大模型中Self-Attention与Flash-Attention原理概述
它不是预先计算完整的注意力矩阵,而是在计算小块输出时,根据需要动态地计算注意力分数和权重。例如,在计算一个小块Qi与其他小块Ki和Vj的交互时,仅计算当前小块所需的注意力分数和权重,并且在计算完成后,不存储完整的注意力矩阵,而是直接更新小块输出。例如,重复利用已经计算过的中间结果,避免重复计算相同的部分。在传统的自注意力计算中,需要先计算所有的注意力分数,然后进行 Softmax 归一化,最后计算
目录
1.1查询(Query)、键(Key)和值(Value)的生成
1.2 注意力分数(Attention Scores)的计算
1.Self-Attention
Self-Attention(自注意力机制)是 Transformer 架构中的核心组件。它能够让模型在处理序列数据(如自然语言文本中的单词序列、时间序列等)时,自动地关注序列中不同位置的元素,从而更好地捕捉序列内部的依赖关系。
1.1查询(Query)、键(Key)和值(Value)的生成


1.2 注意力分数(Attention Scores)的计算
对于序列中的每个位置i,计算其与其他位置j的注意力分数。注意力分数衡量了位置i对位置j的关注程度。这个分数通过查询向量qi和键向量kj的点积(Dot - Product)来计算,并且为了防止数值过大,通常会除以sqrt(dk) ( 是查询向量和键向量的维度),再通过一个 Softmax 函数进行归一化。
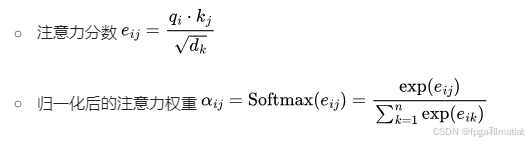
1.3 输出的计算
最后,通过注意力权重对值向量进行加权求和,得到输出向量yi
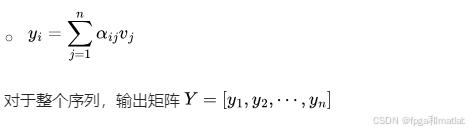
2.Flash-Attention
Flash Attention是一种高效的注意力机制计算方法。在传统的自注意力计算中,计算复杂度和内存占用较高,尤其是在处理长序列数据时。Flash Attention的主要目标是减少计算量和内存访问,从而提高计算速度,同时保持较高的准确性。Flash Attention利用了一些数学技巧和算法优化来加速注意力计算。其关键思想包括分块计算(Tiling)和近似计算(Approximate Computation),以减少不必要的计算和内存操作。其结构如下图所示:
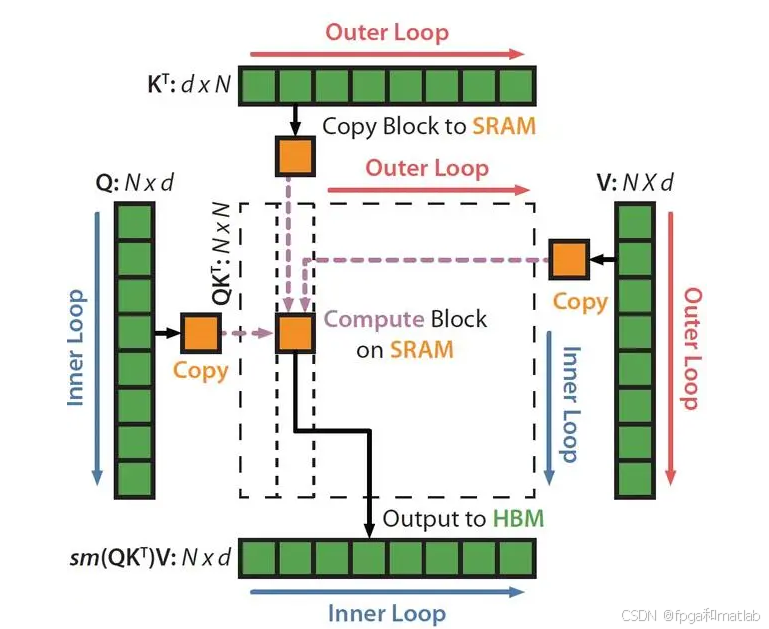
2.1 分块处理

2.2 块级注意力计算

2.3 合并块输出
将所有小块的输出合并起来,得到最终的输出。这个过程可能需要一些额外的处理,例如调整维度和拼接操作。

Flash Attention还可能采用一些近似计算方法来进一步减少计算量。例如,在计算注意力分数和权重时,可以使用低精度的数据类型(如半精度浮点数)或者进行截断操作。另外,通过合理安排计算顺序和利用缓存(Cache)技术,可以减少内存访问次数。例如,重复利用已经计算过的中间结果,避免重复计算相同的部分。
2.4 One-Pass计算
Flash Attention的一个关键特性是能够实现 “one-pass” 计算。在传统的自注意力计算中,需要先计算所有的注意力分数,然后进行 Softmax 归一化,最后计算加权求和。这个过程涉及到多个步骤,并且中间结果需要存储在内存中。
Flash Attention通过巧妙的算法设计,在一次遍历数据的过程中完成注意力计算。它利用了一些近似和优化技巧,使得计算能够更加高效地在硬件上执行。
2.5 Q、K、V分块操作
Flash Attention 采用分块(Tiling)操作来处理 Q、K、V 矩阵。

传统问题:在传统自注意力计算中,需要先计算完整的注意力矩阵,然后进行 Softmax 归一化,再计算输出。这个过程中会产生大量中间结果并存储在内存中,增加了内存开销和计算时间。
Flash Attention 策略:Flash Attention 采用一种动态计算和更新的策略。它不是预先计算完整的注意力矩阵,而是在计算小块输出时,根据需要动态地计算注意力分数和权重。例如,在计算一个小块Qi与其他小块Ki和Vj的交互时,仅计算当前小块所需的注意力分数和权重,并且在计算完成后,不存储完整的注意力矩阵,而是直接更新小块输出。这种方式减少了内存中中间结果的存储,同时也避免了不必要的计算。

欢迎加入 MCP 技术社区!与志同道合者携手前行,一同解锁 MCP 技术的无限可能!
更多推荐


 7
7 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)