【论文解读】Segment Anything 分割一切大模型(附论文地址)
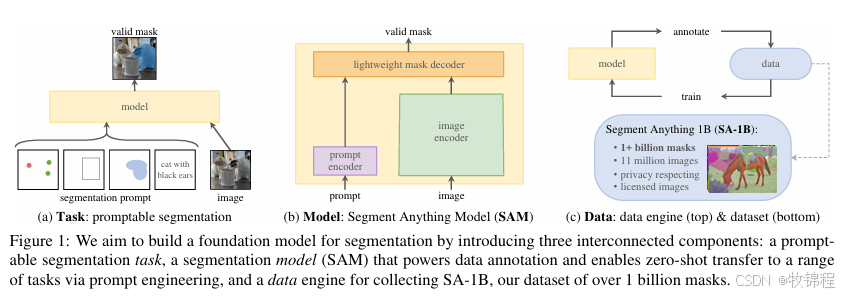
这是一项新的图像分割任务、模型和数据集。我们构建了迄今为止最大的分割数据集,包含超过10亿个掩码,覆盖了1100万张图像。该模型被设计和训练为可提示的(promptable),因此它能够通过提示工程零样本迁移到新的图像分布和任务。我们在众多任务上评估了它的能力,并发现它的零样本性能令人印象深刻——通常与或甚至优于以前的全监督结果。在自然语言处理(NLP)中,提示(prompt)的概念被用来指导语言
论文地址:https://ai.meta.com/research/publications/segment-anything/
摘要
这是一项新的图像分割任务、模型和数据集。我们构建了迄今为止最大的分割数据集,包含超过10亿个掩码,覆盖了1100万张图像。该模型被设计和训练为可提示的(promptable),因此它能够通过提示工程零样本迁移到新的图像分布和任务。
我们在众多任务上评估了它的能力,并发现它的零样本性能令人印象深刻——通常与或甚至优于以前的全监督结果。
引言
大型语言模型对NLP的影响
预训练于网络规模数据集的大型语言模型正在彻底改变自然语言处理(NLP),展现出强大的零样本和少样本泛化能力。
这些“基础模型”能够泛化到训练期间未见过的任务和数据分布。
通过提示工程,即使用文本来提示语言模型为手头的任务生成有效的文本内容,这些模型的性能与微调模型相比出奇地好。
图像分割的基础模型目标
本项工作的目标是构建一个图像分割的基础模型,即开发一个可提示的模型,并在广泛的数据集上进行预训练,使用一个能够实现强大泛化的任务。
该模型旨在通过提示工程在新数据分布上解决一系列下游分割问题。
计划的成功取决于三个关键组成部分:任务、模型和数据。
任务、模型和数据的相互关系
任务、模型和数据的选择是相互关联的,需要一个综合性的解决方案。
首先定义了一个可提示的分割任务,该任务足够通用,能够提供强大的预训练目标,并能够支持广泛的下游应用。
这个任务需要一个支持灵活提示的模型,并且能够实时输出分割掩码,以支持交互式使用。
为了训练模型,需要一个多样化、大规模的数据源。由于没有现成的网络规模分割数据源,因此构建了一个“数据引擎”,即在数据收集和模型改进之间进行迭代。
Segment Anything 任务
任务定义
在自然语言处理(NLP)中,提示(prompt)的概念被用来指导语言模型生成特定任务的有效文本响应。我们将这一概念转化为图像分割领域,提出了“可提示的分割任务”,目标是给定任何分割提示(prompt),返回一个有效的分割掩码。这里的“提示”可以是一组前景/背景点、一个粗略的框或掩码、自由形式的文本,或任何指示图像中要分割的内容的信息。有效输出掩码的要求意味着即使提示是模糊的并且可能指向多个对象(例如,一个点可能同时指代衬衫或穿衬衫的人),输出应该是至少一个对象的合理掩码。

