计算机毕业设计Python+大模型知识图谱中华古诗词可视化 古诗词智能问答系统 古诗词数据分析 古诗词情感分析 PyTorch Tensorflow LSTM 阿里千问大模型精调
计算机毕业设计Python+大模型知识图谱中华古诗词可视化 古诗词智能问答系统 古诗词数据分析 古诗词情感分析 PyTorchTensorflow LSTM 阿里千问大模型精调
温馨提示:文末有 CSDN 平台官方提供的学长联系方式的名片!
温馨提示:文末有 CSDN 平台官方提供的学长联系方式的名片!
温馨提示:文末有 CSDN 平台官方提供的学长联系方式的名片!
开发技术:
前端:vue.js echarts D3.js
后端:Flask/Django
机器学习/深度学习:LSTM情感分析模型、PyTorch、Tensorflow、阿里千问大模型精调、chatgpt、卷积神经网络CNN/RNN
爬虫:drssionpage框架(全新技术,反爬强悍)
数据库:mysql关系型数据库、neo4j图数据库、mongodb
吊打答辩现场的要点总结:
1-百万数据爬虫
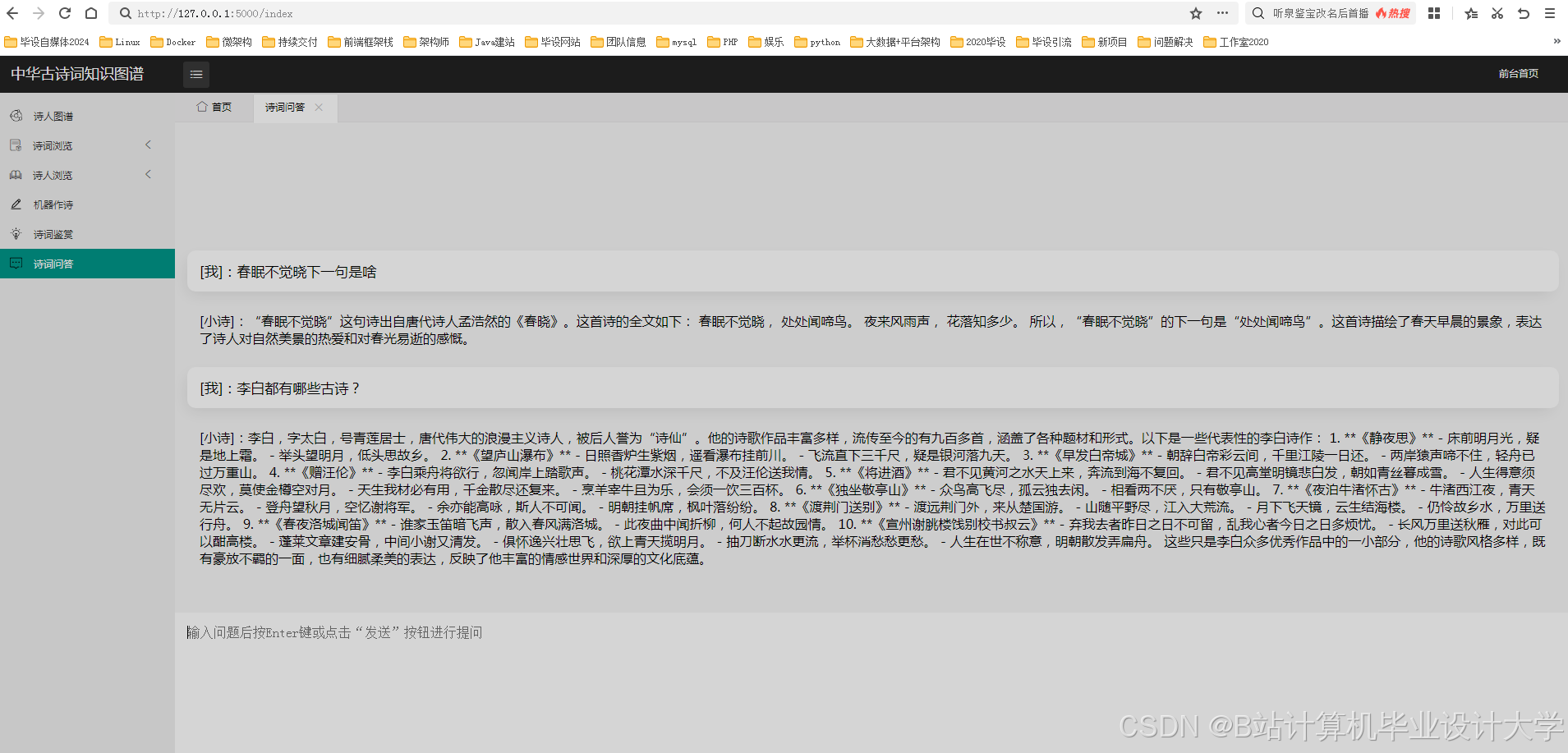
2-大模型的应用
3-智能问答
4-深度学习模型训练优化:LSTM、PyTorch、Tensorflow、卷积神经网络CNN/RNN
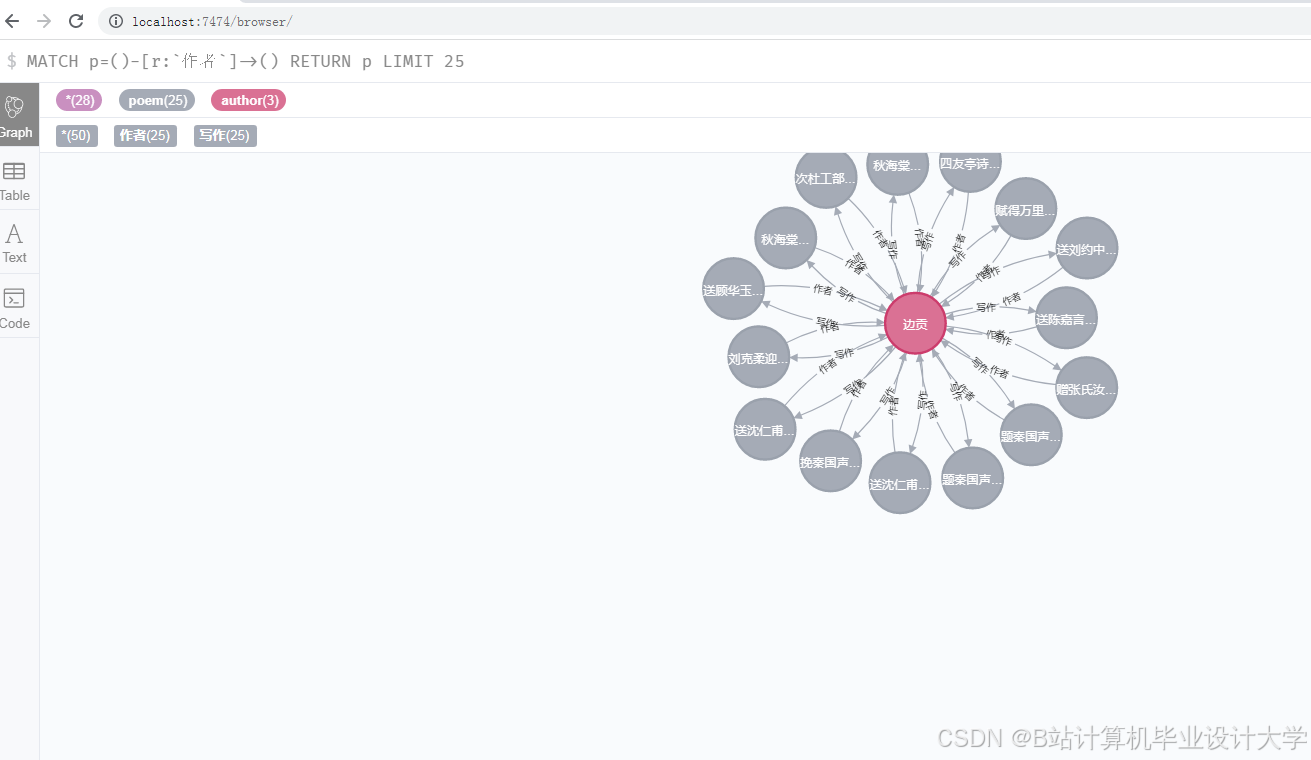
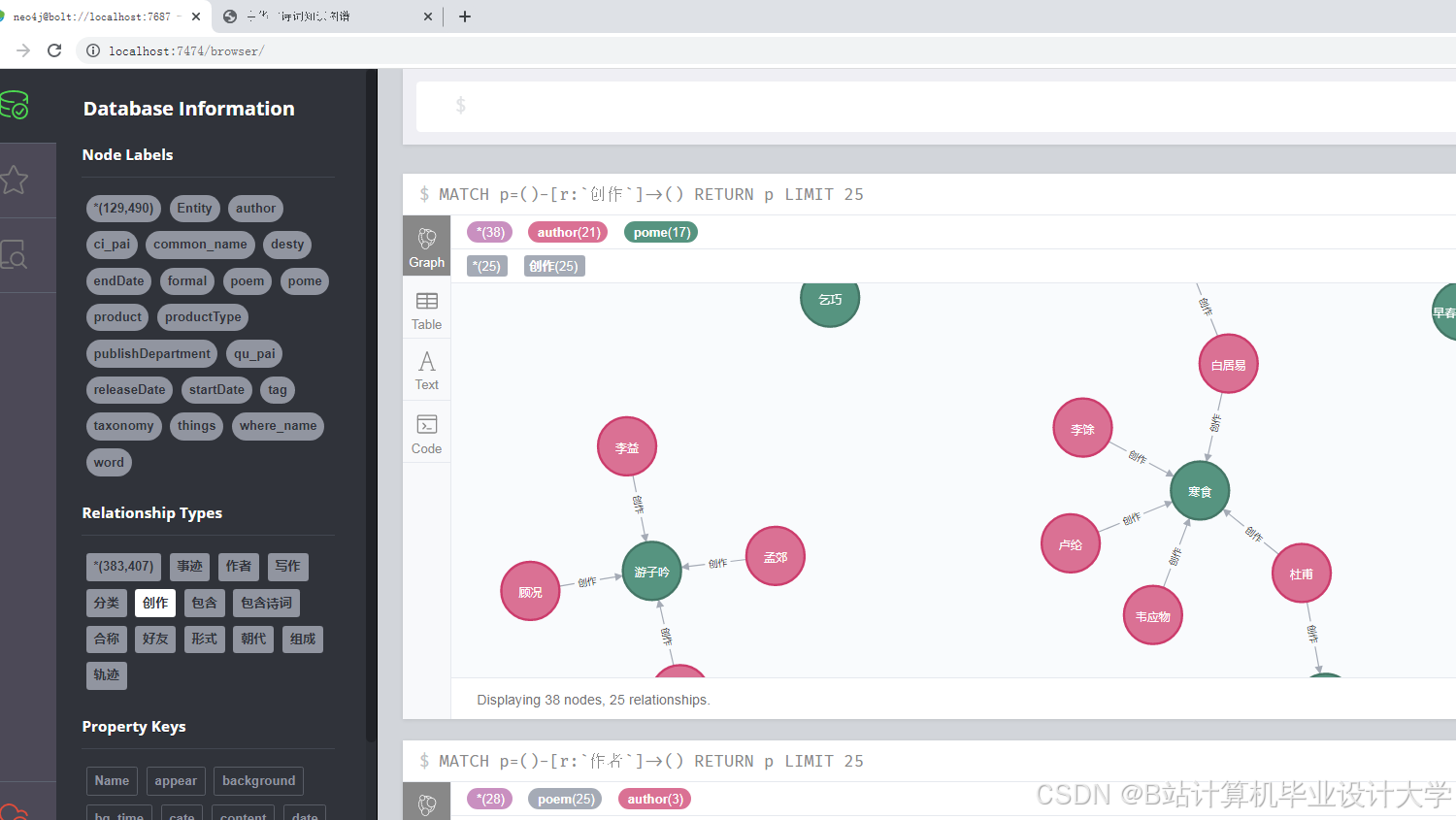
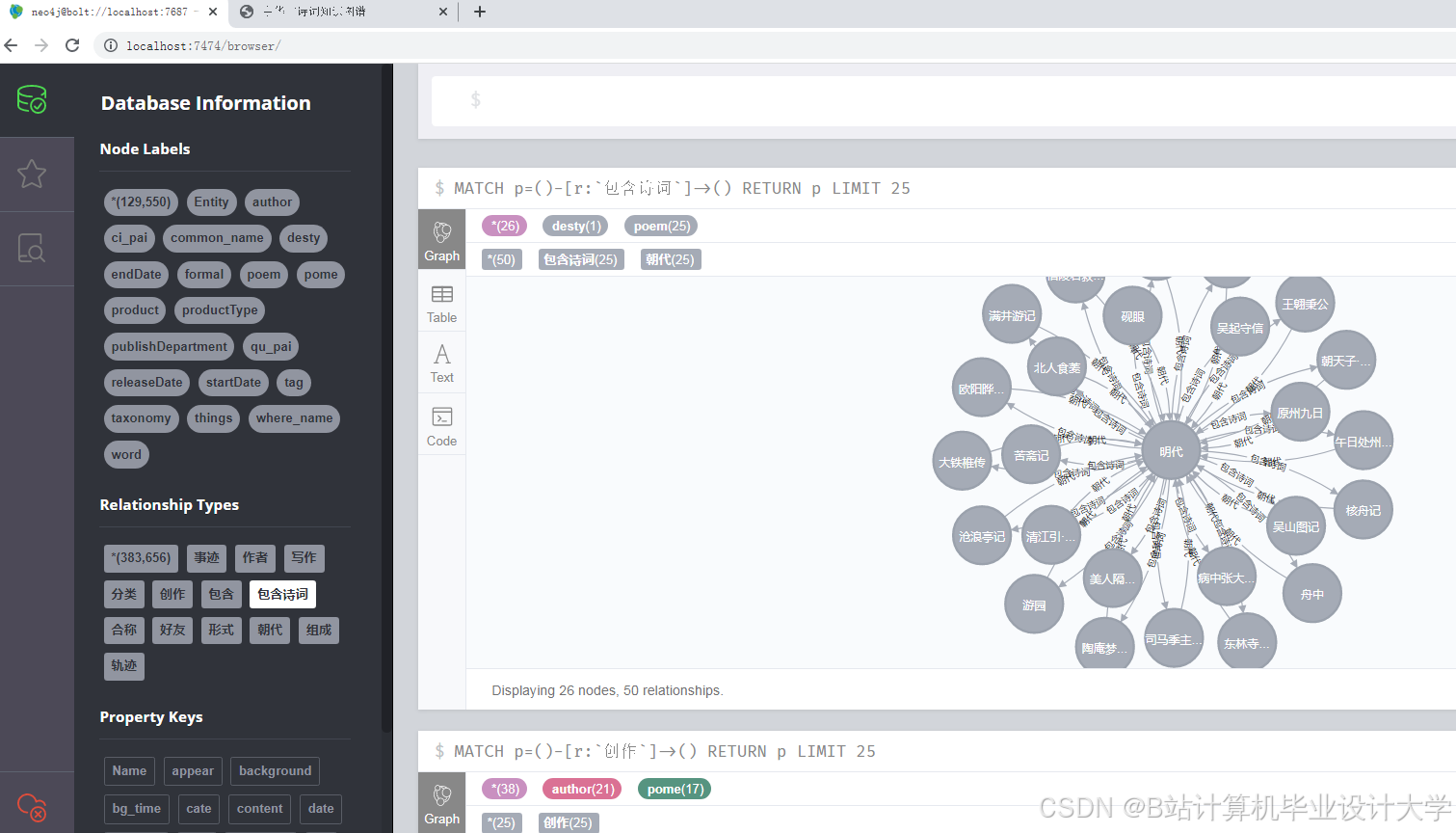
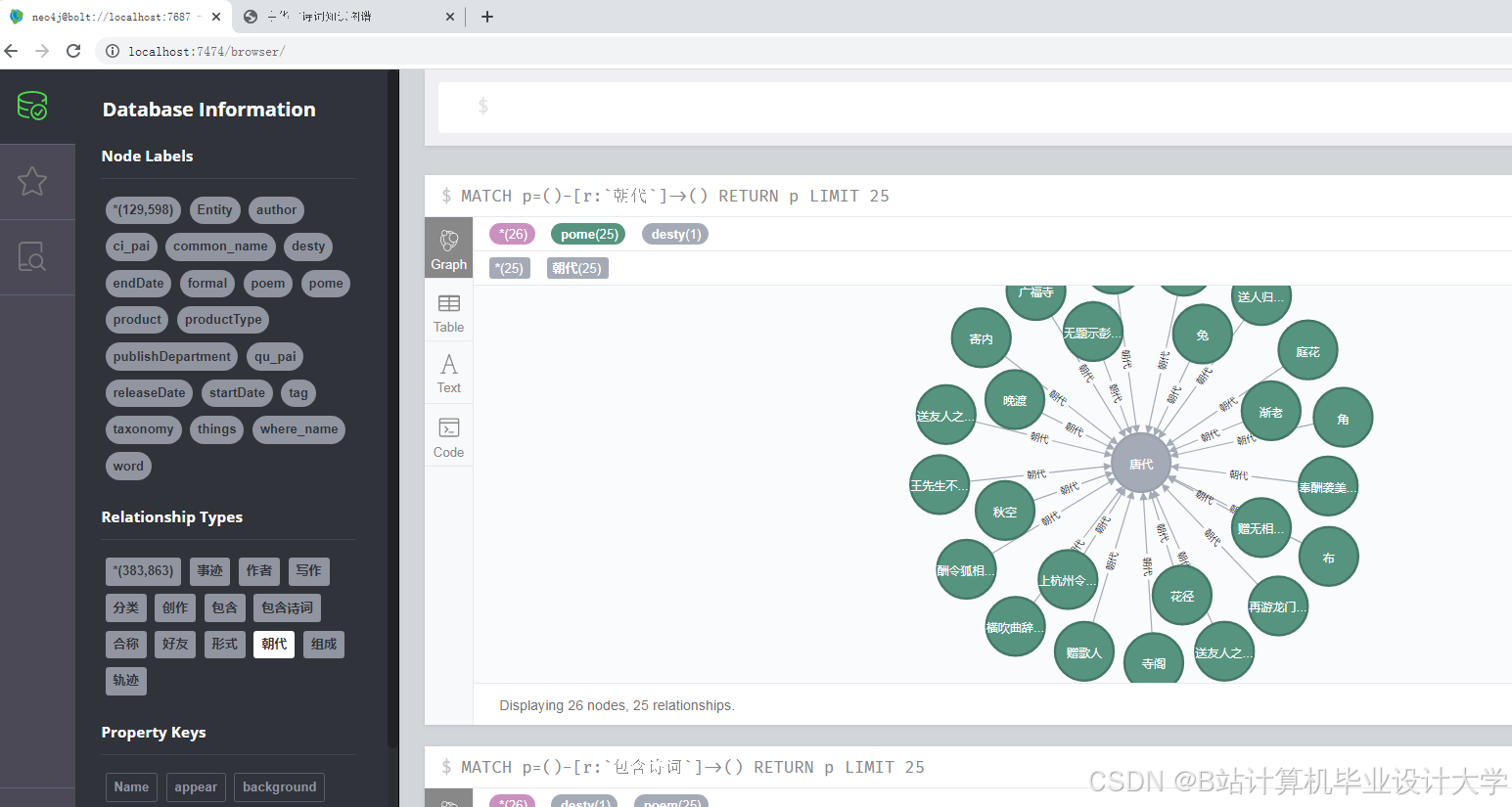
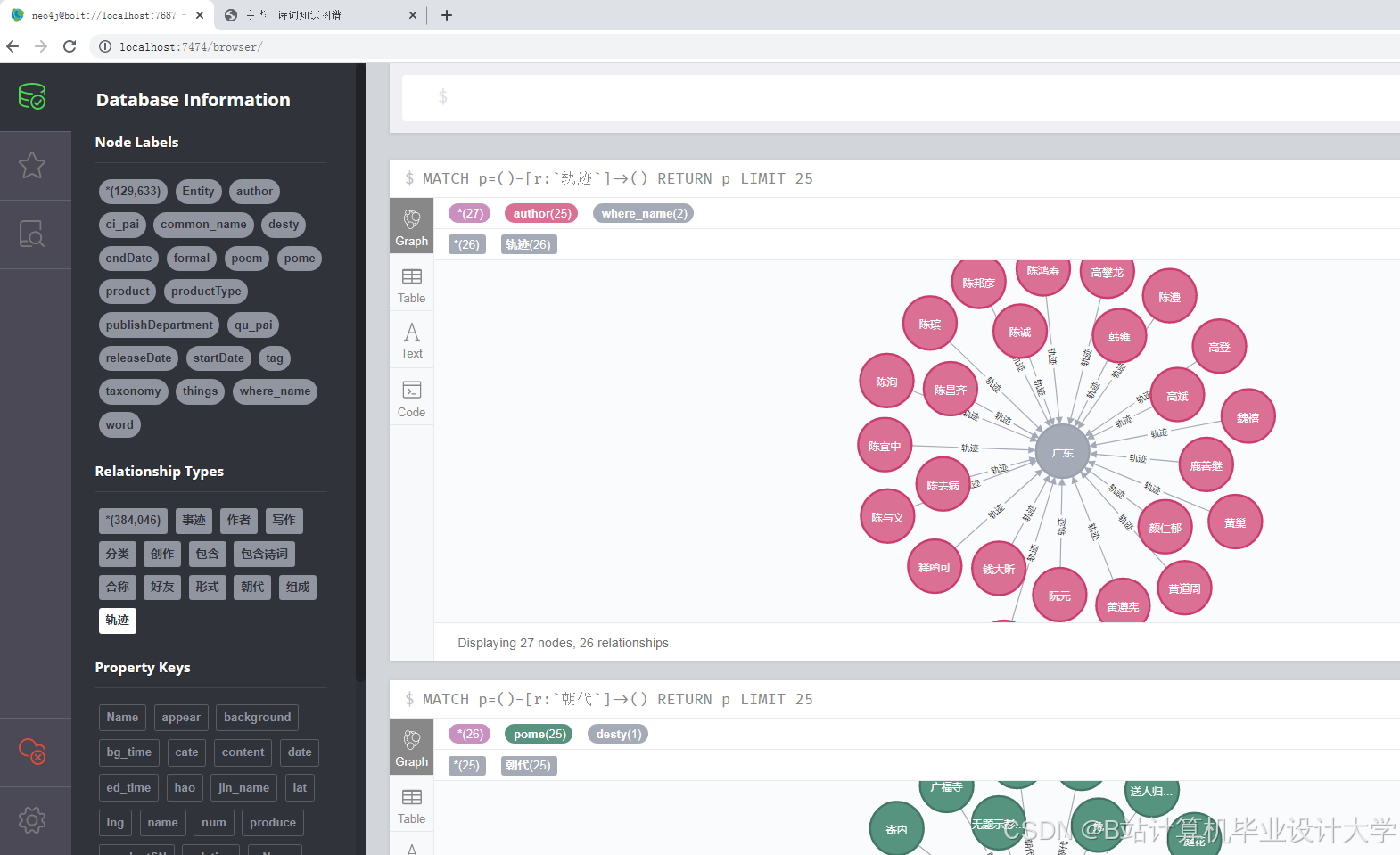
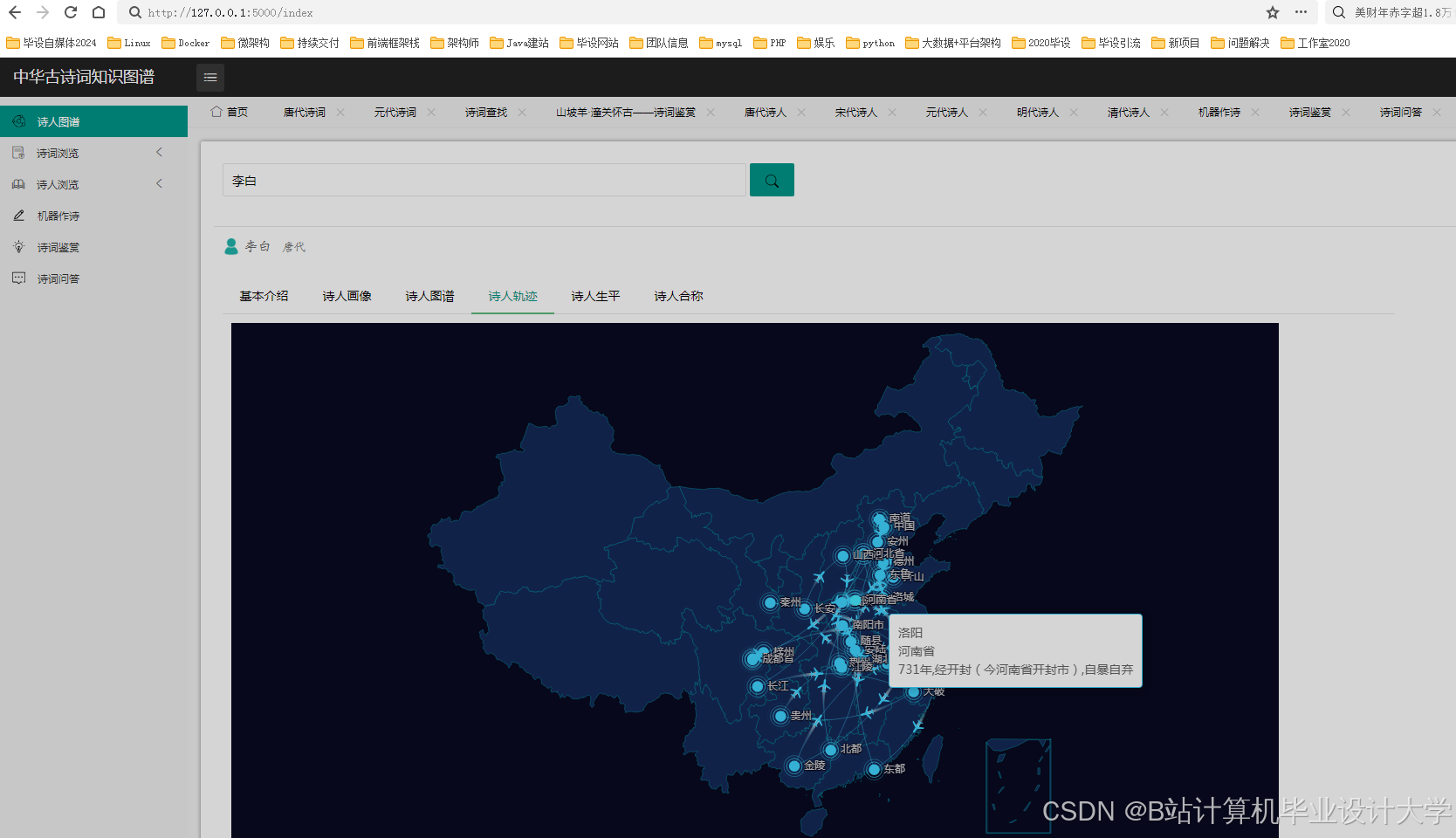
5-Neo4J知识图谱显摆
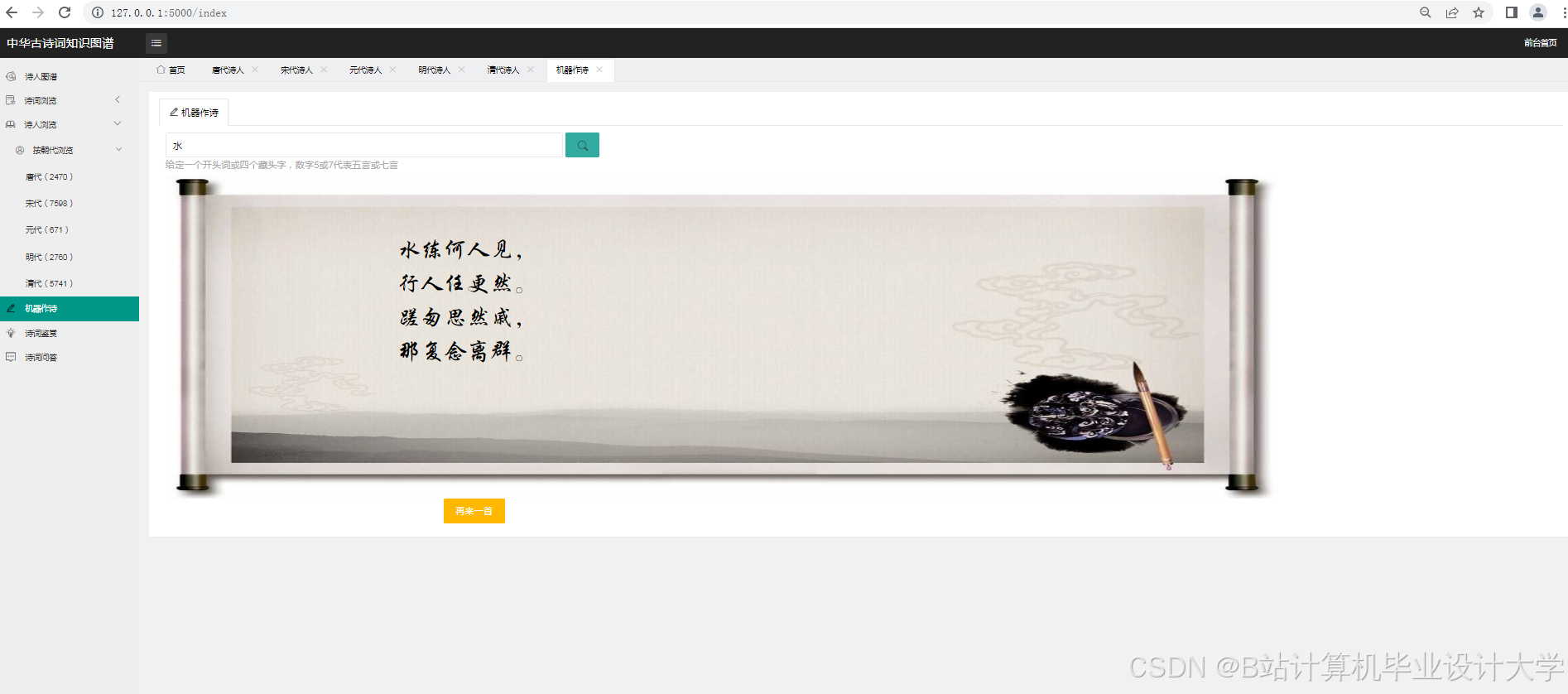
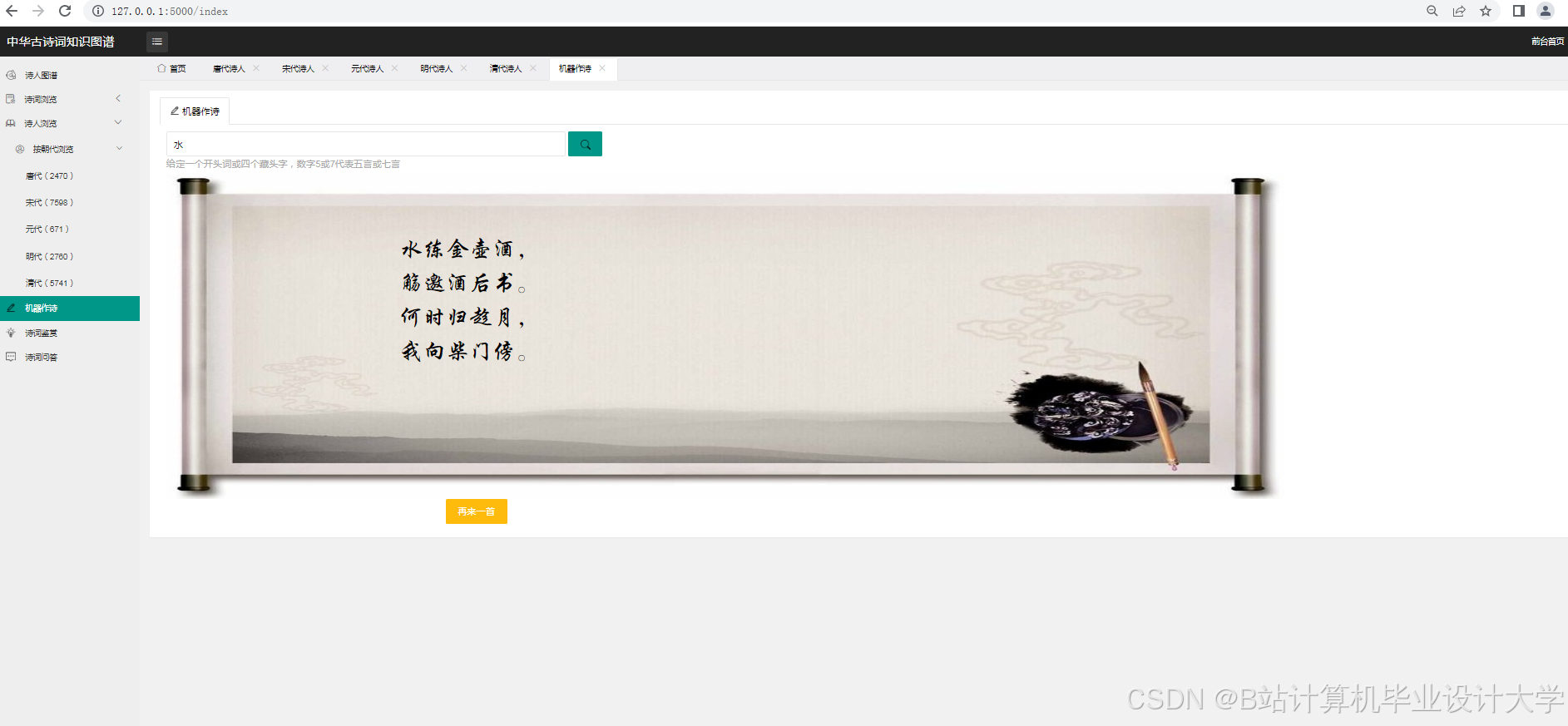
6-自动即兴发挥写诗
7-可视化大屏
8-情感分析
《Python+大模型知识图谱中华古诗词可视化》开题报告
一、课题背景与研究意义
课题背景
中华古诗词是中华民族的文化瑰宝,蕴含着丰富的历史、文化和情感信息。然而,随着时代的变迁,大量古诗词作品被尘封于古籍之中,难以被现代人广泛阅读和欣赏。传统的阅读和教学方式已难以满足当代学习者个性化、便捷化的需求。因此,如何借助现代技术手段,尤其是Python和深度学习大模型(如LSTM、BERT等),对古诗词进行数字化处理与可视化展示,成为了一个重要的研究课题。
