如果用unsoloth进行微调lllama、phi、gamma和qwen等等(大白话篇)
如何利用unsloth进行大模型微调
什么是微调
使用特定任务的数据(如情感分类、问答系统)对预训练模型进行进一步训练,调整模型参数以适应该任务。
前言
什么是unsloth:
总结是一款微调的框架,在这个框架下,你的微调速度直接翻倍,最影响的就是速度,让不管好的电脑还是不咋地的电脑都能进行加速。很快能进行微调出结果
一、第一步:环境的搭建
我感觉代码的难度不大,新手最恼火的就是环境了,搭建这一套环境让很多人都望而却步,运行不是这个库没有就是那个库没有。我首先介绍我的环境
操作系统:linux
这个不用多说,别想着在windows来处理这些了,能是能处理,但是很多库对windows本身支持并不是很好,你本身就要做这件事,所以立刻马上,给我在虚拟机装一个linux。
这里环境搭建的第一步就是安装python不用我说了
我是用conda进行的,所以现在立刻马上去网上搜,如果conda安装
我的python版本是:3.12.7
现在conda装好了,直接创建一个虚拟环境,不习惯也得习惯,你做研究做这些必须环境要独立出来,不要整一个什么都能用的环境,这样你发现问题简直就是噩梦
附上我的环境的安装环境,这个呢,你可以找我要,因为太长了影响阅读environment.yml
本篇红色的部分都可以找我要
直接就是在你电脑运行:conda env create -f environment.yml
这样你的电脑就会拥有一个可以运行unsloth和其他需要包的环境
前提是运行没有出错哈,建议换国内的镜像
二、第二步:准备工作
这一步主要是啥呢,你想想,微调就是让一个大模型熟悉你的知识,做出你的知识所得到的结果,比如你把一个大模型想象一个刚毕业的大学生,啥都会点,但是不精,你一问他你专业的知识他就不知道了,所以你要把你专业的事告诉他,让他明白,他一旦学习了,面对你专业的事,他就自然而然就懂了,我这次用什么来研究呢?《患者是否患有脓毒症》当然这是我的工作,首先这个就是专业知识,当然你也可以换成你的,比如让他更明白法律,情感之类的,这个我只是举例,以我们研究的方向,患者是否患有脓毒症,首先你要2个事告诉模型,第一个是input,第二个是output,你要告诉他你的输入是什么,你的输出是什么
1.准备自己的数据
准备自己要预训练的数据