预训练
预训练算法模拟了一系列提示(例如点、框、掩码)对于每个训练样本,并比较模型的掩码预测与真实情况。这种方法源自交互式分割,但不同于交互式分割的目标是在足够用户输入后预测一个有效掩码,我们的目标是即使提示是模糊的,也能始终预测一个有效掩码。这确保了预训练模型在涉及模糊性的用例中有效,包括我们数据引擎所需的自动注释。
零样本迁移
直观上,预训练任务赋予模型在推理时对任何提示做出适当响应的能力,因此可以通过工程化提示解决下游任务。例如,如果有一个用于猫的边界框检测器,可以通过将检测器的框输出作为提示提供给模型来解决猫的实例分割问题。一般来说,可以通过提示将广泛的实际分割任务转化为可解决的问题。除了自动数据标注,我们在实验中还探索了五个不同的示例任务。
相关任务
分割是一个广泛的领域,包括交互式分割、边缘检测、超像素化、目标提议生成、前景分割、语义分割、实例分割、全景分割等。我们的目标是生产一个能够适应许多(尽管不是全部)现有和新的分割任务的通用模型,通过提示工程实现。这与以前在多任务分割系统上的工作不同。在多任务系统中,单个模型执行一组固定的任务,例如联合语义、实例和全景分割,但训练和测试任务是相同的。我们工作的一个重要区别是,训练用于可提示分割的模型可以在推理时执行一个新的、不同的任务,通过作为一个更大系统中的组件,例如执行实例分割,可提示分割模型与现有的目标检测器结合。
讨论
提示和组合是强大的工具,使单个模型能够以可扩展的方式使用,可能完成在模型设计时未知的任务。这种方法类似于其他基础模型的使用方式,例如CLIP作为DALL·E图像生成系统的文字-图像对齐组件。我们预计,通过提示工程等技术实现的可组合系统设计,将比专门针对一组固定任务训练的系统实现更广泛的应用。同时,通过组合的视角比较可提示和交互式分割也很有趣:虽然交互式分割模型是针对最终用户设计的,但训练用于可提示分割的模型也可以作为一个更大算法系统的一部分,正如我们将展示的。
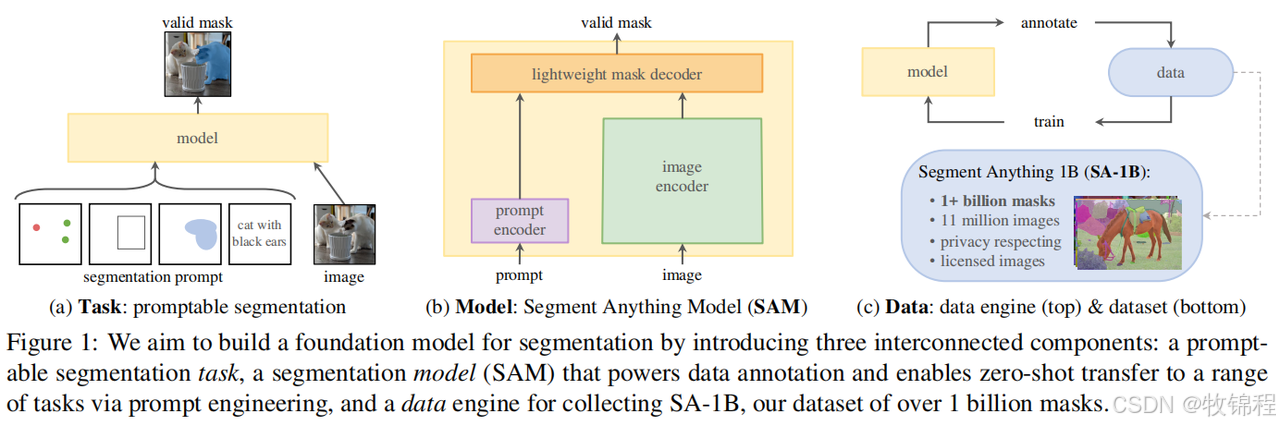
Segment Anything 模型
图像编码器 (Image Encoder)
-
使用基于 MAE (Masked Autoencoder) 预训练的 Vision Transformer (ViT),能够处理高分辨率输入。
-
图像编码器对每张图像运行一次,生成图像嵌入(image embedding),供后续提示使用。
提示编码器 (Prompt Encoder)
支持两种类型的提示:
稀疏提示:包括点、框和文本。点和框通过位置编码和学习的嵌入表示,文本使用 CLIP 的文本编码器。
密集提示:如掩码,通过卷积处理并与图像嵌入结合。
如果没有掩码提示,则使用一个学习的“无掩码”嵌入。
轻量级掩码解码器 (Mask Decoder)
将图像嵌入和提示嵌入结合,生成分割掩码。
基于 Transformer 架构,支持自注意力和交叉注意力机制,能够高效地生成掩码。
解码器运行两次,更新图像嵌入和提示嵌入,最终通过动态线性分类器生成掩码。