研究意义
- 文化传承:通过数字化手段保存和传播古诗词,促进中华文化的传承与发展。
- 知识发现:利用深度学习大模型挖掘古诗词中的潜在信息和关联,发现新的研究视角和切入点。
- 教育普及:通过可视化技术,使古诗词的学习和理解更加直观和生动,提高教育效果。
- 技术探索:探索Python和深度学习大模型在文本处理、知识图谱构建及可视化方面的应用,为相关领域的研究提供新的思路和方法。
二、国内外研究现状
国内研究现状
近年来,国内学者在古诗词数字化处理方面取得了显著进展。一些研究利用自然语言处理技术对古诗词进行分词、词性标注、情感分析等。同时,也有学者尝试构建古诗词知识图谱,并通过可视化技术展示其结构和关系。然而,在结合深度学习大模型进行古诗词知识图谱构建和可视化方面的研究相对较少,尚有很大空间。
国外研究现状
国外在文本处理、知识图谱构建及可视化方面的研究起步较早,技术较为成熟。特别是在自然语言处理领域,深度学习大模型已被广泛应用于文本分类、情感分析、机器翻译等多个方面。然而,由于语言和文化的差异,国外在中华古诗词方面的研究相对较少,但其在文本处理和可视化方面的技术积累为本项目提供了有益的借鉴。
三、研究内容与技术路线
研究内容
- 数据收集与预处理:从互联网或古籍数据库中收集中华古诗词的原始数据,并进行清洗、分词、去停用词等预处理工作。
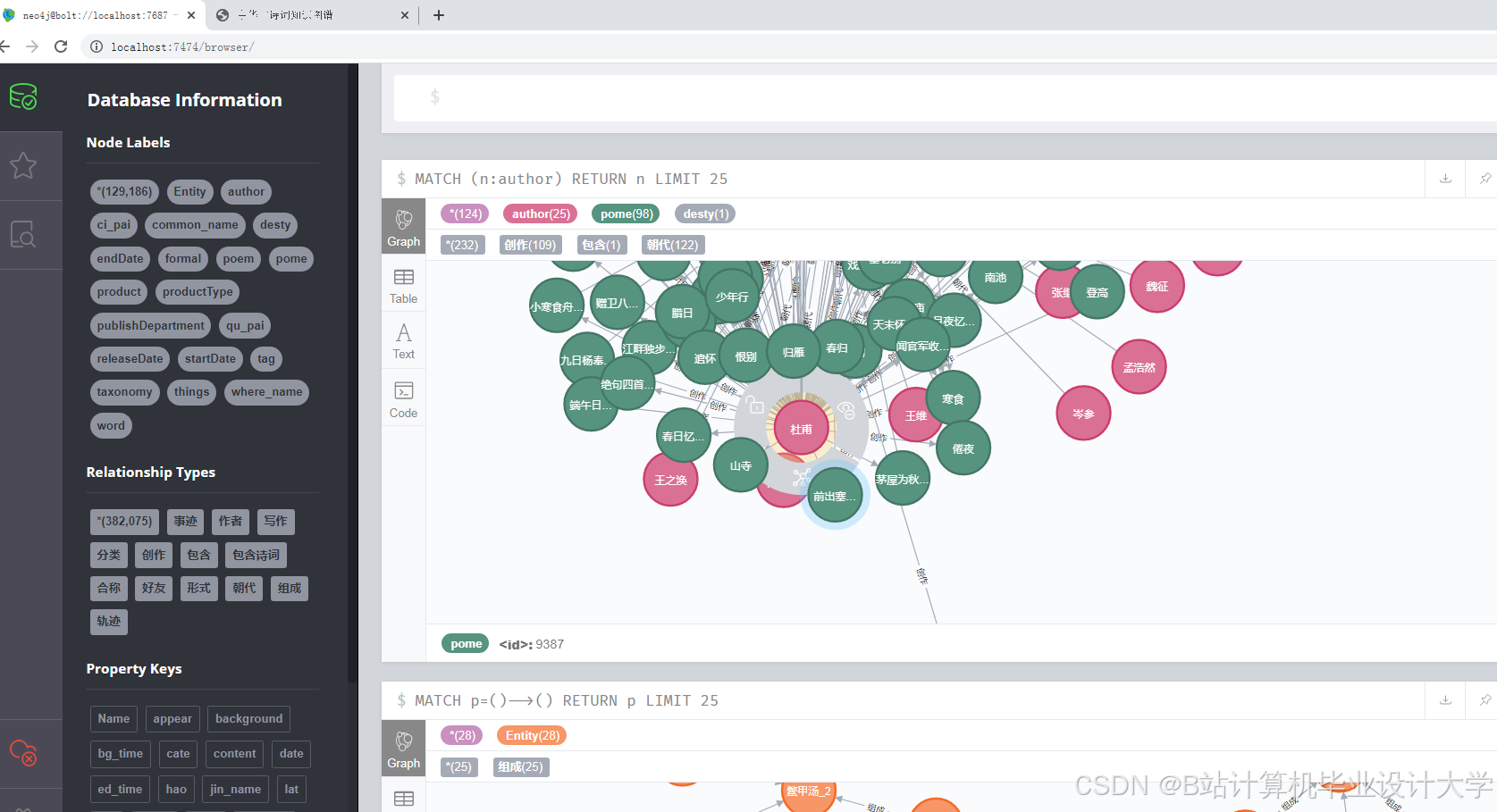
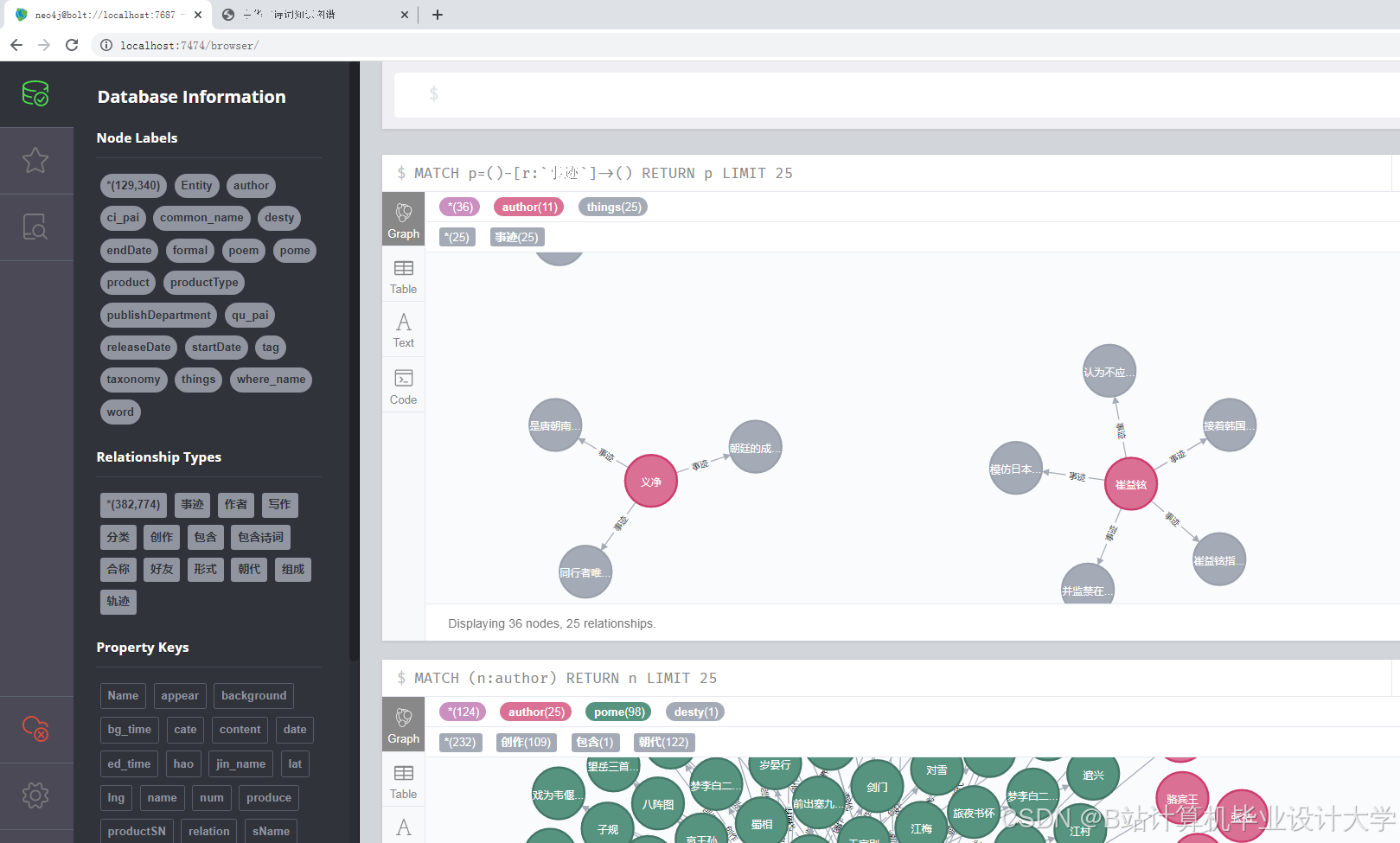
- 知识图谱构建:基于预处理后的数据,构建中华古诗词的知识图谱,包括实体识别、关系抽取和图谱构建等步骤。
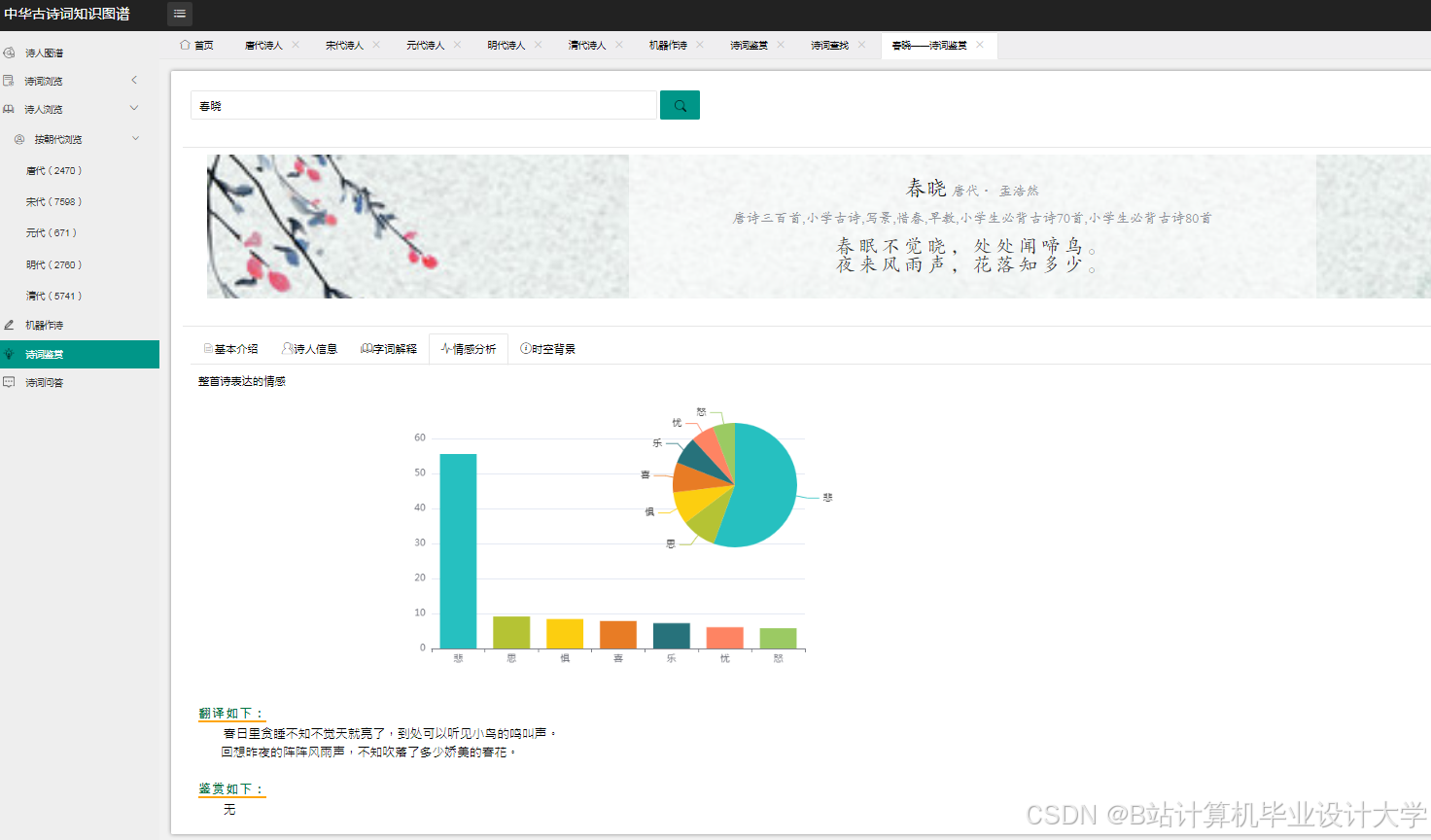
- 深度学习大模型训练:利用深度学习框架(如TensorFlow、PyTorch)训练大模型(如LSTM、BERT等),对古诗词进行主题分类、情感分析等任务。
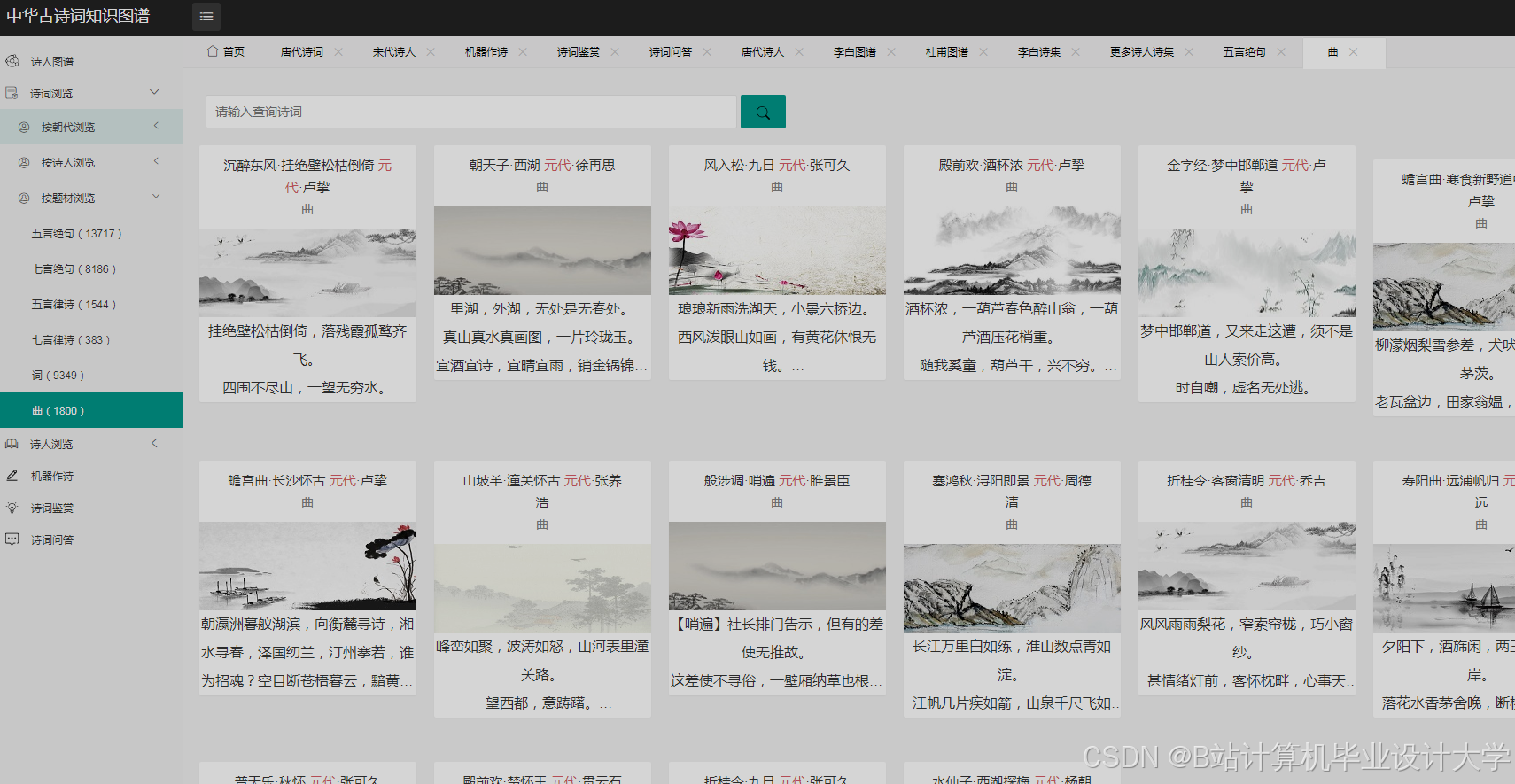
- 可视化系统设计:利用前端可视化库(如D3.js、ECharts)设计并实现古诗词知识图谱的可视化系统。
技术路线
- 数据收集与预处理:利用Python的爬虫技术从互联网或古籍数据库中收集古诗词数据,并利用jieba等分词工具进行分词处理。
- 知识图谱构建:基于预处理后的数据,利用Neo4j等图数据库构建古诗词的知识图谱。
- 深度学习大模型训练:利用深度学习框架训练大模型,对古诗词进行主题分类、情感分析等任务。