这是我们准备的数据集,是个json,里面装了几百条数据,当然你也要自己装备我一样数据结构的数据,input就是你要告诉模型你的问题是什么,output就是你让计算机知道遇到你这样的问题,应该问答什么,因为我们是一个研究患者是否患有脓毒症的嘛,0代表没有患脓毒症,1代表患有脓毒症。
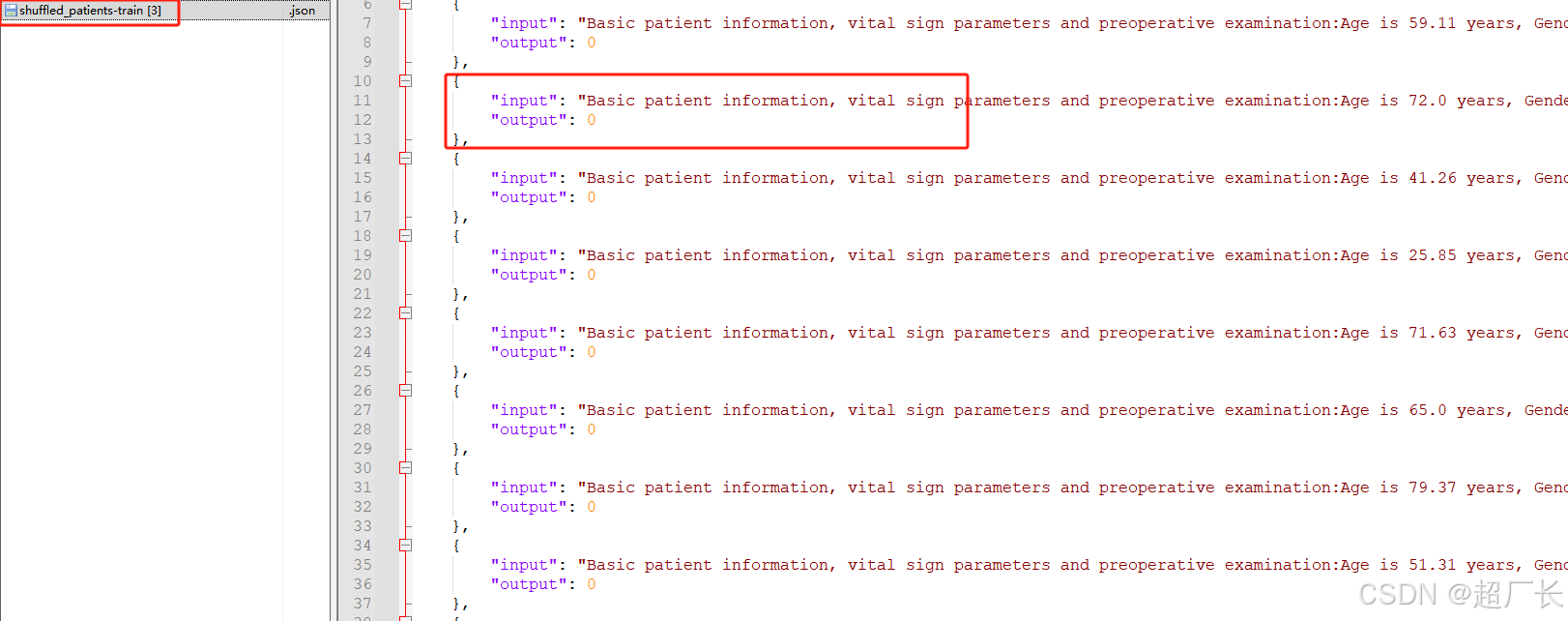
1.写代码进行训练
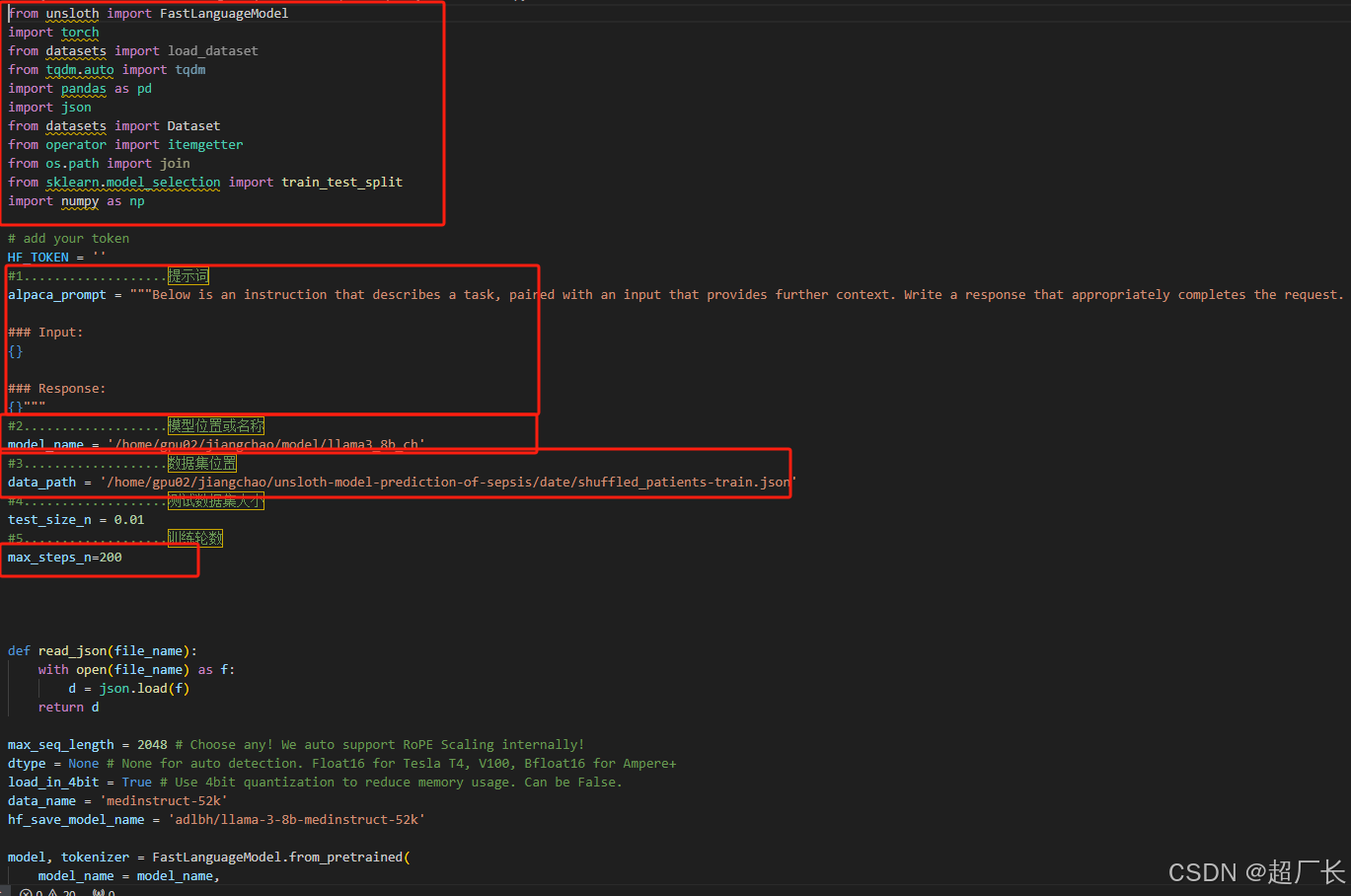
我写的代码已经精简了,只要你跟着第一步环境搭建好了,数据准备好了,那直接就可以进行训练了,我这里以qwen来举例
首先就是引用的包就能知道是个基于unsloth框架来记性大模型的微调了
第二呢:提示词在大模型微调也很重要,当然我们这一套是经过调整的。是符合面对多维度复杂场景下最好的提示词
第三呢:就是更改模型的位置
第四呢:更改你的预训练数据的位置,就是上面叫你准备的数据集
设置要多大的部署,看你机器而定,我们研究环境是3张4090,所以bath_size和steps都可以设大一点
直接训练就能得到一个适配器文件夹,里面包含的基座模型和这次训练的结果
第三步:测试自己的训练结果
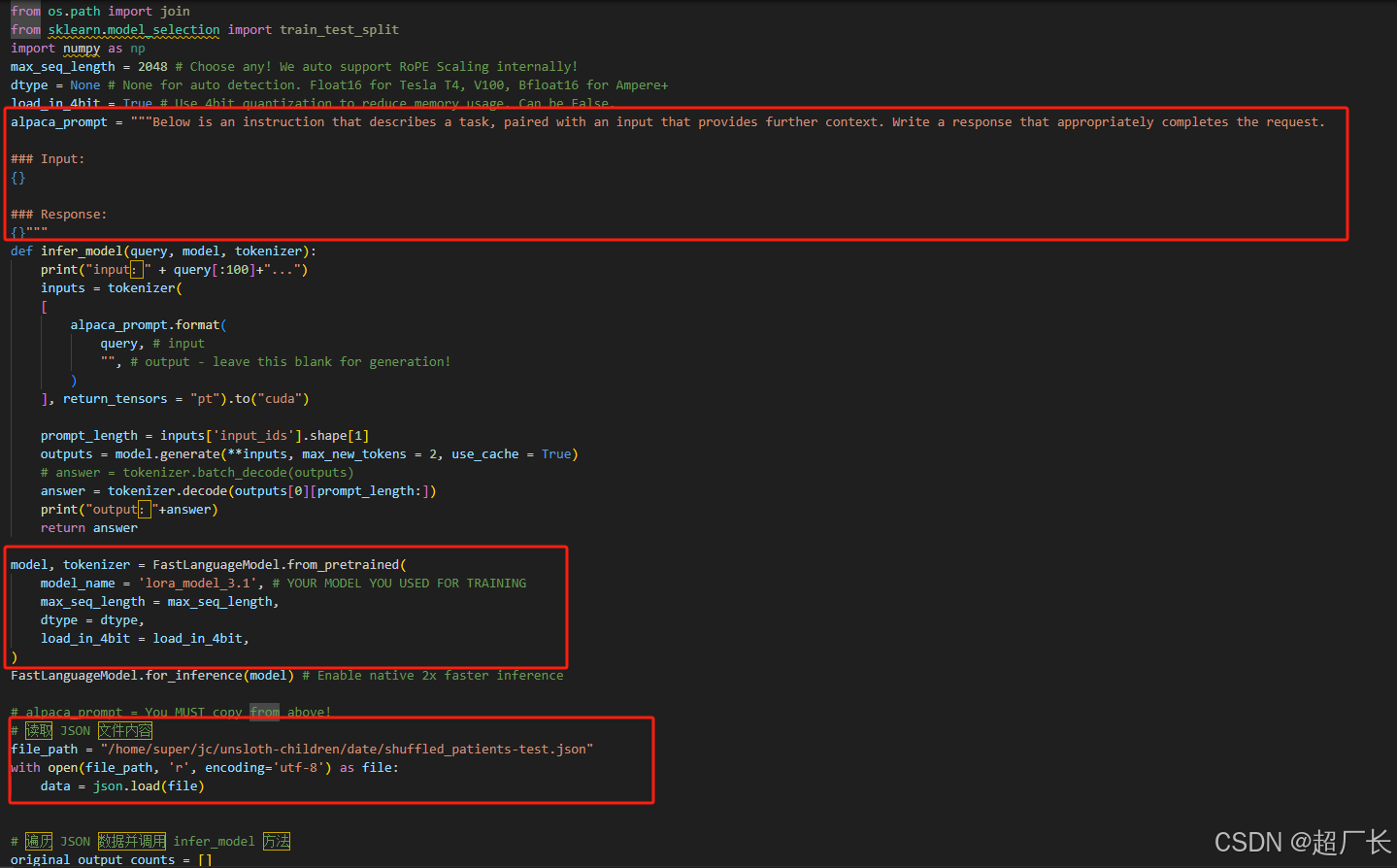