处理模糊性
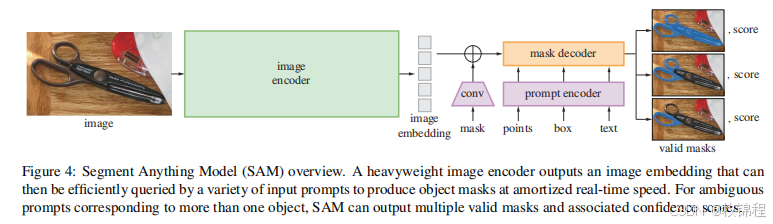
多掩码输出:SAM 能够为单个提示生成多个掩码,以处理模糊性(如一个点可能对应多个对象)。默认情况下,SAM 生成三个掩码,分别对应整体、部分和子部分。
掩码排序:模型为每个掩码预测一个置信度分数(基于 IoU),用于排序。
效率
实时处理:SAM 的设计注重效率,图像编码器只需运行一次,提示编码器和掩码解码器在浏览器中运行,处理时间约为 50ms。
轻量级解码器:解码器的计算量仅为图像编码器的 1%,确保实时交互。
损失和训练
损失函数:使用 焦点损失 (Focal Loss) 和 Dice 损失 的线性组合来监督掩码预测,IoU 预测头使用均方误差损失。
训练算法:模拟交互式分割设置,随机采样点或框作为提示,逐步优化掩码预测。每个掩码进行 11 轮迭代训练,确保模型能够处理模糊提示。
Segment Anything 数据引擎
数据引擎是 Segment Anything Model (SAM) 的核心组成部分,用于生成大规模、高质量的分割掩码数据集 SA-1B。数据引擎分为三个阶段:辅助手动阶段、半自动阶段 和 全自动阶段,通过模型与标注员的协作,逐步提高掩码的数量和质量。
数据引擎的三个阶段
辅助手动阶段
流程:专业标注员使用基于 SAM 的交互式分割工具,通过点击前景/背景点来标注掩码,并使用像素级工具(如画笔和橡皮擦)进行细化。
特点:标注员可以自由标注任何对象,不限于特定语义类别。
结果:收集了 430 万掩码,来自 12 万张图像,平均每张图像约 20 个掩码。
模型改进:随着数据量的增加,SAM 的性能逐步提升,标注时间从每掩码 34 秒减少到 14 秒。
半自动阶段
-
流程:SAM 自动生成一部分高置信度的掩码,标注员专注于标注剩余的对象,以增加掩码的多样性。
-
特点:通过自动生成掩码,标注员可以更高效地标注复杂或难以识别的对象。
-
结果:收集了 590 万掩码,来自 18 万张图像,平均每张图像约 72 个掩码(包括自动生成的掩码)。
-
模型改进:SAM 的性能进一步提升,标注时间略有增加,因为剩余对象更难标注。
全自动阶段
-
流程:SAM 完全自动生成掩码,无需标注员参与。通过 32x32 的网格点生成掩码,并使用 IoU 预测模块和稳定性过滤来确保掩码质量。
-
特点:全自动阶段依赖于 SAM 的模糊性处理能力,能够生成多个有效的掩码。
-
结果:收集了 11 亿掩码,来自 1100 万张图像,平均每张图像约 100 个掩码。
-
模型改进:SAM 在全自动阶段生成的掩码质量高,接近专业标注水平。
数据引擎的关键技术
模糊性处理
SAM 能够为单个提示生成多个掩码,以处理模糊性(如一个点可能对应多个对象)。
通过预测多个掩码并选择最合适的掩码,确保生成的结果合理。
掩码过滤
置信度过滤:根据 SAM 预测的 IoU 分数,过滤掉低置信度的掩码。