- 可视化系统设计:利用D3.js等前端可视化库设计并实现古诗词知识图谱的可视化系统。
四、研究方法
- 文献调研法:通过查阅相关文献,了解国内外在古诗词数字化处理、知识图谱构建及可视化方面的研究进展和技术方法。
- 实验法:通过编写Python代码,实现数据收集、预处理、知识图谱构建、深度学习大模型训练及可视化系统的设计与实现。
- 比较分析法:对比不同方法在处理古诗词数据、构建知识图谱及可视化效果方面的差异,选择最优方案。
五、研究进度安排
- 第一阶段(1-2个月):完成数据收集与预处理工作,构建初步的古诗词数据集。
- 第二阶段(2-3个月):构建古诗词的知识图谱,并进行初步的可视化展示。
- 第三阶段(3-4个月):训练深度学习大模型,挖掘古诗词的潜在信息,并优化知识图谱的构建。
- 第四阶段(4-6个月):完善可视化系统的设计与实现,进行用户测试与反馈收集。
六、预期成果
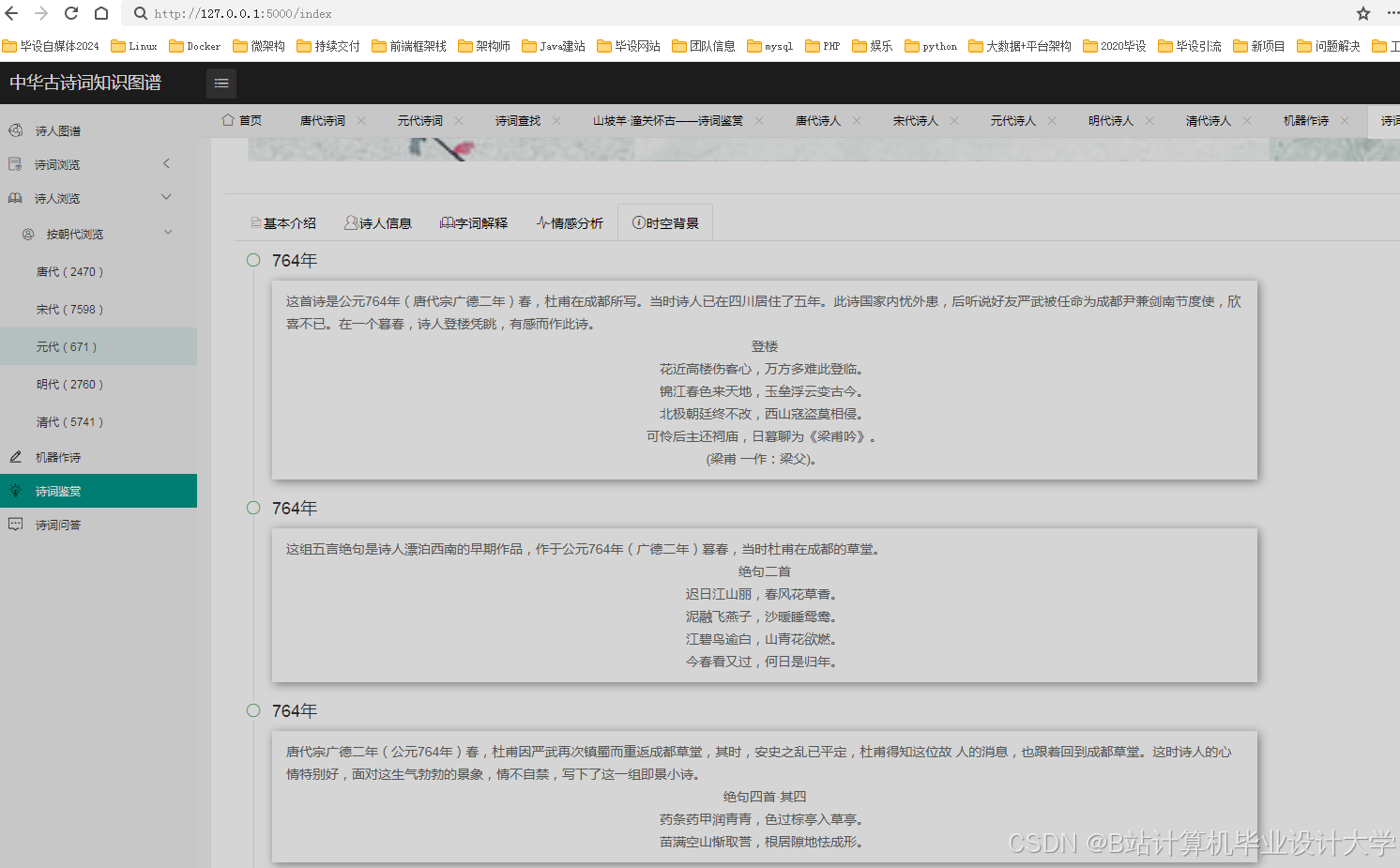
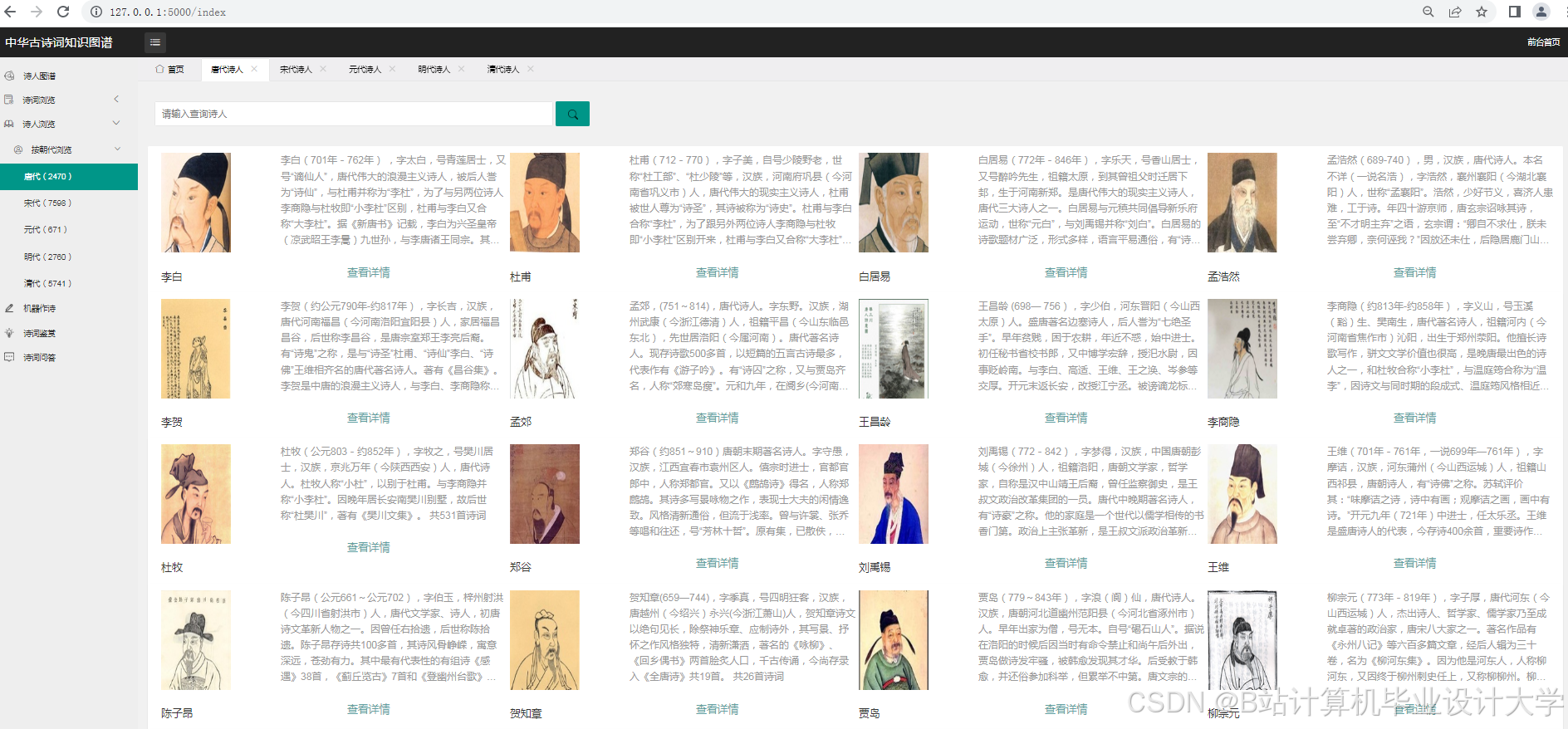
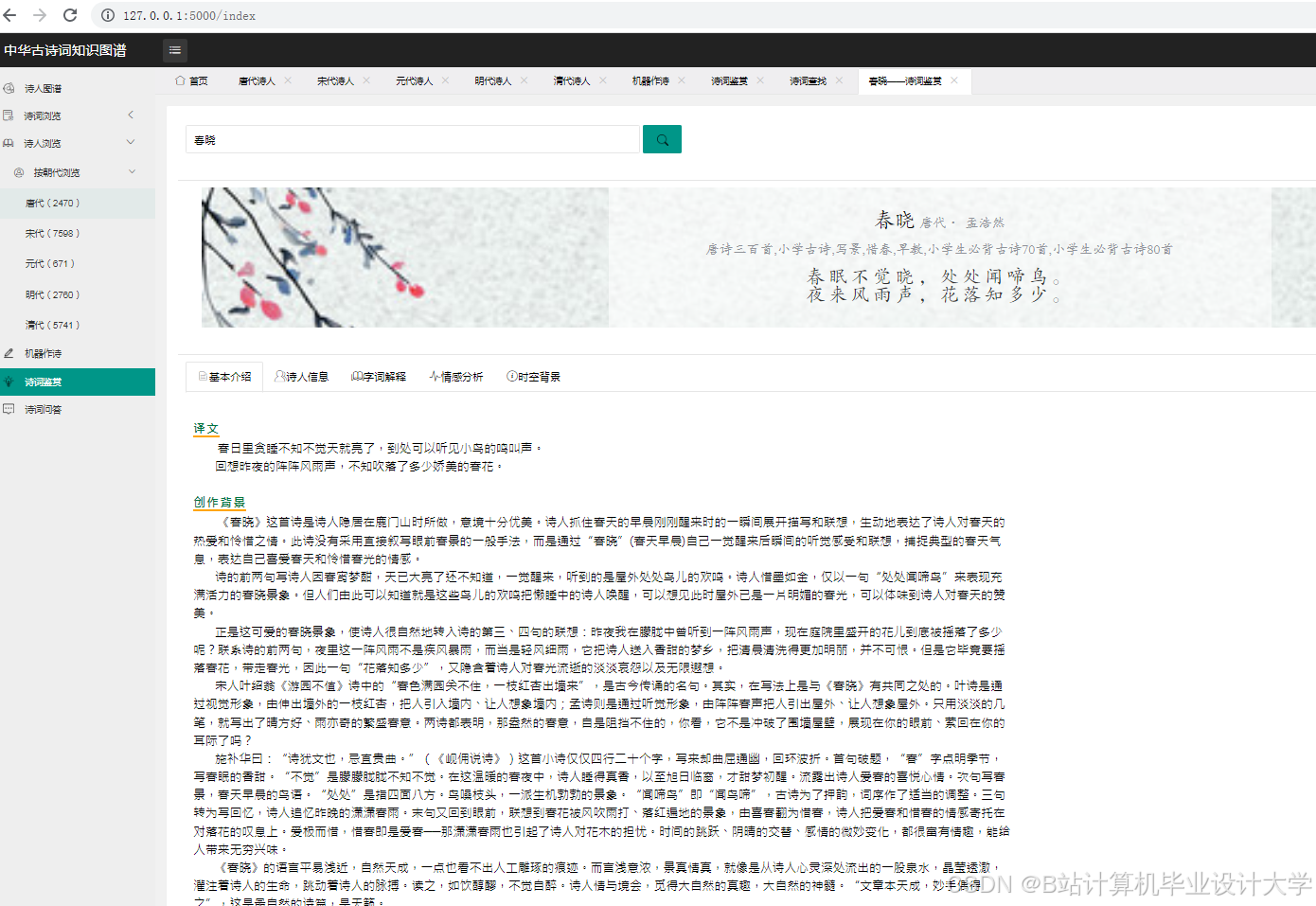
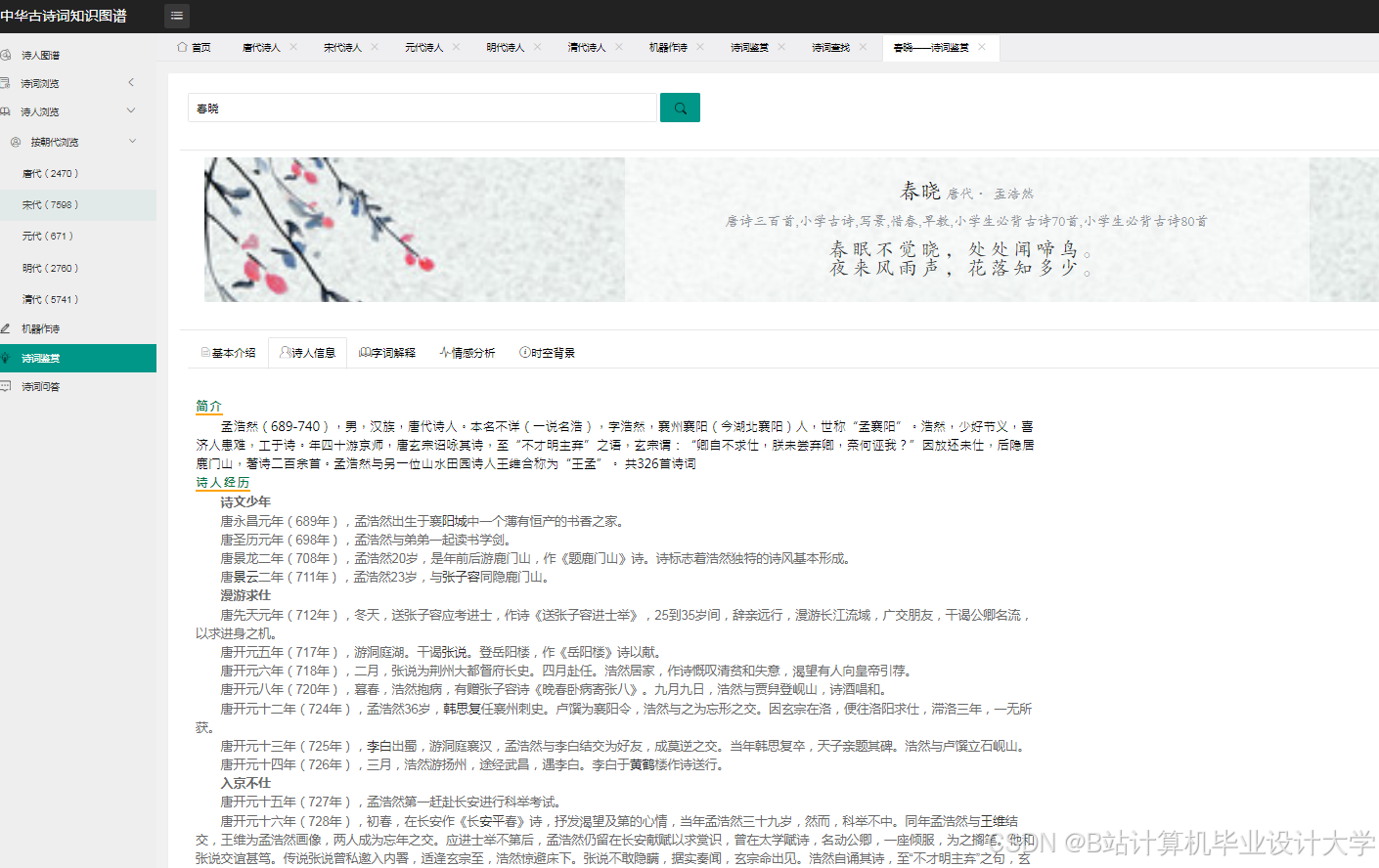
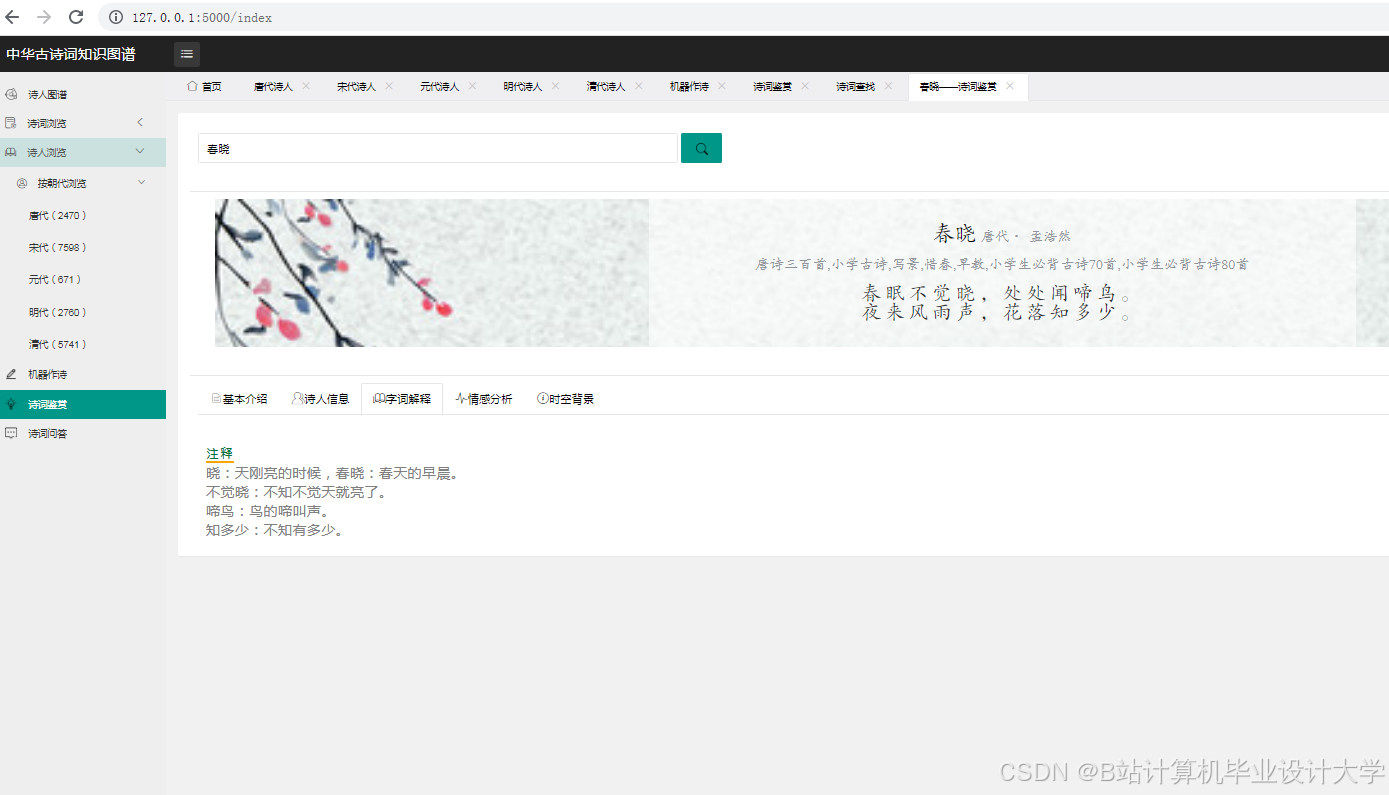
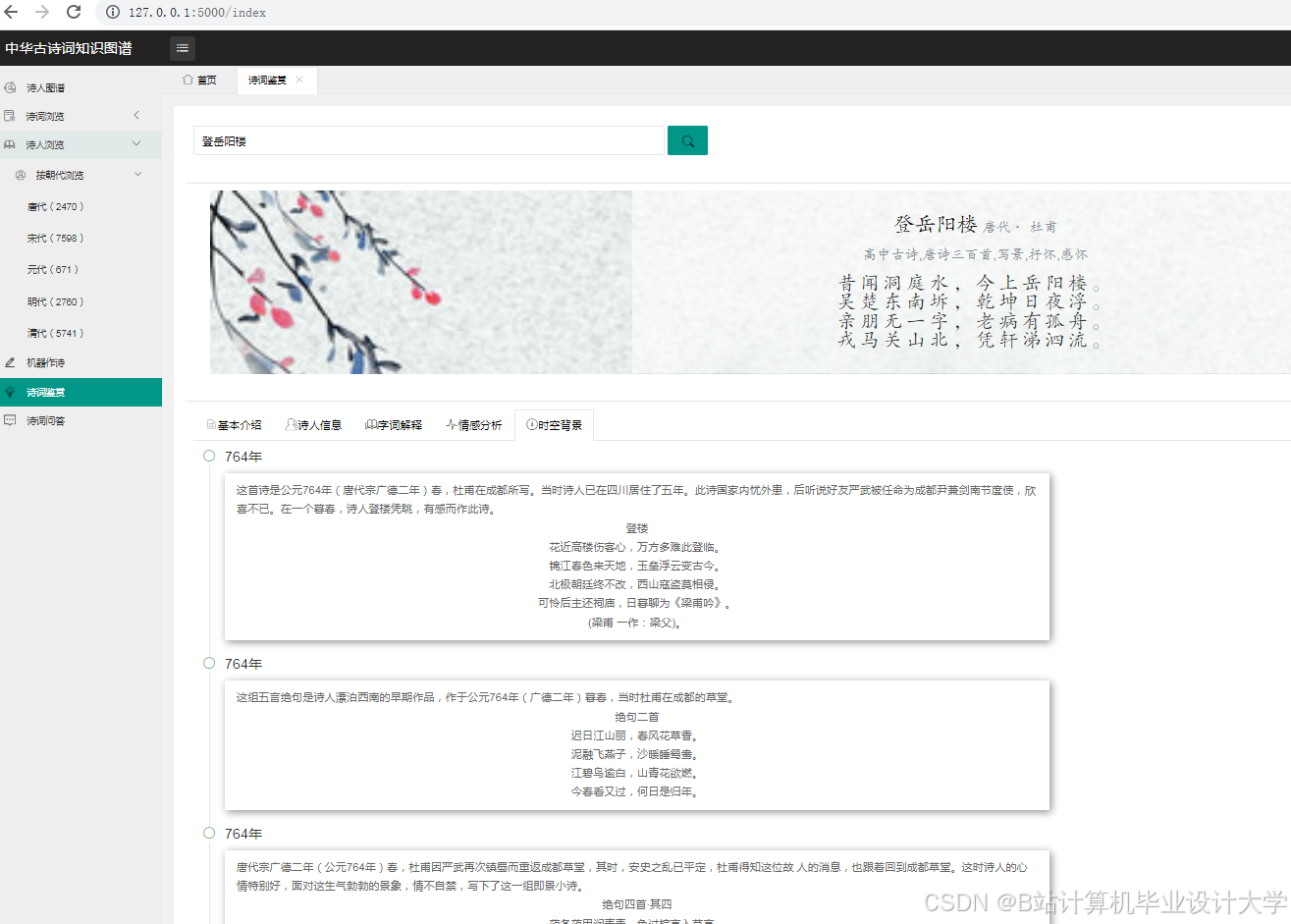
- 构建一个包含作者、朝代、题材、情感等维度的中华古诗词知识图谱。
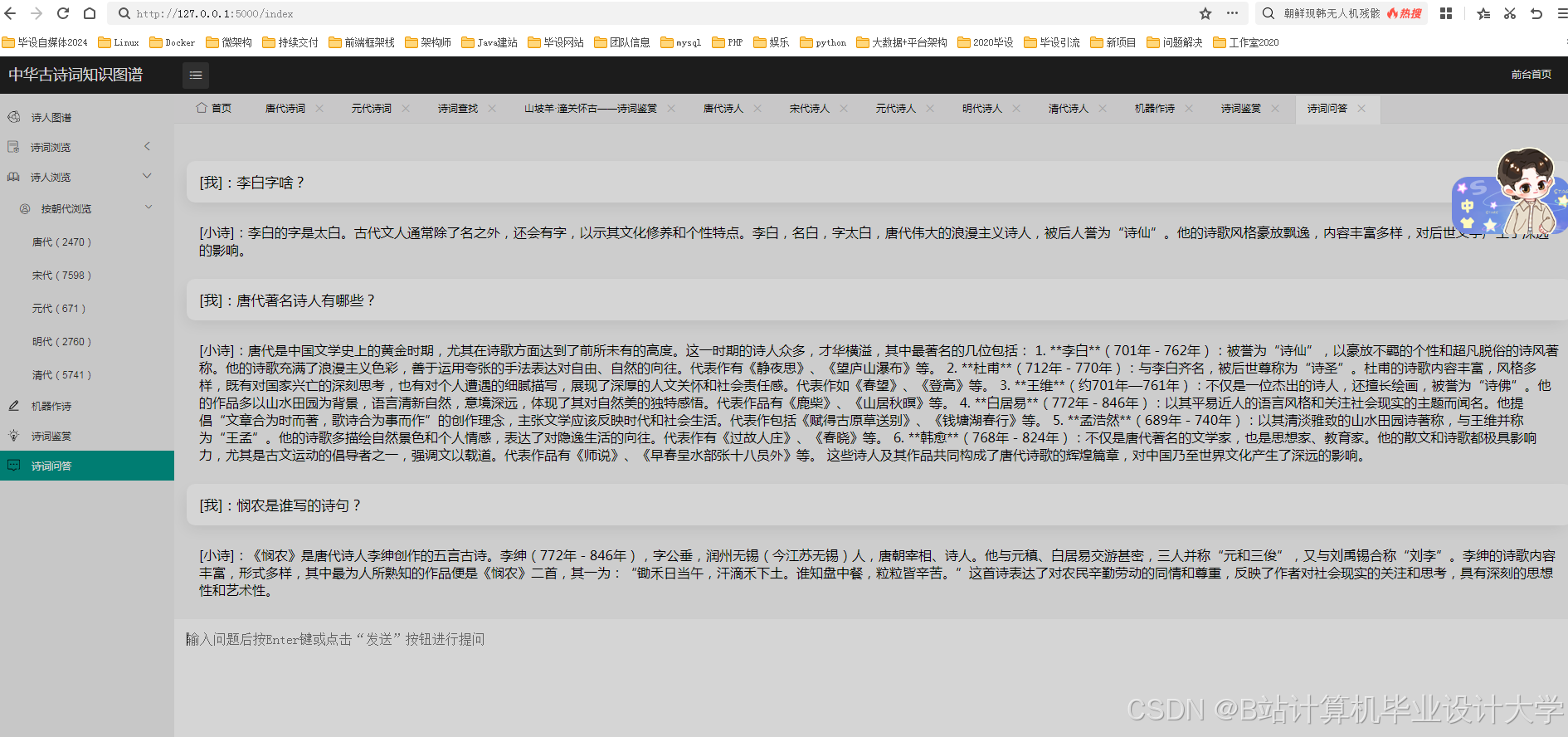
- 实现一个基于深度学习大模型的古诗词主题分类和情感分析系统。
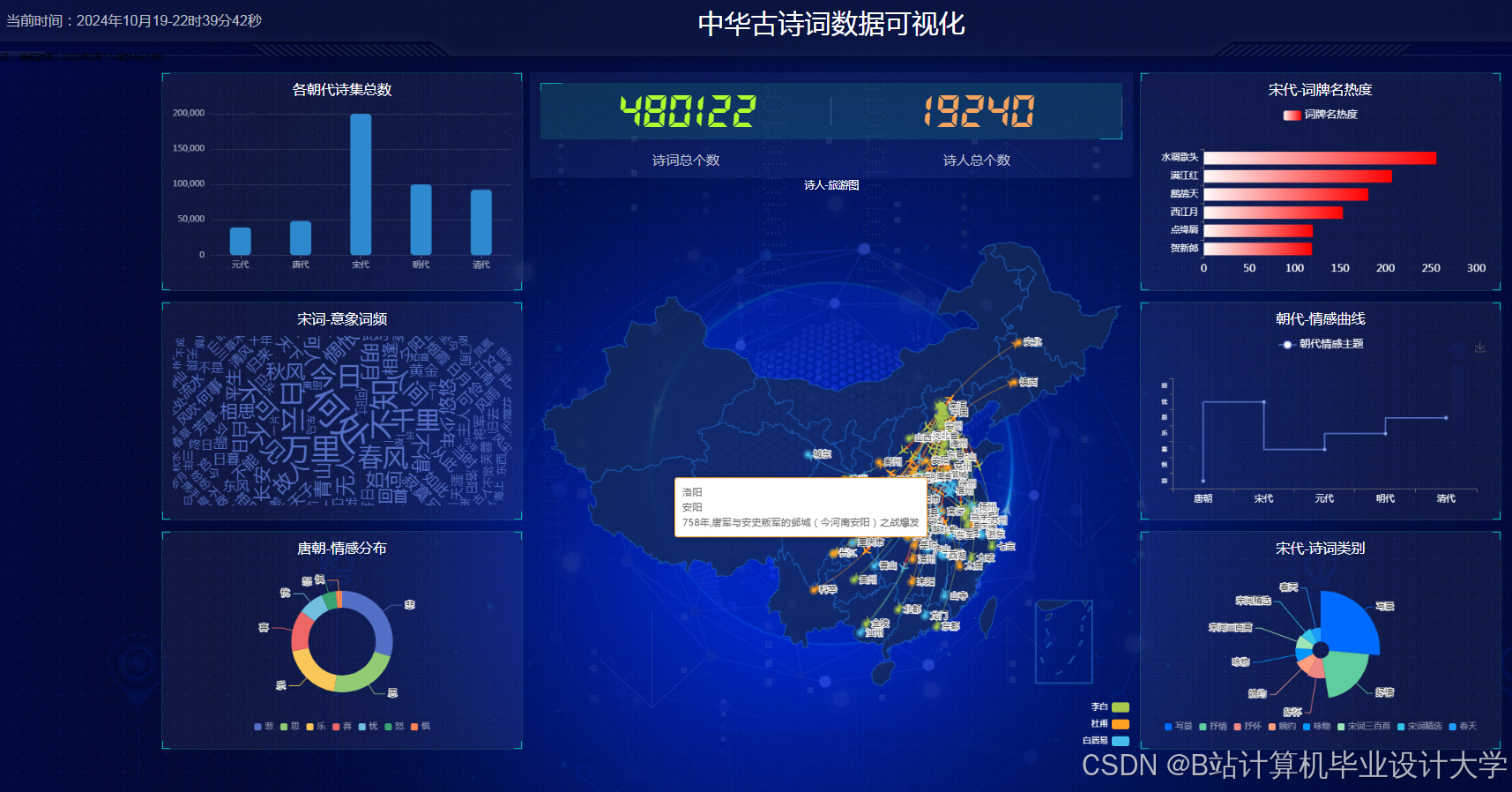
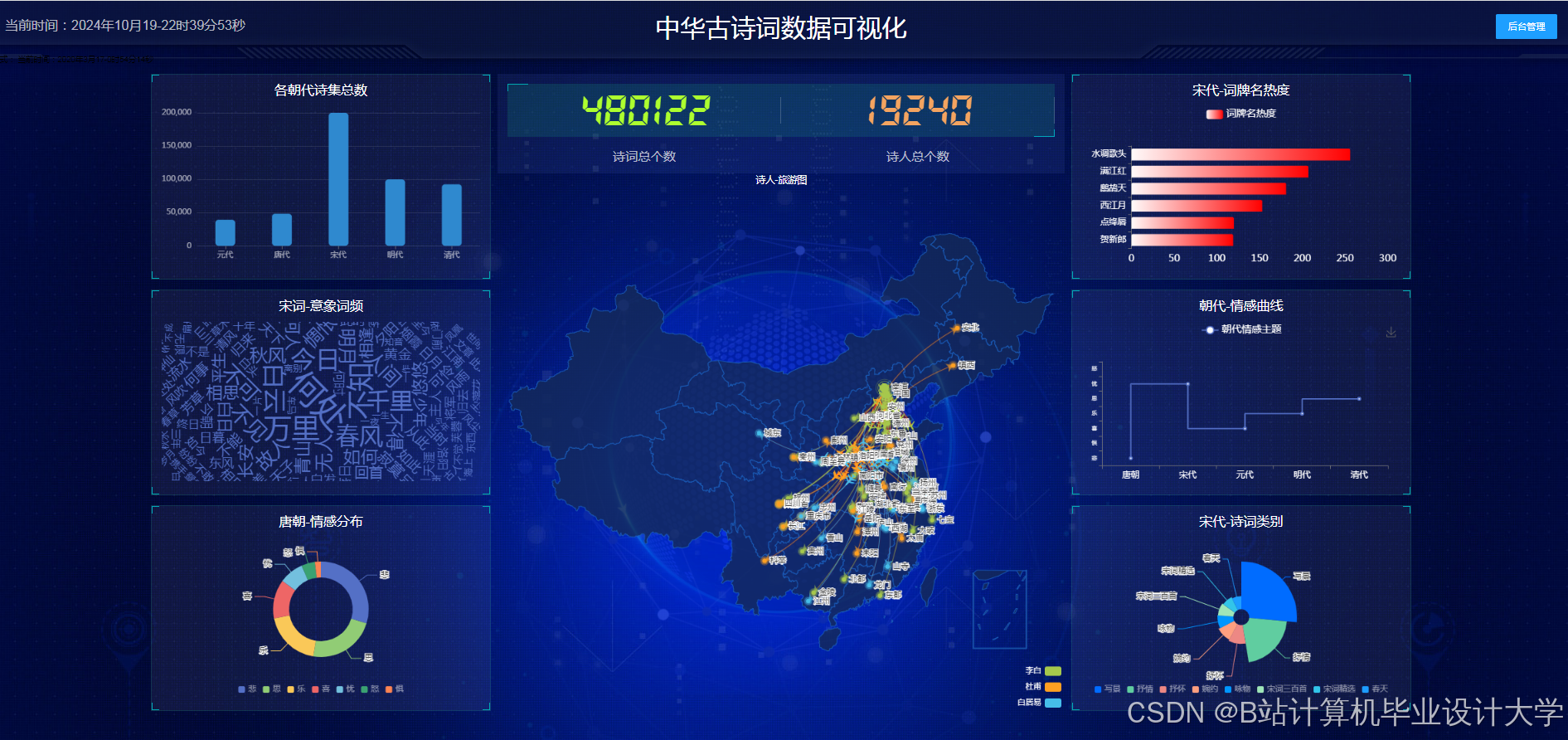
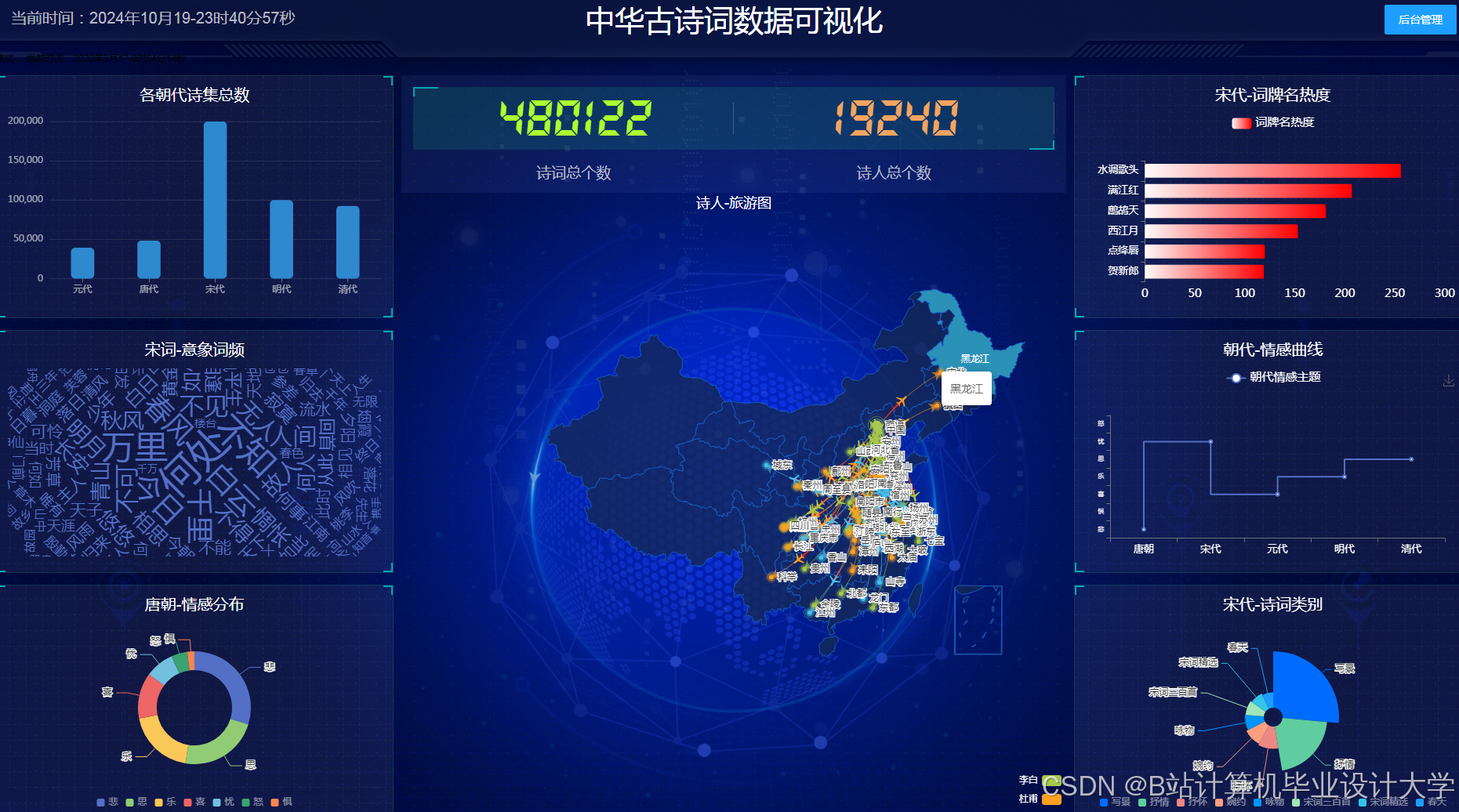
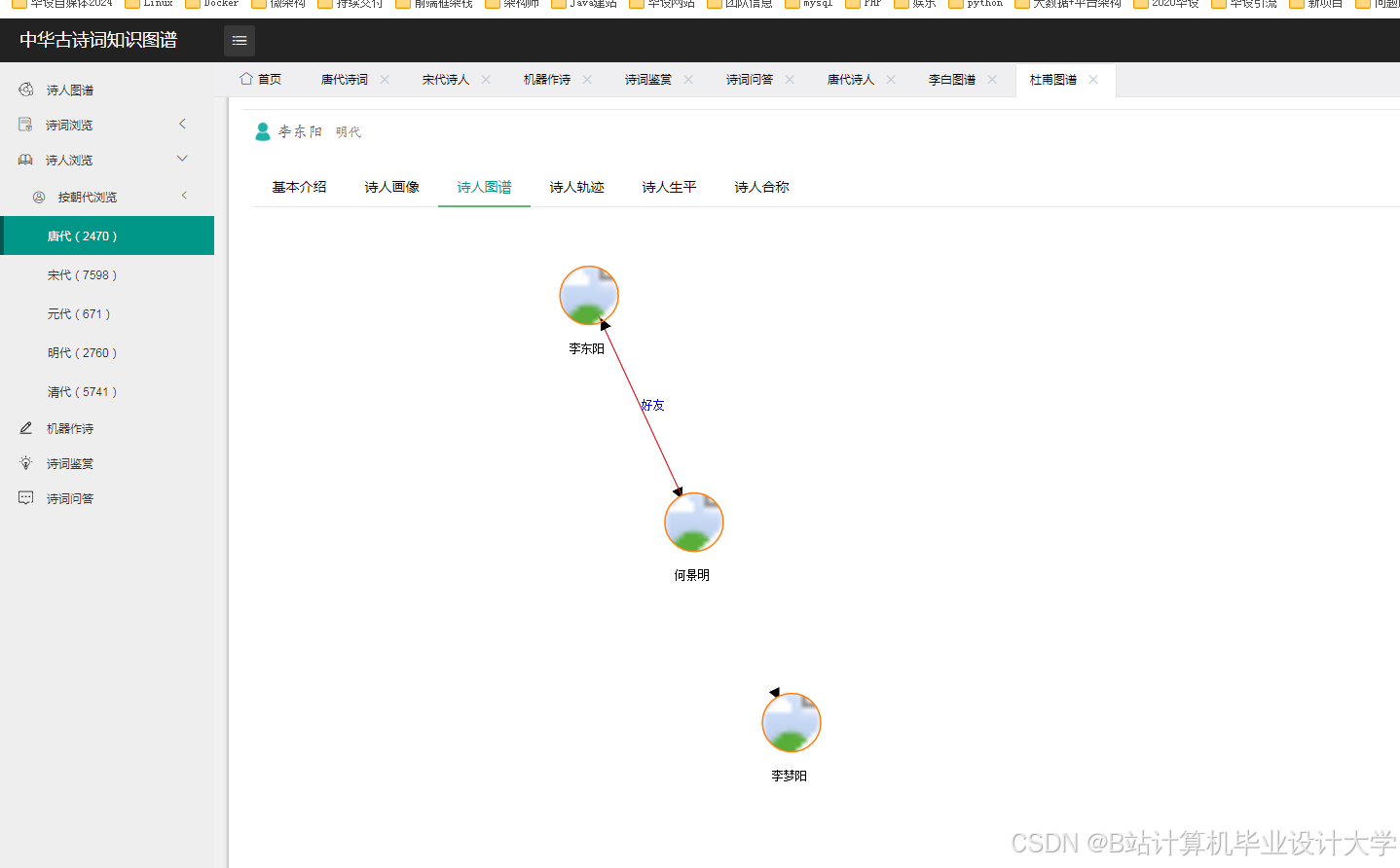
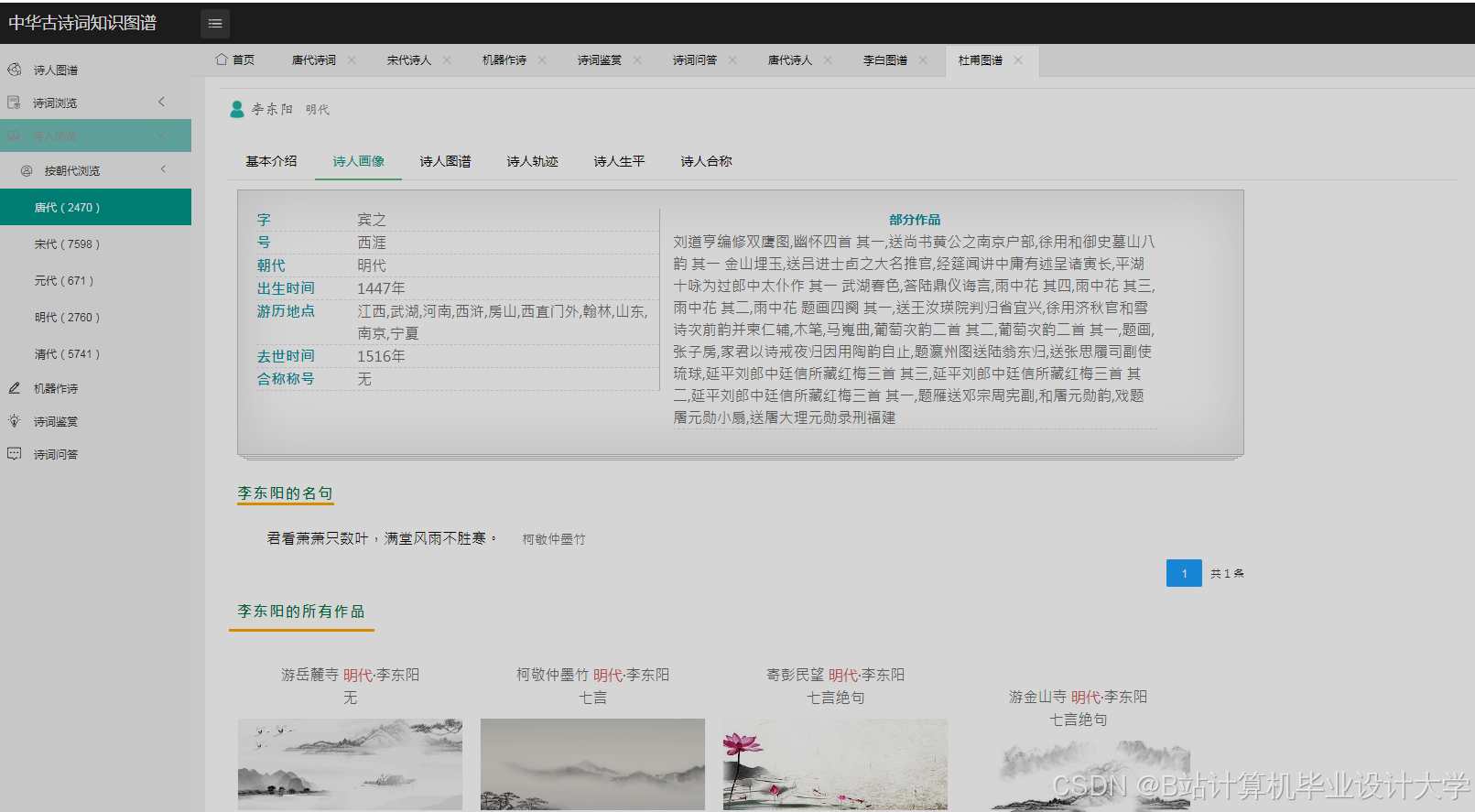
- 设计并实现一个古诗词知识图谱的可视化系统,展示其结构和关系。
七、参考文献
[列出具体的参考文献]
通过以上开题报告,我们明确了《Python+大模型知识图谱中华古诗词可视化》的研究背景、意义、内容、技术路线、研究方法、进度安排和预期成果。该项目旨在利用现代技术手段,推动中华古诗词的数字化处理和可视化展示,为中华文化的传承与发展贡献一份力量。
核心算法代码分享如下:
import torch,pickle,re
