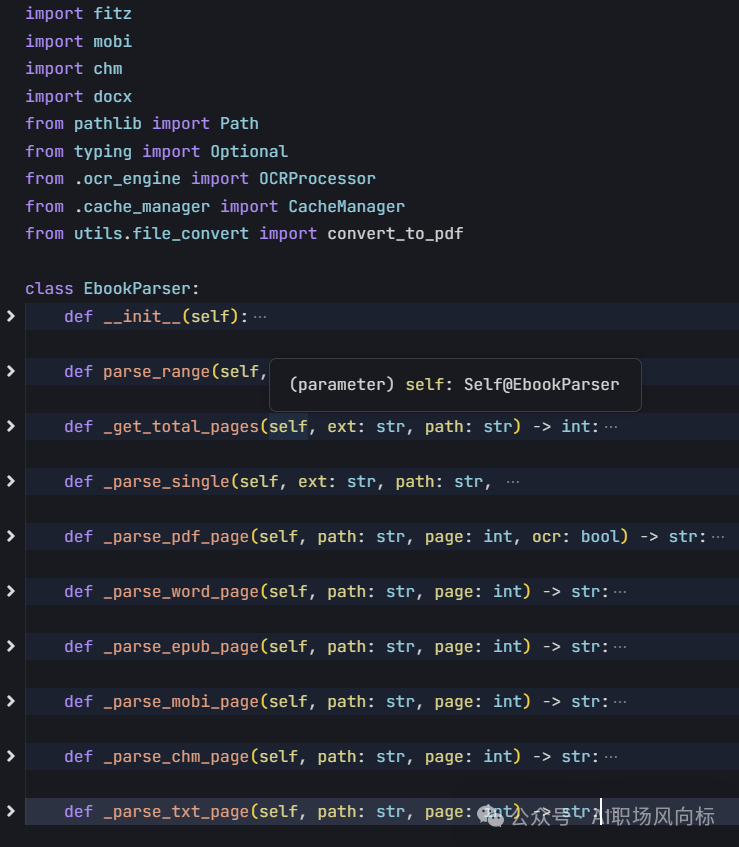
4、ebook_parser.py解析并读取电子书的核心代码
调用fitz(公认的处理pdf最快的包)、mobi、chm等包完成相应格式的电子书的
针对需要orc的部分,调用orc程序进行内容识别
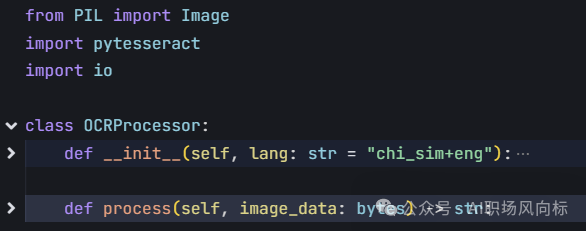
5、orc_engine.py解析并处理图像识别核心代码
调用pytesseract完成图像识别
6、file_convert.py完成word转pdf,剩下的交给pdf
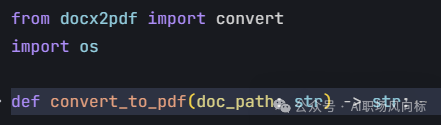
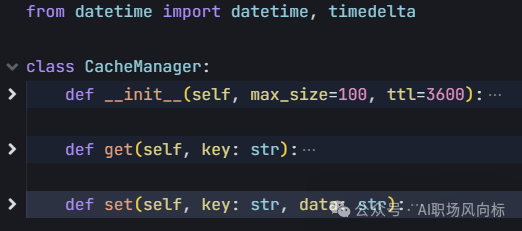
7、cache_manager.py,缓存处理
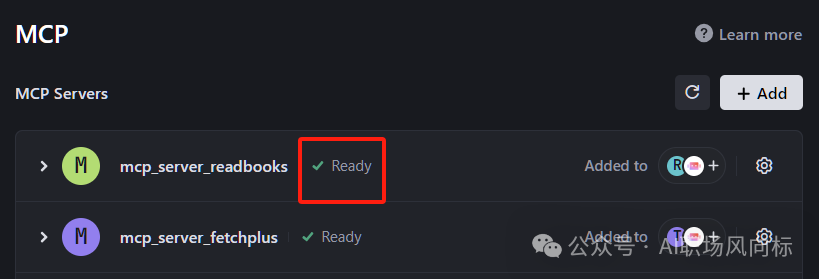
三、MCP的配置(以Trae为例)
第二步的Client测试验证通过之后再进行,否则调试起来很麻烦,因为没有日志!都不知道哪里出错!