稳定性过滤:通过比较不同阈值下的掩码,确保生成的掩码稳定。
大小过滤:过滤掉覆盖图像 95% 以上的掩码,避免生成无意义的掩码。
后处理
去除小区域:去除面积小于 100 像素的掩码区域。
填充小孔洞:填充面积小于 100 像素的掩码孔洞。
数据引擎的成果
SA-1B 数据集:通过数据引擎的全自动阶段,生成了 11 亿个高质量掩码,覆盖了 1100 万张图像。
掩码质量:通过人工评估,94% 的自动生成掩码与人工修正掩码的 IoU 超过 90%,表明掩码质量接近专业标注水平。
Segment Anything 数据集 (SA-1B)

SA-1B 是一个大规模、高质量的分割数据集,包含 1100 万张图像 和 11 亿个掩码。该数据集通过 数据引擎 的全自动阶段生成,旨在为计算机视觉领域的研究提供强大的基础数据支持。
数据集特点
-
图像
-
来源:图像来自第三方摄影公司,均为高分辨率(平均 3300x4950 像素),并经过隐私保护处理(如模糊人脸和车牌)。
-
多样性:图像涵盖了广泛的场景和对象,具有高度的多样性。
-
发布版本:为便于使用,发布的图像经过下采样,最短边为 1500 像素。
-
-
掩码
-
数量:SA-1B 包含 11 亿个掩码,平均每张图像约 100 个掩码。
-
质量:99.1% 的掩码由 SAM 全自动生成,经过严格的质量控制,确保高精度和多样性。
-
评估:通过人工评估,94% 的自动生成掩码与人工修正掩码的 IoU(交并比)超过 90%,表明掩码质量接近专业标注水平。
-
数据集质量分析
-
掩码质量
-
通过随机采样 500 张图像(约 5 万个掩码),由专业标注员对自动生成的掩码进行修正。
-
结果显示,94% 的掩码对 IoU 超过 90%,97% 的掩码对 IoU 超过 75%,表明自动生成的掩码质量非常高。
-
-
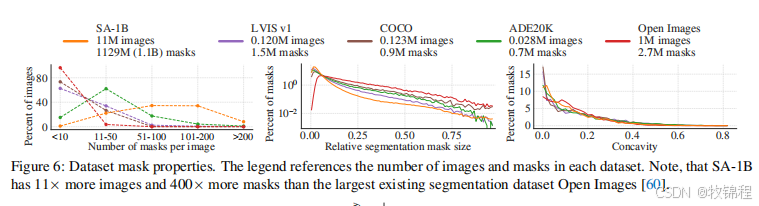
掩码属性
-
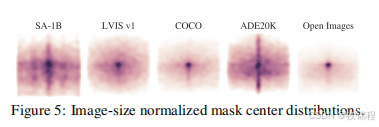
空间分布:SA-1B 的掩码中心分布比现有数据集(如 LVIS、ADE20K)更均匀,覆盖了图像的更多角落。
-
掩码大小:SA-1B 包含更多中小型掩码,反映了数据集中对象的多样性。
-
形状复杂度:SA-1B 的掩码形状复杂度与其他数据集相似,表明其掩码具有合理的形状多样性。
-
数据集的地理和收入分布
-
地理分布
-
SA-1B 的图像来自全球多个国家和地区,覆盖了地理多样性。
-
欧洲和亚洲及大洋洲的图像比例较高,而非洲和拉丁美洲的图像比例较低。
-
-
收入分布
-
SA-1B 在中高收入国家的图像比例较高,而在低收入国家的图像比例较低。
-
尽管存在一定的偏差,SA-1B 在所有地区的掩码数量都显著高于现有数据集。
-
Segment Anything 负责任AI分析
地理和收入分布

-
地理分布
-
SA-1B 数据集中的图像来自全球多个国家和地区,覆盖了地理和经济多样性。
-