from zhon.hanzi import punctuation
import torch.nn as nn
import torch.nn.functional as F
from torch.optim import Adam
from torch.utils.data import DataLoader
class Vocab:
UNK_TAG = "<UNK>" # 表示未知字符
PAD_TAG = "<PAD>" # 填充符
PAD = 0
UNK = 1
def __init__(self):
self.dict = { # 保存词语和对应的数字
self.UNK_TAG: self.UNK,
self.PAD_TAG: self.PAD
}
self.count = {} # 统计词频的
def fit(self, sentence):
"""
接受句子,统计词频
:param sentence:[str,str,str]
:return:None
"""
for word in sentence:
self.count[word] = self.count.get(word, 0) + 1 # 所有的句子fit之后,self.count就有了所有词语的词频
def build_vocab(self, min_count=1, max_count=None, max_features=None):
"""
根据条件构造 词典
:param min_count:最小词频
:param max_count: 最大词频
:param max_features: 最大词语数
:return:
"""
if min_count is not None:
self.count = {word: count for word, count in self.count.items() if count >= min_count}
if max_count is not None:
self.count = {word: count for word, count in self.count.items() if count <= max_count}
if max_features is not None:
# [(k,v),(k,v)....] --->{k:v,k:v}
self.count = dict(sorted(self.count.items(), lambda x: x[-1], reverse=True)[:max_features])
for word in self.count:
self.dict[word] = len(self.dict) # 每次word对应一个数字
# 把dict进行翻转
self.inverse_dict = dict(zip(self.dict.values(), self.dict.keys()))
def transform(self, sentence, max_len=None):
"""
把句子转化为数字序列
:param sentence:[str,str,str]
:return: [int,int,int]
"""
if len(sentence) > max_len:
sentence = sentence[:max_len]
else:
sentence = sentence + [self.PAD_TAG] * (max_len - len(sentence)) # 填充PAD
return [self.dict.get(i, 1) for i in sentence]
def inverse_transform(self, incides):
"""
把数字序列转化为字符
:param incides: [int,int,int]
:return: [str,str,str]
"""
return [self.inverse_dict.get(i, "<UNK>") for i in incides]
def __len__(self):
return len(self.dict)
train_batch_size = 128
test_batch_size = 128
voc_model = pickle.load(open("./models/vocab.pkl", "rb"))
sequence_max_len = 100
class ImdbModel(nn.Module):
def __init__(self):
super(ImdbModel, self).__init__()
self.embedding = nn.Embedding(num_embeddings=len(voc_model), embedding_dim=200, padding_idx=voc_model.PAD).to()
self.lstm = nn.LSTM(input_size=200, hidden_size=64, num_layers=6, batch_first=True, bidirectional=True,
dropout=0.1)
self.fc1 = nn.Linear(64 * 2, 64)
self.fc2 = nn.Linear(64, 7)
def forward(self, input):
