大模型(qwen2.5) RAG实现龙族小说的知识库问答(这是一个记录贴)
同样,我们先把这个类所有的代码贴出来方便复制@property@propertydef _call(self,) -> str:messages,@property这里就不详细解释了,我们只解释每个函数的大致作用这段代码定义了一个名为Qwen2_5_GLM的类,该类继承自langchain.llms.base.LLM和abc.ABC。这个类实现了与一个大型语言模型(LLM)交互的功能,具体是阿里云
一.环境搭建
RAG简介
RAG(Retrieval-Augmented Generation)是一种结合了信息检索(Retrieval)和生成模型(Generation)的框架,用于增强自然语言处理任务中的文本生成能力。它通过从大型语料库中检索相关信息并将其提供给生成模型,使得生成的文本更加准确、上下文相关且信息丰富。
我们来粗略地解释一下RAG的过程,如下图(这是百度上找的一幅相关图片)
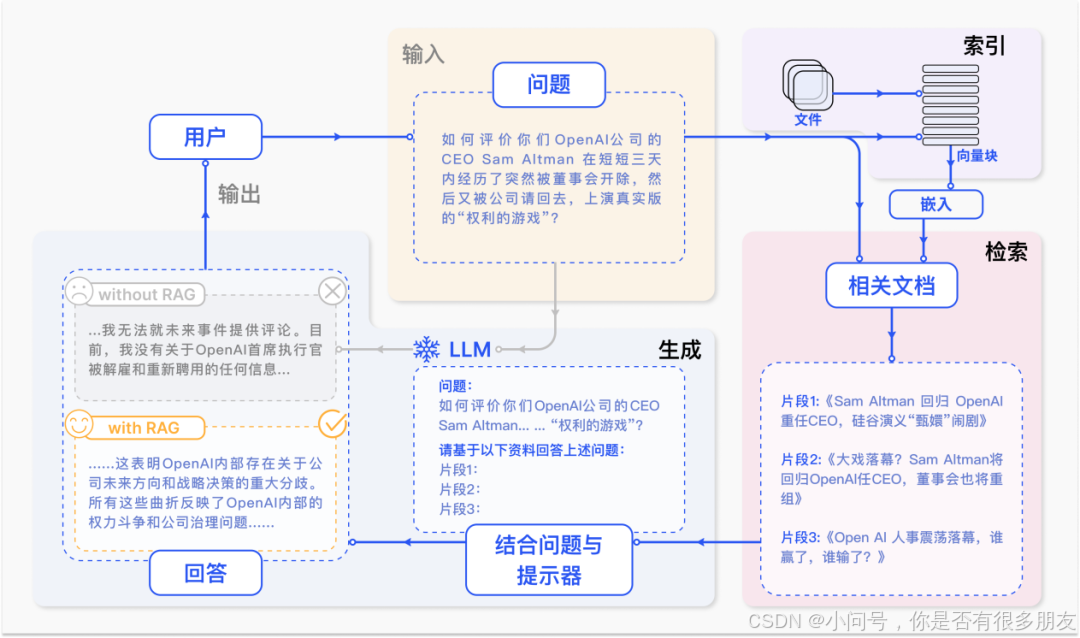
下方是RAG的详细介绍
一文彻底搞懂大模型 - RAG(检索、增强、生成)_rag大模型-CSDN博客
接下来开始搭建小说问答知识库了
注册一个funHPC的云端算力

使用code-server或者本地vscode链接ssh都可以
二.下载模型
1.Qwen2.5-14B-Instruct-GPTQ-Int4下载
LLM模型使用的是qwen2.5-14b的int4量化版本
这里是魔搭社区的官方链接:https://modelscope.cn/models/Qwen/Qwen2.5-14B-Instruct-GPTQ-Int4
下面是下载的步骤
(1)安装modelscope库
打开云环境或者本地环境的终端,运行下方代码
pip install modelscope(2)在运行完成后新建py文件,写入下载模型的代码
#模型下载
from modelscope import snapshot_download
model_dir = snapshot_download('Qwen/Qwen2.5-14B-Instruct-GPTQ-Int4')如果要指定下载路径,在snapshot_download方法内添加
cache_dir=<指定的下载路径>等待模型下载完成
2.gte_Qwen2-1.5B-instruct
向量模型使用的是gte_Qwen2-1.5B-instruct,该模型的魔搭社区官方链接如下:
https://modelscope.cn/models/iic/gte_Qwen2-1.5B-instruct
同样使用modelscope下载,下载代码:
#模型下载
from modelscope import snapshot_download
model_dir = snapshot_download('iic/gte_Qwen2-1.5B-instruct')三. 加载txt文档并存入向量数据库
1.准备工作
(1)下载langchain库
LangChain库是一个用于构建语言模型驱动的应用程序的框架。具体的介绍可参考官网和下方文章
官网:LangChain 框架介绍 | 🦜️🔗 Langchain
博客:一文搞懂LangChain是什么(非常详细),零基础入门到精通,看这一篇就够了-CSDN博客
(2)下载向量数据库faiss
在命令行运行以下命令
pip install faiss-gpu(3)下载龙族2的txt文档
下载链接我放在下方了
龙族全套 共七册(龙族Ⅰ-龙族Ⅳ+龙族前传)江南.pdf - my-share 的分享
2.存入数据库
from langchain.text_splitter import CharacterTextSplitter
from langchain_community.document_loaders import TextLoader
from langchain.embeddings.huggingface import HuggingFaceEmbeddings
from langchain.vectorstores import FAISS
class EmbText():
def loader_text(self):
embeddings_model_dir = '/root/.cache/modelscope/hub/iic/gte_Qwen2-1.5B-instruct'
text_loader = TextLoader('龙族2悼亡者之瞳.txt', encoding='GBK')
data = text_loader.load()
