大模型微调(Fine-tuning)实战:快速使用 colab下的unsloth 零成本打造定制化模型
最近b站上刷到一个博主,大模型DeepSeek,实现本地运行,打造一款定制化的LLM,下面是一些关键步骤和代码。UP主的案例是微调deepseek,打造一个。
·
前言
最近b站上刷到一个博主,微调(Fine-tuning)大模型DeepSeek,实现本地运行,打造一款定制化的LLM,下面是一些关键步骤和代码。
UP主的案例是微调deepseek,打造一个算命大师模型。
一、准备工作
- Colab 是一个基于云端的编程环境
- unsloth是一个开源工具,专门用来加速大语言模型(LLMs)的微调过程
- HuggingFace: 汇聚了众多最前沿的模型和数据集等
首先打开 Colab ,这里是我们的IDE。
将运行时类型改为 T4 GPU(NVIDIA 推出的一款高性能 GPU,特别适合深度学习任务)

二、使用colab平台微调模型
主要步骤
Colab是一个云端编译环境,它提供的是 一个 Jupyter Notebook的IDE
1.安装依赖
# 安装unsloth包(大型语言模型微调工具)
!pip install unsloth
# 卸载旧版本并安装最新版unsloth(GitHub源码)
!pip uninstall unsloth -y && pip install --upgrade --no-cache-dir --no-deps git+https://github.com/unslothai/unsloth.git
# 安装量化工具包
!pip install bitsandbytes unsloth_zoo
输出如下:
2.加载预训练模型
model_name,然后我们选择的是DeepSeek-R1-Distill-Llama-8B(基于 Llama 的 DeepSeek-R1 蒸馏版本,80 亿参数)
from unsloth import FastLanguageModel
import torch
max_seq_length = 2048 # 模型处理文本的最大长度(上下文窗口)
dtype = None # 自动选择计算精度(通常为float16或bfloat16)
load_in_4bit = True # 启用4位量化压缩,减少显存占用
# 加载预训练模型
model, tokenizer = FastLanguageModel.from_pretrained(
model_name="unsloth/DeepSeek-R1-Distill-Llama-8B", # 模型名称
max_seq_length=max_seq_length,
dtype=dtype,
load_in_4bit=load_in_4bit,
# token="hf_...", # HuggingFace 访问令牌(私有模型需填写)
)
4bit 量化(4bit Quantization):一种技术,通过减少模型的精度来节省内存,就像把一个大箱子压缩成一个小箱子,方便携带。
3.微调前测试
# 定义提示词模板(Prompt Engineering)
prompt_style = """以下是描述任务的指令,以及提供进一步上下文的输入。
请写出一个适当完成请求的回答。
在回答之前,请仔细思考问题,并创建一个逻辑连贯的思考过程,以确保回答准确无误。
### 指令:
你是一位精通卜卦、星象和运势预测的算命大师。请回答以下算命问题。
### 问题:
{}
### 回答:
<think>{}"""
# {} 为占位符,后续填充具体问题
# 定义测试问题
question = "1992年闰四月初九巳时生人,女,想了解健康运势"
关键设计解析
| 组件 | 作用 | 最佳实践 |
|---|---|---|
| 指令模板 | 明确模型角色(算命大师)和任务目标(运势预测) | 角色扮演式提示词提升任务对齐度 |
| 思考过程引导 | 要求模型先构建逻辑推理链再生成答案 | 减少幻觉,提高答案可信度 |
| 占位符 {} | 动态插入用户具体问题,实现模板复用 | 提升代码可维护性 |
下面我们测试下微调前的模型的输出
# 准备模型进入推理模式(禁用训练层优化以提升速度)
FastLanguageModel.for_inference(model)
# 构造输入并编码
inputs = tokenizer(
[prompt_style.format(question, "")], # 可能有OCR错误,第二个参数应为占位符填充
return_tensors="pt",
).to("cuda") # 数据移至GPU
# 生成回答
outputs = model.generate(
input_ids=inputs.input_ids,
attention_mask=inputs.attention_mask,
max_new_tokens=1200, # 控制生成文本最大长度
use_cache=True, # 启用KV缓存加速生成