"""
:param input:[batch_size,max_len]
:return:
"""
input_embeded = self.embedding(input) # input embeded :[batch_size,max_len,200]
output, (h_n, c_n) = self.lstm(input_embeded) # h_n :[4,batch_size,hidden_size]
# out :[batch_size,hidden_size*2]
out = torch.cat([h_n[-1, :, :], h_n[-2, :, :]], dim=-1) # 拼接正向最后一个输出和反向最后一个输出
# 进行全连接
out_fc1 = self.fc1(out)
# 进行relu
out_fc1_relu = F.relu(out_fc1)
# 全连接
out_fc2 = self.fc2(out_fc1_relu) # out :[batch_size,2]
return F.log_softmax(out_fc2, dim=-1)
def device():
if torch.cuda.is_available():
return torch.device('cuda')
else:
return torch.device('cpu')
#诗词分割
def tokenlize(sentence):
"""
进行文本分词
:param sentence: str
:return: [str,str,str]
"""
fileters = ['!', '"', '#', '$', '%', '&', '\(', '\)', '\*', '\+', ',', '-', '\.', '/', ':', ';', '<', '=', '>',
'\?', '@', '\[', '\\', '\]', '^', '_', '`', '\{', '\|', '\}', '~', '\t', '\n', '\x97', '\x96', '”',
'“', ]
sentence = re.sub("|".join(fileters), "", sentence)
punctuation_str = punctuation
for i in punctuation_str:
sentence = sentence.replace(i, '')
sentence=' '.join(sentence)
result = [i for i in sentence.split(" ") if len(i) > 0]