splitter = CharacterTextSplitter(chunk_size=512,chunk_overlap=24)
splitter_data = splitter.split_documents(data)
print(splitter_data)
embedding_model = HuggingFaceEmbeddings(model_name=embeddings_model_dir)
db = FAISS.from_documents(splitter_data, embedding_model)
db.save_local('faiss/my_emd_data')
return splitter_data
if __name__ == '__main__':
emb = EmbText()
emb.loader_text()
详细解释
最上方的是导入模块
CharacterTextSplitter:文本分割器,用于将大块的文本分割成更小的部分或片段
TextLoader:TXT文档加载器
HuggingFaceEmbeddings:加载 Hugging Face 提供的预训练语言模型以生成文本嵌入
FAISS:FAISS 类封装了 FAISS 库的功能,允许你在大量的高维向量中进行快速的近似最近邻搜索。在 langchain 中使用 FAISS 类,通常是为了建立一个向量数据库,可以存储由例如 HuggingFaceEmbeddings 生成的嵌入,并且支持对这些嵌入进行快速查询和相似性搜索。
loader_text函数:
这个函数loader_text定义了一个方法,用于加载PDF文档、分割文本并创建一个向量数据库。下面将详细解释每一行代码的作用:
embeddings_model_dir = '/root/.cache/modelscope/hub/iic/gte_Qwen2-1.5B-instruct' 这行代码设置了模型目录的路径(记得将绿色部分的路径改成你自己的向量模型的路径),该目录是嵌入模型的路径,用于生成文本的嵌入(embeddings)。
pdf_loader = PDFMinerLoader('龙族全套.pdf')创建了一个PDFMinerLoader对象,它会使用pdfminer库来加载和解析PDF文件(这里记得。这里的参数指定了要加载的PDF文件名。
data = pdf_loader.load()调用load方法从PDF文件中提取文本数据,并将其存储在变量data中。
splitter = CharacterTextSplitter(chunk_size=256, chunk_overlap=10)初始化了一个CharacterTextSplitter对象,用于将文本数据分割成更小的块。这里设置每个块大小为256个字符,相邻块之间有10个字符的重叠。
splitter_data = splitter.split_documents(data)使用split_documents方法对data进行分割,产生一系列较小的文本块。
embedding_model = HuggingFaceEmbeddings(model_name=embeddings_model_dir)创建了一个HuggingFaceEmbeddings对象,它会加载指定目录下的预训练模型,并能将文本转换为数值型的嵌入向量。
db = FAISS.from_documents(splitter_data, embedding_model)使用FAISS库创建了一个向量数据库。FAISS是一个高效的相似性搜索库,这里它将基于文本块的嵌入向量建立索引。
db.save_local('faiss/my_emd_data')将创建的向量数据库保存到本地磁盘上的指定路径faiss/my_emd_data。
运行结果如下
同时我们打开向量数据库的路径,我的就是代码所示的路径,可以看见在faiss/my_emd_data目录下多了两个文件

四.langchain自定义本地模型
同样,我们先把这个类所有的代码贴出来方便复制
from transformers import AutoModelForCausalLM, AutoTokenizer
from abc import ABC
from langchain.llms.base import LLM
from typing import Any, List, Mapping, Optional
from langchain.callbacks.manager import CallbackManagerForLLMRun
model_name = "/root/.cache/modelscope/hub/Qwen/Qwen2.5-14B-Instruct-GPTQ-Int4"