)
# 解码并打印结果
response = tokenizer.batch_decode(outputs)
print(response[0]) # 输出生成内容
关键参数解析
| 参数/方法 | 作用 | 技术细节 |
|---|---|---|
| for_inference() | 切换模型至推理模式,关闭Dropout等训练专用层 | 减少计算图复杂度,提升推理速度 |
| max_new_tokens=1200 | 限制生成文本长度,防止显存溢出 | 根据T4显存容量调整(14.7GB) |
| use_cache=True | 启用键值缓存(KV Cache),避免重复计算历史token的注意力 | 提升生成速度约30% |
上面的打印效果如下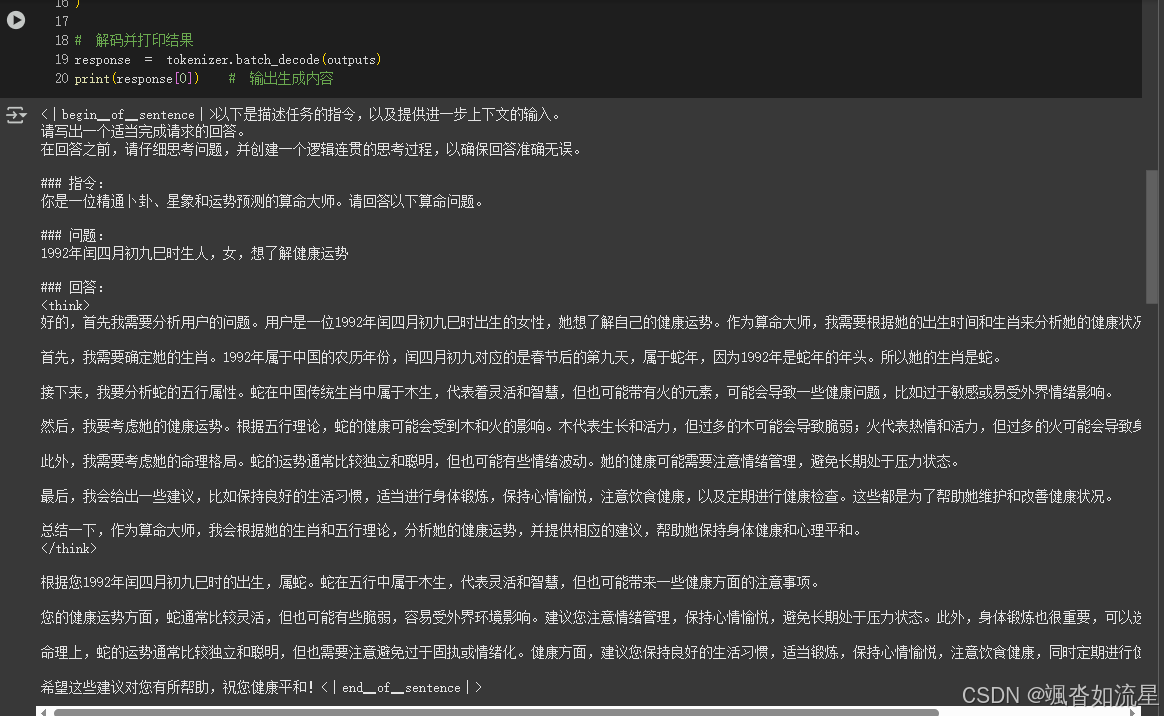
4.加载数据集
下面我们准备加载我们准备好的数据集,
train_prompt_style = """以下是描述任务的指令,以及提供进一步上下文的输入。
请写出一个适当完成请求的回答。
在回答之前,请仔细思考问题,并创建一个逻辑连贯的思考过程,以确保回答准确无误。
### 指令:
你是一位精通八字算命、紫微斗数、风水、易经卦象、塔罗牌占卜、星象、面相手相和运势预测等方面的算命大师。
请回答以下算命问题。
### 问题:
### 回答:
<思考>
{}
</思考>
{}
"""
关键设计解析
| 组件 | 作用 | 微调价值 |
|---|---|---|
| 多任务提示 | 明确整合命理学多领域知识(八字、紫微斗数等) | 提升模型跨领域推理能力 |
| 链式思考(CoT) | 强制模型生成中间推理步骤(<思考>标签内) | 增强答案可解释性,便于人工校验 |
| 动态占位符 | 外层的 {} 用于插入问题,内层的 {} 留给模型生成思考过程 | 结构化训练数据格式对齐 |
# 定义文本结束标记(用于截断生成结果)
EOS_TOKEN = tokenizer.eos_token
# 从tokenizer中获取模型预定义的结束符
# 加载训练数据集
from datasets import load_dataset
dataset = load_dataset(
"Conard/fortune-telling", # 数据集名称(HuggingFace Hub)
split="train[0:200]", # 取训练集前200条(调试阶段减少数据量)
trust_remote_code=True, # 信任远程代码执行(自定义数据加载脚本)
)
# 查看数据结构
print(dataset.column_names) # 输出:['Question', 'Response', 'Complex_CoT']
关键参数解析
| 参数/方法 | 作用 | 最佳实践 |
|---|---|---|
| split=“train[0:200]” | 限制数据量以加速调试(生产环境应使用完整数据集) | 小样本学习时可保留5%验证集 |
| trust_remote_code | 允许执行数据集作者提供的加载脚本(需安全审核) | 建议仅加载已验证来源的数据集 |
| Complex_CoT | 数据集中包含复杂推理链(Chain-of-Thought)字段 | 用于训练模型的逻辑推理能力 |
# 定义数据格式化函数(将原始数据转换为模型训练所需的提示词格式)
def formatting_prompts_func(examples):
# 提取数据集中的三个关键字段
inputs = examples["Question"] # 用户问题
cots = examples["Complex_CoT"] # 复杂推理链(Chain-of-Thought)
outputs = examples["Response"] # 最终回答
texts = [] # 存储格式化后的文本
# 遍历每条数据并进行模板填充
for input, cot, output in zip(inputs, cots, outputs):
# 使用训练模板格式化数据,并添加结束标记
text = train_prompt_style.format(input, cot, output) + EOS_TOKEN
texts.append(text)
return {"text": texts} # 返回格式化后的文本列表
# 应用格式化函数到整个数据集(批量处理)
dataset = dataset.map(formatting_prompts_func, batched=True)
# 查看第一条格式化后的数据样例
print(dataset["text"][0])
结构化参数说明
| 占位符 | 预期内容 | 数据源字段 |
|---|---|---|
| {question} | 用户原始问题 | examples[“Question”] |
| {cot} | 推理链(Chain-of-Thought) | examples[“Complex_CoT”] |
