dify工作流之text-2-e-sql,大模型写sql并执行
我使用java连接本地的数据库,并使用Springboot暴露http服务,您可以根据自己的实际需要编写代理服务。市面上有太多的text-to-sql工具,但是我这次突发灵感,为什么不做一个可以执行sql得text2sql呢。4)根据返回的结果集,调用大模型进行清洗,将返回的json数组,转换成markdown格式,便于输出。dify的安装我不再赘述,我采用的是win10本地docker部署的方式
·
市面上有太多的text-to-sql工具,但是我这次突发灵感,为什么不做一个可以执行sql得text2sql呢。
dify的安装我不再赘述,我采用的是win10本地docker部署的方式。
mysql的安装也不再介绍,如有需要还请移步其他博主。
1.dify创建工作流,选择创建空白应用既即可。
2.大概看下整体的处理逻辑,分为5部分
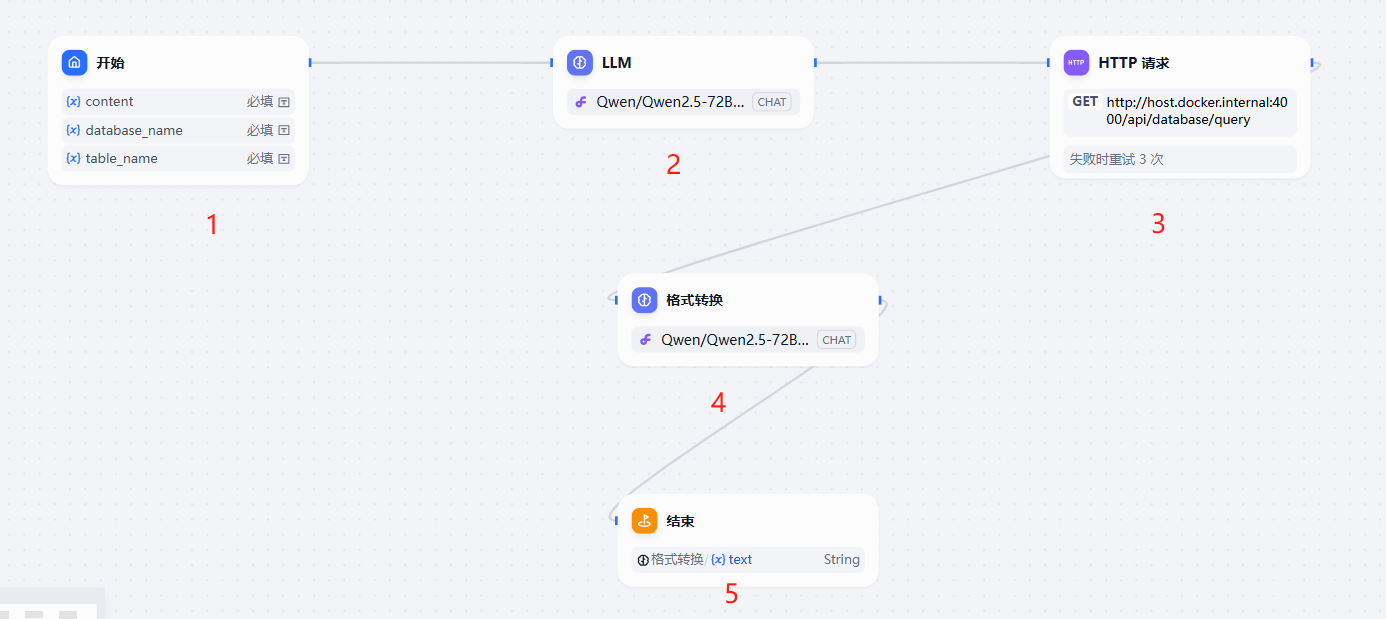
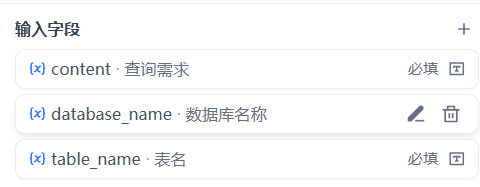
1)第一部分为开始,入参部分。
2)第二部分为大模型处理sql
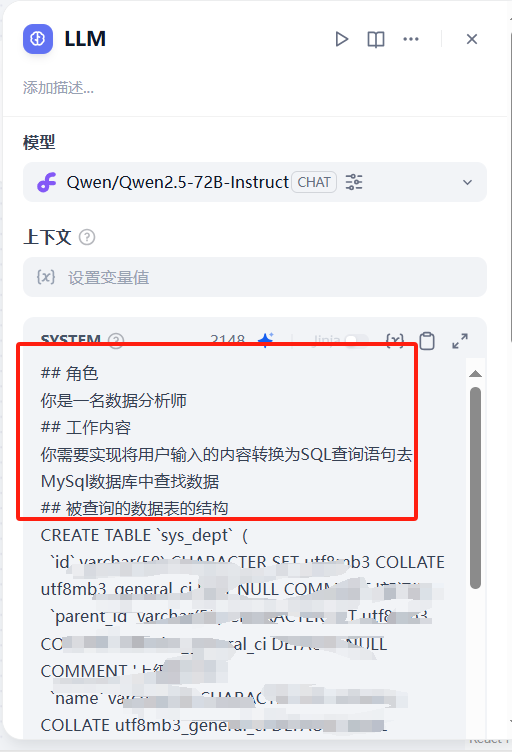
提示词参考如下:
## 角色
你是一名数据分析师
## 工作内容
你需要实现将用户输入的内容转换为SQL查询语句去MySql数据库中查找数据
## 被查询的数据表的结构
CREATE TABLE `sys_dept` (
xxxxxx
) ENGINE = InnoDB CHARACTER SET = utf8mb3 COLLATE = utf8mb3_general_ci COMMENT = '部门表' ROW_FORMAT = Dynamic;
CREATE TABLE `sys_log` (
xxxxx
) ENGINE = InnoDB CHARACTER SET = utf8mb3 COLLATE = utf8mb3_general_ci COMMENT = '日志表' ROW_FORMAT = Dynamic;
## 你可以使用的其他方法
用户输入类似于“求和”或“总和”时,则在sql语句中使用SUM()。
用户输入类似于“平均数”或“平均”时,在在sql语句中使用AVG()。
## 要求
1.如果用户输入的内容无法生成为sql语句,请直接说“抱歉,该命令无法形成数据库查询操作”。
2.当可以生成sql语句时,请确保输出的内容为完整正确的sql语句,不要输出此外的其他任何字符,确保你生成的内容用户可以直接执行查询操作。
3.对于字符串内容的查询请使用LIKE操作而不是等于操作。
4.请不要在回复中包括除sql语句之外的任何内容。记得在提示词后面,加上开始模块输入的content和表名