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype="auto",
device_map="auto"
)
tokenizer = AutoTokenizer.from_pretrained(model_name)
class Qwen2_5_GLM(LLM, ABC):
max_token: int = 10000
temperature: float = 0.01
top_p:float = 0.9
history_len: int = 3
def __init__(self):
super().__init__()
@property
def _llm_type(self) -> str:
return "Qwen"
@property
def _history_len(self) -> int:
return self.history_len
def set_history_len(self, history_len: int = 10) -> None:
self.history_len = history_len
def _call(
self,
prompt: str,
stop: Optional[List[str]] = None,
run_manager: Optional[CallbackManagerForLLMRun] = None,
**kwargs: Any,
) -> str:
messages = [
{"role": "system", "content": "You are Qwen, created by Alibaba Cloud. You are a helpful assistant."},
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
generated_ids = model.generate(
**model_inputs,
max_new_tokens=2048
)
generated_ids = [
output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)
]
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
return response
@property
def _identifying_params(self) -> Mapping[str, Any]:
"""Get the identifying parameters."""
return {"max_token": self.max_token,
"temperature": self.temperature,
"top_p": self.top_p,
"history_len": self.history_len}
这里就不详细解释了,我们只解释每个函数的大致作用
这段代码定义了一个名为Qwen2_5_GLM的类,该类继承自langchain.llms.base.LLM和abc.ABC。这个类实现了与一个大型语言模型(LLM)交互的功能,具体是阿里云开发的Qwen模型的一个特定版本。下面是对每个函数的作用解释:
类属性
max_token, temperature, top_p, history_len
这些都是类的属性,用来设置生成文本时的一些参数:
max_token: 控制最大输出token数量。
temperature: 影响输出的随机性;值越低,输出越确定。
top_p: 核采样参数,控制词汇表中累积概率分布的最大值。
history_len: 控制对话历史记录的长度。
构造函数
__init__(self)
类的构造函数,调用父类的构造函数初始化实例。
属性方法
_llm_type(self) -> str
返回表示LLM类型的字符串,在这里是"Qwen"。
_history_len(self) -> int
返回对话历史记录的长度。
set_history_len(self, history_len: int = 10) -> None
设置对话历史记录的长度,默认为10。
主要方法
_call(self, prompt: str, stop: Optional[List[str]] = None, run_manager: Optional[CallbackManagerForLLMRun] = None, **kwargs: Any) -> str
这是实际与LLM进行交互的方法,它接收一个提示(prompt)作为输入,并返回由LLM生成的响应文本。
它首先构建了消息列表,包括系统角色说明和用户提供的提示。
然后使用apply_chat_template方法准备这些消息以供模型处理。