return result
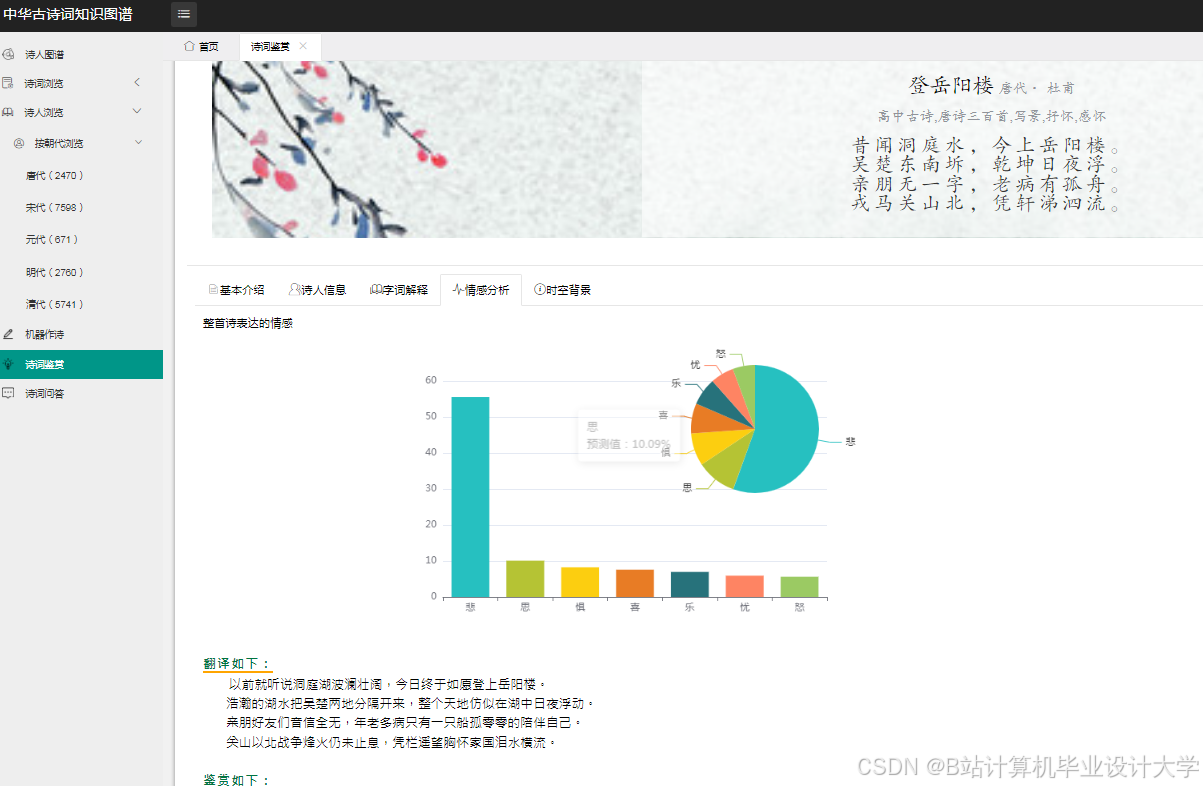
def poem_emotion_predict(line):
sequence_max_len=100
model = torch.load('./models/lstm_model.pkl',map_location=torch.device('cpu'))
model.to(device())
print(line)
review = tokenlize(line)
# review=tokenlize(line)
vocab_model = pickle.load(open("./models/vocab.pkl", "rb"))
result = vocab_model.transform(review,sequence_max_len)
# print(result)
data = torch.LongTensor(result).to(device())
data=torch.reshape(data,(1,sequence_max_len)).to(device())
# print(data.shape)
output = model(data)
data=output.data.cpu().numpy()
#['悲', '惧', '乐', '怒', '思', '喜', '忧']
dit={}
sum=0
for i in range(len(data[0])):
sum+=abs(float(data[0][i]))
if i==0:
dit['悲']=abs(float(data[0][i]))
if i==1:
dit['惧'] = abs(float(data[0][i]))
if i==2:
dit['乐']=abs(float(data[0][i]))
if i==3:
dit['怒'] = abs(float(data[0][i]))
if i==4:
dit['思']=abs(float(data[0][i]))
if i==5:
dit['喜'] =abs(float(data[0][i]))
if i==6:
dit['忧']=abs(float(data[0][i]))
#dit=dict(sorted(dit.items(), key=lambda item: item[1], reverse=True))
newsum=0
for key,value in dit.items():
print(value/sum)
if value/sum>0.1:
val=round((1-value/sum-0.7)*100,2)