通过图像描述推断地理位置,发现 SA-1B 在欧洲和亚洲及大洋洲的图像比例较高,而在非洲和低收入国家的图像比例较低。
-
尽管存在地域不平衡,SA-1B 在所有地区(包括非洲)的掩码数量都显著高于现有数据集。
-
-
收入分布
-
SA-1B 在中高收入国家的图像比例较高,而在低收入国家的图像比例较低。
-
与 COCO 和 Open Images 数据集相比,SA-1B 在地理和收入分布上更具多样性,但仍存在一定的偏差。
-
人群分割的公平性
-
性别表现
-
使用 MIAP (More Inclusive Annotations for People) 数据集评估 SAM 在不同性别表现上的分割性能。
-
结果显示,SAM 在男性和女性上的表现相似,没有显著差异。
-
-
年龄群体
-
评估 SAM 在不同年龄群体(如年轻、中年、老年)上的分割性能。
-
SAM 在老年群体上的表现略好,但置信区间较大,差异不显著。
-
-
肤色
-
使用专有数据集评估 SAM 在不同肤色(Fitzpatrick 皮肤类型 1-6)上的分割性能。
-
SAM 在不同肤色群体上的表现相似,没有显著差异。
-
服装分割的公平性
-
评估 SAM 在服装分割上的性能,重点关注不同性别和年龄群体的表现。
-
结果显示,SAM 在男性服装上的分割性能略高于女性,尤其是在单点提示下。但随着提示点数的增加,差异逐渐缩小。
-
在年龄群体上,SAM 的表现没有显著差异。
零样本迁移实验
零样本迁移是指模型在没有针对特定任务进行训练的情况下,直接应用于新任务。SAM 通过提示工程(Prompt Engineering)实现了多种分割任务的零样本迁移。
实验任务
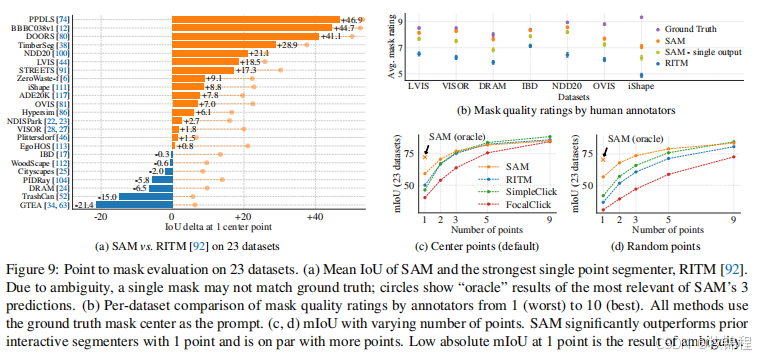
单点有效掩码评估

任务:从单个前景点生成有效的分割掩码。
评估方法:使用 mIoU(平均交并比) 和人工评估(评分 1-10)来衡量掩码质量。
结果:SAM 在 23 个数据集上表现优异,尤其是在单点提示下,生成的掩码质量高于基线模型(如 RITM)。
边缘检测

任务:在 BSDS500 数据集上进行边缘检测。
方法:通过 16x16 的网格点生成掩码,并使用 Sobel 滤波器和边缘 NMS 生成边缘图。
结果:尽管 SAM 未经边缘检测训练,但仍能生成合理的边缘图,召回率较高,但精度较低。
对象提议生成
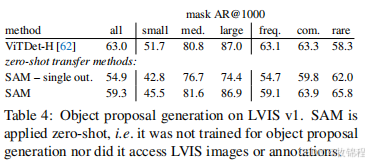
任务:在 LVIS v1 数据集上生成对象提议。
方法:通过 64x64 的网格点生成掩码,并使用 NMS 过滤冗余掩码。
结果:SAM 在中等和大型对象以及稀有对象上的表现优于基线模型(如 ViTDet)。
实例分割
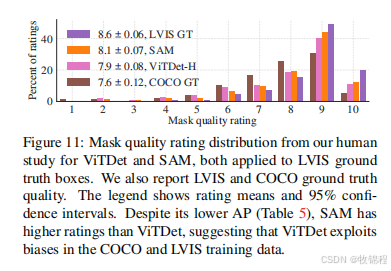
-
任务:在 COCO 和 LVIS v1 数据集上进行实例分割。
-
方法:使用 ViTDet 生成的边界框作为提示,SAM 生成分割掩码。
-