接着将文本转换为模型可以理解的张量格式。
使用模型的generate方法基于输入生成新的文本。
最后,将生成的ID解码回人类可读的文本,并返回这个文本。
辅助方法
_identifying_params(self) -> Mapping[str, Any]
返回一个映射,包含用于标识当前LLM配置的关键参数。这有助于在不同地方识别或比较不同的LLM配置。
五.主函数
同样,我们先贴全部代码
from langchain.prompts import PromptTemplate
from langchain.embeddings import HuggingFaceEmbeddings
from langchain.vectorstores import FAISS
from Qwen2_5_GLM import Qwen2_5_GLM
class Main_main():
def define_prompt(self,que):
embeddings_model_dir = '/root/.cache/modelscope/hub/iic/gte_Qwen2-1.5B-instruct'
embedding_model = HuggingFaceEmbeddings(model_name=embeddings_model_dir)
db = FAISS.load_local('faiss/my_emd_data',embedding_model,allow_dangerous_deserialization=True)
docs = db.similarity_search(que,k=1000)
docs_m=[]
for doc in docs:
docs_m.append(doc.page_content)
PROMPT_TEMPLATE="基于以下已知信息,思考回答用户问题,不允许在答案中添加编造成分\n已知内容\n{content}\n用户问题\n{que}"
prompt = PromptTemplate(input_variables=['content','que'],template=PROMPT_TEMPLATE)
my_prompt = prompt.format(content=docs_m,que=que)
return my_prompt
def qa(self):
llm = Qwen2_5_GLM()
que = '路明非为什么要和楚子航谈论星座'
prompt = Main_main().define_prompt(que)
print(prompt)
result = llm(prompt)
return result
if __name__ == '__main__':
re_=Main_main().qa()
print(re_)
下面是解释:
define_prompt(self, que)
这个方法的作用是构建一个特定的提示(prompt),用于引导语言模型生成回答。它执行以下步骤:
加载嵌入模型:使用 HuggingFace 的嵌入模型来转换文本为向量表示。
加载 FAISS 数据库:从本地加载一个预先构建好的 FAISS 向量存储,该数据库包含大量文档的向量表示。
搜索相似文档:基于输入的问题 que,在 FAISS 数据库中搜索最相关的文档。
整理文档内容:将找到的相关文档的内容提取出来,并整理成一个字符串列表 docs_m。
创建提示模板:定义了一个字符串模板 PROMPT_TEMPLATE,该模板指定了如何组合已知信息和用户问题。
格式化提示:使用 PromptTemplate 类根据模板和变量值(即文档内容和问题)生成最终的提示文本 my_prompt。
qa(self)
这个方法的作用是获取对给定问题的回答。它执行以下操作:
实例化 LLM:创建了 Qwen2_5_GLM 类的一个实例,这应该是用于生成回答的大规模语言模型。
定义问题:设定了一个具体的问题 que。
构造提示:调用 define_prompt 方法来构造与问题对应的提示。
打印提示:输出构造好的提示到控制台,以便可以查看或调试。
获取回答:将提示传递给语言模型 llm,并获取其生成的回答 result。
返回结果:最后,将语言模型生成的回答作为方法的返回值。
六.最终运行结果
在经过上述的配置后,我们运行最终的mian文件,得到了下面的结果

当然为了更准确地生成回答,我们最好能在存入数据库前对文本进行数据清洗,这可能会在后续的记录贴中记录

欢迎加入 MCP 技术社区!与志同道合者携手前行,一同解锁 MCP 技术的无限可能!
更多推荐

 30
30 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)