| {answer} | 最终回答 | examples[“Response”] |
关键设计解析
| 组件 | 作用 | 技术细节 |
|---|---|---|
| 字段映射 | 将原始数据字段(Question/CoT/Response)与模板占位符对齐 | 确保数据与提示词结构一致 |
| 批量处理 | 使用 dataset.map(…, batched=True) 提升处理效率 | 比逐条处理快3-5倍 |
| 结束标记 | 添加 EOS_TOKEN 明确文本边界,防止模型无限生成 | 常用标记:`< |
5.执行微调
# 使用Unsloth库进行高效微调
from unsloth import FastLanguageModel
# 准备模型用于训练
FastLanguageModel.for_training(model)
# 应用LoRA适配器
model = FastLanguageModel.get_peft_model(
model, # 预训练基础模型
r=16, # LoRA秩(决定可训练参数量)
target_modules = [ # 指定适配的注意力层模块
"q_proj", "k_proj",
"v_proj", "o_proj",
"gate_proj",
"up_proj",
"down_proj"
],
lora_alpha = 16, # LoRA缩放因子(影响参数更新幅度)
lora_dropout = 0, # 正则化丢弃率(0表示不丢弃)
bias = "none", # 偏置项处理方式
use_gradient_checkpointing = "unsloth", # 使用显存优化技术
random_state = 3407, # 随机种子(确保可复现性)
use_rslora = False, # 是否使用Rank-Stabilized LoRA
loftq_config = None, # LoftQ量化配置(未启用)
)
关键参数解析
| 参数 | 作用 | 推荐值 |
|---|---|---|
| r=16 | 控制LoRA秩,决定新增可训练参数的数量(秩越大模型容量越高) | 8-64(根据任务复杂度调整) |
| target_modules | 指定需要微调的注意力层模块(覆盖Q/K/V/O及FFN层) | 保持默认覆盖全注意力层 |
| lora_alpha=16 | 缩放因子,影响LoRA参数更新的幅度(通常与r保持比例关系) | 建议设置为r的1-2倍 |
| use_gradient_checkpointing | 通过重计算梯度节省显存(可支持更大batch size) | 显存不足时必开 |
from trl import SFTTrainer # 监督式微调工具
from transformers import TrainingArguments
from unsloth import is_bfloat16_supported # 检查bfloat16支持
# 初始化训练器
trainer = SFTTrainer(
model=model, # 待微调模型
tokenizer=tokenizer, # 分词器
train_dataset=dataset, # 训练数据集
dataset_text_field="text", # 数据集中文本字段名
max_seq_length=4096, # 最大序列长度(根据模型调整)
dataset_num_proc=2, # 数据预处理并行进程数
packing=False, # 禁用动态打包(保证数据完整性)
args=TrainingArguments(
per_device_train_batch_size=2, # 单GPU批大小
gradient_accumulation_steps=4, # 梯度累积步数(等效batch_size=8)
warmup_steps=5, # 学习率预热步数
max_steps=75, # 最大训练步数
learning_rate=2e-4, # 初始学习率
fp16=not is_bfloat16_supported(), # 自动选择混合精度模式
bf16=is_bfloat16_supported(),
logging_steps=1, # 每步记录日志
optim="adamw_8bit", # 8bit优化器(节省显存)
weight_decay=0.01, # L2正则化系数
lr_scheduler_type="linear", # 学习率衰减策略
seed=3407, # 随机种子
output_dir="outputs", # 模型输出目录
report_to="none", # 禁用第三方监控
)
)
关键参数解析
| 参数 | 作用 | 推荐值 |
|---|---|---|
| gradient_accumulation_steps | 通过累积梯度模拟更大batch size(显存不足时的关键技巧) | 通常设置为2-8 |