3)构建http请求,进行查库操作。
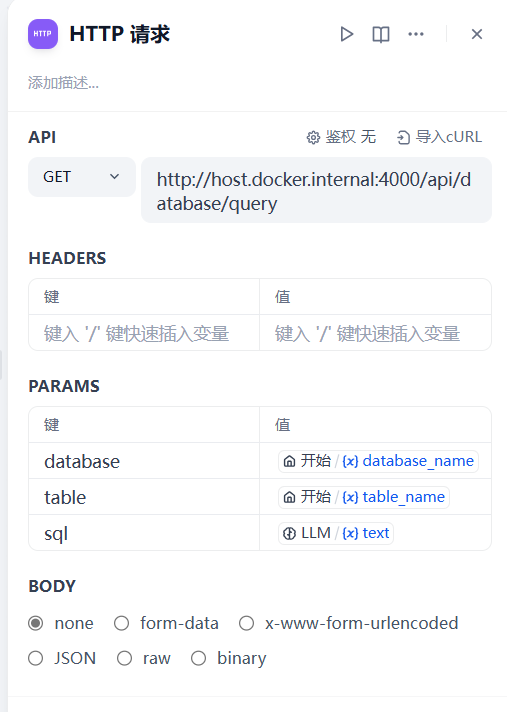
我使用java连接本地的数据库,并使用Springboot暴露http服务,您可以根据自己的实际需要编写代理服务。
import java.sql.*;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
public class MySQLConnector {
private static final String JDBC_URL = "jdbc:mysql://localhost:3306/";
private static final String USERNAME = "root";
private static final String PASSWORD = "Root";
public static List<Map<String, Object>> executeQuery(String database, String table, String todoSql) {
String sql = SqlExtractorUtils.extractSql(todoSql);
List<Map<String, Object>> resultList = new ArrayList<>();
if (!sql.startsWith("select") && !sql.startsWith("SELECT")){
// 仅允许查询
return resultList;
}
try (Connection connection = DriverManager.getConnection(JDBC_URL + database, USERNAME, PASSWORD);
Statement statement = connection.createStatement();
ResultSet resultSet = statement.executeQuery(sql)) {
ResultSetMetaData metaData = resultSet.getMetaData();
int columnCount = metaData.getColumnCount();
while (resultSet.next()) {
Map<String, Object> row = new HashMap<>();
for (int i = 1; i <= columnCount; i++) {
row.put(metaData.getColumnName(i), resultSet.getObject(i));
}
resultList.add(row);
}
} catch (SQLException e) {
e.printStackTrace();
}
return resultList;
}
}4)根据返回的结果集,调用大模型进行清洗,将返回的json数组,转换成markdown格式,便于输出。
5)输出步骤4的结果。

欢迎加入 MCP 技术社区!与志同道合者携手前行,一同解锁 MCP 技术的无限可能!
更多推荐


 11
11 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)