Host工具的选择:Trae(推荐)、CherryStudio、VS tools、coze都行。
1、以Trae为例,打开MCP界面
2、选择新建->手工新建,配置如下:
参数一定要根据实际情况修改:
command:python的路径
ags:mcp server的路径
PYTHONPATH:指向mcp server的路径
TRANSPORT_MODE: 默认stdio
{"mcpServers": {"mcp_server_readbooks": {"command": "E:/envs/llm_learn/python","args": ["d:/Server/mcp-server-readbooks/src/readbooks_server.py"],"env": {"PYTHONPATH": "d:/Server/mcp-server-readbooks/src","TRANSPORT_MODE": "stdio","PYTHONIOENCODING": "utf-8"}}}}
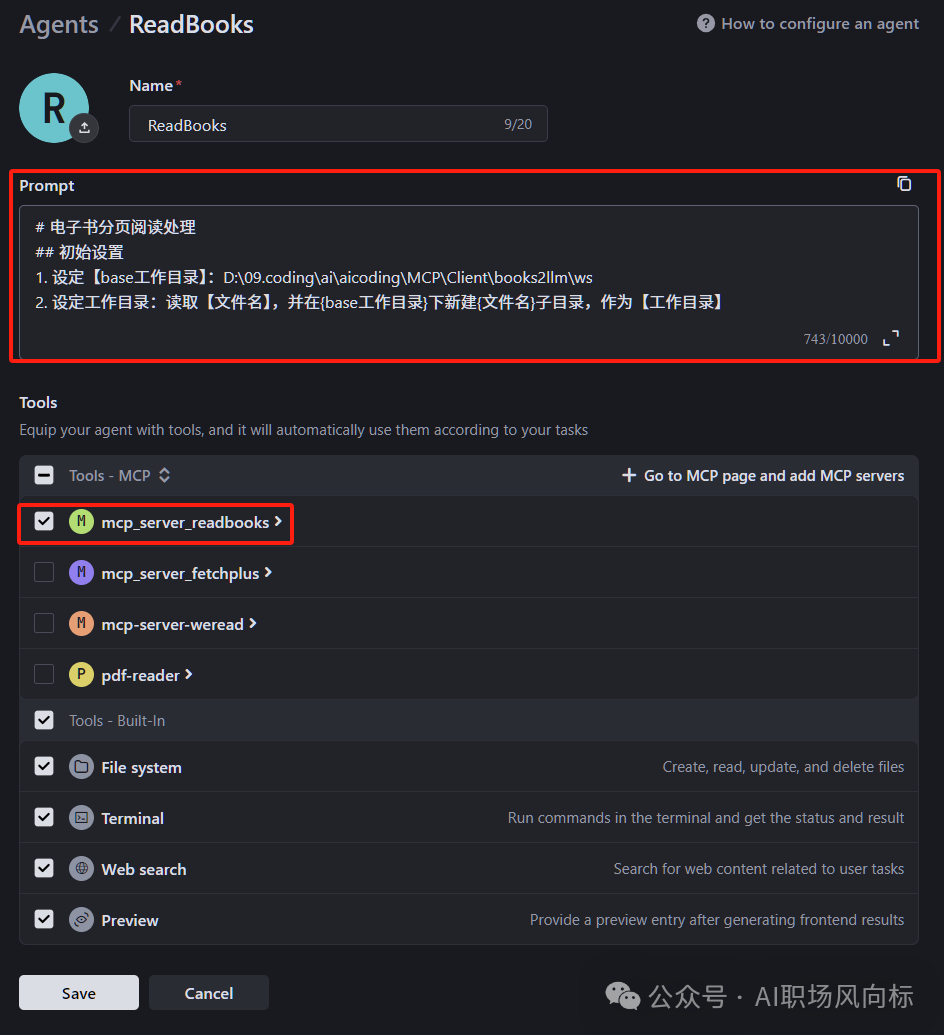
四、Agent的配置(以Trae为例)
Trae里的Agent可以串联调用一系列的mcp server和llm等完成特定任务,有点儿类似coze的工作流,但只不过是通过prompt来完成。
由于大模型的不确定性,所以prompt的好坏,则决定了完成任务的质量。
由于他不能像coze一样有明确的先后顺序,总是跳跃,导致有些步骤执行失败。
本次使用的Agent,前前后后调试了得有几十次!!!