| warmup_steps | 学习率从0线性增加到设定值,避免初期训练不稳定 | 总步数的5%-10% |
| o | ptim=“adamw_8bit” | 使用8bit量化优化器,减少显存占用(可节省约30%显存) |
| lr_scheduler_type=“linear” | 学习率线性衰减到0,平衡训练稳定性和收敛速度 | 简单任务可用cosine衰减 |
trainer_stats = trainer.train()
6.微调后测试
# 切换到推理模式(关闭Dropout等训练专用层)
FastLanguageModel.for_inference(model)
# 构建输入提示词(应用与训练时一致的模板)
question = "1992年闰四月初九巳时生人,女,想了解健康运势"
prompt = prompt_style.format(question, "") # 第二个参数留空用于生成填充
# 文本转Token ID(自动添加特殊标记)
inputs = tokenizer(
[prompt],
return_tensors="pt",
padding=True,
truncation=True,
).to("cuda") # 加载到GPU
# 生成回答
outputs = model.generate(
input_ids=inputs.input_ids, # 输入序列
attention_mask=inputs.attention_mask,# 注意力掩码
max_new_tokens=1200, # 最大生成长度
pad_token_id=tokenizer.eos_token_id, # 填充标记(防止生成中断)
temperature=0.7, # 控制随机性(0-1)
top_p=0.9, # 核采样概率阈值
use_cache=True, # 使用KV缓存加速
)
# 解码输出
response = tokenizer.batch_decode(
outputs[:, inputs.input_ids.shape[1]:], # 仅解码生成部分
skip_special_tokens=True, # 过滤特殊标记
)[0]
print(response)
关键参数解析
| 参数 | 作用 | 推荐值 |
|---|---|---|
| max_new_tokens=1200 | 控制生成文本的最大长度(需小于模型上下文窗口) | 根据任务需求调整 |
| temperature=0.7 | 值越低生成越确定,值越高越随机(0.3-0.9) | 0.7适合开放式生成 |
| top_p=0.9 | 仅从累计概率前90%的候选词中采样(平衡多样性与合理性) | 0.8-0.95 |
7.将微调后的模型保存为 GGUF 格式
# 模型切换到推理模式(关闭Dropout等训练专用层)
FastLanguageModel.for_inference(model)
# 提示词格式化(存在占位符缺失风险)
inputs = tokenizer([prompt_style.format(question, "")],
return_tensors="pt").to("cuda") # 第二个参数为空字符串
# 文本生成配置
outputs = model.generate(
input_ids=inputs.input_ids,
attention_mask=inputs.attention_mask,
max_new_tokens=1200, # 最大生成长度
use_cache=True, # 启用KV缓存加速
)
8.将微调后的模型上传到 HuggingFace
先去 HuggingFace 上面创建一个自己的token,一定确保有写权限
from huggingface_hub import create_repo
MY_HUGGINGFACE_TOKEN = "TODO这里输入你的token"
MY_HUGGINGFACE_REPO = "TODO这里输入你的用户名/fortune_teller"
# 创建模型仓库(需确保token有写入权限)
create_repo(MY_HUGGINGFACE_REPO,
token=MY_HUGGINGFACE_TOKEN,
exist_ok=True) # 允许仓库已存在
# 上传模型和分词器(需验证方法名正确性)
model.push_to_hub_gguf(MY_HUGGINGFACE_REPO,
tokenizer,
token=MY_HUGGINGFACE_TOKEN)

使用 Ollama 运行 HuggingFace 模型
ollama run hf.co/{username}/{repository}


欢迎加入 MCP 技术社区!与志同道合者携手前行,一同解锁 MCP 技术的无限可能!
更多推荐

 32
32 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)