结果:SAM 生成的掩码边界更清晰,质量更高,尽管在 AP(平均精度)上略低于 ViTDet。

文本到掩码分割

-
任务:根据文本提示生成分割掩码。
-
方法:使用 CLIP 的文本编码器生成文本嵌入,作为 SAM 的提示。
-
结果:SAM 能够根据简单和复杂的文本提示生成掩码,尽管效果尚不完美,但展示了其潜力。
消融研究

数据集
使用 23 个多样化的分割数据集进行评估。
主要评估指标为 mIoU(平均交并比)。
实验内容
数据引擎阶段:分析不同数据引擎阶段(辅助手动、半自动、全自动)对模型性能的影响。
数据量:分析不同数据量(0.1M、1M、11M 图像)对模型性能的影响。
图像编码器规模:分析不同图像编码器规模(ViT-B、ViT-L、ViT-H)对模型性能的影响。
实验结果
数据引擎阶段
辅助手动阶段:使用手动标注的掩码训练模型,性能较低。
半自动阶段:结合自动生成和手动标注的掩码,性能显著提升。
全自动阶段:使用全自动生成的掩码训练模型,性能接近使用所有数据的结果。
结论:每个数据引擎阶段都带来了性能提升,全自动阶段的数据量最大,对模型性能的提升最为显著。
数据量
0.1M 图像:性能显著下降,表明数据量不足。
1M 图像:性能接近使用 11M 图像的结果,表明 1M 图像已经足够训练一个高性能模型。
11M 图像:性能最佳,但相比 1M 图像的提升有限。
结论:1M 图像是一个合理的实用设置,能够在性能和计算成本之间取得平衡。
图像编码器规模
ViT-B:性能较低,但计算成本最低。
ViT-L:性能显著提升,接近 ViT-H。
ViT-H:性能最佳,但相比 ViT-L 的提升有限。
结论:ViT-L 是一个合理的选择,能够在性能和计算成本之间取得平衡。
结论
-
该项目提出了一个新的任务(promptable segmentation)、模型(SAM)和数据集(SA-1B),旨在推动图像分割领域进入基础模型时代。
-
SAM模型和SA-1B数据集的发布,为计算机视觉的基础模型研究提供了新的资源。
-
SAM在多种任务上展现了令人印象深刻的零样本性能,常常与或甚至超越了以前的全监督结果。
-
尽管SAM在某些方面不是完美的,比如可能会错过一些细节结构,有时会错误地产生一些小的不连续组件,但它在泛化性和实时性方面表现出色。
-
SAM的设计使其能够通过提示工程零样本迁移到新的图像分布和任务,这在多个下游任务中得到了验证。
-
SA-1B数据集的规模和多样性为训练鲁棒性和泛化能力强的模型提供了可能,同时也为研究社区提供了宝贵的资源。
-
尽管SAM在许多方面表现出色,但仍有改进的空间,特别是在处理文本提示和提高边界清晰度方面。
硬性的标准其实限制不了无限可能的我们,所以啊!少年们加油吧!

欢迎加入 MCP 技术社区!与志同道合者携手前行,一同解锁 MCP 技术的无限可能!
更多推荐


 24
24 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)