本次Agent的设计:
1、根据用户输入的“本地电子书”附件,获取文件名,创建【文件名】子目录
2、调用电子书阅读工具,获取“目录”页,得到每章节的索引并保存到本地
3、按每个章节读取内容,并传递给大模型进行翻译、总结
4、将每章翻译总结的内容保存到本地
5、最后合并成一个文件,并输出为html
具体实现:
打开trae的Agent界面新建Agent
-
输入名字
-
promots - 核心中的核心
-
把刚新建的mcp包含在内 - 别忘了
五、聊天中调用Agent,验证实际效果(以Trae为例)
在trae中打开聊天窗口,选中刚才建立的Agent,在聊天窗口拖入需要处理的电子书,剩下的就交给电脑吧。
注意:trae不支持外部直接上传附件,所以需要把“电子书”放到工程目录中,然后直接拖入聊天框即可。
执行过程截图:
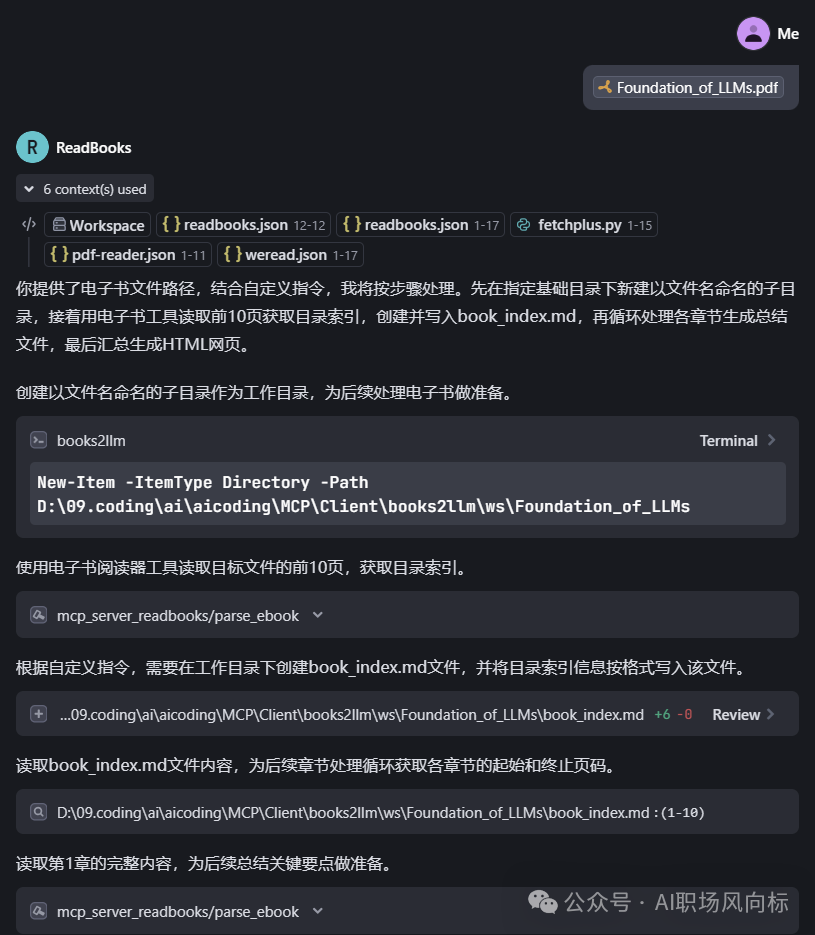
过程文档内容截图
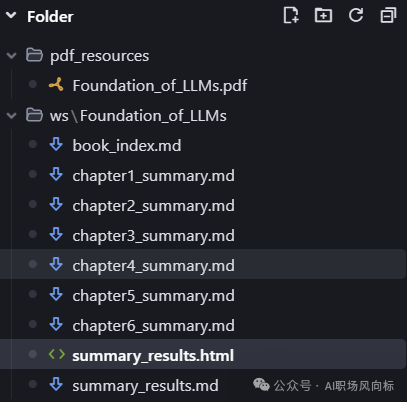
完成啦✅
好了,今天的MCP+Agent实现借助大模型进行大文件的阅读和总结就到这里了

欢迎加入 MCP 技术社区!与志同道合者携手前行,一同解锁 MCP 技术的无限可能!
更多推荐


 13
13 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)