else:
val=round((1-value/sum)*100,2)
dit[key]=val
newsum+=val
dit = dict(sorted(dit.items(), key=lambda item: item[1], reverse=True))
jsonData=[]
name=[]
val=[]
for key,value in dit.items():
name.append(key)
val.append(round(value/newsum*100,2))
print(key+" "+str(value))
dit={}
dit['name']=name
dit['value']=val
jsonData.append(dit)
# print(output.data.max(1, keepdim=True)[0].item())
pred = output.data.max(1, keepdim=True)[1] # 获取最大值的位置,[batch_size,1]
# print(pred.item())
#['悲', '惧', '乐', '怒', '思', '喜', '忧']
if pred.item() == 0:
print("悲")
elif pred.item() == 1:
print("惧")
elif pred.item() == 2:
print("乐")
elif pred.item() == 3:
print("怒")
elif pred.item() == 4:
print("思")
elif pred.item() == 5:
print("喜")
elif pred.item() == 6:
print("忧")
return jsonData
if __name__ == '__main__':
poem_emotion_predict('天街小雨润如酥')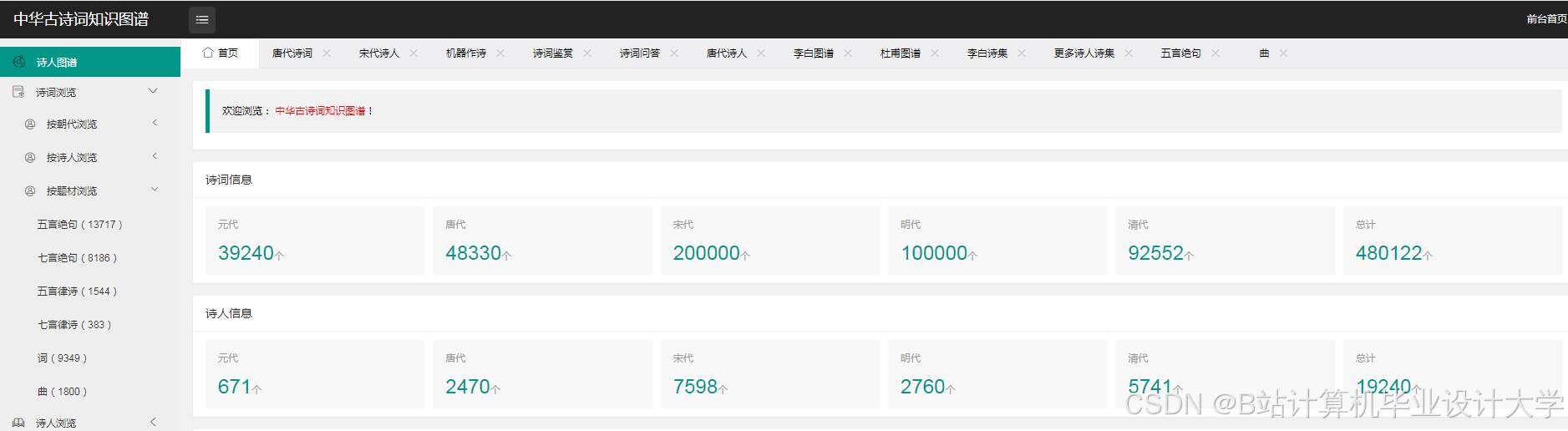
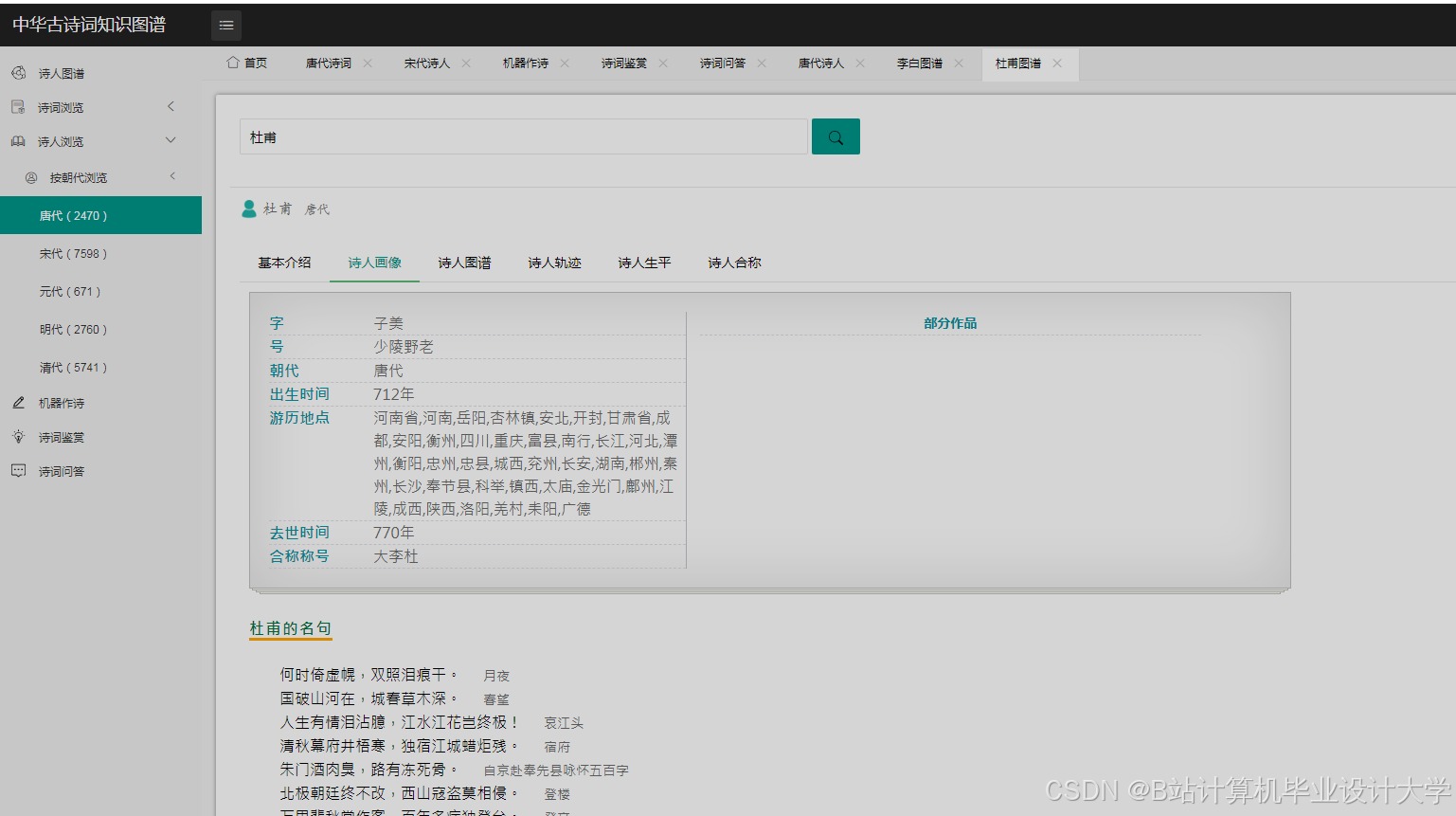
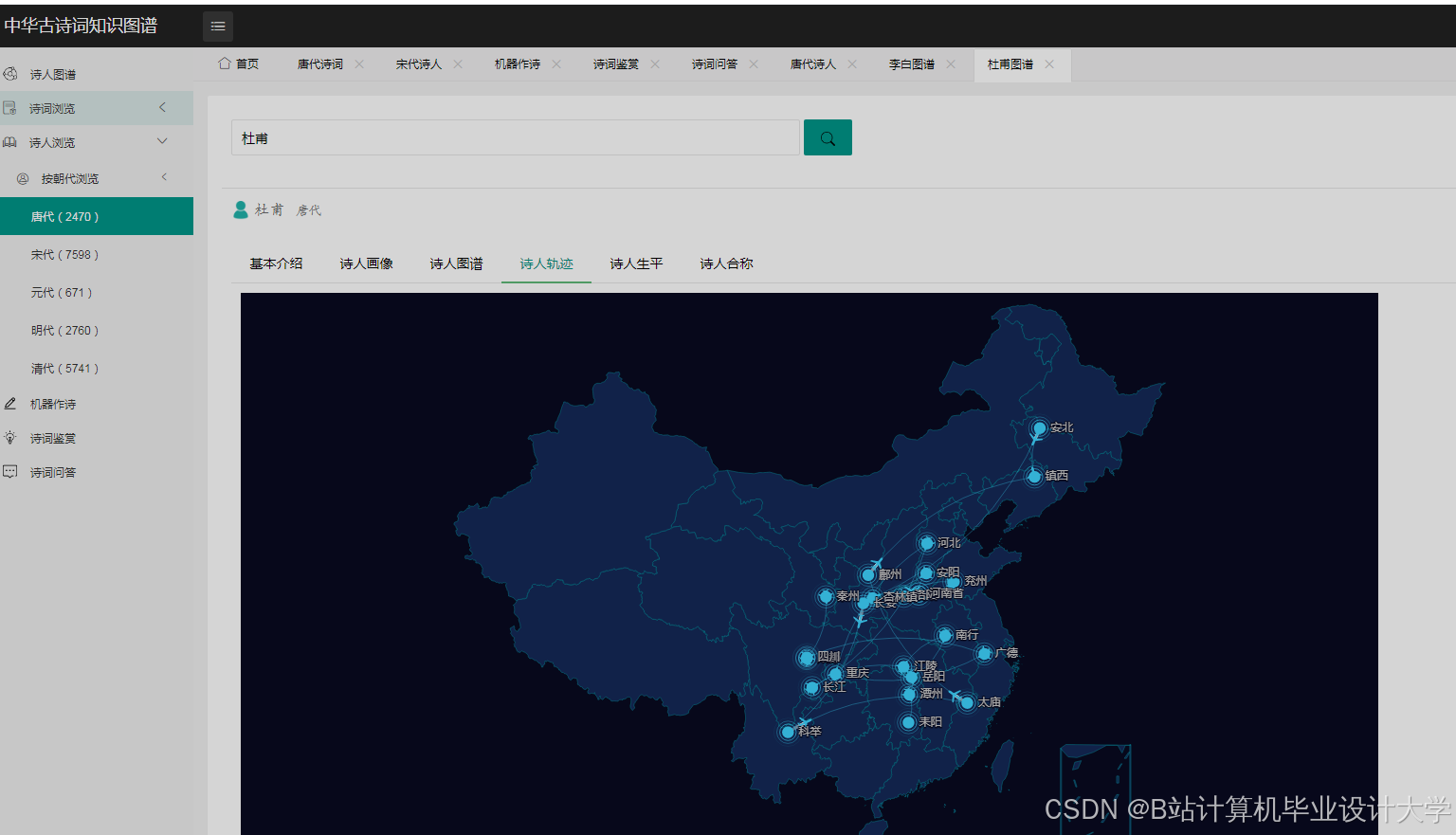
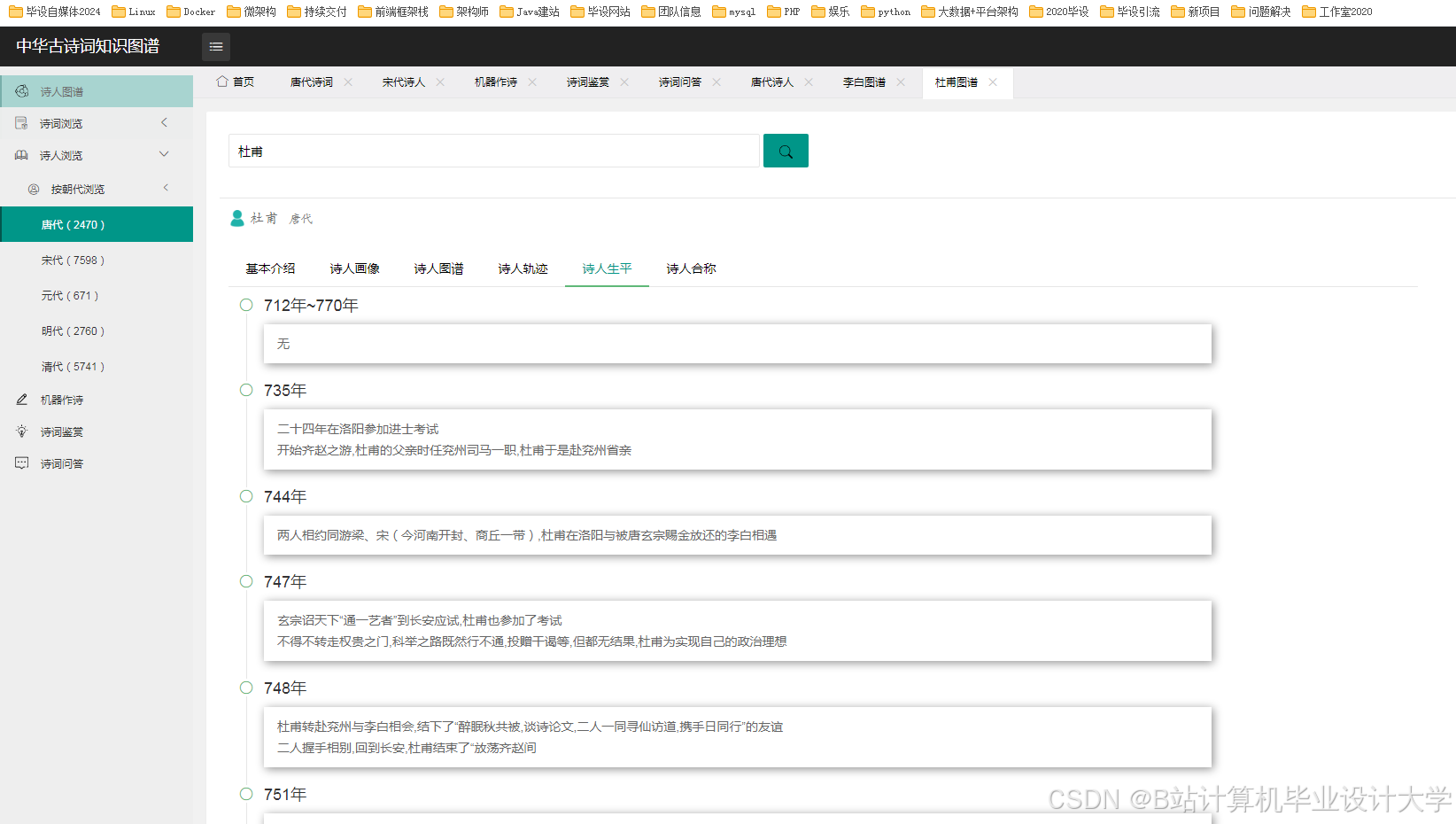
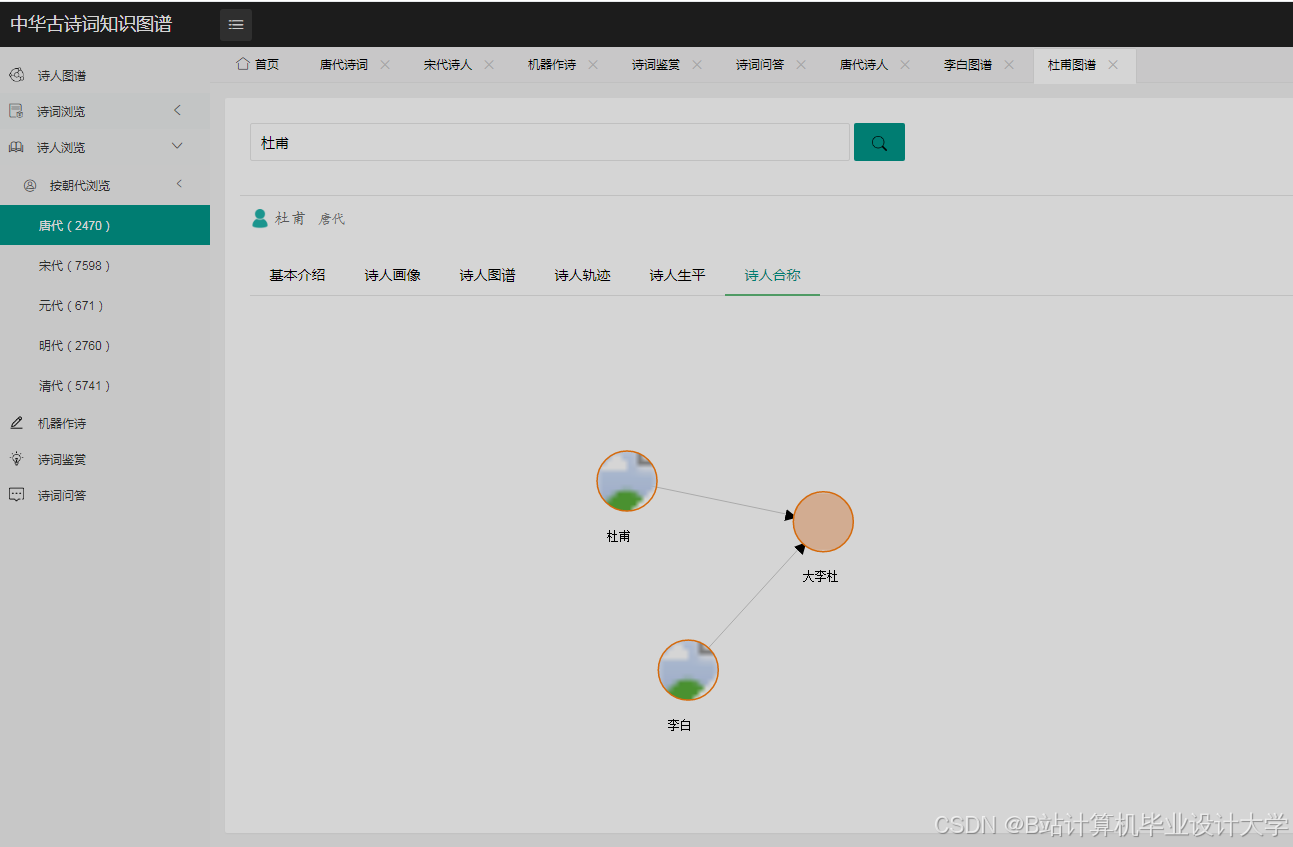


欢迎加入 MCP 技术社区!与志同道合者携手前行,一同解锁 MCP 技术的无限可能!
更多推荐


 26
26 0
0- 0



 已为社区贡献47条内容
已为社区贡献47条内容

所有评论(0)