就3个点:提示词文本,导入模型,导入自己测试的数据
提示词文本:和训练的一样
导入模型:导入刚刚我们输出的
导入自己测试的数据:这一步呢,这个测试数据完全是和训练的数据一模一样的结构,但是就是数据不同,你可以准备500条数据,其中80%提取出来作为训练,20%作为测试
直接运行就能得到结果
这是我们基于llama3训练出来的最好的效果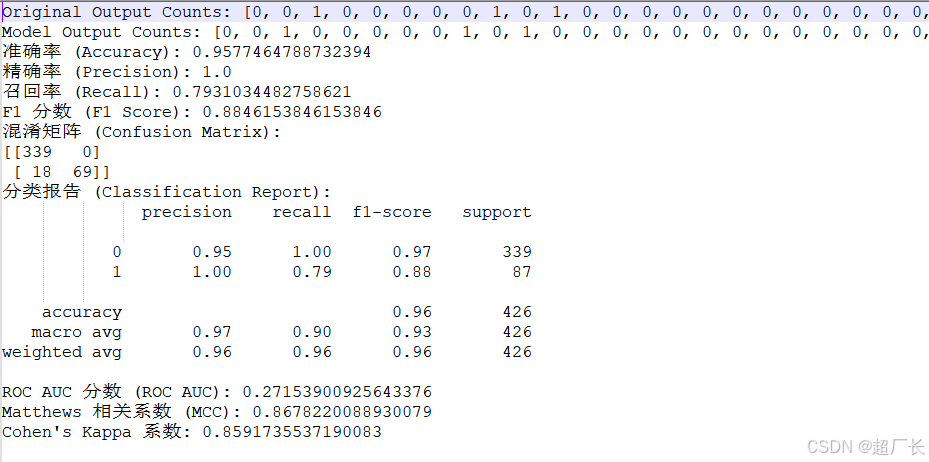
而且我们准备的数据也没多少,这样的结果来说相当可以了,可以作为很多领域下大模型微调的重要参考了
总结
环境很重要:
其实代码上unsloth的github下都说得很清楚了,大家有空可以去看看
https://github.com/unslothai/unsloth
当然我们是做了精简:只有2个代码文件
就训练和测试,就能包括所有的,需要的也可以找我要
关注公众号;程序员PG
找到我

欢迎加入 MCP 技术社区!与志同道合者携手前行,一同解锁 MCP 技术的无限可能!
更多推荐

 27
27 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)